Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO  uBio
uBio 
 Permalink
PermalinkIntroducción
En el mundo, el déficit de agua es producto del consumo total que se incrementa debido al crecimiento poblacional (Kummu et al., 2016); asimismo, el 78% de agua suministrada a las grandes ciudades proviene de fuentes de agua superficial (lagos, manantiales y ríos) y sus cuencas de drenaje representan el 41% de la superficie terrestre (McDonald et al., 2014). En el Perú, la escasez de agua y variabilidad climática son preocupaciones fundamentales en muchas cuencas, particularmente en las de la vertiente del Pacífico, donde, a pesar de su intensa actividad económica y su alta densidad poblacional, solo cuenta con 1.8% de los recursos hídricos (Alcántara, 2015).
Un caso especial es el río Pisco, cuyo caudal depende de las precipitaciones que ocurren en su cuenca alta y que es importante porque abastece a la principal actividad socio-económica que es la agricultura de exportación ubicada en el valle, dadas sus condiciones favorables de relieve, calidad agrológica de suelos y disponibilidad hídrica (INRENA, 2003).
Las descargas son fundamentales para la gestión de los recursos hídricos como herramienta para la conservación de los ecosistemas, de la biodiversidad y en adaptación al cambio climático (Bussettini, 2018), de allí la importancia de su estudio. Los Servicios Ecosistémicos Hidrológicos (SEH) de provisión son aquellos que las poblaciones obtienen directamente de los ecosistemas, así como de su transformación, tales como el agua, alimentos, madera, leña, medicinas, ornamentos, entre otros (Arellano & Ruiz, 2018).
En los problemas hidrológicos las soluciones se obtienen mediante modelos matemáticos de simulación hidrológica o modelos de series de tiempo que trabajan capturando los patrones en los datos históricos extrapolándolos al futuro (Loucks et al., 2005). Actualmente, se aplican modelos estocásticos en complementar datos climáticos diarios observados, generar series largas de datos sintéticos para el análisis de riesgos y evaluar los posibles efectos a largo plazo de la antropogénesis del cambio climático (Wan et al., 2005).
Los métodos de análisis de series de tiempo consideran el hecho de que los datos tomados en diversos periodos pueden tener algunas características de autocorrelación, tendencia o estacionalidad que se deben tener en cuenta para modelar el comportamiento de la serie observada (Aliaga, 1985). Un modelo es autorregresivo si la variable en el período t es explicada por las observaciones de ella misma correspondiente a períodos anteriores, adicionándose un término de error (Tealab, 2018). Por tanto, la base de los modelos autorregresivos es generar el presente o futuro en función de lo que ha ocurrido en el pasado (Alcántara et al., 2014).
En este trabajo, la hipótesis planteada consideró la posibilidad de modelar estocásticamente las descargas medias anuales del río Pisco a través de un modelo autorregresivo ajustándolas a distribuciones estadísticas teóricas. El objetivo fue simular el comportamiento de las descargas medias anuales del río Pisco a través del análisis de series de tiempo utilizando modelos autorregresivos y ajustarlas a distribuciones teóricas de probabilidad para conocer su disponibilidad como SEH de aprovisionamiento.
Materiales y Métodos
Área de estudio
El estudio se llevó a cabo en la cuenca del río Pisco / Ica / Perú que posee una superficie de drenaje de 4 434.50 Km2 con un 62.70% de cuenca húmeda, siendo la principal fuente de aprovisionamiento hídrico superficial (SEH), con ocurrencia de precipitaciones estacionales. Esta disponibilidad fue evaluada en la sección de control de la estación hidrométrica Letrayoc, y sin considerar aporte de lagunas es 25.91 m3/s como valor medio anual histórico y 14.26 m3/s al 75% de probabilidad de no excedencia (INRENA, 2003).
