











 text in
text in  English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink
INTRODUCCIÓN
Debido al incremento de la tecnología respecto a la comunicación y transferencia de datos a través de redes, el uso sistemas de huellas dactilares se ha hecho común en el área forense y policial, tanto en instituciones del Estado como en instituciones privadas. Un ejemplo de ello son los bancos, donde se verifica la huella para realizar retiros de dinero, lo que brinda seguridad al cliente ante una suplantación o robo de identidad. Otro caso es cuando un delincuente ingresa a la sala de operaciones con el fin de practicarse varias cirugías estéticas para lograr un cambio físico notorio de su persona; la identidad de esta persona se detecta gracias a su huella dactilar, que es única e irrepetible. De la misma forma, cuando se presenta una persona desfigurada por algún accidente, se puede realizar su reconocimiento inequívoco gracias a sus huellas dactilares.
La investigación se basa en la búsqueda de información en grandes bases de datos, lo que origina que el tiempo de respuesta se vea reflejado en costos muy elevados; así, la búsqueda de imágenes complica aún más el levantamiento de información. El almacenamiento de una imagen digital implica contar con un gran espacio de memoria, y si se trata de una gran cantidad de imágenes, se eleva el costo. La búsqueda de este tipo de información se puede realizar utilizando diferentes tipos de algoritmos; sin embargo, se debe tener en cuenta el tiempo de respuesta y el costo que se originan al realizar la búsqueda en estas grandes bases de datos, donde el tiempo de respuesta es fundamental.
La búsqueda eficiente de huellas dactilares conduce al objetivo general de investigación, que es plantear un método de búsqueda eficiente de huella dactilar a un menor costo y tiempo, en el cual se aplica machine learning, para la clasificación de segmentos, y algoritmo discreto, para la búsqueda secuencial en un determinado segmento.
Realizar una búsqueda secuencial en una gran base de datos genera demora en el tiempo de búsqueda. Las huellas dactilares cuentan con características que permiten su clasificación, como arco, arco derecho, arco izquierdo, arco de carpa y circular o espiral (Dass y Jain, 2004). El trabajo de búsqueda de huellas dactilares presentado se enfoca únicamente en huellas dactilares de individuos en una macro base de datos con la finalidad de reducir el tiempo de búsqueda.
La clasificación de huellas dactilares consiste en realizar un particionamiento sistemático de la base de datos en diferentes segmentos utilizando machine learning. Dichos segmentos se conforman por la aproximación de las características de cada huella dactilar. La clasificación de las huellas en segmentos reduce significativamente el tiempo empleado en la identificación de las huellas dactilares, especialmente en situaciones donde la precisión y la velocidad son críticos.
La propuesta del método consiste primero en clasificar las huellas dactilares por sus características utilizando machine learning, de modo que sea posible crear grupos por características similares o más próximas; luego, en un segundo momento, utilizar un algoritmo discreto que permita realizar una búsqueda secuencial y encontrar la huella buscada.
MARCO TEÓRICO
Sistemas biométricos
Un sistema biométrico esencialmente es un reconocedor de patrones que captura datos biométricos de una persona, extrae un conjunto de características a partir de dichos datos y las compara con otros patrones previamente almacenados en el sistema (Wayman, Lain, Maltoni, y Maio, 2005).
Un sistema biométrico es un sistema automatizado que realiza tareas de biometría. Es decir, es un sistema que fundamenta sus decisiones de reconocimiento mediante las características físicas o de comportamiento de una persona de manera automatizada ( Fernández, 2008).
Para solucionar estos problemas, se vienen desarrollando métodos basados en ciertos rasgos biométricos que garantizan la identidad de las personas. Estos rasgos biométricos están clasificados en dos tipos (Fernández, 2008): El primero es la biometría fisiológica, basada en las partes de cuerpo, como son las huellas dactilares, el iris, la retina, la voz, la mano y el rostro. El segundo tipo es la biometría conductual, basada en las de acciones de una persona, como, por ejemplo, la firma de un individuo.
Características de un indicador biométrico
Según Fernández (2008), un indicador biométrico es alguna característica con la cual se puede realizar biometría, así se tiene:
Universalidad: el rasgo biométrico existe para todas las personas.
Unicidad: el rasgo identifica unívocamente a cada persona.
Permanencia: el rasgo se mantiene invariable con el tiempo a corto plazo.
Inmutabilidad: el rasgo se mantiene invariable con el tiempo a largo plazo o durante toda la vida.
Mensurabilidad: el rasgo es apto para ser caracterizado cuantitativamente.
Rendimiento: el rasgo permite el reconocimiento del individuo con rapidez, robustez y precisión.
Aceptabilidad: el rasgo debe ser aceptado por la mayoría de la población.
Invulnerabilidad: el rasgo permite la robustez del sistema frente a los métodos de acceso fraudulentos.
