










Servicios Personalizados
Revista

Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkLexis
versión impresa ISSN 0254-9239
Lexis vol.41 no.1 Lima 2017
http://dx.doi.org/http://doi.org/10.18800/lexis.201701.003
ARTÍCULOS
Lenguas y dialectos pano del Purús: una aproximación filogenética*
Roberto Zariquiey, Alonso Vásquez, Gabriela Tello
Pontificia Universidad Católica del Perú
RESUMEN
El presente artículo ofrece una propuesta de clasificación de las variedades lingüísticas pertenecientes a la familia lingüística pano habladas en la provincia del Purús (región Ucayali, Perú). Los datos empleados recogen información léxica sobre nueve de estas variedades lingüísticas e información gramatical sobre ocho de ellas. Este material ha sido analizado empleando métodos filogenéticos y demuestra la pertinencia de agrupar a todas estas lenguas en un subgrupo al interior de la familia pano. Sin embargo, los resultados revelan una contradicción entre los datos provenientes del léxico y los datos provenientes de la gramática: los primeros sugieren la existencia de tres unidades lingüísticas bien delimitadas, mientras que los segundos sugieren la existencia de cuatro. Esto abre interesantespreguntas en torno a la posible existencia de un continuo dialectal yaminawa. Finalmente, este artículo discute la posición de la lengua iskonawa (una lengua pano obsolescente) en relación con las lenguas del Purús. Los datos muestran que el iskonawa exhibe una fuerte base purusina, que nos lleva a postularlo como una lengua muy cercana a las lenguas habladas en el Purús.
Palabras clave: pano, Purus, filogenética, variación léxica, variación grammatical.
ABSTRACT
The present paper aims to provide a classification of the Panoan linguistic varieties spoken in the province of Purus (Ucayali, Peru). The data covers lexical information coming from nine Panoan linguistic varieties of the Purus province, as well as grammatical information taken from eight of them. The data have been analyzed using phylogenetic methods and show the need of including all these languages in a single Panoan subgroup. The results, however, show inconsistent trends between the lexical and the grammatical data: lexical data suggest the existence of three well-defined linguistic units, while the grammatical data point towards the existence of four. This fact opens interesting questions regarding the so-called Yaminawa dialectal continuum. Finally, this paper discusses the position of Iskonawa (an obsolescent Panoan language) in relation to the languages of Purus. The data shows that Iskonawa is closely-related to the languages of the Purus region.
Keywords: Panoan, Purus, phylogenetics, lexical variation, grammatical variation.
1. Introducción
El presente artículo tiene como objetivo ofrecer una propuesta de clasificación de las variedades lingüísticas pertenecientes a la familia lingüística pano habladas en la provincia del Purús (región Ucayali, Perú). Los datos incluyen información léxica proveniente de nueve variedades lingüísticas pano de dicha región, así como información gramatical tomada de ocho de ellas. Los materiales han sido analizados empleando métodos filogenéticos, particularmente el algoritmo que dio pie a las llamadas redes de vecinos o neighbor-nets (Dunn 2014).
Los resultados revelan una contradicción entre los datos provenientes del léxico y los datos obtenidos a partir del cotejo de rasgos gramaticales (que incluyen rasgos fonológicos). Los primeros sugieren la existencia de tres unidades lingüísticas bien delimitadas: (1) amawaka, (2) kashinawa y (3) lo que, siguiendo la literatura, podemos llamar "complejo dialectal yaminawa" (Fleck 2013; Valenzuela y Guillaume 2016). Este complejo dialectal incluiría, por lo menos, a las siguientes variedades lingüísticas: sharanawa, chaninawa, yaminawa, mastanawa, nawa y marinawa, siendo el caso que las diferencias entre estas resultan extremadamente sutiles. Por otra parte, los datos obtenidos a partir de cuestionarios gramaticales (que incluyen rasgos fonológicos) sugieren la existencia de cuatro unidades lingüísticas diferenciadas: (1) amawaka, (2) kashinawa, (3) yaminawa y (4) un continuo dialectal que agrupa a las demás variedades (sharanawa, chaninawa, mastanawa, nawa y marinawa). Estas diferencias en los resultados, centradas en la posición del yaminawa en el panorama purusino serán discutidas en la sección 5.
Si bien se sugiere la posibilidad de que efectos areales y de contacto puedan estar jugando un rol en la configuración lingüística de las variedades pano habladas en el Purús (básicamente, mediante nivelación léxica), nuestra propuesta es, más bien, que se trata de innovación gramatical; es decir que la gramática yaminawa ha atravesado cambios que la han distanciado de sus variedades hermanas. Esta propuesta se condice con el hecho de que, tal como ha sido señalado por Shell (1965: 11), las lenguas pano tienden a ser más similares lexicamente que en términos de su gramática.