Análisis de datos y ajuste a un modelo periódico autorregresivo estocástico
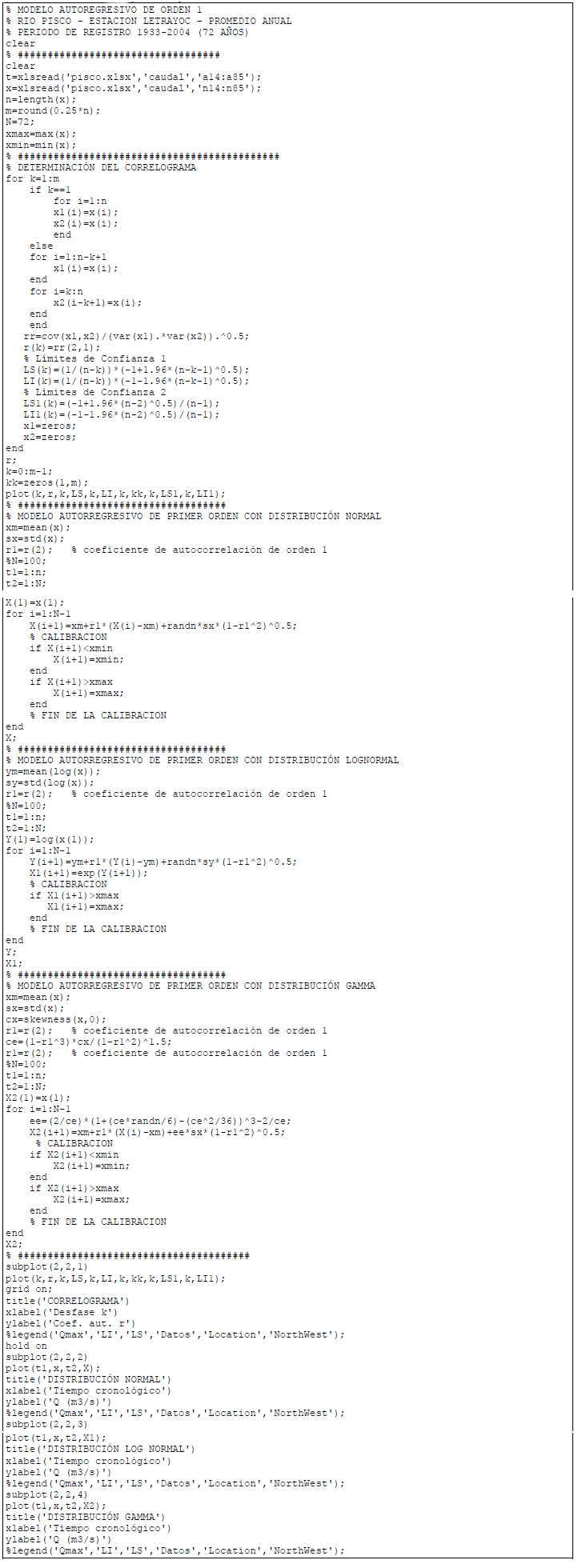
El modelamiento estocástico autorregresivo se aplicó a los datos de descargas medias anuales de la estación Letrayoc ubicada a 13°40’ S, 75°46’ O y 630 msnm. Los datos fueron proporcionados por la ATDR (Administración Técnica de Riego Chincha - Pisco) con una longitud de registro de 72 años (Tabla 1), entre 1933 y 2004. El análisis de las descargas consistió en verificar consistencia, saltos, tendencias y cálculo de los estadísticos: media, máximos, mínimos, desviación estándar, coeficiente de sesgo, coeficiente de variación y coeficientes de correlación (Maidment, 1993). Como programa de cómputo principal se utilizó el MAR1 realizado en MATLAB R2016a, utilizándose programas complementarios como SAMS 2009, Hidroesta y hojas de cálculo Excel.