La Tabla 1 muestra las diversas tecnologías biométricas según los grados de confianza (alto, medio, bajo) de las propiedades anteriormente descritas (Maltoni, Maio, Jain, y Prabhakar, 2003).
Tabla 1 Comparación de tecnologías biométricas.
| Identificador biométrico | Universalidad | Unicidad | Permanencia | Mensurabilidad | Rendimiento | Aceptabilidad | Invulnerabilidad |
|---|---|---|---|---|---|---|---|
| ADN | Alto | Alto | Alto | Bajo | Alto | Bajo | Bajo |
| Oreja | Medio | Medio | Alto | Medio | Medio | Alto | Medio |
| Cara | Alto | Bajo | Medio | Alto | Bajo | Alto | Alto |
| Termo grama facial | Alto | Alto | Bajo | Alto | Medio | Alto | Bajo |
| Huella dactilar | Medio | Alto | Alto | Medio | Alto | Medio | Medio |
| Modo de andar | Medio | Bajo | Bajo | Alto | Bajo | Alto | Medio |
| Geometría de la mano | Medio | Medio | Medio | Alto | Medio | Medio | Medio |
| Venas de la mano | Medio | Medio | Medio | Medio | Medio | Medio | Bajo |
| Iris | Alto | Alto | Alto | Medio | Alto | Bajo | Bajo |
| Pulsación de teclado | Bajo | Bajo | Bajo | Medio | Bajo | Medio | Medio |
| Olor | Alto | Alto | Alto | Bajo | Bajo | Medio | Bajo |
| Retina | Alto | Alto | Medio | Bajo | Alto | Bajo | Bajo |
| Firma | Bajo | Bajo | Bajo | Alto | Bajo | Alto | Alto |
| Voz | Medio | Bajo | Bajo | Medio | Bajo | Alto | Alto |
Fuente: Datos basados en la percepción de los autores del libro Handbook of Fingerprint (Maltoni et al., 2003).
Identificación biométrica
La identificación biométrica ha sido definida por el profesor Jain Lakhmi como el proceso que permite relacionar de forma automática la identidad de un individuo mediante el uso de algunas características físicas o del comportamiento que sea inherente a la persona (Fernández, 2008).
Huella dactilar
Una huella dactilar es la representación de la morfología superficial de la epidermis de un dedo (Persto, 2020). La huella dactilar se forma en la etapa fetal del ser humano y está constituida por crestas papilares; asimismo, es inmutable durante toda la vida, a menos que sufra lesiones o daños severos (Villamizar, 1994).
Características de la huella dactilar
En 1892, Francis Galton publicó el primer sistema de clasificación y estableció la individualidad y permanencia de las huellas dactilares; los “puntos finos” que Galton identificó son utilizados hoy en día (Persto, 2020).
Dass y Jain (2004) se basaron en la clasificación de las huellas digitales de Henry (1900), quien plantea cinco clases principales basadas en el NIST4: (a) arco izquierdo, (b) arco derecho, (c) arco, (d) arco de carpa y (e) circular o espiral. Esta se muestra en la Figura 1.
Fuente: Base de datos especial del Instituto Nacional de Estándares y Tecnología (NIST4) (Dass y Jain, 2004)

El módulo de inscripción o almacenamiento de la Huella dactilar
Se encarga de la adquisición análoga o digital de algún indicador biométrico de una persona, como, por ejemplo, la adquisición de la imagen de una huella dactilar mediante un escáner. Una vez obtenida la huella se almacena en la base de datos (patrones o plantillas) proveniente de un dispositivo biométrico. El proceso se puede observar en la Figura 2.
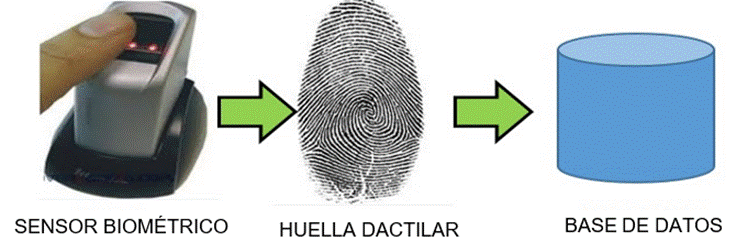
Fuente: Elaboración propia.
Figura 2 Módulo de inscripción de una huella dactilar de un sistema biométrico.
