











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkAportes de la filogenética a la investigación médica.
Contributions of phylogenetics to medical research.
Javier Mendoza-Revilla1
1 Bachiller en Biología, Unidad de Biología Integrativa (UBI) Laboratorios de Investigación y Desarrollo (LID) Universidad Peruana Cayetano Heredia. Lima, Perú.
RESUMEN
A pesar de su reciente incorporación en la investigación médica, la biología evolutiva ha contribuido significativamente en el entendimiento del origen, desarrollo y mantenimiento de muchas enfermedades importantes para el ser humano. Investigaciones en enfermedades infecciosas, sobretodo en la resistencia contra antibióticos son claros ejemplos de esto. Así mismo, ha cambiando la forma en que vemos y entendemos a nuestro cuerpo, y su vulnerabilidad a ciertos tipos de enfermedades. Otras áreas como el cáncer, enfermedades mentales y envejecimiento han empezado a beneficiarse de la perspectiva evolutiva. Más específicamente, la filogenética como una disciplina de la biología evolutiva, ha mostrado ser una herramienta eficiente para descubrir los orígenes de enfermedades y determinar que cepas poseen mayor probabilidad de propagación. Debido a esto, este artículo tiene como objetivo brindar una idea básica de qué son y cómo interpretar los denominados árboles filogenéticos. Los médicos que puedan entender estos métodos, sin duda, podrán estar mejor preparados para comprender la creciente literatura médica que aborda este tipo de aproximación metodológica que se deriva de la biología evolutiva.
PALABRAS CLAVE: Investigación médica, evolución, genética. (Fuente: DeCS BIREME)
SUMMARY
Despite its recent incorporation into medical research, evolutionary biology has contributed significantly in the understanding of the origin, development and maintenance of many important human diseases. Research on infectious diseases, such as antibiotic resistance is a clear example of this. It has also changed the way we see and understand our bodies, as well as their vulnerability to certain types of illnesses. Other areas of research such as cancer therapeutics, mental disorders and aging have begun to benefit from adopting an evolutionary perspective. More precisely, phylogenetics, as a discipline of evolutionary biology, has proved itself an efficient tool for discovering the origins of many diseases and thus determine which strains have higher likelihood of spreading. This article aims to provide a basic understanding of what phylogenetic trees are and how to interpret them. Physicians who can understand these methods will undoubtedly be better prepared to comprehend the growing literature that addresses this type of approach derived from evolutionary biology.
KEY WORDS: Medical research, evolution, genetics. (Source: MeSH NLM)
INTRODUCCIÓN
De las muchas aplicaciones de la biología evolutiva, aquellas en medicina son las más obvias y potencialmente las más importantes para la salud humana. Sin embargo, la medicina y la salud pública han usado tan solo una fracción de lo que la biología evolutiva puede ofrecer (1). Entre las áreas donde la biología evolutiva ha tenido un aporte importante, destacan aquellas relacionadas con la compresión de las enfermedades infecciosas, sobre todo en la resistencia a los antibióticos. Como fue resaltado por Restif (2), "las enfermedades infecciosas, causadas por organismos microscópicos que viven con un corto tiempo generacional y enormes variaciones demográficas, son sin duda un campo de juego natural para la evolución". La resistencia a antibióticos no es más que un claro ejemplo de selección natural (aunque a un nivel celular y no individual). De la misma manera, las investigaciones en cáncer han empezado a ver esta enfermedad desde un punto de vista evolutiva (3,4). La lógica es muy parecida, ya que las células cancerígenas, son también células que poseen una mayor capacidad de reproducción que las células normales.
Quizás una de las mayores contribuciones de la biología evolutiva hacia la medicina ha sido proveer una mejor compresión de nuestro cuerpo, y de porque nos ha dejado vulnerables a ciertos tipos de enfermedades. Una visión evolutiva deja de lado la arcaica noción de que el cuerpo es una maquina diseñada y lo toma más bien como un producto de distintas presiones evolutivas a través de un largo periodo de tiempo. Un apéndice, la muela del juicio, un estrecho canal de parto o genes que nos predisponen a distintas enfermedades no tienen sentido bajo el concepto de un diseño (1). Por ejemplo, genes que nos predisponen al aumento de peso o al gusto por las grasas pudieron haber sido útiles en tiempos donde no abundaban los recursos o bien para aprovecharlos mejor. Sin embargo, hoy en día nos producen solo dificultades como la obesidad y la diabetes. Con el surgimiento del secuenciamiento del genoma humano y la mayor cantidad de marcadores moleculares, es posible determinar "señales de selección", que nos permiten conocer qué genes estuvieron seleccionados en las últimas generaciones (5), sean o no ventajosos para el ambiente en que hoy vivimos. Entre las otras áreas que están empezando a utilizar esta aproximación también se encuentran los estudios en desórdenes mentales (6) y en la compresión del envejecimiento (7).
