Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1. Introducción
La pandemia generada por el coronavirus COVID-19 llegó a Latinoamérica el 26 de febrero de 2020, cuando Brasil confirmó el primer caso en São Paulo. Luego de un mes, los países de la región cerraron las escuelas y aeropuertos, clausuraron negocios e implementaron un rango de restricciones en un intento por controlar la pandemia. Sin embargo, las estadísticas sugieren que las medidas tomadas fueron poco útiles porque, hasta finales de enero de 2021, se han registrado más de 600.000 muertes por COVID-19 en toda la región1.
El Perú fue uno de los primeros países de América Latina en poner a sus ciudadanos en cuarentena para intentar contener la propagación del coronavirus. El 16 de marzo de 2020, el Gobierno decretó un estado de emergencia sanitaria, cerró las fronteras del país, ordenó que la gente saliera solo para cosas imprescindibles como comprar alimentos y medicamentos, y decretó toques de queda en distintos horarios en todas las ciudades. En un principio, la cuarentena se estableció para un período de dos semanas, pero la situación fue empeorando y se prolongó hasta el 30 de junio de 2020. Sin embargo, a pesar de las medidas tomadas, el Perú es considerado uno de los países más afectados por la pandemia en América Latina. Por ello, diversas investigaciones buscan analizar los efectos de las medidas implementadas por el Gobierno, las variables socioeconómicas y las variables geográficas sobre la gravedad y la propagación del virus (Atalan, 2020; Fernandes et al., 2020; Nguimkeu & Tadadjeu, 2020).
Por un lado, las investigaciones empíricas sugieren que las medidas implementadas por el Gobierno para disminuir el distanciamiento social, tales como las cuarentenas, redujeron significativamente la propagación del coronavirus (Atalan, 2020). Sin embargo, es necesario mencionar que las medidas de distanciamiento social también tuvieron efectos sobre el comportamiento y la psicología de las personas, el medio ambiente y la economía (Atalan, 2020; Wang & Li, 2021).
Por otro lado, los resultados de las investigaciones empíricas indican que algunas variables socioeconómicas se asocian positivamente con el número de infectados por COVID-19. Por ejemplo, Nguimkeu y Tadadjeu (2020), utilizando datos de 182 países, encontraron que la densidad poblacional, la proporción de población de 65 años a más y la urbanización se asocian positivamente con el número de infectados por COVID-19. Los autores también encontraron que el nivel de ingresos de las personas y la calidad de la infraestructura de salud no tienen efectos significativos en la propagación del virus.
De otro lado, los resultados empíricos sugieren que las variables geográficas tienen efectos importantes en la evolución de casos y muertes por COVID-19. Se ha encontrado que la temperatura media tiene una relación negativa con la cantidad de infectados por coronavirus (Nguimkeu & Tadadjeu, 2020). Sin embargo, la altura del territorio es la variable geográfica que ha generado mayor variedad de discusiones teóricas y empíricas. Algunos estudios sugieren que la altura se relaciona negativamente con el número de casos y muertes por COVID-19 (Arias-Reyes et al., 2020; Fernandes et al., 2020). Estos estudios indican que la gran altitud se caracteriza por cambios drásticos de temperatura entre la noche y el día, sequedad del aire y altos niveles de radiación de luz ultravioleta (Arias-Reyes et al., 2020). En particular, la radiación de luz ultravioleta A y B puede producir alteraciones en los enlaces moleculares del ADN y el ARN y, por lo tanto, la radiación ultravioleta a gran altitud puede actuar como un desinfectante natural (Andrade, 2020; Zubieta-Calleja, 2020; Zubieta-Calleja & Zubieta- DeUrioste, 2017). Otros estudios indican que todavía es prematuro llegar a la conclusión de los impactos de las grandes altitudes sobre la gravedad y progresión de la pandemia sin una evaluación de otros factores sociales, demográficos y factores de riesgo o variables de salud (Huamaní et al., 2020).
La comprensión de los diferentes factores que están determinando la evolución de muertes por COVID-19 podría ser clave para diseñar políticas de prevención para evitar grandes pérdidas económicas y sociales en esta y futuras pandemias. De hecho, en un estudio sobre las epidemias en el Perú, García Cáceres (2002) indica que la cuarentena que se decretó en 1833, ante la llegada del cólera asiático, probó ser eficaz para la realidad peruana porque el arenal sulfuroso del desierto costero constituyó una barrera natural que limitó el viaje del cólera, de un oasis a otro, desde Tumbes a Tarapacá. Esto implica que un enfermo de cólera en Paita no podría esparcir esa enfermedad a las ciudades vecinas porque el desierto, con sus arenas sulfurosas, impedía una rápida propagación de una población a otra o de un valle a otro. Por lo tanto, las políticas que se implementen ante determinadas epidemias deben considerar las barreras naturales que ofrece la geografía del país.
En este sentido, esta investigación busca contribuir a la literatura sobre los determinantes de los casos y muertes por COVID-19 en el Perú; en específico, el rol de la movilidad de las personas -entendida como el desplazamiento y medida por la proporción de personas que recorren más de un kilómetro en un día-, la geografía y el desarrollo económico. Para ello, utilizamos regresiones de Poisson con efectos aleatorios y datos de cuatro grupos de variables a nivel de distritos: (1) COVID-19, (2) movilidad de las personas, (3) variables geográficas y (4) variables socioeconómicas.
Entre los principales resultados, encontramos que la movilidad de las personas tiene una relación negativa con la probabilidad de acumular casos y muertes de COVID-19 hasta la novena semana de pandemia, pero tiene una relación positiva a partir de la decimoprimera semana. También encontramos que las variables socioeconómicas como el PIB per cápita y la esperanza de vida tienen asociaciones positivas con la probabilidad de acumular casos y muertes de COVID-19, mientras que las variables geográficas, como la altura y la pendiente del territorio, tienen asociaciones negativas. Los resultados también indican que el rol de las variables geográficas y socioeconómicas depende de la inclusión de Lima en el análisis empírico.
El resto del documento está estructurado de la siguiente manera. En la segunda sección, se discutirán los detalles de los datos y de la metodología utilizada para el análisis. En la tercera y la cuarta sección, se presentarán los resultados encontrados. Por último, en la quinta y la sexta sección, se darán a conocer las conclusiones, limitaciones y futuras líneas de investigación.
2. Datos y metodología
2.1 Datos
En esta investigación, usamos cuatro grupos de variables: (1) COVID-19, (2) movilidad, (3) geográficas y (4) socioeconómicas.
COVID-19
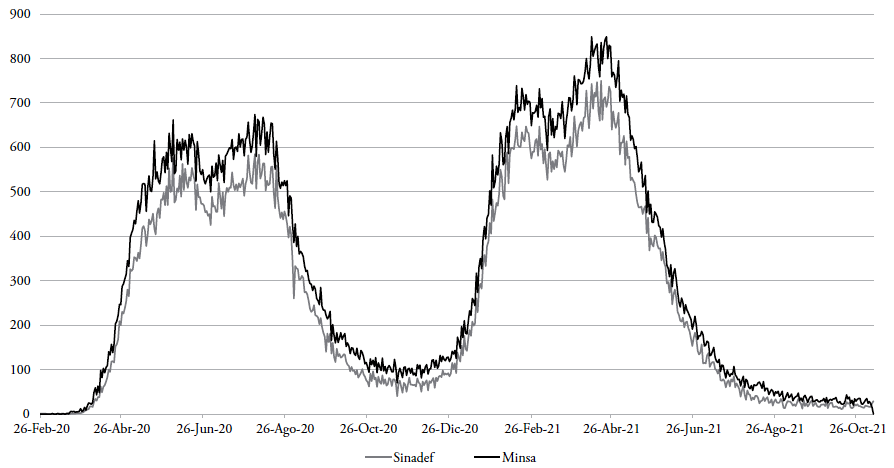
En este grupo se incorpora el número de casos y muertes por COVID-19. La información de casos y muertes es generada por el Ministerio de Salud del Perú (Minsa)2. La información de muertes también es proporcionada por el Sistema Informático Nacional de Defunciones (Sinadef)3. Sin embargo, incluso con la información actualizada, encontramos diferencias cuando comparamos la información de muertes del Minsa con la del Sinadef (véase el anexo 1). Asimismo, en la información actualizada del Minsa, encontramos presencia de muertes antes que casos por COVID-19. Al respecto, el equipo encargado de actualizar la información del Minsa indicó lo siguiente:
Cuando ocurre una epidemia no es infrecuente que los primeros casos que se diagnostican en los servicios de salud, y que se hacen públicos, no sean realmente los primeros que ocurren, más aún al tratarse de una enfermedad nueva cuyas manifestaciones clínicas pueden confundirse con otras entidades y evolucionar rápidamente hasta el deceso. La vigilancia epidemiológica y el análisis retrospectivo de los casos y de las defunciones permiten identificar algunos casos (generalmente muy pocos) que pueden haberse presentado antes y que permiten tener una idea más clara de la trasmisión de la enfermedad. Como se dijo al principio, no es raro que ello ocurra en todos los países y no solo para COVID-194.