Arquitectura de los procesos de un sistema biométrico
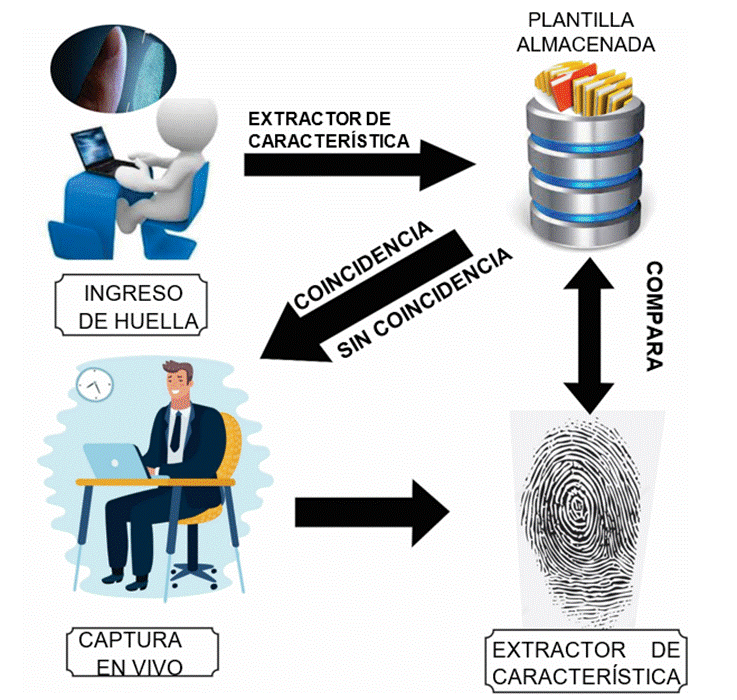
El proceso actual inicia en el ingreso de la huella dactilar en un aparato de reconocimiento de huella con un escáner óptico de huellas. Este aparato convierte la información en dígitos y captura la imagen de la huella ingresada. Una vez digitalizada, la huella es llevada a la base de datos (plantilla) por medio de algoritmos matemáticos según su característica particular.
Luego se continúa con la captura en vivo de la huella que se va a buscar; extrayendo sus características se realiza la búsqueda en la base de datos donde se encuentran almacenadas con anterioridad las huellas. Si encuentra coincidencias con la imagen ingresada, se puede comprobar la identidad de la persona a quien corresponde dicha imagen, lo que da un resultado positivo en la búsqueda. Si se diera el caso de no encontrar coincidencias en la imagen digitalizada de la huella, esta es comparada y arroja un resultado negativo de dicha búsqueda (ver Figura 3).
Método de clustering
El clustering tiene aplicaciones variadas dentro de las ciencias de la computación, como, por ejemplo, la compresión de imágenes (Scheunders, 1997) y digitalización de la voz (Makhoul, Roucos y Gish, 1985); recuperación de información relacionada (Bathia y Deogun, 1998); minería de datos, donde se da la búsqueda de grupos con determinadas características de interés (así se tiene el descubrimiento de nuevos segmentos de clientes con el objetivo de mejorar los servicios que se brinda) (Fayyad, Piatetsky-Shapiro y Padhraic, 1996); la segmentación de imágenes al dividir la imagen en regiones homogéneas (de acuerdo con alguna característica de interés como son la intensidad, el color o textura), esto es especialmente importante en aplicaciones médicas (Pham y Prince, 1999); y la clasificación de imágenes satelitales en diferentes zonas (urbana, descampados, ríos, bosques) (Soldberg, Taxt, y Jain, 1996).
Los métodos de clustering se diferencian entre ellos en la manera de componer los clusters. Aquellos que lo hacen según la correspondencia a una partición del conjunto de objetos son conocidos como métodos de Hard-clustering (Kearns, Mansour, y Ng, 1997); de estos, el más conocido es el algoritmo K-Means (Forgy, 1965; MacQueen, 1967).
Algoritmo K-Means
El algoritmo K-Means aplicado a clustering (Forgy, 1965) es una heurística comúnmente utilizada para resolver el problema de clustering (MacQueen, 1967). La idea esencial del algoritmo es tener los K centros iniciales y armar clusters asociando los objetos de X a los centros más cercanos; luego, se recalculan los centros. Si los nuevos centros no difieren de los centros previos, el algoritmo finaliza; en caso contrario, se itera el proceso de asociación con nuevos centros hasta que no exista variación en los centros o se establezca algún nuevo criterio de parada con poco número de reasignaciones de los objetos para estos métodos.
Machine learning
Se denomina machine learning a un conjunto de algoritmos computacionales que comparten un principio en común: El usuario no implementa la función de evaluación de manera explícita, sino simplemente provee al ordenador una forma de crear autónomamente esta función para después optimizarla a partir de la experiencia basada en datos de aprendizaje. En otras palabras, el usuario no introduce los criterios empleados por la computadora, es esta quien determina los criterios utilizando un algoritmo en particular.
En este proyecto, se emplea específicamente un algoritmo denominado K-Means (o K Medias), que es un algoritmo de segmentación/clusterización de datos. Este método fue propuesto formalmente por primera vez el año 1957 por el matemático Stuart P. Lloyd, aunque su publicación oficial data del año 1982, en el artículo titulado Least Squares Quantization in PCM. Este algoritmo ha sido optimizado varias veces en las décadas subsiguientes, hasta llegar a implementaciones recientes. El K-Means consiste en la segmentación de un conjunto de puntos en un espacio euclidiano de la siguiente manera: Primero, el algoritmo asigna k centroides de manera aleatoria (donde k es un valor arbitrario escogido por el usuario). Los clusters son entonces segmentados de acuerdo a la mínima distancia de cada punto con cada uno de estos centroides como se muestra en la Figura 4.