Por su parte, la filogenética - la ciencia de construir y evaluar hipótesis acerca de los patrones históricos de descendencia en forma de árboles evolutivos (8) - ha dejado de ser exclusiva de la taxonomía – la disciplina encargada de clasificar, identificar y nombrar organismos – y ha mostrado ser una herramienta muy práctica con excelentes resultados. Se han utilizado métodos de reconstrucción filogenética para localizar el origen de una enfermedad en particular (9), determinar que cepas poseen mayor posibilidad de propagación en el futuro (10), o para distinguir entre distintos tumores cancerígenos (11). Debido a su importancia en las investigaciones médica y el mayor incremento de esta herramienta en el área, este artículo tiene como objetivo brindar una idea básica de qué son y cómo interpretar los árboles filogenéticos, así los médicos que puedan entender los métodos filogenéticos podrán estar mejor preparados para juzgar la importancia de estas investigaciones en el futuro.
Nociones básicas en filogenia
¿Qué es un árbol filogenético?
En los términos más generales, un árbol filogenético es una representación esquemática de entidades biológicas que están conectadas por descendencia común, pueden ser especies o grupos taxonómicos mayores (8). Hoy en día, la mayoría de árboles filogenéticos se crean a partir de datos moleculares ya sea ADN, ARN o proteínas. Se tiende a usar ADN cuando se analizan especies cercanamente emparentadas, porque proveen mayor información (las cadenas de ADN son más largas que las cadenas de aminoácidos); mientras que las secuencias de aminoácidos son usados para análisis filogenéticos de especies más lejanamente emparentadas (12).
Es importante resaltar que la filogenia tiene orígenes más antiguos. El famoso naturalista Ernst Häckel – un ferviente evolucionista - describía las relaciones entre diferentes organismos en forma de árboles filogenéticos, únicamente a partir de datos morfológicos, inclusive dibujaba estos diagramas como verdaderos árboles (13) y es a partir de sus esquemas, probablemente se acuño el término árbol filogenético.
Aunque para el caso de las investigaciones médicas, los árboles filogenéticos son generados principalmente a partir de datos moleculares, el análisis e interpretación de un árbol es independiente del tipo de datos utilizado para su construcción.
¿Cómo se construye un árbol filogenético?
Los métodos para generar árboles filogenéticos se pueden dividir en dos categorías: los métodos basados en matrices de distancia y los basados en datos de caracteres discretos (14) (los distintos nucleótidos para secuencias de ADN o ARN o aminoácidos para secuencias de proteínas).
De los métodos que utilizan matrices de distancia, el método de Unión de Vecinos (Neighbor-Joining, NJ) es uno de los más usados. Este método (como todos los métodos de distancia), parte de generar una matriz de distancia, que cuando se trabaja con secuencias, se genera al contar las diferencias de nucleótidos entre todos los pares de secuencias. El árbol es luego generado al unir las secuencias que posean la menor cantidad de diferencias o lo que es lo mismo, la menor distancia genética.
Los métodos basados en datos discretos más usados, son tres: a) Máxima Parsimonia (MP), b) Máxima Verosimilitud (o Maximum Likelihood, ML), y c) Inferencia Bayesiana. El método de MP, trata de elegir un árbol que pueda explicar las diferencias en las secuencias observadas utilizando el menor número de cambios. Para ello, genera secuencias ancestrales, secuencias que puedan dar origen a las secuencias observadas, y asigna diferentes puntajes a los distintos árboles formados. El puntaje de cada árbol es simplemente el número de mutaciones que son necesarias para dar origen a las secuencias. El árbol que contenga el menor puntaje, se le conoce como el árbol más parsimonioso, ya que necesita menos cambios para explicar el origen de todas las secuencias.
En el método de Máxima Verosimilitud, el principio es tratar de encontrar un árbol que explique las relaciones entre las diferentes secuencias con la mayor probabilidad (14). Para eso, utiliza un modelo evolutivo y cambiando sus parámetros, por ejemplo modificando la topología (el orden de las ramas), la longitud de las ramas e incluyendo diferentes probabilidades de sustituciones, encuentra la mayor verosimilitud para un árbol dado. Luego, lo altera (por ejemplo moviendo una rama y colocándola en otro sitio), y vuelve a modificar sus parámetros hasta encontrar un árbol que no se pueda modificar o aumentar su verosimilitud, es decir haber encontrado un árbol con la máxima verosimilitud.