Tabla 1 Datos de descargas medias anuales del río Pisco en la estación Letrayoc (1933-2004).
| Año | Q (m3/s) | Año | Q (m3/s) | Año | Q (m3/s) | Año | Q (m3/s) |
|---|---|---|---|---|---|---|---|
| 1933 | 33.52 | 1951 | 33.92 | 1969 | 17.33 | 1987 | 16.81 |
| 1934 | 38.86 | 1952 | 28.25 | 1970 | 25.56 | 1988 | 22.98 |
| 1935 | 32.16 | 1953 | 36.34 | 1971 | 24.69 | 1989 | 32.90 |
| 1936 | 25.02 | 1954 | 31.47 | 1972 | 44.80 | 1990 | 6.40 |
| 1937 | 20.81 | 1955 | 34.86 | 1973 | 31.00 | 1991 | 16.56 |
| 1938 | 25.85 | 1956 | 26.79 | 1974 | 24.71 | 1992 | 4.18 |
| 1939 | 35.27 | 1957 | 23.83 | 1975 | 16.52 | 1993 | 22.63 |
| 1940 | 18.32 | 1958 | 14.61 | 1976 | 21.73 | 1994 | 32.24 |
| 1941 | 18.88 | 1959 | 28.36 | 1977 | 17.39 | 1995 | 33.43 |
| 1942 | 22.35 | 1960 | 21.35 | 1978 | 7.80 | 1996 | 26.28 |
| 1943 | 34.01 | 1961 | 41.90 | 1979 | 13.13 | 1997 | 10.87 |
| 1944 | 29.28 | 1962 | 33.13 | 1980 | 8.24 | 1998 | 54.87 |
| 1945 | 24.86 | 1963 | 35.54 | 1981 | 20.58 | 1999 | 26.05 |
| 1946 | 41.27 | 1964 | 15.49 | 1982 | 17.84 | 2000 | 27.85 |
| 1947 | 18.07 | 1965 | 13.25 | 1983 | 15.32 | 2001 | 30.56 |
| 1948 | 32.66 | 1966 | 21.89 | 1984 | 51.68 | 2002 | 28.64 |
| 1949 | 23.22 | 1967 | 51.48 | 1985 | 22.44 | 2003 | 24.97 |
| 1950 | 27.41 | 1968 | 13.93 | 1986 | 41.58 | 2004 | 17.07 |
Por tratarse de una estación, se utilizó un modelo autorregresivo periódico y univariado, calculándose los coeficientes de correlación mensual, graficando y visualizando el correlograma serial, así como la función de autocorrelación para la identificación de la forma del modelo (Del Aguila, 2001). El correlograma serial se graficó para un número de retardos (lags) de N/4, estableciendo los límites de confianza según la Fórmula 1.
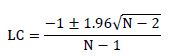
Fórmula 1. Límites de Confianza para el correlograma.
Donde:
LC: límites de confianza;
N: número total de datos.
Los parámetros del modelo utilizado son: (x, ρx,1, ..., ρx,1, y (2ε, y se procesan según la Fórmula 2 (Salas & Yevjevich, 1972) modificada por Mejía (2017).
Xi+1= μx+ρx,1(Xi−μx+εi+1
Fórmula 2. Procesamiento para los parámetros utilizados para el cálculo de la descarga en el año actual.
Donde:
X i+1: descarga en el año actual;
μx: media;
ρx,1: primer coeficiente de autocorrelación;
Xi: descarga del año anterior;
(i+1: variable aleatoria normal no correlativa con media cero y varianza (( 2.
Desarrollo de un código computacional en MATLAB
A través de la opción Modelamiento Matemático / Caja de Herramientas / Matemáticas Simbólicas del MATLAB R2016a, se plantearon los comandos y se definieron secuencialmente las funciones del modelo MAR1- Modelo Autorregresivo de orden 1 (Apéndice 1), basados en la teoría siguiente:
Generación de información de variable ajustada a la distribución normal: siendo X la variable descargas medias anuales, para la generación de información de X con distribución Normal, donde X se distribuye con N (µx, σ2 x), y ε debe ser N (0, σ2ε), según el modelo (Fórmula 2); por lo tanto, valores aleatorios de Xi+1 pueden ser generados tomando valores de εi+1. Si t es una variable aleatoria con N (0,1), entonces tσε = tσx[1-ρ2 X,1]1/2 tiene distribución normal N (0, σ2 ε). Así, el modelo de Markov de primer orden para generar información con (µX, σ2 X) está en la Fórmula 3 (Mejía, 2017).