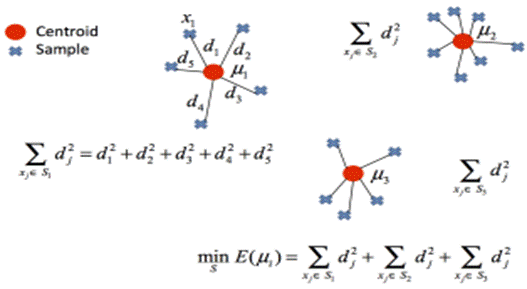
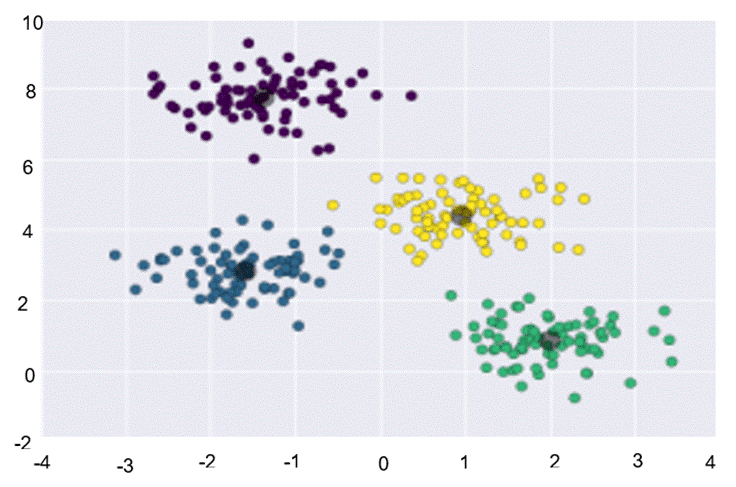
Una vez que los k clusters están formados, se recalculan los centroides empleando la media del conjunto de puntos pertenecientes a cada cluster, como se observa en la Figura 5. El algoritmo es iterativo, por lo que el proceso se repite hasta que los centroides convergen. En este caso, convergencia significa que los clusters formados permanecen constantes incluso en las iteraciones subsiguientes. Cabe resaltar que la convergencia de este algoritmo en una cantidad finita de iteraciones ya ha sido demostrada, por lo que siempre es posible llegar a un final.
METODOLOGÍA
Se realizó la revisión documental del tema de investigación, se analizó la información escrita sobre la búsqueda de huella dactilar en una base de datos grande y se encontró un buen número de artículos relacionados al tema en las bases de datos indexadas de los últimos años. Se revisó cada uno de los artículos encontrados en la búsqueda de información, lo que resultó ser relevante para ampliar y definir la visión del tema; de esta forma, se genera el aporte adecuado a la solución de este tipo de problemas.
Se finalizó con el planteamiento de segmentación de la base de datos a gran escala en segmentos que agrupen las huellas dactilares por sus características, para luego seleccionar un solo segmento donde se realizaría la búsqueda de la huella a identificar; este modelo contempla tener un tiempo de respuesta eficiente al realizar la búsqueda de una determinada huella en una base de datos muy grande.
ANTECEDENTES
Clasificación huellas dactilares usando curvas de flujo de campo de orientación
Los autores Dass y Jain (2004) revisan las diferentes series de enfoque que se han desarrollado sobre la clasificación de las huellas dactilares; además, verifican que los métodos híbridos desarrollados no han sido probados en grandes bases de datos. Asimismo los autores indican que las clases que se utilizan para la clasificación son importantes. Otros investigadores han empleado cuatro clases que no resultaron ser efectivas en la clasificación; por lo tanto, en este caso los autores plantean cinco clases para obtener mejores resultados.
De acuerdo a lo expresado por Dass y Jain (2004), el procedimiento que utilizaron casi logró determinar la clasificación de las huellas digitales con un porcentaje de 94.4% de exactitud, por lo que proponen, en un trabajo a futuro, incluir en su estudio la detección de las zonas donde se originan los bucles más pequeños, además de seguir tomando como base la clasificación propuesta por Henry (1900), que consiste en: arco, arco derecho, arco, arco de carpa y circular o espiral.
El procedimiento utilizado se basa en la base de datos NIST4 (Instituto Nacional de Estándares y Tecnología), y el enfoque usado para el desarrollo es una combinación del enfoque estructural, sintáctico y netamente basado en las matemáticas (Watson y Wilson, 1992).