El método de la Inferencia Bayesiana, es conceptualmente muy parecido al de la Máxima Verosimilitud. En ambos casos, se exploran los posibles árboles, moviéndose de un árbol a otro al cambiar los parámetros del modelo (la topología, la longitud de las ramas, la tasa de sustitución) y calculando la verosimilitud de cada árbol (15); pero una de las diferencias fundamentales entre ambos es que la Inferencia Bayesiana incluye una probabilidad a priori, es decir incluye una probabilidad para cada hipótesis (los valores de los parámetros), sin tener en cuenta las secuencias. De esta manera la hipótesis óptima (el árbol elegido) es la que maximiza la probabilidad a posteriori, siendo esta la verosimilitud multiplicada por la probabilidad a priori (16). Además, la Inferencia Bayesiana, tiene una forma distinta de explorar los posibles árboles y calcular la probabilidad a posteriori utilizando un algoritmo llamado Montecarlo basado en Cadenas de Markov (Markov Chain Monte Carlo, MCMC) (17).
Cada método de reconstrucción filogenética posee ventajas y limitaciones, hasta ahora existe un gran debate de cuál es el óptimo. Como este tema está fuera del alcance de esta revisión, nos centraremos en la comprensión e interpretación de los árboles filogenéticos. Para ver una aproximación más detallada acerca de los distintos métodos utilizados en reconstrucción filogenética se recomienda consultar a Hillis (18) o Felsenstein (19).
Anatomía de un árbol filogenético
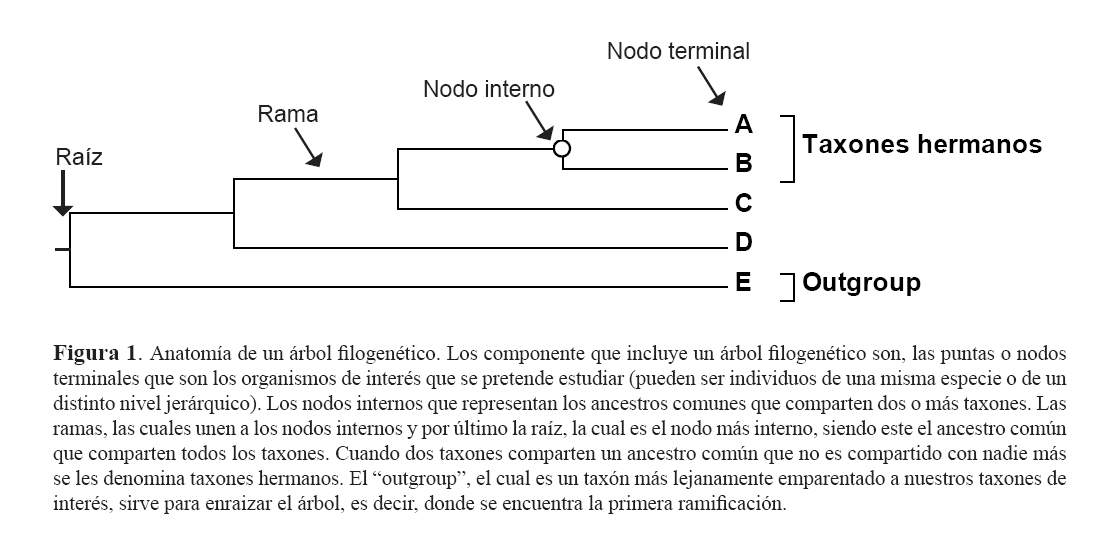
Un árbol filogenético contiene varios componentes. En la parte de la derecha de la figura 1 se encuentran los nodos terminales o puntas, que representan las Unidades Taxonómicas Operativas (OTUS) o taxones. Estas pueden ser individuos de una especie o grupos taxonómicos mayores. Cada uno de estos nodos terminales se encuentran unidos mediante ramas a un nodo interno, el cual representa al ancestro común entre los nodos terminales. De tal manera que los nodos terminales representan el presente, mientras que los nodos internos representan el pasado.
La importancia de un árbol filogenético yace en la topología, es decir, cómo están unidas las ramas o el patrón de ramificación, lo que representa la relación evolutiva entre los distintos taxones. En el caso de la figura 1, a los taxones A y B, se les denomina taxones hermanos, ya que comparten un reciente ancestro común, y que no lo comparten con otro. Al taxón F, se le denomina "outgroup", que se encuentra emparentado más lejanamente a los otros taxones, llamados "ingroup". Los outgroups sirven para enraizar el árbol, es decir para indicar el comienzo del proceso de ramificación, señalando así el nodo más interno compartido por todos, la raíz.