Las estadísticas del Minsa indican que el número de casos en el Perú comienza el 6 de marzo de 2020, día que se detectó el primer paciente positivo por coronavirus, mientras que las estadísticas actualizadas del número de muertes indican que el primer deceso por COVID-19 se produjo el 3 de marzo.
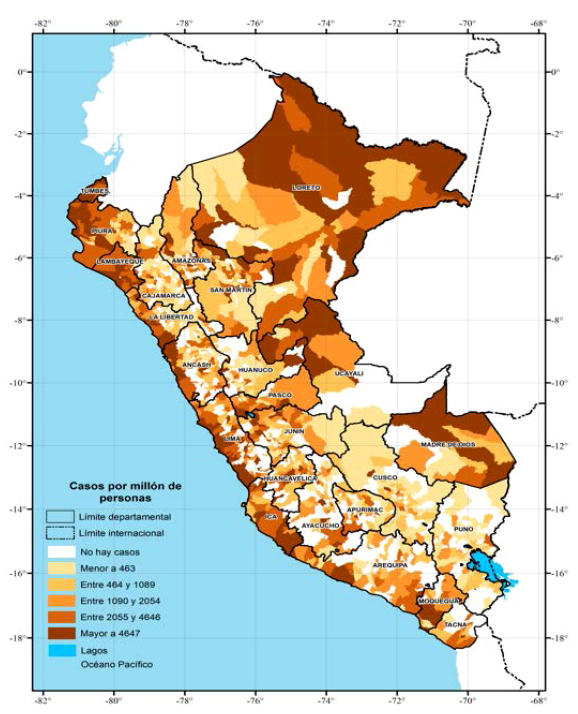
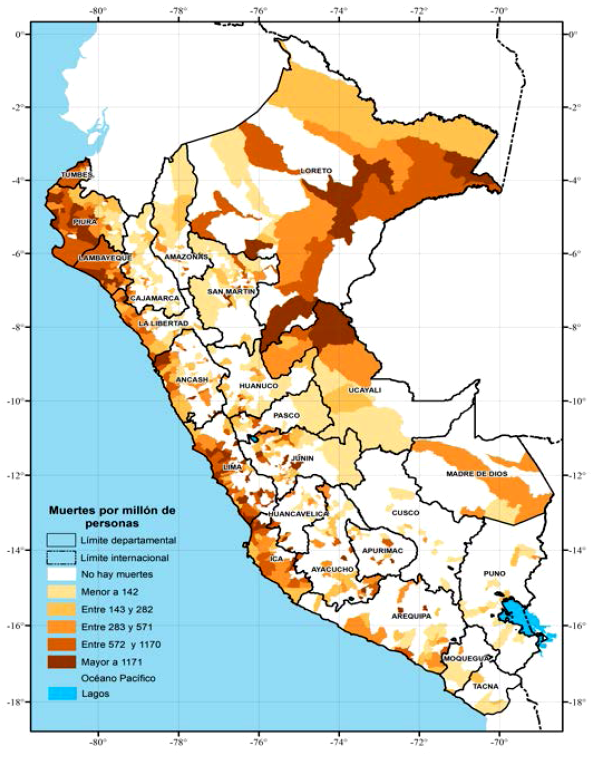
En las figuras 1 y 2, mostramos grupos de distritos según la cantidad acumulada de casos y muertes por millón de personas provocadas por COVID-19. En estas figuras, los colores más oscuros corresponden a los distritos que concentran la mayor cantidad acumulada de casos y muertes por millón de personas, y el color blanco corresponde a los distritos que no tienen información. Las estadísticas de estas figuras sugieren que los distritos ubicados a lo largo de la Costa del país son aquellos que concentran la mayor cantidad de casos y muertes por millón de personas. En las figuras, también observamos que en la Selva (yunga fluvial, selva alta y selva baja) se localizan distritos que concentran gran cantidad de casos por COVID-19. En las figuras, podemos observar que los distritos que tienen selva y tienen gran cantidad de muertes por millón de personas corresponden a las capitales departamentales o se localizan alrededor de estas, tales como Iquitos en el departamento de Loreto, Puerto Maldonado en el departamento de Madre de Dios y Pucallpa en el departamento de Ucayali. Las figuras también indican que los distritos ubicados en la Sierra (quechua, suni, puna y janca) son aquellos que tienen la menor cantidad de casos y muertes por millón de personas. También observamos que la Sierra es la región con mayor cantidad de distritos que no han registrado muertes por COVID-19.
Movilidad
En este grupo se incorpora la medida de movilidad de las personas, y los datos han sido provistos por el Banco Interamericano de Desarrollo (BID) para el período 06/marzo/20 - 14/junio/205. El indicador que usamos como movilidad de las personas corresponde a la proporción de personas que recorren más de un kilómetro en un día, el cual se ha construido usando datos georreferenciados de teléfonos celulares. Para más detalles sobre los datos de movilidad de las personas generados por el BID para 22 países de Latinoamérica, véase Aromí et al. (2020, 2021).
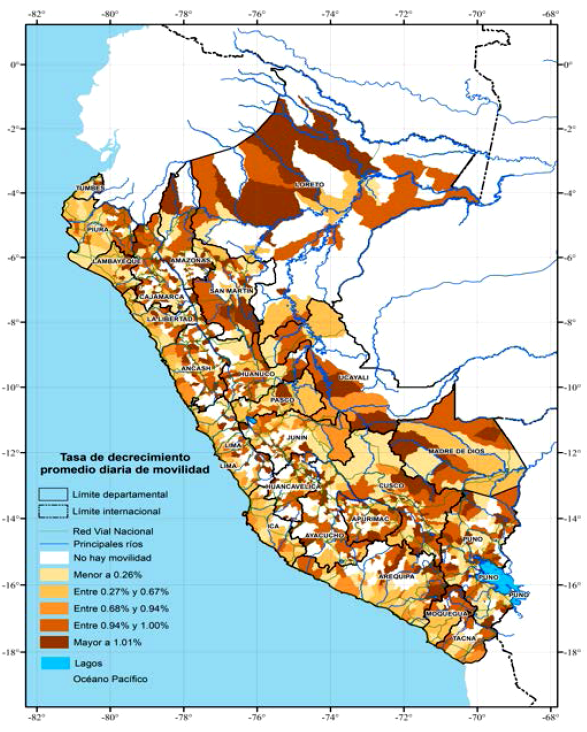
En la figura 3, mostramos la tasa de disminución promedio diaria de la movilidad de las personas. En esta figura, el color más oscuro representa a los distritos que más disminuyeron la movilidad de las personas, mientras que el color más claro corresponde a los distritos con las menores tasas de disminución de la movilidad de las personas. En esta figura, también mostramos la red vial nacional, de color verde, con el objetivo de ver si existe alguna relación espacial entre la movilidad de las personas y las vías de comunicación. Las estadísticas de la figura sugieren que los distritos de la Costa son aquellos que menos disminuyeron la movilidad de las personas, y lo mismo ocurre con los distritos que corresponden a las capitales departamentales o a las principales ciudades de las regiones. En esta figura, también observamos que algunos distritos de la Sierra, donde se juntan varios ramales de la red vial nacional de comunicación terrestre, pertenecen al grupo con altas tasas de decrecimiento promedio diario de la movilidad de las personas. Estos resultados sugieren que las políticas de distanciamiento social implementadas por el Gobierno pudieron haber disminuido la movilidad de las personas en los cruces de las carreteras porque las personas no podían viajar. Sin embargo, para verificar esta hipótesis realizaremos un análisis empírico utilizando regresiones.
Geográficas
En este grupo, se incorporan las variables geográficas de distancias de los centros poblados hacia la red vial nacional, el Camino del Inca6, el puerto más cercano y el litoral del mar. Estas variables geográficas también han sido utilizadas por Seminario et al. (2019) para analizar la evolución de la desigualdad regional del Perú utilizando datos a nivel de departamentos para el período 1795-2018. El grupo de variables geográficas también incluye la pendiente promedio del territorio y ancho del macizo andino. Estas variables han sido utilizadas por Seminario y Palomino (2021) para analizar la evolución de la concentración de la actividad económica y de la población del Perú a nivel de provincias para el período 1795-2018. Sin embargo, los datos a nivel de distritos los hemos obtenido utilizando la información de centros poblados del censo de población de 2017 y el software ArcGIS.