Un método eficaz de clasificación y búsqueda de huellas dactilares
La clave para la tarea de clasificación de imágenes de huellas dactilares son las características. La eficacia de la extracción de las caracterizadas depende de la calidad de las imágenes, la representación de los datos de la imagen, de los modelos de procesamiento de imágenes y la evaluación de la extracción de la característica.
La evaluación en tiempo real de la calidad de la imagen ofrece mejorar mucho la precisión del sistema de identificación. La buena calidad de las imágenes requiere menor pretratamiento y mejora. Por el contrario, las imágenes de baja calidad requieren mayor pretratamiento y, por supuesto, mejora. Para que la búsqueda de huellas dactilares sea eficiente, se requiere que las imágenes de la huella dactilar sean de buena calidad.
La mayoría de los métodos clasifican las huellas dactilares en cuatro o cinco clases con un nivel de precisión de 80% a 95%. El método propuesto por los autores las clasifica en seis clases con las cuales se obtiene un nivel de precisión del 97%, lo que muestra una mejora con respecto a los anteriores (Bhuvan y Bhattacharyya, 2009).
Un sistema de emparejamiento en tiempo real para grandes bases de datos de huellas dactilares
La técnica que mencionan Ratha, Karu, Chen, y Jain (1996) es más simple: consiste en colocar las imágenes en la base de datos como un texto plano, el cual es una secuencia de caracteres con la información de cada píxel. El principal inconveniente de este método es que la escena de descripción puede ser diferente en momentos diferentes para el mismo, dependiendo del contexto de la consulta. Los autores se sienten motivados cuando observan el gran espacio que ocupan estos datos al ser almacenados y plantean reducirlo usando técnicas de extracción de características.
Una base de datos de huellas digitales se caracteriza por un gran número de registros (del orden de millones). El tamaño de la base de datos del FBI ha crecido de más de 0.8 millones de tarjetas de huellas dactilares (diez huellas dactilares por tarjeta), en 1924, a más de 114 millones de tarjetas de huellas dactilares en 1994. El requisito de almacenamiento para una colección tan grande de imágenes se ejecuta en 1.140 terabytes sin compresión. Además, se espera que el tipo de consulta de este sistema difiera radicalmente de los otros dominios de aplicación de bases de datos de imágenes.
La imagen del mismo objeto puede variar dependiendo de su orientación, la luz ambiente y el sensor. El sentido de la información es de una dimensionalidad mucho mayor que la información textual. En una biblioteca digital hay principalmente tres componentes: captura de datos, gestión del almacenamiento y técnicas de búsqueda y consulta.
Según la propuesta de Ratha et al. (1996), se separa la información de las imágenes en sus características para guardarlas en la base de datos. De esta forma, solo hace falta tomar una foto de la huella de una persona y verificarla con las características propias de la persona.
A menudo, la mala calidad de las imágenes reduce la precisión del sistema. Por lo tanto, de acuerdo con Douglas (1993), se está considerando una evaluación de calidad de imagen en la etapa de entrada.
Modelo de búsqueda secuencial
Como se observa en la Figura 6, actualmente la búsqueda de huellas dactilares en una gran base de datos demanda demasiado tiempo de respuesta cuando se realiza una búsqueda secuencial, aun cuando la base de datos está ordenada, por lo que esta búsqueda se puede relacionar con el valor tiempo-costo.
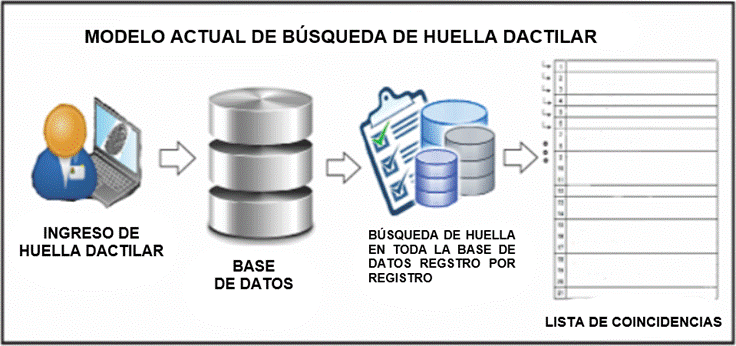
Búsqueda secuencial de una huella dactilar
Dado el ingreso de una imagen de una huella digital (ver Figura 6), en formato bmp, esta se representa en una matriz cuyos elementos son ceros y unos. Luego, se realiza la conexión a la base de datos para buscar dicha matriz que tiene el tipo BLOB (Binary Large Object).
El siguiente código explica como el SQLite realiza una búsqueda secuencial registro por registro, y retorna una lista. Si el elemento ha sido encontrado, esta lista tiene un tamaño mayor a cero. De lo contrario, el tamaño es cero. Lo cual nos permite determinar cuándo una búsqueda ha sido exitosa (ver Figura 7).