Entendiendo árboles filogenéticos
Por definición, mientras más ancestros comunes compartan dos taxones en exclusión de otros, se encuentran más cercanamente emparentados (8). En la figura 1, los taxones A y B se encuentran emparentados más cercanamente al taxón C que al D, ya que comparten tres ancestros (o nodos internos), mientras que con D comparten tan solo dos. Es importante notar que, tanto C, como A y B se encuentran igualmente emparentados a D. El hecho que C se encuentre más "cerca" a D en el árbol, no significa que filogenéticamente se encuentre más emparentado (basta solo con contar los nodos internos como lo acabamos de hacer). Para utilizar un ejemplo práctico, imaginémonos que el taxón A es la especie humana, el taxón B los chimpancés (puede ser cualquiera, el chimpancé común o el bonobo, el chimpancé pigmeo) y la especie C, el gorila; entonces, filogenéticamente, cualquier humano o cualquier chimpancé se encontrará igualmente emparentado al gorila, a pesar de las diferencias morfológicas que uno pueda encontrar.
Otro aspecto importante a tomar en cuenta al analizar los árboles filogenéticos es que no importa la manera que se encuentren ordenados los taxones en las puntas de los árboles, siempre y cuando se respete la topología (el patrón de ramificación). La figura 2, muestra el mismo árbol filogenético que la figura 1, a pesar que los taxones en las puntas se encuentren en un orden distinto. Nótese que, los taxones A y B son taxones hermanos (no comparten un ancestro común con alguien más) y que cada uno se encuentra igualmente emparentado al taxón C que cualquiera de los dos al taxón D, a pesar que en las puntas, estos se encuentran más juntos a él. Esto se puede comprobar simplemente volviendo a contar el número de ancestros comunes (o nodos internos) que comparten.
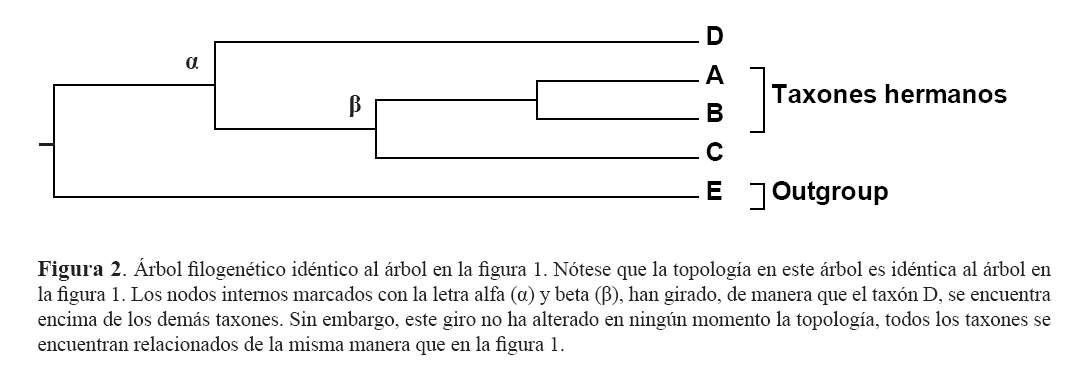
Para ayudar a comprender mejor esta idea, basta con imaginarse a los árboles filogenéticos no como representaciones en dos dimensiones sino en tres. Lo que ocurrió en la figura 2, fue que el nodo que une a los taxones A, B y C con el taxón D (representado con la letra alfa, α) y el nodo que une a A y B con C (representado con la letra beta, β), giraron sobre su propio eje, de manera que D, se encuentra ahora encima de estos; pero este giro, en ningϊn momento alterσ la topología del árbol, lo que hace que el árbol en la figura 1 sea exactamente el mismo que la figura 2. Para hacerlo más sencillo, imaginemos que giramos al nodo que une a los taxones A y B en la figura 1 ó 2; no importa en qué orden queden al girarlos, siempre serán taxones hermanos.