Uno de los factores más importantes de las regiones del Perú es la altitud generada por la cordillera de los Andes (Seminario & Palomino, 2021). Por ello, el presente estudio también emplea otras dos variables geográficas de relevancia: el ancho del macizo andino y la pendiente promedio del territorio. Seminario y Palomino (2021) determinaron el ancho del macizo andino por la curva de nivel de 2.300 m s. n. m., es decir, esta variable fue definida como la distancia horizontal entre la frontera de la yunga marítima y la frontera de la yunga fluvial en Sudamérica. Este indicador es importante, pues el ancho del macizo andino puede afectar el desplazamiento de la población y determinar la extensión de territorio alto.
Como complemento al ancho del macizo andino, se utilizó la pendiente promedio del territorio, ya que la primera no brinda información sobre el relieve del territorio. La pendiente del territorio permite identificar diferentes formas de relieve, como montañas, mesetas y valles. La variable fue generada por Seminario y Palomino (2021) utilizando las curvas de nivel cada 30 metros en Sudamérica. También empleamos la altura promedio del territorio generada con base en el modelo de elevación digital disponible en ArcGIS, el cual ha sido elaborado por el centro Earth Resources Observation and Science en Sioux Falls, Dakota del Sur.
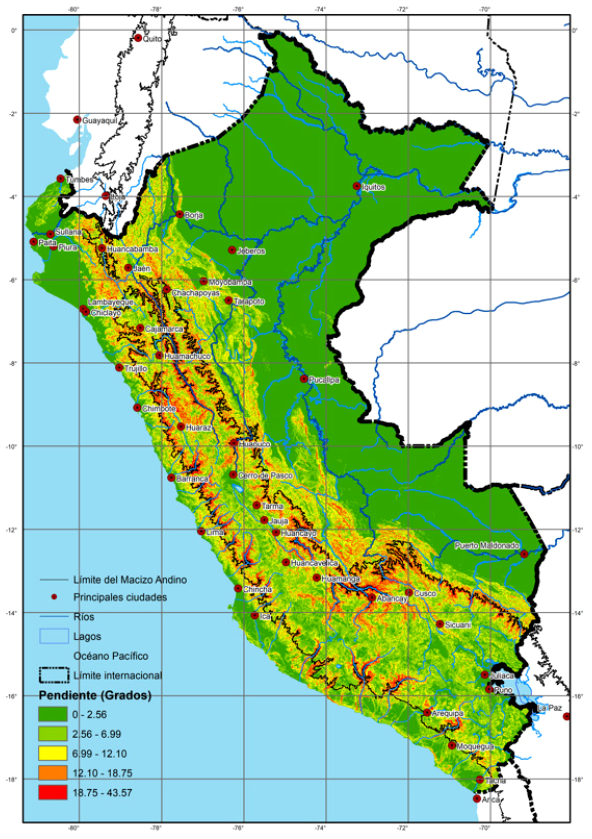
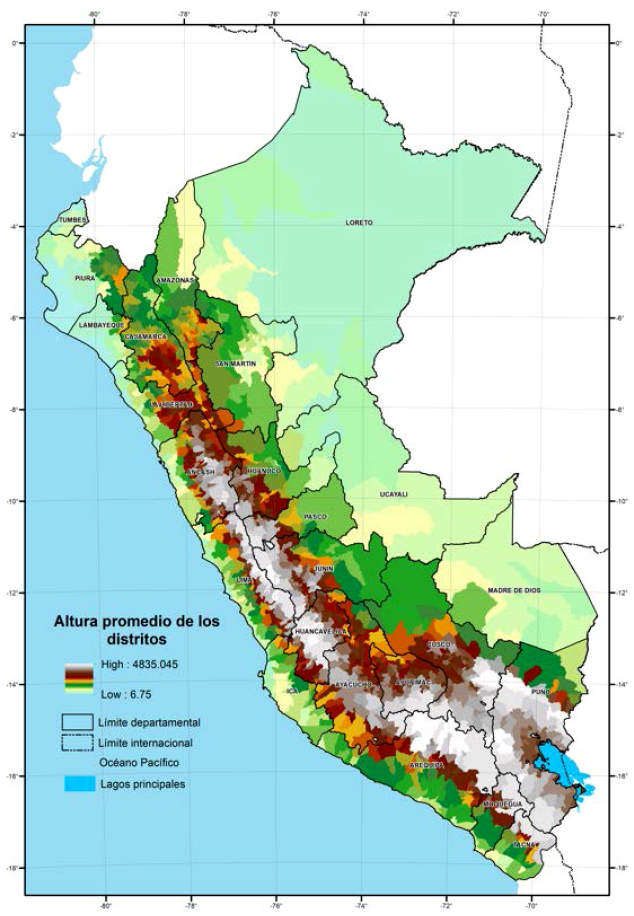
En las figuras 4 y 5, mostramos los distritos del Perú según su pendiente y altura promedio del territorio. Por un lado, en la figura 4, notamos que el territorio de la Costa tiene baja pendiente, lo cual facilita la movilidad de las personas de un lugar a otro, mientras que en los límites del macizo andino el territorio es más inclinado, lo cual se convierte en una barrera natural para que las personas se movilicen con facilidad. También podemos notar que dentro del macizo andino también hay territorio plano, pero este territorio corresponde a las regiones suni, puna o janca; es decir, el territorio plano dentro del macizo andino se ubica por encima de los 3.500 m s. n. m. Por lo tanto, podemos indicar que la menor cantidad acumulada de casos y muertes por COVID-19 en los distritos localizados en la Sierra podría ser consecuencia de las barreras naturales que evitan la propagación del virus. Por otro lado, en la figura 5, podemos observar que la Costa norte y la Costa centro del país tienen distritos con menor altura promedio que la Costa sur del país. En esta figura, también podemos notar que los distritos de la Selva tienen una altura similar a los distritos de la Costa norte o Costa centro. Estas estadísticas sugieren que la altura se relaciona negativamente con la cantidad de casos y muertes causadas por el coronavirus. En todo caso, utilizaremos regresiones para verificar la relación empírica de la pendiente y altura promedio del territorio con la evolución de casos y muertes por COVID-19.
Socioeconómicas
En este grupo se consideran las variables relacionadas con la pobreza, la educación, el ingreso per cápita y el tamaño de los centros poblados. Para ello, utilizamos tres fuentes de información: el Instituto Nacional de Estadística e Informática (INEI), Seminario y Palomino (2022), y el Programa de las Naciones Unidas para el Desarrollo (PNUD).
Por un lado, del INEI (2020) se recogieron las series sobre la pobreza a nivel distrital. Esta es una variable relevante en el estudio, debido a que diversas investigaciones sugieren que el coronavirus afecta en una proporción mayor a las personas de bajos recursos. Michael Ryan, director de emergencias de la Organización Mundial de la Salud, señaló que el estilo de vida causado por la pobreza y el bajo acceso a los servicios de salud hace a las personas más susceptibles al coronavirus y a presentar complicaciones en el momento de tener la enfermedad (OMS, 2020).
En esa misma línea, es relevante incorporar el PIB per cápita en nuestro análisis. Así, Seminario y Palomino (2022) generaron el PIB per cápita y PIB por km2 a nivel de provincias y distritos del Perú para el período 1993-2018. Los autores también han generado series anuales de densidad poblacional y tamaño promedio de los centros poblados desde 1993 hasta 2018.