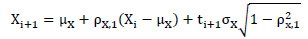
Fórmula 3. Modelo de Markov.
En la generación de información con distribución Log- normal se utiliza el mismo modelo anterior, pero con aplicación de logaritmo natural, transformándose los datos originales (Xi) a (Yi). Los valores de Xi se transforman en Yi = ln (Xi). El modelo de generación Log- normal está dado por la Fórmula 4.
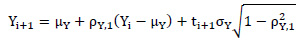
Fórmula 4. Modelo de generación Log- normal.
Donde: µY, σY y ρY,1 representan la media, desviación estándar y coeficiente de correlación serial de primer orden de los logaritmos de los datos originales (Y), respectivamente.
Modelo de generación de información con distribución Gamma: (Thomas & Fiering, 1962) propusieron el modelo de generación Gamma a partir del modelo de Markov de primer orden. El procedimiento consistió en definir Cε como el coeficiente de asimetría de la componente aleatoria ε y pudo ser estimado por la Fórmula 5 (Mejía, 2017).
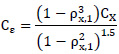
Fórmula 5. Coeficiente de Asimetría de ε (Mejía, 2017).
Donde:
ρx,1 y CX son los coeficientes de correlación serial de primer orden y de asimetría, respectivamente, para los datos originales.
El elemento aleatorio εi+1 está definido según la Fórmula 6.
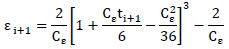
Fórmula 6. Cálculo del elemento aleatorio εi+1.
Donde:
ti+1: Valor aleatorio con N (0,1).
Xi+1 puede ser generado de acuerdo a la Fórmula 7.
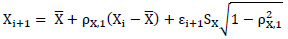
Fórmula 7. Generación de Xi+1.
Bondad de ajuste, simulación de descargas y calibración del modelo
Para probar la bondad de ajuste del modelo MAR1 se utilizó el estadístico de Kolmogorov Smirnov, donde las hipótesis a contrastar fueron las siguientes:
H0: Las descargas anuales del río Pisco siguen una distribución Normal / Log-normal / Gamma
H1: Las descargas anuales del río Pisco NO siguen una distribución Normal / Log-normal / Gamma.
El estadístico de contraste de la prueba está dado por la Fórmula 8.
Dn= máx |P(x) – P0 (x)|
Fórmula 8. Contraste de la máxima discrepancia.
Donde:
P(x): frecuencia teórica relativa;
P0(x): frecuencia observada relativa; y,
Dn: máxima discrepancia de P(x) y P0(x). Este valor se compara con el valor tabular de la distribución que se está probando, con un α predeterminado de 0.05.
Se calculó el coeficiente de parsimonia (CP) para el MAR1, con la Fórmula 9 (Aliaga, 1985).

Fórmula 9. Coeficiente de Parsimonia (CP) para el MAR1.
Se simularon 10 series se descargas medias anuales del río Pisco con el modelo MAR1 ajustadas a la distribución Normal, Log-normal y Gamma, respectivamente. Para verificar la distribución con mejor ajuste por cada simulación se realizó la cuantificación de la raíz del menor error medio cuadrático (RMEC) y el criterio de Schultz con las Fórmulas 10 y 11, respectivamente.
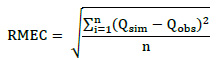
Fórmula 10. Raíz del Menor Error Medio Cuadrático (RMEC).
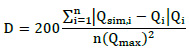
Fórmula 11. Criterio de Schultz para verificar la distribución con mejor ajuste por cada simulación.