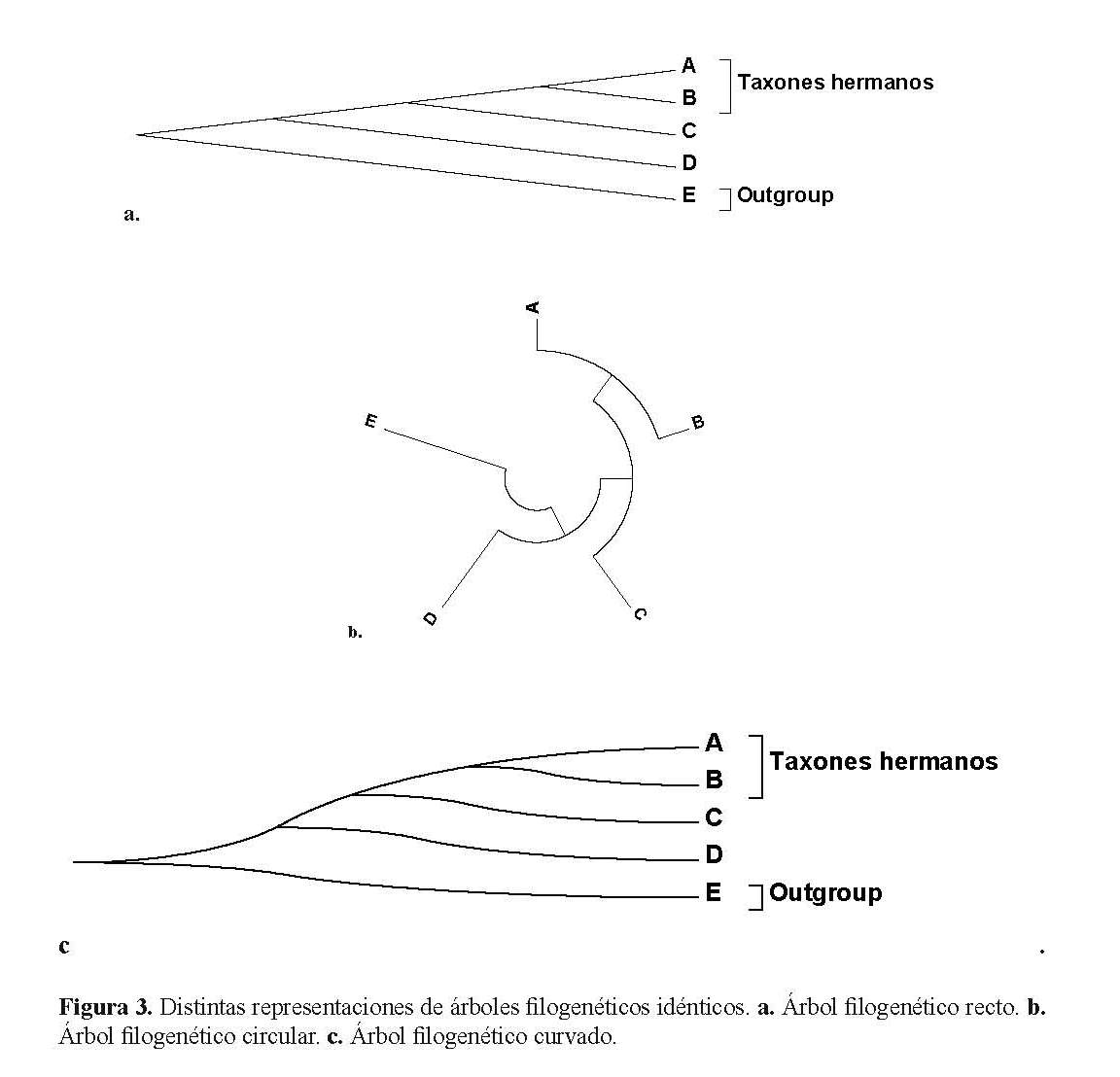
Por último, los árboles filogenéticos no pueden ser representados únicamente de esta forma tradicional que se le denomina árbol rectangular (recuerden que Häckel los representaba inclusive como verdaderos árboles). Los árboles pueden representarse de distintas maneras, pero respetando la topología. La figura 3 muestra tres árboles exactamente iguales. La figura 3 muestra a: un árbol recto, b: un árbol en círculo y c: un árbol curvado.
Ejemplos del uso de la filogenética en investigaciones médicas
La epidemiología
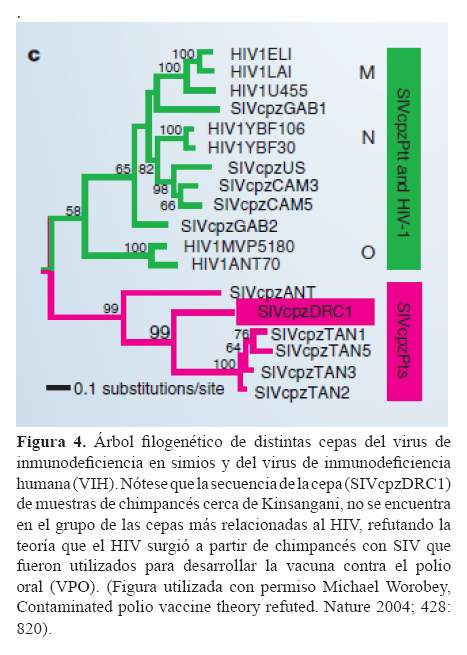
Una de las investigaciones más importantes en la epidemiología molecular en los últimos años, ha sido las relacionadas con el origen del virus de inmunodeficiencia humana (VIH)(20-25). Sin embargo, a pesar de la amplia evidencia que sostiene que el VIH pasó a la especie humana por zoonosis (contagio por animales), existe controversia acerca de su aceptación tanto en la comunidad laica como en la científica. Gran parte de la controversia se debe a la teoría postulada por Hooper (26), un periodista británico que sostiene que los chimpancés que habitan cerca de Kinsangani en la República Democrática del Congo, fueron portadores del virus de la inmunodeficiencia en simios (SIV por sus siglas en inglés) que fue transmitido a los humanos, cuando se usaron sus riñones para desarrollar la vacuna contra la polio oral. Una pequeña comunicación de Worobey et al, en el 2004 (27), parece por fin refutar por completo esta teoría. Ellos identificaron una cepa circulante del síndrome de inmunodeficiencia en simios en muestras fecales de chimpancés que habitan cerca de Kisangani, cuyas secuencias amplificadas (que llamaron SIVcpzDRC1), mostraron un mayor parentesco con otras cepas de SIV que están infectando a otros chimpancés (a la especie Pan troglodytes schweinfurthii en particular) y que se encuentran fuera de las agrupaciones de cepas del SIV que afectan a otra subespecie de chimpancé (Pan troglodytes troglodytes) más relacionadas al VIH.