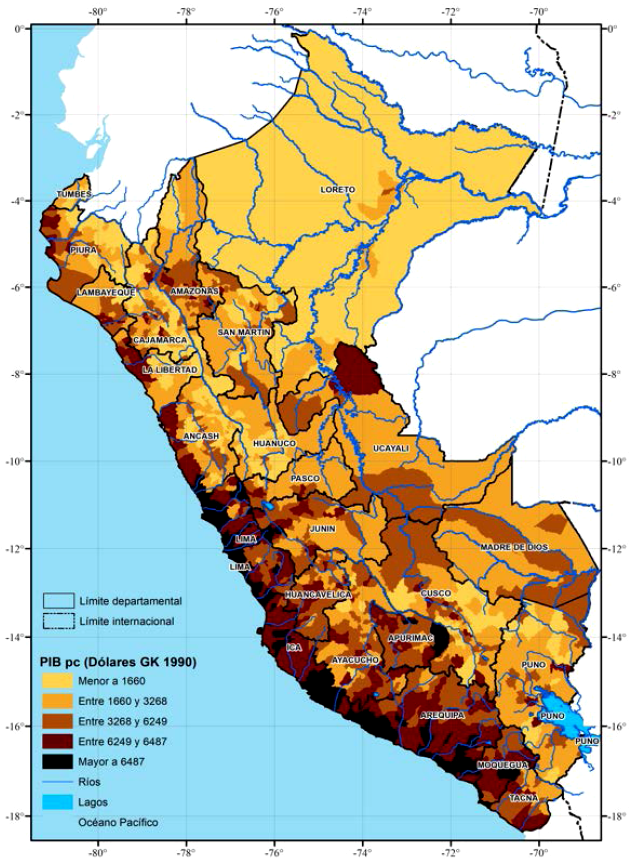
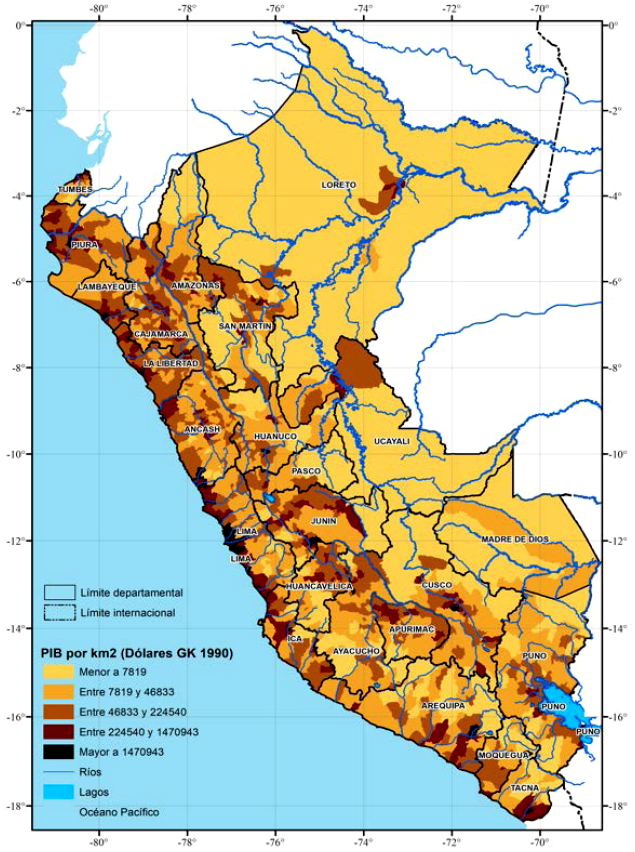
En las figura 6 y 7, mostramos la distribución espacial del PIB per cápita y el PIB por km2 a nivel de distritos para el año 2018, respectivamente. De acuerdo con estas figuras, los distritos con mayores niveles de PIB per cápita y PIB por km2 se localizan en la Costa, en las capitales departamentales en la Selva, en las zonas mineras en la Sierra, y en las regiones dedicadas a la agricultura de exportación en la yunga fluvial y la selva alta. Estos resultados sugieren que los distritos con la mayor cantidad acumulada de casos y muertes por COVID-19 son aquellos con mayores niveles de PIB per cápita y PIB por km2.
Por último, también incorporamos en el análisis empírico el Índice de Desarrollo Humano (IDH) y sus componentes (esperanza de vida, educación e ingreso per cápita) para el año 2019, las cuales han sido generadas por el PNUD (2019).
2.2 Metodología
Para evaluar la relación de la movilidad con la evolución de casos o muertes por COVID-19 a nivel de distritos del Perú, utilizamos la metodología de datos de panel. De esa manera, incorporamos tanto la dimensión temporal como la transversal que tienen las series recogidas. Sin embargo, utilizamos regresiones de panel con efectos aleatorios porque las variables geográficas y socioeconómicas que incorporamos en el análisis empírico no tienen dimensión temporal. Asimismo, usamos modelos de Poisson porque en la base de datos de COVID-19 hay presencia de muchos ceros (Henderson, Storeygard, & Weil, 2020). Por lo tanto, el modelo empírico general por estimar es el siguiente:
Pr(Yi,t)│X) = exp(X'β)
Pr(Yi,t│X) = exp(β0 + β1ln(Movilidad)i,t + β2ln(VG)i + β3ln(VSE)i + ei)
donde Y corresponde a los casos o muertes acumulados por millón de personas provocados por la COVID-19, y Movilidad corresponde al porcentaje de personas que recorrieron más de un kilómetro por día. Las variables geográficas (VG) incluyen las distancias de los centros poblados hacia los puertos, la distancia hacia el Camino del Inca, la distancia al litoral del mar y la distancia hacia la red vial nacional; también se incluyen el ancho del macizo andino y la pendiente y la altura promedio del territorio. Las variables socioeconómicas (VSE) incluyen la pobreza, el PIB per cápita, el PIB por km2, el IDH y sus componentes, el tamaño promedio de los poblados y la densidad poblacional. Por último, et,i corresponde al error de la estimación. Dado que los regresores están expresados en logaritmos naturales, los parámetros estimados corresponden a las elasticidades.
El período del análisis empírico está restringido a la disponibilidad de los datos de movilidad de las personas, los cuales se inician el 6 de marzo y terminan el 14 de junio de 2020. Asimismo, las regresiones consideran una muestra de 1.834 distritos, de los cuales 1.197 tienen información de movilidad de las personas.
3. Resultados
En la tabla 1, mostramos las correlaciones entre los cuatro grupos de variables incorporados en esta investigación: (1) COVID-19, (2) movilidad, (3) geográficas y (4) socioeconómicas.
Tabla 1 Correlación de Pearson a nivel de distritos
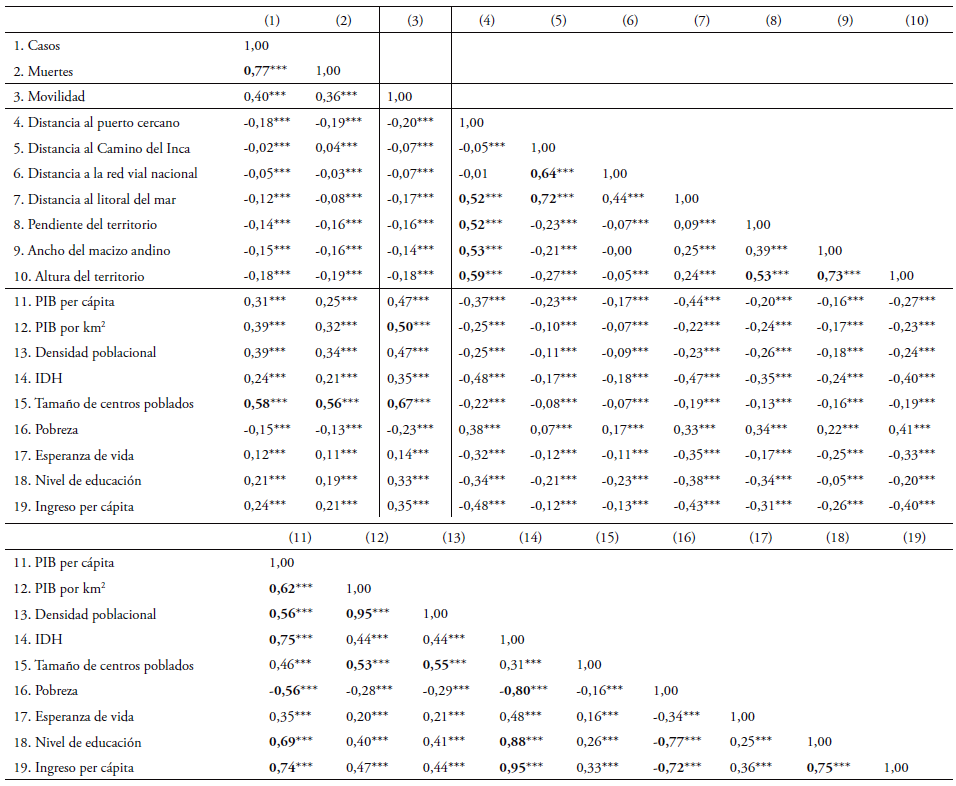
Notas. Esta tabla presenta las correlaciones entre todas las variables consideradas en el análisis empírico. Las estadísticas consideran una muestra de 1.834 distritos. La significancia estadística al 0,1%, 1% y 5% se indica con ***, ** y *, respectivamente.
En primer lugar, las estadísticas indican que existe una correlación del 77% entre el número de muertes y el número de casos por COVID-19, mientras que la correlación de la movilidad de las personas con la cantidad de casos es del 40% y con la cantidad de muertes es del 36%. Esto sugiere que una mayor movilidad de la población podría manifestarse en un alza de los casos y muertes causados por la pandemia.
En segundo lugar, las estadísticas indican que existe una relación negativa entre las variables geográficas y la cantidad de casos. Sin embargo, no todas las variables geográficas tienen una relación negativa con la cantidad de muertes. Los resultados sugieren una relación positiva entre la cantidad de muertes y la distancia promedio de los centros poblados hacia el Camino del Inca. Esto podría ser porque un caso de COVID-19 que se encuentra alejado del Camino del Inca fallece porque hay pocas posibilidades de que sea atendido a tiempo en un centro médico. No obstante, es necesario que futuras investigaciones incorporen variables de geolocalización de las muertes a causa de la pandemia para verificar esta hipótesis.