Para la calibración se utilizaron las pruebas de comparación estadística entre medias y desviaciones estándar de la serie original (histórica) y de las series simuladas, bajo la hipótesis de que ambas - histórica y simuladas - son estadísticamente iguales, con un nivel de significancia de ( = 0.05. Se utilizó la prueba T de Student para la media y la prueba F de Fisher para la desviación estándar. También se realizó la comparación gráfica entre los estadísticos de las descargas históricas y generadas.
Resultados y discusión
Las descargas medias anuales del río Pisco de una longitud de registro de 72 años resultaron consistentes a través del método estadístico: prueba T para la media y prueba F para la desviación estándar. El promedio máximo y mínimo fue 54.87 m3/s y 4.18 m3/s en los años 1998 y 1992, respectivamente; desviación estándar de 10.48 m3/s; coeficiente de variación 0.4015 y coeficiente de sesgo igual a 0.4564.
Del análisis de la serie de tiempo de la Figura 1 se puede ver que los valores máximos corresponden a los megas fenómenos del Niño ocurridos en la costa peruana los años 1967, 1984 y 1998.
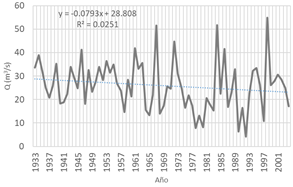
Respecto al correlograma de la Figura 2, no podemos afirmar que las descargas presentan estructura de dependencia, porque los valores se encuentran dentro del intervalo de confianza (LCsup = 0.217, LCinf = - 0.245); sin embargo, dentro del ámbito del análisis de caudales anuales, la autocorrelación de retardo uno es la más frecuente y con ella es suficiente para expresar la dependencia serial de los datos (Salas et al., 1997), con el adicional de cumplir con el principio estadístico de la parsimonia de parámetros. La cantidad de parámetros para el MAR1 anual es 3, siendo el número de datos 72 resultó un coeficiente de parsimonia de 24, mayor al número mínimo que es 15 (Aliaga, 1985). Según la literatura, es deseable la simplicidad, por lo que la orden del modelo y el número de parámetros debe ser pequeño (Roldán, 1994).
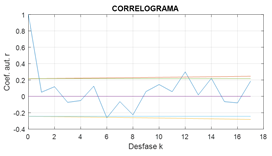
El código matemático de formulación del programa MAR1 - Modelo Autorregresivo de Orden 1 (Apéndice 1) con una longitud de registro simulado de 72 años, fue utilizado para la generación de 10 series sintéticas (con motivo de comparación); dicho programa permite graficar las salidas en cantidad ilimitada de veces y sus resultados tabularlos en hoja de cálculo Excel. Se confirmó la hipótesis de que es posible modelar estocásticamente las descargas medias anuales del río Pisco a través de un modelo autorregresivo tal como Obregón (1993), quien aplicó con éxito modelos autorregresivos en descargas medias mensuales del río Pisco en el período 1974 a 1988.
La metodología utilizada en este trabajo evidencia que las descargas anuales simuladas son estadísticamente iguales a las históricas, tal como lo reportaron Quispe et al. (2017) para el caso del río Ramis en Puno, Perú. Gráficamente, las descargas medias anuales del río Pisco ajustadas a la distribución Normal, Log-normal y Gamma con el programa MAR1 muestran un comportamiento estadísticamente igual a las descargas medias históricas observadas en el río Pisco basado en el análisis de la serie de tiempo de memoria larga (Figura 3).
Cuantitativamente, el ajuste a la distribución Gamma es el más conveniente, con base al análisis de la raíz del menor error medio cuadrático (RMEC = 11.03) y al criterio de Schultz (D = 15.44, suficiente) (Tabla 2).