En la figura 4, se muestra claramente estas relaciones: La nueva cepa SIVcpzDRC1 se agrupa con las cepas SIVcpzTAN y SIVcpzANT, las cuales forman una agrupación distinta de las cepas de SIV (SIVcpzGAB, SIVcpzUS y SIVcpzCAM), más emparentadas al VIH. Si los chimpancés cerca de Kinsangani, hubieran sido los portadores del virus que mutó y que ahora afecta a los humanos, la cepa encontrada se encontraría más cercanamente relacionada a los VIH, es decir compartirían más ancestros comunes, y no sólo compartirían la raíz en este árbol. Por lo tanto, el estudio de Worobey et al., refuta completamente la teoría del VPO/SIDA y más bien apoya la noción más aceptada que el SIV fue transmitido en varias ocasiones y en distintos lugares a los humanos (diferentes cepas de SIV se encuentran más cercanamente emparentadas a diferentes cepas de HIV).
Identificación de mutaciones asociadas a enfermedades
Cuando se trata de buscar un gen que confiera o predisponga a una enfermedad, la aproximación clásica es mediante estudios de asociación genética. Estos, buscan relacionar un marcador genético particular con una enfermedad (o un rasgo complejo) a través de una población o dentro de familias (28). En el caso de trabajar con una población, diseño conocido como de caso-control, las frecuencias de los alelos o del genotipo en el sitio de interés, son comparadas entre individuos con el rasgo de interés (caso) y sin el rasgo (control). Una mayor frecuencia en los casos se toma como evidencia que el alelo o el genotipo está asociado a un mayor riesgo de susceptibilidad o predisposición a la enfermedad (29).
En el gen BRCA1 (Breast cáncer-1), un gen supresor de tumores, se han identificado varias mutaciones que confieren susceptibilidad a desarrollar cáncer de mama. Casi la mitad de las mutaciones reportadas, son cambios en el marco de lectura (alterando la traducción a proteínas) por lo que se espera encontrar una asociación con la enfermedad; mientras que las mutaciones restantes son del tipo cambio de sentido (la mutación origina un solo cambio de aminoácido) (30). Asociaciones de susceptibilidad a estos últimos tipos de mutaciones han sido encontradas en pocos estudios (31,32).
La falta de conocimiento acerca de las propiedades estructurales, bioquímicas y funcionales de este gen, hace difícil conocer las consecuencias que las mutaciones de cambio de sentido en este gen puedan ocasionar (33). Ante este problema, Fleming et al. (34), utilizaron una aproximación evolutiva para establecer si las mutaciones de cambio de sentido en este gen conferían o no una mayor susceptibilidad a desarrollar cáncer de mama. Su lógica fue: si las mutaciones se encuentran en regiones evolutivamente conservadas del ADN (las secuencias se mantienen muy similares en distintas especies) o en regiones del ADN que habían sido seleccionadas positivamente (se han encontrado una señal de selección), es más probable que una mutación en esas regiones, confiera mayor susceptibilidad a desarrollar cáncer.
Para esto, realizaron un análisis filogenético utilizando la secuencia del exón 11 del gen BRC1, región que codifica más del 60% de la proteína de 57 mamíferos, de un marsupial, un ave y de un anfibio. Utilizando esta aproximación, identificaron 8 regiones de muy alta conservación de aminoácidos en los mamíferos que también se encontraban altamente conservadas en aves y anfibios. Siete de estas regiones, se encontraban en sitios probables de interacción con proteínas, mientras que la restante posee una función desconocida, pero su conservación inclusive en anfibios sugiere que es importante (34).