Asimismo, los resultados de las columnas 4-10 sugieren que existe una correlación mayor del 50% entre algunas variables geográficas. Por ejemplo, encontramos que existe una correlación positiva del 64% entre la distancia promedio de los centros poblados hacia el Camino del Inca y hacia la red vial nacional. También encontramos que la altura promedio del territorio tiene una correlación positiva del 59% con la distancia promedio de los centros poblados hacia el puerto más cercano, del 53% con la pendiente promedio del territorio y del 73% con el ancho del macizo andino. Los resultados también indican que la distancia promedio de los centros poblados hacia el puerto más cercano tiene una correlación positiva del 52% con la distancia promedio hacia el litoral del mar y la pendiente promedio del territorio, y del 53% con el ancho del macizo andino. Para evitar problemas de multicolinealidad en las regresiones, utilizaremos aquellas variables que tienen una correlación menor del 50%.
En tercer lugar, las estadísticas señalan que las variables socioeconómicas, excepto la referida a la pobreza, tienen una correlación positiva con la cantidad de casos y muertes por COVID-19. Observando el resto de las correlaciones, encontramos algunos posibles problemas de multicolinealidad entre las variables socioeconómicas. Por ejemplo, encontramos que el PIB per cápita tiene una correlación del 62% con el PIB por km2, del 56% con la densidad poblacional, del -56% con la pobreza, del 75% con el IDH, del 69% con la esperanza de vida y del 74% con el ingreso per cápita. Por lo tanto, en línea con el bloque de variables geográficas, para evitar problemas de multicolinealidad, seleccionamos aquellas que tienen una correlación menor del 50%.
Si bien se han detectado relaciones interesantes entre las variables, recurrimos a las regresiones para profundizar el análisis empírico. Confirmamos que no tenemos problemas de multicolinealidad en el análisis de regresiones porque el factor de inflación de la varianza (VIF por sus siglas en inglés) es menor de 10. En las tablas 2 y 3, mostramos los resultados de las regresiones de Poisson con efectos aleatorios a nivel de distritos. Asimismo, con el objetivo de analizar la importancia de Lima, las tablas muestran los resultados con y sin Lima7. Los resultados sugieren que la movilidad tiene asociaciones positivas significativas a un nivel de confianza del 99% con la cantidad de casos y muertes causados por la pandemia. Los resultados también indican que no hay diferencias significativas en la magnitud de la asociación de la movilidad de las personas cuando excluimos a Lima de las regresiones.
De acuerdo con los resultados de la tabla 2, el incremento del 1% en la movilidad de las personas está asociado con un aumento de la probabilidad de acumular más casos por millón de personas de alrededor del 0,16% cuando se incluye a Lima, y de alrededor del 0,18% cuando se la excluye. Los resultados también indican que dicha magnitud alcanza un valor del 0,1671% cuando incorporamos las variables geográficas y las variables socioeconómicas en las regresiones que incluyen a Lima; mientras que las regresiones que excluyen a Lima sugieren que el nivel de asociación de la movilidad de las personas alcanza un valor del 0,1864%.
Los resultados de la tabla 2 también sugieren que las variables geográficas tienen una relación negativa con la cantidad de casos por millón de personas. De acuerdo con las regresiones que incluyen y excluyen a Lima, solo la altura promedio del territorio tiene una asociación significativa, a un nivel de confianza del 90%.
Las regresiones que incorporan todas las variables sugieren que el incremento del 1% en la altura promedio del territorio se asocia negativamente con la probabilidad de acumular más casos por millón de personas en 0,4439% cuando se incluye a Lima y en 0,3804% cuando se excluye a Lima. Esto implica que la altura actúa como una barrera natural para evitar el incremento de los contagios. Estos resultados están en línea con los encontrados por investigaciones previas realizadas para el caso peruano (Accinelli & León-Abarca, 2020; Intimayta-Escalante, Rojas-Bolívar, & Hancco, 2020; Seclén et al., 2020; Segovia-Juárez, Castagnetto, & Gonzales, 2020). Por un lado, usando regresiones de panel y datos a nivel de departamentos, Seclén et al. (2020) encontraron una relación negativa entre la altura promedio y la cantidad acumulada de infectados por coronavirus. Por otro lado, usando regresiones lineales, Segovia-Juárez et al. (2020) también encontraron una relación negativa entre la altura de las capitales provinciales y el número de casos de COVID-19.
Los resultados de la tabla 2 también sugieren que las variables socioeconómicas tienen una relación positiva con la cantidad de casos por millón de personas. Sin embargo, el nivel de significancia estadística y la magnitud de las asociaciones dependen de la inclusión de Lima en las regresiones. Los resultados indican que el PIB per cápita tiene una asociación positiva y significativa sobre la probabilidad de acumular casos de coronavirus por millón de personas cuando se incluye a Lima en las regresiones, pero cuando se excluye a Lima solo tiene una asociación significativa cuando se controla por variables geográficas. De acuerdo con los resultados, el aumento del 1% en el PIB per cápita está relacionado con un incremento de la probabilidad de acumular casos por millón de personas en un 0,8521% cuando se incluye a Lima y en un 0,5144% cuando se excluye a Lima.
Tabla 2 Resultados a nivel de distritos, casos por COVID-19
| A: Con Lima | ||||
| (1) | (2) | (3) | (4) | |
| Ln (Movilidad de las personas) | 0,1689*** | 0,1671*** | 0,1679*** | 0,1671*** |
| (0,0188) | (0,0189) | (0,0188) | (0,0189) | |
| Ln (Distancia al Camino del Inca) | -0,1255** | -0,0019 | ||
| (0,0491) | (0,0471) | |||
| Ln (Pendiente del territorio) | 0,0619 | -0,0087 | ||
| (0,1137) | (0,0797) | |||
| Ln (Altura del territorio) | -0,5829*** | -0,4439*** | ||
| (0,0580) | (0,0686) | |||
| Ln (PIB per cápita) | 0,6028*** | 0,8521*** | ||
| (0,2140) | (0,2076) | |||
| Ln (Tamaño de centros poblados) | 0,2127*** | 0,0111 | ||
| (0,0645) | (0,0559) | |||
| Ln (Esperanza de vida) | 0,8117* | -0,0004 | ||
| (0,4513) | (0,4494) | |||
| B: Sin Lima | ||||
| (1) | (2) | (3) | (4) | |
| Ln (Movilidad de las personas) | 0,1979*** | 0,1962*** | 0,1962*** | 0,1962*** |
| (0,0248) | (0,0248) | (0,0248) | (0,0248) | |
| Ln (Distancia al Camino del Inca) | -0,1541*** | -0,0576 | ||
| (0,0364) | (0,0472) | |||
| Ln (Pendiente del territorio) | -0,1496* | -0,0906 | ||
| (0,0768) | (0,0787) | |||
| Ln (Altura del territorio) | -0,4750*** | -0,3868*** | ||
| (0,0638) | (0,0704) | |||
| Ln (PIB per cápita) | 0,2467 | 0,5151*** | ||
| (0,1578) | (0,1615) | |||
| Ln (Tamaño de centros poblados) | 0,3786*** | 0,1260*** | ||
| (0,0469) | (0,0453) | |||
| Ln (Esperanza de vida) | 1,2012*** | 0,4670 | ||
| (0,4020) | (0,4007) |
Notas. Esta tabla presenta las elasticidades estimadas entre la probabilidad de acumular casos de COVID-19 por millón de personas y la movilidad de las personas, variables geográficas y variables socioeconómicas. Las elasticidades se han estimado utilizando modelos de Poisson con efectos aleatorios. Las regresiones consideran una muestra de 1.834 distritos del Perú. Las regresiones de las columnas (1), (2) y (3) consideran como variables independientes la movilidad de las personas, las variables geográficas y las variables socioeconómicas, respectivamente. La columna (4) presenta las elasticidades estimadas considerando todas las variables consideradas en las columnas de la (1) a la (3). Las regresiones del panel A incluyen todos los distritos, mientras que las regresiones del panel B excluyen a los distritos del departamento de Lima y a la provincia constitucional del Callao. Los errores estándar robustos se encuentran entre paréntesis. La significancia estadística al 1%, 5% y 10% se indica con ***, ** y *, respectivamente.
Por otro lado, los resultados sugieren que el tamaño de los centros poblados se relaciona positivamente con la probabilidad de acumular casos por millón de personas. Sin embargo, la relación positiva solo es significativa cuando se excluye a Lima o no se controla por variables geográficas cuando se incluye Lima. Esto sugiere que las regiones urbanas del interior del país son aquellas que tienen más probabilidad de acumular casos por millón de personas porque el tamaño de los centros poblados es mayor que el de las zonas rurales. De acuerdo con los resultados, el aumento de un 1% en el tamaño de los centros poblados se asocia positivamente con la probabilidad de acumular casos por millón de personas en un 0,1190% en los distritos que no se localizan en Lima.
En la tabla 3, mostramos los resultados de la relación de la movilidad de las personas, las variables geográficas y las variables socioeconómicas con la cantidad de muertes acumuladas por millón de personas a nivel de distritos.