Modelo propuesto
El modelo que se plantea segmenta la base de datos de gran magnitud en segmentos según las características de cada una de las huellas, de tal manera que la búsqueda no se realice en toda la base de datos sino en un determinado segmento; luego, en este segmento seleccionado, se realiza la búsqueda, y así se obtiene un resultado inmediato de la identificación de la huella buscada, como se muestra en la Figura 8.
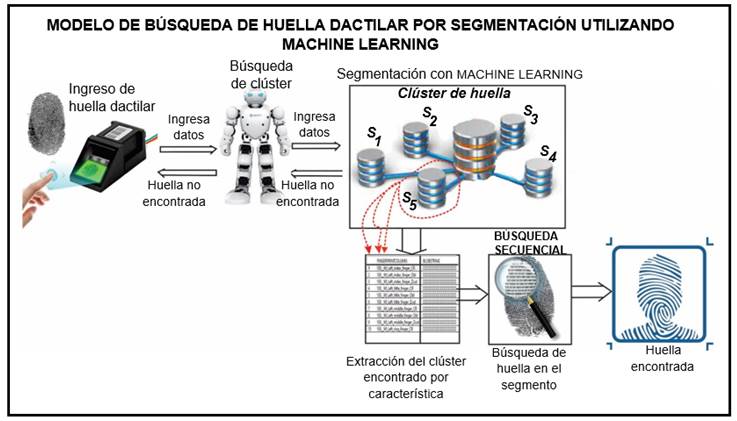
Fuente: Elaboración propia.
Figura 8 Modelo de búsqueda de huellas dactilares en grandes bases de datos.
En primer lugar, se ingresa la huella dactilar de la persona que debe ser identificada. A través del ordenador, se ejecuta la aplicación de clasificación de la huella ingresada, la cual retornará el número de segmento correspondiente encontrado en la base de datos ya entrenada en la fase de entrenamiento del modelo para la respectiva búsqueda. Esta base de datos contiene todas las huellas dactilares almacenadas, en ella se encuentra la huella a identificar. Buscar en la base de datos no segmentada demanda un tiempo de respuesta muy largo que, en algunos casos, es fundamental para tomar una decisión.
La base de datos que almacena las huellas dactilares es grande, por lo que, al realizar una búsqueda secuencial, esta tarda un tiempo considerable en dar la respuesta, a pesar de que la base de datos esté indexada. Dichas huellas dactilares cuentan con ciertas características que permiten clasificarlas en segmentos, lo que permite realizar la búsqueda solamente en el segmento seleccionado, donde se encuentra la huella a buscar. Para la segmentación se utiliza machine learning, específicamente el algoritmo K-Means, que permite agrupar las huellas según las características que el algoritmo identifica como más próximas. Al usar este método se segmenta la base de datos en cinco clusters (segmentos).
Al ingresar la huella que se va a buscar, se clasifica según el número de segmento que la contiene. Luego de ser ubicada en el segmento seleccionado, se realiza una búsqueda en ese segmento utilizando un algoritmo discreto. Como se observa, la búsqueda ya no se realiza en toda la base de datos, sino solamente en el segmento seleccionado. Así, se observa que al realizar la búsqueda en un solo segmento la huella buscada se identifica en un tiempo óptimo.
Funciones y módulos
Búsqueda secuencial no segmentada
En el presente script se realiza la búsqueda secuencial de una imagen en una base de datos no segmentada, donde el objetivo principal es obtener el tiempo que demora el algoritmo en encontrar el par en búsqueda y se muestra en la interfaz.
import time
import sqlite3
def busqueda_sec(bin):
inicio = time.perf_counter()
try:
sqliteConnection = sqlite3.connect(’nocluster.db’) cursor = sqliteConnection.cursor()
print("Connected to SQLite")
sql_fetch_blob_query = """SELECT * from
nocluster where imagen = ? LIMIT 1"""
cursor.execute(sql_fetch_blob_query, (bin,))
record = cursor.fetchall()
cursor.close()
except sqlite3.Error as error:
print("Failed to read blob data from sqlite table", error)
# finally:
# if sqliteConnection:
# sqliteConnection.close()
# print("sqlite connection is closed")
tiempo = time.perf_counter() - inicio
dir_img = ’D:/Python/milhuellas/k-images/’
+record[0][0]+’.bmp’
#print(tiempo)
return tiempo, dir_img
Predicción y búsqueda
Se carga un modelo entrenado previamente que se aplicará para predecir en que cluster se encuentra la imagen a buscar, luego se aplica el algoritmo de búsqueda secuencial en dicho cluster, se captura el tiempo de todo el proceso y se muestra en la interfaz.