También encontraron evidencia de selección positiva actuando en residuos en el dominio de interacción con la proteína RAD51, tanto en humanos como en otros mamíferos, lo que sugiere que esta región se encuentra sufriendo evolución adaptativa. Con esta información, lograron identificar 41 mutaciones de sentido, que probablemente influencian la función del gen, ya que se encontraban en las regiones conservadas o en las regiones que se encontraban sufriendo selección positiva, y que probablemente confieran un grado de susceptibilidad a desarrollar cáncer de mama. Esta información, previamente desconocida permitirá priorizar el estudio de estas mutaciones en el futuro.
CONCLUSIONES
En resumen, la filogenética, la ciencia de construir y evaluar hipótesis acerca de los patrones históricos de descendencia en forma de árboles evolutivos ha mostrado ser una herramienta muy práctica con excelentes resultados en las investigaciones médicas. Este hecho es apoyado por el incremento de las investigaciones que hacen uso de esta aproximación. Un árbol filogenético (resultado de un análisis filogenético), es una representación esquemática de entidades biológicas que están conectadas por descendencia común, pueden ser especies o grupos taxonómicos mayores. Su análisis e interpretación es independiente del tipo de datos (morfológico o molecular) utilizado para su construcción. Mientras más ancestros comunes compartan dos taxones en exclusión de otros, estos se encontrarán más cercanamente emparentados. No importa la manera que se encuentren ordenados los taxones en las puntas de los árboles o de qué manera este representado (recto, circular o curvado), siempre y cuando se respete la topología (el patrón de ramificación), el árbol filogenético será el mismo.
Es importante mencionar, que este artículo muestra tan solo una pequeña parte de las investigaciones desarrolladas, pero las opciones para nuevas investigaciones son amplias. Sin embargo, son aún pocos los médicos que poseen la información o experiencia necesaria para comprender estas investigaciones. La situación se muestra alarmante en países como Estados Unidos o Inglaterra, en donde varios alumnos de medicina no aceptan la teoría de evolución, no obstante en estos países ya se ha empezado a discutir acerca de un cambio en el currículo en donde se incluya por lo menos un curso básico de evolución.
Ya sea utilizando la genética evolutiva para descubrir porque existen genes que nos predispongan a enfermedades, la filogenética para descubrir el origen de un alimento contaminado, o el origen de una enfermedad que mata más de 40 millones de personas al año, la conclusión seguirá siendo la misma: médicos con un conocimiento más profundo de la evolución del cuerpo humano y de las enfermedades, estarán mejor preparados para juzgar las nuevas investigaciones o bien para llevar sus propias investigaciones.
Aunque comprendiendo la evolución del cuerpo humano y de las enfermedades no tengan una aplicación en la práctica clínica dado que ningún médico debería guiarse por teorías o experimentos que aun no hayan sido probados bajo un riguroso estudio controlado, sin embargo, lo que la biología evolutiva puede ofrecer en la clínica del día a día es una manera de organizar racionalmente toda la información que uno posee, porque la evolución no es solo una teoría, es la teoría unificadora de toda la vida y eso incluye también todo lo que hay dentro de ella.
REFERENCIAS BIBLIOGRÁFICAS
1. Nesse RM, Stearns SC. The great opportunity: Evolutionary applications to medicine and public health. Evolutionary Applications. 2008; 1: 28–48. [ Links ]
2. Restif O. Evolutionary epidemiology 20 years on: challenges and prospects. Infect Genet Evol. 2009; 9 (1): 108-23. [ Links ]
3. Greaves MF. Cancer: The Evolutionary Legacy. New York: Oxford University Press; 2000. [ Links ]
4. Greaves M. Cancer causation: the Darwinian downside of past success? The Lancet Oncology. 2002; 3:244–251. [ Links ]
5. Olson, S. Population genetics. Seeking the signs of selection. Science. 2002; 298:1324–1325. [ Links ]
6. Badcock, C, Crespi B. Imbalanced genomic imprinting in development: an evolutionary basis for the aetiology of autism. Journal of Evolutionary Biology. 2006; 19:1007–1032. [ Links ]