Tabla 3 Resultados a nivel de distritos, muertes por COVID-19
| A: Con Lima | ||||
| (1) | (2) | (3) | (4) | |
| Ln (Movilidad de las personas) | 0,1757*** | 0,1730*** | 0,1757*** | 0,1730*** |
| (0,0230) | (0,0231) | (0,0230) | (0,0231) | |
| Ln (Distancia al Camino del Inca) | -0,0380 | 0,0631 | ||
| (0,0623) | (0,0570) | |||
| Ln (Pendiente del territorio) | -0,0222 | -0,2659*** | ||
| (0,1460) | (0,0976) | |||
| Ln (Altura del territorio) | -0,6293*** | -0,4326*** | ||
| (0,0829) | (0,0955) | |||
| Ln (PIB per cápita) | 0,4396 | 0,9576*** | ||
| (0,2873) | (0,2713) | |||
| Ln (Tamaño de centros poblados) | 0,2780*** | -0,0708 | ||
| (0,0758) | (0,0664) | |||
| Ln (Esperanza de vida) | 1,6656*** | 1,2736** | ||
| (0,6431) | (0,6088) | |||
| B: Sin Lima | ||||
| (1) | (2) | (3) | (4) | |
| Ln (Movilidad de las personas) | 0,1968*** | 0,1968*** | 0,1968*** | 0,1968*** |
| (0,0344) | (0,0344) | (0,0344) | (0,0344) | |
| Ln (Distancia al Camino del Inca) | -0,0849* | 0,0021 | ||
| (0,0509) | (0,0564) | |||
| Ln (Pendiente del territorio) | -0,2972*** | -0,3800*** | ||
| (0,1017) | (0,0977) | |||
| Ln (Altura del territorio) | -0,5094*** | -0,3613*** | ||
| (0,0878) | (0,0927) | |||
| Ln (PIB per cápita) | 0,1133 | 0,5866*** | ||
| (0,2126) | (0,2163) | |||
| Ln (Tamaño de centros poblados) | 0,4756*** | 0,0305 | ||
| (0,0720) | (0,0652) | |||
| Ln (Esperanza de vida) | 1,9710*** | 1,5187*** | ||
| (0,5662) | (0,5685) |
Notas. Esta tabla presenta las elasticidades estimadas entre la probabilidad de acumular casos de COVID-19 por millón de personas y la movilidad de las personas, variables geográficas y variables socioeconómicas. Las elasticidades se han estimado utilizando modelos de Poisson con efectos aleatorios. Las regresiones consideran una muestra de 1.834 distritos del Perú. Las regresiones de las columnas (1), (2) y (3) consideran como variables independientes la movilidad de las personas, las variables geográficas y las variables socioeconómicas, respectivamente. La columna (4) presenta las elasticidades estimadas considerando todas las variables consideradas en las columnas de la (1) a la (3). Las regresiones del panel A incluyen todos los distritos, mientras que las regresiones del panel B excluyen a los distritos del departamento de Lima y a la provincia constitucional del Callao. Los errores estándar robustos se encuentran entre paréntesis. La significancia estadística al 1%, 5% y 10% se indica con ***, ** y *, respectivamente.
En primer lugar, los resultados indican que la movilidad de las personas tiene una relación positiva con la probabilidad de acumular muertes por millón de personas independientemente de si se considera o no a Lima. Las regresiones que toman en cuenta todas las variables sugieren que un aumento del 1% en la movilidad de las personas se asocia positivamente con la probabilidad de acumular más muertes por millón de personas en un 0,1730% cuando se incluye a Lima y en un 0,1891% cuando no se incluye a Lima. Sobre la base de estos resultados, podemos indicar que el incremento de la movilidad de las personas, medida por el porcentaje de la población del distrito que recorre más de un kilómetro, aumenta la probabilidad de acumular más casos y muertes por COVID-19.
En segundo lugar, las regresiones muestran que la pendiente y la altura promedio del territorio tienen una relación negativa con la probabilidad de acumular muertes por millón de personas. Por un lado, encontramos que un incremento del 1% en la pendiente promedio del territorio se asocia negativamente con la probabilidad de acumular muertes por millón de personas en un 0,2689% cuando se incluye a Lima y en un 0,3861% cuando no se incluye a Lima. Por otro lado, los resultados indican que un incremento del 1% en la altura promedio del territorio se asocia negativamente con la probabilidad de acumular muertes por millón de habitantes en un 0,4314% cuando se incluye a Lima y en un 0,3553% cuando no se incluye a Lima. En concreto, los resultados sugieren que las regiones del Perú con territorios más accidentados y altos tienen menos probabilidad de acumular más muertes provocadas por una enfermedad de rápido contagio como la COVID-19.
En tercer lugar, los resultados indican que algunas variables socioeconómicas tienen una relación positiva con la probabilidad de acumular muertes por millón de personas. De hecho, muestran que la probabilidad de acumular muertes por millón de personas tiene una relación positiva con el PIB per cápita y la esperanza de vida. Estos resultados sugieren que, en el Perú, la primera ola de la pandemia ha causado más muertes en las regiones con mayores niveles de desarrollo económico.
Por un lado, los resultados sugieren que un incremento del 1% en el PIB per cápita se asocia positivamente con la probabilidad de acumular más muertes por millón de personas en un 0,9601% cuando se incluye a Lima y en un 0,5865% cuando no se incluye a Lima. Es decir, cuando se excluye a Lima de las regresiones, la magnitud de la relación empírica del PIB per cápita disminuye en 37 puntos básicos. Por otro lado, los resultados indican que un incremento del 1% en la esperanza de vida se asocia positivamente con la probabilidad de acumular muertes por millón de personas en un 1,2704% cuando se incluye a Lima y en un 1,5277% cuando se excluye a Lima. De otro lado, los resultados muestran que no es clara la relación empírica entre la probabilidad de acumular muertes por millón de personas y el tamaño de los centros poblados. En concreto, los resultados indican que la dirección de las relaciones empíricas se mantiene con y sin Lima, pero la magnitud es mayor cuando se excluye a Lima en la mayoría de las variables.
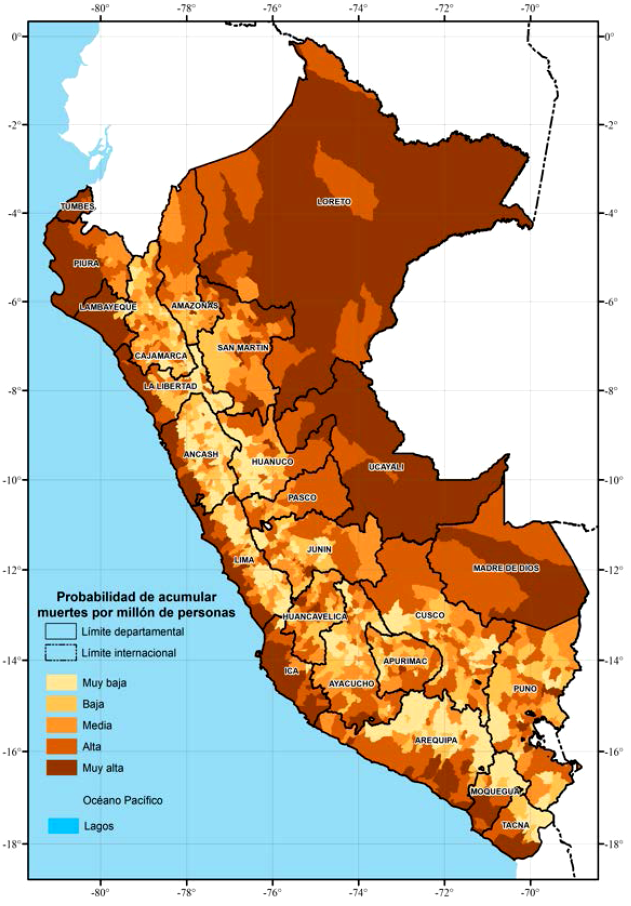
Utilizando los parámetros estimados de las regresiones que consideran todas las variables y excluyen a Lima, computamos la probabilidad de acumular casos y muertes por millón de personas a nivel de distritos causados por la pandemia. En las figuras 8 y 9, mostramos la distribución espacial de los distritos del Perú según quintiles de probabilidad de acumular casos y muertes por millón de personas, respectivamente. En estas figuras, el color más oscuro corresponde a los distritos con mayor probabilidad de acumular más casos y muertes por millón de personas.