import time
from joblib import load
import sqlite3
cluster= load(’2domodelo’)
def busqueda_cluster(features,bin):
inicio = time.perf_counter()
clus = cluster.predict(features)[0] #clus = 0,1,2,3
try:
sqliteConnection = sqlite3.connect(’cluster.db’)
cursor = sqliteConnection.cursor()
print("Connected to SQLite")
sql_fetch_blob_query = """SELECT * from cluster{0} where imagen = ? LIMIT 1""".format(clus+1)
cursor.execute(sql_fetch_blob_query, (bin,))
record = cursor.fetchall()
cursor.close()
except sqlite3.Error as error:
print("Failed to read blob data from sqlite table", error)
# finally:
# if sqliteConnection:
# sqliteConnection.close()
# print("sqlite connection is closed")
tiempo = time.perf_counter() - inicio
dir_img = ’D:/Python/milhuellas/k-images/’ +record[0][0]+’.bmp’
#print(tiempo)
return tiempo, dir_img
Otras funciones necesarias
La función image_feature necesita de InceptionV3, que es una red neuronal convolucional para ayudar en el análisis de imágenes y la detección de objetos y que comenzó como un módulo para Googlenet.
def image_feature(imagen):
model = InceptionV3(weights=’imagenet’, include_top=False)
features = [];
img=image.load_img(imagen, target_size=(224,224))
x = img_to_array(img)
x=np.expand_dims(x,axis=0)
x=preprocess_input(x)
feat=model.predict(x)
feat=feat.flatten()
features.append(feat)
return features
def salir():
shutil.rmtree(’Temporal’)
exit()
Pruebas de tiempo
Finalmente, tras la implementación del algoritmo en el programa, se debe determinar el tiempo de procesamiento de cada búsqueda para la comparación correspondiente. Se toman 50 imágenes escogidas aleatoriamente sin repetición con la finalidad de analizar la evolución del tiempo de búsqueda con relación a la posición de la imagen en la base de datos no clusterizada. Tras la ejecución de los algoritmos previamente expuestos, se determinaron los resultados que se muestran en la Tabla 2.
Tabla 2 Tiempo de búsqueda del algoritmo propuesto.
| Nro. | Nro. Huella | Tiempo Segmentado (s) | Tiempo Secuencial (s) | Nro. | Nro. Huella | Tiempo Segmentado (s) | Tiempo Secuencial (s) |
|---|---|---|---|---|---|---|---|
| 1 | 531 | 0.004379 | 0.008464 | 26 | 268 | 0.002802 | 0.004809 |
| 2 | 528 | 0.004228 | 0.008589 | 27 | 264 | 0.009219 | 0.008393 |
| 3 | 517 | 0.004777 | 0.008337 | 28 | 261 | 0.003089 | 0.005612 |
| 4 | 513 | 0.004227 | 0.008667 | 29 | 259 | 0.003477 | 0.006325 |
| 5 | 506 | 0.003872 | 0.008317 | 30 | 247 | 0.007648 | 0.008603 |
| 6 | 490 | 0.003828 | 0.008067 | 31 | 237 | 0.007601 | 0.009455 |
| 7 | 486 | 0.005438 | 0.008955 | 32 | 236 | 0.009113 | 0.005527 |
| 8 | 483 | 0.005157 | 0.010635 | 33 | 233 | 0.003252 | 0.006325 |
| 9 | 480 | 0.004468 | 0.008513 | 34 | 222 | 0.003704 | 0.005572 |
| 10 | 472 | 0.006281 | 0.015658 | 35 | 211 | 0.008135 | 0.010234 |
| 11 | 444 | 0.002972 | 0.007607 | 36 | 179 | 0.003113 | 0.003579 |
| 12 | 442 | 0.003441 | 0.007469 | 37 | 173 | 0.002846 | 0.002438 |
| 13 | 437 | 0.003763 | 0.007042 | 38 | 163 | 0.003166 | 0.002587 |
| 14 | 428 | 0.004522 | 0.016173 | 39 | 156 | 0.002703 | 0.002495 |
| 15 | 408 | 0.004283 | 0.006484 | 40 | 153 | 0.002625 | 0.002485 |
| 16 | 397 | 0.004105 | 0.008492 | 41 | 144 | 0.002265 | 0.002865 |
| 17 | 392 | 0.004123 | 0.007803 | 42 | 138 | 0.002307 | 0.002889 |
| 18 | 390 | 0.004025 | 0.006753 | 43 | 121 | 0.002772 | 0.001929 |
| 19 | 377 | 0.003137 | 0.006483 | 44 | 91 | 0.005962 | 0.003999 |
| 20 | 356 | 0.010098 | 0.014196 | 45 | 80 | 0.002847 | 0.001563 |
| 21 | 337 | 0.003842 | 0.008346 | 46 | 78 | 0.002946 | 0.001216 |
| 22 | 316 | 0.008645 | 0.013955 | 47 | 66 | 0.002495 | 0.001253 |
| 23 | 312 | 0.003817 | 0.006923 | 48 | 64 | 0.002835 | 0.001167 |
| 24 | 309 | 0.003928 | 0.005397 | 49 | 42 | 0.002091 | 0.001048 |
| 25 | 272 | 0.003292 | 0.006387 | 50 | 9 | 0.003076 | 0.000588 |
Fuente: Elaboración propia.