7. Finch CE. The Biology of Human Longevity: Inflammation, Nutrition, and Aging in the Evolution of Lifespans. Boston: Academic Press; 2007. [ Links ]
8. Gregory TR. Understanding evolutionary trees. Evolution: Education and Outreach 2008; 1: 121-137. [ Links ]
9. Heeney JL, Dalgleish AG, Weiss RA. Origins of HIV and the evolution of resistance to aids. Science. 2006; 13:462–466. [ Links ]
10. Smith D. Predictability and preparedness in influenza control. Science. 2006; 312:392–394. [ Links ]
11. Abu-Asab, M, Chaouchi M, Amri H. Phyloproteomics: what phylogenetic analysis reveals about serum proteomics. Journal of Proteome Research. 2006; 5: 2236–2240. [ Links ]
12. Simmons MP, Freudenstein JV. Artifacts of coding amino acids and other composite characters for phylogenetic analysis. Cladistics. 2002; 18: 354– 365. [ Links ]
13. Häckel E. Generelle Morphologie der Organismen: allgemeine Grundzüge der organischen Formen- Wissenschaft, mechanisch begründet dürch die von C. Darwin reformirte Decendenz-Theorie. Berlin. 1866. [ Links ]
14. Michu E. A short guide to phylogeny reconstruction. Plant soil environ. 2007; 53 (10): 442–446. [ Links ]
15. Bromham L. Reading the story in DNA: a beginners guide to molecular evolution. Oxford: Oxford University Press; 2008. [ Links ]
16. Holder MT, Lewis PO. Phylogeny Estimation: Traditional and Bayesian Approaches. Nature Reviews Genetics. 2003; 43:275-284. [ Links ]
17. Gilks WR, Richardson S, Spiegelhalter DJ. Markov Chain Monte Carlo in practice. London: Chapman & Hall; 1996. [ Links ]
18. Hillis DM, Mortiz C, Mable BK. Molecular systematics. 2nd edit. Sunderland MA: Sinauer Associates; 1996. [ Links ]
19. Felsenstein, J. Inferring Phylogenies. Sunderland MA: Sinauer Associates; 2004. [ Links ]
20. Chang SY, Bowman BH, Weiss JB, Garcia RE, White TJ. The origin of HIV-1 isolate HTLV-IIIB Nature. 1993: 363 (6428): 466–9. [ Links ]
21. Zhu T, Korber BT, Nahmias AJ, Hooper E, Sharp PM, Ho DD. An African HIV-1 Sequence from 1959 and Implications for the Origin of the Epidemic. Nature. 1998; 391 (6667): 594–7. [ Links ]
22. Gao F, Elizabeth B; Robertson DL, Chen Y; Rodenburg CM, Michael SF, Cummins LB, Arthur LO, et al. Origin of HIV-1 in the chimpanzee Pan troglodytes troglodytes. Nature. 1999; 397 (6718): 436–441. [ Links ]
23. Salemi M. Dating the common ancestor of SIVcpz and HIV-1 group M and the origin of HIV-1 subtypes by using a new method to uncover clock-like molecular evolution. FASEB J. 2000; 15 (2): 276–78. [ Links ]
24. Chitnis A, Rawls D, Moore J. Origin of HIV Type 1 in Colonial French Equatorial Africa? AIDS Res Human Retroviruses. 2000; 16 (1): 5–8. [ Links ]
25. Santiago ML, Range F, Keele BF; Li Y, Bailes E, Bibollet-Ruche F, Fruteau C, Noe R, et al. Simian Immunodeficiency Virus Infection in Free-Ranging Sooty Mangabeys (Cercocebus atys atys) from the Tai Forest, Cote dIvoire: Implications for the Origin of Epidemic Human Immunodeficiency Virus Type 2. J Virol. 2005; 79 (19): 12515–27. [ Links ]
26. Hooper E. The river: a journey to the source of HIV and AIDS. Boston, MA : Little, Brown and Co; 1999. [ Links ]
27. Worobey M, Santiago ML, Keele BF, Ndjango J-BN, Joy JB, Labama BL, Dheda BD, Rambaut A, Sharp PM, Shaw GM, Hahn BH. Contaminated polio vaccine theory refuted. Nature. 2004; 428: 820. [ Links ]
28. Sevilla SD. Metodología de los estudios de asociación genética. Rev Insuf Cardiaca. 2007; 2(3):111-114. [ Links ]
29. Hirschhorn JN, Lohmueller K, Byrne E. A comprehensive review of genetic association studies. Genet Med. 2002; 4 (2): 45-61. [ Links ]
30. Shen D, Vadgama JV. BRCA1 and BRCA2 gene mutation analysis: visit to the Breast Cancer Information Core (BIC). Oncol Res. 1999; 11, 63–69. [ Links ]
31. Monteiro AN, August A, Hanafusa H. Evidence for a transcriptional activation function of BRCA1 C-terminal region. Proc Natl Acad Sci. 1996; 93: 13595–13599. [ Links ]
32. Brzovic PS, Meza JE, King MC, Klevit RE. BRCA1 RING domain cancer-predisposing mutations. Structural consequences and effects on protein- protein interactions. J Biol Chem. 2001; 276 (44): 41399–41406. [ Links ]
33. Collins FS. BRCA1 lots of mutations, lots of dilemmas. N Engl J Med. 1996; 334:186–188. [ Links ]
34. Fleming MA, Potter JD, Ramirez CJ, Ostrander GK, Ostrander EA. Understanding missense mutations in the BRCA1 gene: An evolutionary approach. PNAS. 2003; 100 (3): 1151–1156. [ Links ]