Las figuras 8 y 9 sugieren que los distritos que se ubican en la Costa y la Selva tienen mayores probabilidades de acumular más casos y muertes por millón de personas. Por un lado, la Costa tiene más probabilidad de acumular casos y muertes por COVID-19 porque en esta región vive alrededor del 70% de la población y presenta una densidad promedio de 111 personas por km2. Por otro lado, observamos que la Selva también es una región con altas probabilidades de acumular casos y muertes. Estos resultados pueden deberse tanto a las condiciones sanitarias como a las costumbres de la gente. A pesar de que las principales ciudades cuentan con personal médico muy capacitado, la mayoría de los centros de salud de ciudades pequeñas y comunidades rurales se encuentra en malas condiciones de infraestructura, equipamiento y personal médico (García, 2020). En las figuras, observamos que la Sierra es la región con menor cantidad de distritos con altas probabilidades de acumular casos y muertes por COVID-19, lo cual puede ser explicado por barreras naturales, como la pendiente y altura promedio del territorio. No obstante, también observamos presencia de distritos con altas probabilidades de acumular casos y muertes por millón de personas, y las figuras sugieren que son las capitales departamentales, las capitales provinciales o las zonas mineras.
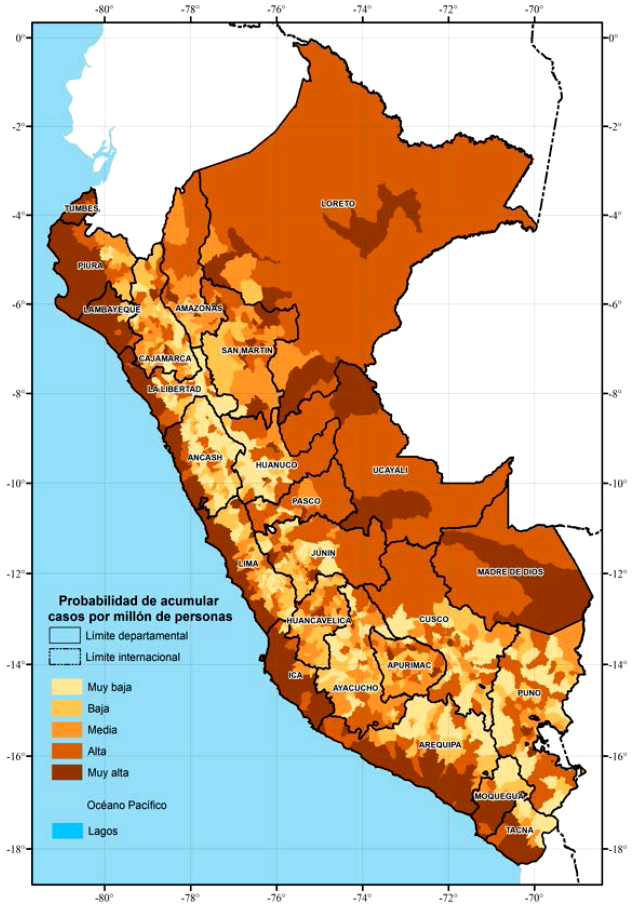
Fuente: Seminario y Palomino (2022). Elaboración propia.
Figura 8 Probabilidad de acumular casos por millón de personas
4. Análisis de sensibilidad
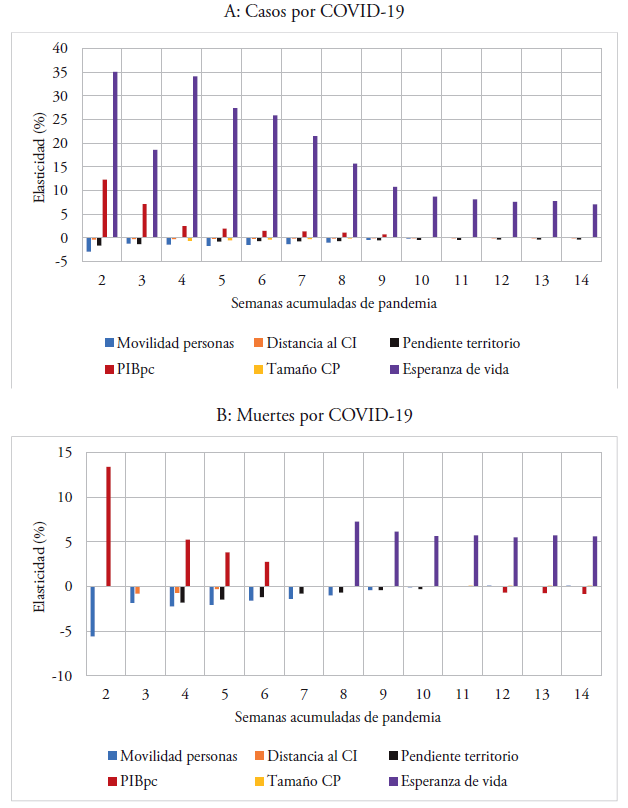
En esta sección, discutimos la evolución de las relaciones empíricas según la cantidad acumulada de semanas de pandemia. Para ello, utilizamos el modelo 4 de las tablas 2 y 3. La figura 10 muestra los resultados considerando todos los distritos del Perú, mientras que la figura 11 muestra los resultados considerando solo los distritos de Lima Metropolitana. En estas figuras, solo presentamos las relaciones empíricas que son estadísticamente significativas a un nivel de confianza del 90%.
En primer lugar, los resultados de las figuras 10 y 11 indican que la relación de la movilidad de las personas con la probabilidad de acumular casos y muertes por millón de personas no ha sido positiva en todas las semanas de pandemia. En particular, la relación positiva se observa a partir de la decimoprimera semana de pandemia, mientras que en las semanas previas se observa una relación negativa. Por un lado, la relación positiva puede ser explicada por la reapertura de ciertas actividades económicas que no podían permanecer en cuarentena total. Es probable que las reaperturas hayan ocurrido en el sector informal porque nuestro análisis empírico se encuentra dentro del período de cuarentena nacional que se inició el 16 de marzo de 2020 y se prolongó hasta el 30 de junio de 20208. Esto implica que las cuarentenas prolongadas no son sostenibles porque pueden agudizar la economía informal de un país. Por otro lado, la relación negativa posiblemente esté capturando el desplazamiento del personal dedicado a controlar la pandemia. Esto sugiere que el desplazamiento del personal médico y las fuerzas armadas y policiales contribuyó a controlar el avance de la pandemia durante las primeras nueve semanas de cuarentena nacional. En concreto, los resultados sugieren que el rol de la movilidad depende del sector que se considere en el análisis empírico9.
En segundo lugar, los resultados de la figura 10 indican que el tamaño de los centros poblados tiene una relación positiva con la probabilidad de acumular casos por millón de personas en las primeras cuatro semanas de pandemia cuando se considera a todos los distritos del Perú, mientras que los resultados de la figura 11 muestran una relación negativa entre la cuarta y la octava semana de pandemia cuando se considera solo a los distritos de Lima Metropolitana. Estos resultados sugieren que, excluyendo los distritos de Lima Metropolitana, que parecen tener una dinámica distinta, los distritos más grandes del Perú fueron los primeros en acumular casos de COVID-19.
En tercer lugar, los resultados de las figuras 10 y 11 indican que el PIB per cápita tiene una asociación positiva con la probabilidad de acumular casos y muertes por millón de personas. Los resultados muestran que la asociación positiva empieza en la segunda semana de pandemia cuando se considera a los distritos de Lima Metropolitana y desde la cuarta semana de pandemia cuando se considera a todos los distritos del Perú. Con base en estos resultados, podemos indicar que la pandemia primero se extendió en los distritos con mayor PIB per cápita de Lima Metropolitana y después se extendió al resto de distritos del país que también tienen altos niveles de PIB per cápita.
En cuarto lugar, los resultados de la figura 10 indican que la esperanza de vida tiene una relación positiva con la probabilidad de acumular muertes por millón de personas en las primeras cinco semanas de pandemia y después de la octava semana de pandemia cuando se considera a todos los distritos del Perú. De otro lado, los resultados de la figura 11 indican que la esperanza de vida está asociada positivamente con la probabilidad de acumular casos por millón de personas en Lima Metropolitana durante todo el período de análisis, mientras que la asociación positiva con la probabilidad de acumular muertes por millón de personas se observa a partir de la octava semana de pandemia. Estos resultados sugieren que los distritos con mayor esperanza de vida de Lima Metropolitana son los que acumularon más casos, pero, debido a la calidad del sistema de salud respecto a las otras regiones del país, pudieron reducir la probabilidad de acumular muertes en las primeras ocho semanas de pandemia; sin embargo, a partir de la novena semana, las muertes se acumularon en los distritos de todo el Perú que tienen mayor esperanza de vida.