Tabla 2 Estadísticos principales de las series observadas y simuladas con MAR1.
| Estadístico | Q obs. | Q sim. D. Normal* | Q sim. D. Log-normal* | Q sim. D. Gamma* |
|---|---|---|---|---|
| Promedio | 25.91 | 26.12 | 25.18 | 26.28 |
| Desviación Est. | 10.48 | 3.58 | 4.69 | 3.43 |
| Varianza | 109.78 | 12.80 | 22.01 | 11.74 |
| Máximo | 54.87 | 35.04 | 35.13 | 33.57 |
| Mínimo | 4.18 | 16.90 | 0.00 | 19.74 |
| n | 72 | 72 | 72 | 72 |
| D (Schultz) | 15.89 | 16.95 | 15.44 | |
| RMEC | 11.11 | 11.80 | 11.03 | |
| * Caudales promedio de las 10 simulaciones realizadas. |
La ecuación de generación de descargas encontrada para el año promedio en la estación Letrayoc en el río Pisco sirve como técnica hidrológica para extender datos anuales, tal como señala (Alfaro & Soley, 2009) para datos meteorológicos en general, quedando definida según la Fórmula 12.
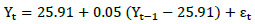
Fórmula 12. Generación de descargas para el año promedio.
Se calibró y validó el modelo autorregresivo de orden 1 del programa MAR1, probándose la independencia y normalidad de los errores a través de la prueba no paramétrica de Kolmogorov Smirnov, con un delta tabular de 0.1603 a un nivel de significancia del 5%.
Respecto de la capacidad de almacenamiento de las aguas del río Pisco (disponibilidad hídrica superficial como Servicio Ecosistémico Hidrológico de aprovisionamiento), se obtuvo una capacidad de almacenamiento simulada de 104.3 Hm3 que es menor a la capacidad observada de 117.7 Hm3 (Tabla 3), que evidencia la tendencia a la disminución de los caudales (pendiente negativa de la recta de la Figura 1). Siendo que los recursos hídricos pueden ser considerados como “productos del ecosistema”, es necesaria su protección y gestión sostenible, para proteger y salvaguardar los recursos hídricos (Bussettini, 2018).
Por último, las herramientas de programación como MATLAB R2016a permiten realizar operaciones matemáticas diversas con relativa facilidad cuyos resultados, acompañados de gráficos, le otorgan una ventaja adicional en el uso de modelos (Moreno & Salazar, 2008).
Tabla 3 Estadísticos de sequía- Resultados del programa SAMS.
| Estadístico | Histórica | Generada |
|---|---|---|
| Sequía más larga (años) | 10 | 6.3 |
| Déficit máximo (%) | 95.88 | 53.33 |
| Superávit más largo (años) | 7 | 5.8 |
| Excedente máximo (Hm3) | 38.4 | 57.25 |
| Capacidad de almacenamiento (Hm3) | 117.7 | 104.3 |
| Coeficiente de Hurst | 0.677 | 0.6382 |
Conclusiones
Se concluye que la utilización de los modelos estocásticos en hidrología aplicados a descargas medias, anuales o mensuales, producen resultados satisfactorios, verificados, en este caso, con la raíz del menor error medio cuadrático (RMEC) como estadístico de bondad de ajuste de modelos. Estos modelos podrían ser utilizados para simular otras condiciones en los ríos, además de ser usados para explicar el cambio climático, como, por ejemplo, los efectos El Niño frente a la costa peruana aplicados a series temporales de temperatura superficial del mar; sin embargo, su uso mayoritario es en la evaluación de los recursos hídricos con fines de gestión. Se ha comprobado que en la cuenca del río Pisco los Servicios Ecosistémicos Hidrológicos (SEH) de aprovisionamiento de agua se están reduciendo, probablemente ante las modificaciones en el clima y un uso descontrolado.
El programa MAR1 en su primera versión puede ser utilizado para modelar datos de descargas mensuales de los ríos de nuestro país con el propósito de servir para la cuantificación de la disponibilidad hídrica superficial de los mismos.