La primera columna describe la posición de la imagen en la base de datos, mientras que las siguientes dos columnas muestran el tiempo de búsqueda en segundos de la imagen usando los algoritmos segmentado y secuencial, respectivamente.
En conclusión, el experimento desarrollado permite confirmar que el algoritmo de búsqueda segmentada presenta ventajas sobre el algoritmo secuencial clásico. Esto principalmente debido a los dos siguientes motivos:
La búsqueda secuencial en un cluster es considerablemente menor en promedio al tiempo de búsqueda en la base de datos completa.
El tiempo de evaluación de una imagen en el modelo de clasificación es lo suficientemente breve como para no exceder al tiempo de búsqueda del algoritmo secuencial.
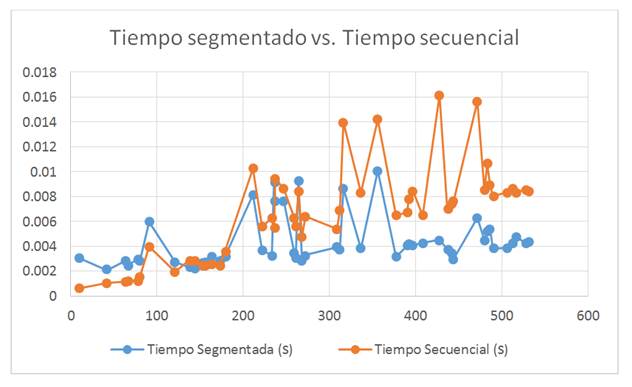
En la Figura 9 se observa que la intersección de las rectas de tiempo secuencial y tiempo segmentado se da en el punto 112.5; luego, de acuerdo con los diagramas de regresión realizados, se puede deducir que para una base de datos de 537 imágenes, el punto donde la búsqueda secuencial empieza a tomar más tiempo es a partir de la imagen en la posición 113 en la base de datos no segmentada.
DISCUSIÓN
El enfoque de Dass y Jain (2004) tiene cuatro etapas principales: primero, la extracción del campo de orientación para la imagen de la huella dada; segundo, la generación de orientación de campo flujo curvas (OFFCs); tercero, el etiquetado de cada OFFC en las cuatro clases: bucles izquierdo y derecho, espiral y arco; y, por último, una clasificación general de la imagen de huella digital en una de las cuatro clases basada netamente en las matemáticas (el valor de la orientación de la imagen de la huella digital es un vector) y utilizando métodos de la geometría diferencial. De acuerdo con lo expresado por Dass y Jain (2004), con el procedimiento que utilizaronen lograron determinar la clasificación de las huellas digitales con un porcentaje de 94.4% de exactitud.
El propósito de este artículo es proponer un método de búsqueda totalmente eficiente aplicando machine learning, el cual obtiene una segmentación de las huellas dactilares de una base de datos grande y la agrupa según las características de cada huella en segmentos. Luego, se aplica un algoritmo de búsqueda secuencial en uno de los segmentos seleccionados, es decir, el que contiene la huella a identificar. La propuesta de este modelo es minimizar los tiempos de búsqueda y se logra una confianza al 95%. Se demuestra también en esta investigación que la búsqueda segmentada es más eficiente que realizar una búsqueda secuencial en una base de datos grande, lo que también es más eficiente que el método utilizado por Dass y Jain (2004).
CONCLUSIONES
El presente artículo tiene como objetivo principal minimizar tiempos en el motor de búsqueda al realizar la identificación de una persona en una gran base de datos. Tras la evaluación de métodos y algoritmos existentes, el aporte concluye que al emplear machine learning se consigue segmentar una gran base de datos agrupando las huellas dactilares por sus características más próximas y aplicando luego una técnica de búsqueda secuencial en solo un segmento seleccionado para encontrar la huella dactilar de la persona en términos eficientes.
Este modelo no busca la huella en toda la base de datos, pues ello demanda un tiempo de respuesta muy alto. Lo que se plantea con esta propuesta es realizar la búsqueda solo en uno de los segmentos clasificados por características, donde se encontraría la huella buscada, con lo que se reduce el tiempo de búsqueda.
RECOMENDACIONES
En el estudio de la investigación en relación al tema “Búsqueda de huellas dactilares en gran base de datos”, se sugiere una metodología documental y exhaustiva conservando el modelo propuesto en el tema del artículo de investigación. Al realizar la segmentación se recomienda utilizar algoritmos genéricos, que son métodos adaptativos que pueden usarse para resolver problemas de búsqueda y optimización con la finalidad u objetivo único de optimizar en tiempo los resultados finales.
También se recomienda realizar pruebas con una muestra más grande para probar la eficiencia del modelo propuesto.