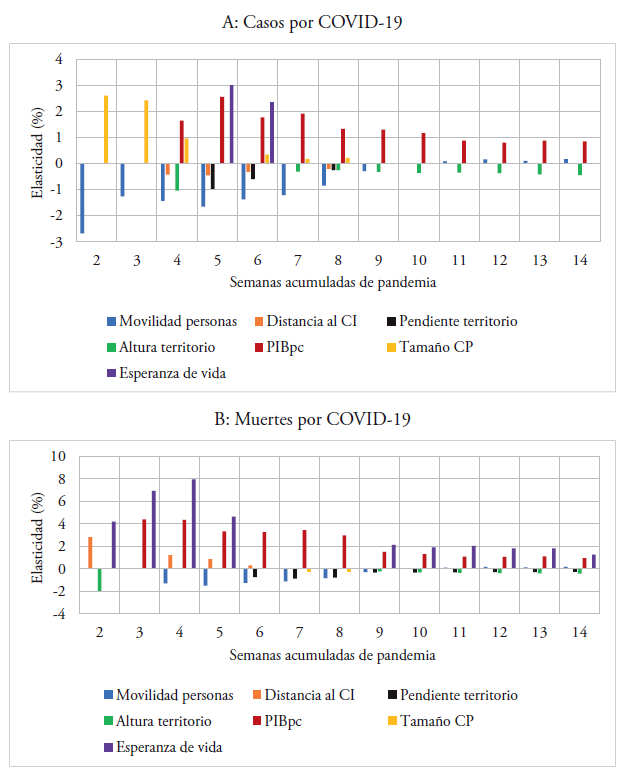
Notas. Esta figura presenta las elasticidades estimadas entre la probabilidad de acumular casos y muertes por COVID-19 por millón de personas y la movilidad de las personas, las variables geográficas y las variables socioeconómicas. Las elasticidades se han estimado utilizando modelos de Poisson con efectos aleatorios. Las regresiones consideran la especificación empírica que incluye todas las variables que no tienen problemas de multicolinealidad (modelo 4 de la tabla 2 para casos y tabla 3 para muertes). Las regresiones consideran una muestra de 1.834 distritos de todo el Perú. El gráfico presenta solo las elasticidades significativas a un nivel de confianza del 90%.
Figura 10 Resultados por semana de pandemia, todo el Perú
Notas. Esta figura presenta las elasticidades estimadas entre la probabilidad de acumular casos y muertes por COVID-19 por millón de personas y la movilidad de las personas, las variables geográficas y las variables socioeconómicas. Las elasticidades se han estimado utilizando modelos de Poisson con efectos aleatorios. Las regresiones consideran la especificación empírica que incluye todas las variables que no tienen problemas de multicolinealidad (modelo 4 de la tabla 2 para casos y de la tabla 3 para muertes). Las regresiones consideran una muestra de 49 distritos de Lima Metropolitana (provincias de Lima y Callao). El gráfico presenta sólo las elasticidades significativas a un nivel de confianza del 90%.
Figura 11 Resultados por semana de pandemia, Lima Metropolitana
Por último, en la figura 10 se observa una relación negativa entre la altura del territorio y la probabilidad de acumular casos por millón de personas a partir de la séptima semana de pandemia, mientras que la relación negativa entre la altura del territorio y la probabilidad de acumular muertes por millón de personas se observa a partir de la novena semana de pandemia. Asimismo, encontramos una asociación negativa entre la pendiente del territorio y la probabilidad de acumular muertes por millón de personas a partir de la sexta semana. De otro lado, los resultados de la figura 11 indican que la pendiente del territorio tiene una asociación negativa con la probabilidad de acumular casos por millón de personas cuando solo se considera a los distritos de Lima Metropolitana, mientras que la asociación negativa entre la pendiente del territorio y la probabilidad de acumular muertes por millón de personas se observa a partir de la cuarta semana. Estos resultados sugieren que la presencia de algún accidente geográfico, como un cerro, podría impedir que la pandemia se traslade de un lugar a otro dentro de cada distrito. Con base en estos resultados, podemos indicar que la altura y la pendiente del territorio podrían actuar como barreras naturales para evitar la expansión de pandemias a lo largo de todo el territorio peruano.
5. Conclusiones
La comprensión de los diferentes factores que están determinando la evolución de muertes por COVID-19 podría ser clave para diseñar políticas de prevención que permitan evitar grandes pérdidas económicas y sociales en esta y futuras pandemias. En efecto, Casalino (2017) indica que, en los períodos de epidemias, las autoridades y la población han tomado medidas específicas para afrontarlas. Estos períodos constituyeron oportunidades para mejorar las condiciones sanitarias. Por lo tanto, entender cuáles son los determinantes de esta pandemia debe servir para mejorar los sistemas de salud y diseñar programas para que la población y el Gobierno sepan cómo actuar de manera eficiente en futuras situaciones similares.
Por ello, la presente investigación busca contribuir a la literatura sobre los determinantes de los casos y muertes de COVID-19 en el Perú; en específico, sobre el rol de la movilidad, geografía y desarrollo. Para ello, usamos regresiones de Poisson con efectos aleatorios, y datos de cuatro grupos de variables a nivel de distritos: (1) COVID-19; (2) movilidad de las personas, entendida como el desplazamiento; (3) variables geográficas; y (4) variables socioeconómicas.
Los resultados indican que las relaciones empíricas cambian según la evolución de la pandemia. Por un lado, encontramos que la movilidad de las personas tiene una relación negativa con la probabilidad de acumular casos y muertes de COVID-19 en las primeras nueve semanas de pandemia, pero encontramos una relación positiva a partir de la decimoprimera semana. Por otro lado, encontramos que las variables socioeconómicas como el PIB per cápita y la esperanza de vida tienen asociaciones positivas con la probabilidad de acumular casos y muertes de COVID-19; no obstante, la magnitud de la relación empírica disminuye a medida que se acumulan más semanas de pandemia. De otro lado, encontramos que las variables geográficas, como la altura y la pendiente del territorio, tienen asociaciones negativas con la probabilidad de acumular casos y muertes de COVID-19; sin embargo, la significancia estadística y la magnitud de la relación empírica no se observa en todas las semanas de pandemia. También encontramos que el rol de las variables geográficas y socioeconómicas depende de la inclusión de Lima en el análisis empírico.
6. Implicancias, limitaciones y agenda futura
Los resultados encontrados en este estudio tienen tres implicancias. En primer lugar, los resultados indican que la movilidad de las personas aumenta la probabilidad de acumular más casos y muertes por COVID-19 a partir de la decimoprimera semana de pandemia. En ese sentido, es clave que el Gobierno encuentre formas eficientes de manejar el distanciamiento social para disminuir la proporción de personas que recorren más de un kilómetro. En segundo lugar, los resultados indican que las variables geográficas y socioeconómicas tienen asociaciones importantes con la probabilidad de acumular más muertes por COVID-19. Por lo tanto, el Gobierno debe implementar medidas de lucha contra la pandemia con base en el nivel de riesgo de cada región configurado por sus variables geográficas y socioeconómicas. En tercer lugar, las figuras que muestran la probabilidad de acumular casos y muertes por millón de personas permiten identificar regiones en las que el Gobierno debe focalizar su intervención en esta pandemia o en futuras pandemias que tengan características similares a la de la COVID-19.
No obstante, este estudio tiene varias limitaciones. La primera es que las variables socioeconómicas y geográficas incorporadas en el análisis no tienen dimensión temporal y, por ello, no es posible visualizar cómo estas han variado día a día. En este contexto, futuras investigaciones podrían recurrir a fuentes de big data para generar indicadores económicos a nivel subregional de alta frecuencia para analizar los impactos dinámicos de las variables geográficas y socioeconómicas. Las futuras investigaciones también podrían incorporar otras variables geográficas a nivel subregional que han sido usadas en algunas investigaciones, pero en análisis agregado de países (Henderson et al., 2020; Walrand, 2021). Entre las variables geográficas que podrían incorporar las futuras investigaciones se encuentran la latitud, la temperatura, la humedad, la precipitación, el flujo de agua, los tipos de suelo, la calidad de aire, etc.
La segunda limitación es que no hemos incorporado variables del sector salud. Por lo tanto, futuras investigaciones podrían incorporar variables que midan el nivel de calidad y equipamiento del sistema de salud en cada región, tales como la cantidad de médicos, enfermeras, medicinas, camas UCI, etc. Estas variables podrían permitir identificar con claridad si la poca cantidad de muertes en algunas regiones es debido al desempeño del sector salud o se debe a factores inmunológicos que la población ha desarrollado al vivir en esas regiones. En esta línea, también resulta importante incorporar indicadores de variación genética que la población ha desarrollado para ser inmune a determinados tipos de enfermedades según la región donde ha nacido o vive, las cuales podrían ayudar para el manejo de futuras pandemias.
La tercera limitación es que el indicador de movilidad de las personas utilizado en esta investigación no permite diferenciar la movilidad de las personas dedicadas a controlar la pandemia y la movilidad del resto de la población. Por ello, futuras investigaciones podrían hacer esfuerzos para generar indicadores de movilidad de las personas para los diferentes sectores dedicados a controlar la pandemia y para el resto de los sectores de la economía. Futuras investigaciones también podrían explorar otras formas de generar indicadores de movilidad de las personas para divisiones administrativas pequeñas (Chauvin, 2021; Couture et al., 2021; Cook, Currier, & Glaeser, 2022).