Este artículo, además, discute la posición de la lengua iskonawa (una lengua pano obsolescente hablada solo por seis personas) en relación con las lenguas del Purús. Los resultados sugieren una cercanía significativa entre el iskonawa y las lenguas pano purusinas. En el caso del iskonawa, sin embargo, la cercanía al Purús se aprecia más en la gramática que en el léxico. Considerando, otra vez, que la gramática tiende a ser más variable que el léxico entre las lenguas pano (Shell 1965: 11), asumimos que el parecido gramatical apunta sólidamente hacia una filiación purusina del iskonawa. En realidad, la divergencia apreciada en el léxico podría explicarse a partir de innovaciones motivadas por el contacto con lenguas pano ajenas al Purús (particularmente, el shipibo-konibo, lengua pano del Ucayali), que puede explicarse a partir de la historia reciente de este pueblo (Zariquiey 2015). Sin embargo, de ser una lengua del Purús, el iskonawa estaría entre las lenguas más divergentes del grupo.1
El presente artículo presenta la siguiente estructura: en la sección 2 presentamos los métodos empleados y los procedimientos de recojo y procesamiento de datos, en la sección 3 ofrecemos una breve introducción a las lenguas pano del Purús, en la sección 4 damos cuenta de los resultados de nuestro estudio y, finalmente, en la sección 5 discutimos los resultados obtenidos y proponemos algunas líneas de explicación, que pueden ser relevantes para futuras clasificaciones internas de toda la familia. Unas breves conclusiones son brindadas en la sección 6.
2. Métodos
En esta sección reseñamos brevememente las distintas etapas en las que dividimos el trabajo en el que se sustenta este estudio y describimos los métodos empleados para cada una de ellas. En la subsección 2.1, presentamos el proceso de recojo de datos; en la subsección 2.2, discutimos el trabajo de preprocesamiento de la información; en la subsección 2.3, ofrecemos una descripción del procesamiento final de los datos, que produjo los resultados presentados en la sección 4; finalmente, en la subsección 2.4, hacemos una breve mención al almacenamiento de los datos léxicos obtenidos en el marco de este estudio, los mismos que se encuentran a disposición de todos los interesados en el Archivo Digital de Lenguas Peruanas del Departamento de Humanidades de la Pontificia Universidad Católica del Perú (http://repositorio.pucp.edu.pe/index/handle/123456789/15344).
2.1. Recojo de los datos
Los datos empleados en este estudio son en un 100% de primera mano y casi en su totalidad fueron recogidos por los autores del presente artículo en el marco de un proyecto de investigación ejecutado durante los años 2015 y 2016.2 Para ello, se realizaron dos periodos de trabajo de campo en las afueras de la ciudad de Pucallpa. En el primero, realizado en el 2015 y dedicado a la elicitación léxica, se trabajó con nueve variedades pano del Purús (dos hablantes por variedad = un total de 18 hablantes). En el segundo periodo, también realizado en el 2015, pero esta vez dedicado a la elicitación gramatical, se trabajó solo con ocho variedades y nuevamente con dos hablantes por variedad (es decir, un total de 16 hablantes).3 Todo esto se detalla a continuación en la tabla 1. Debido a que el objetivo de este estudio era comparar datos gramaticales con datos léxicos y no contamos con los primeros para la variedad denominada xuxunawa, esta no ha sido incluida en el análisis. Sin embargo, los datos léxicos han sido puestos a disposición de los interesados en el Archivo Digital de Lenguas Peruanas, tal como se mencionó arriba y se detalla en la subsección 2.4.
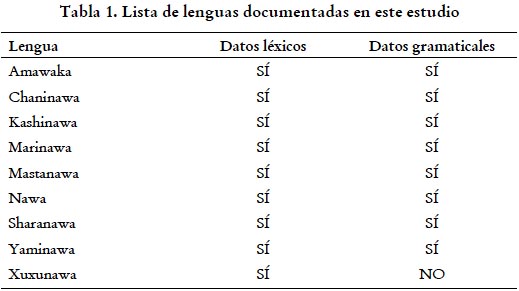
Los datos léxicos se obtuvieron a partir de una lista Swadesh de 200 términos. Las palabras en cada idioma fueron transcritas a mano en sesiones de trabajo que, tal como ya se explicó, contaron siempre con la presencia de dos hablantes. Todas las palabras fueron, además, grabadas empleando el micrófono interno de una grabadora ZOOMH4. Las grabaciones estéreo se hicieron en formato no comprimido WAV, a un ratio de 44,100 Hz y a 16 bits. Los datos gramaticales, por su parte, fueron recogidos a partir de un cuestionario escrito diseñado por Pilar Valenzuela y el primer autor de este artículo.
Los datos gramaticales y léxicos recogidos en el marco de esta investigación fueron cotejados con datos para otras dos lenguas pano: kakataibo e iskonawa. Los datos de estas dos lenguas fueron recogidos por el primer autor de este artículo en el marco de proyectos de investigación previos y tienen funciones cruciales en nuestro análisis: kakataibo es una lengua pano perteneciente a la rama más occidental de la familia y será empleada como outlayer, es decir, esta lengua representa la variedad lingüística más divergente en nuestra muestra. Por otro lado, la importancia de los datos del iskonawa radica en el hecho de que esta lengua ha sido considerada en la literatura como una lengua posiblemente relacionada con las lenguas del Purús (ver subsección 4.3): tal como ya se mencionó en la introducción, en este artículo buscamos dar algunas luces sobre la posición del iskonawa al interior de la familia lingüística pano.
2.2. Preprocesamiento de los datos
Siguiendo lo propuesto por Dunn (2014) para el empleo de métodos filogenéticos en los estudios lingüísticos, hemos preprocesado los datos obtenidos en el campo a partir de la lista Swadesh de 200 términos. Para ello, hemos observado los criterios siguientes.
a. Cada forma léxica es un carácter
El procesamiento tradicional para datos léxicos de naturaleza comparativa se basa en el principio de que cada significado de una lista cerrada constituye un carácter a comparar. Entonces, se determina si las formas para el mismo significado en dos lenguas distintas son cognadas o no. El método seguido aquí es distinto. En este estudio, tratamos a cada forma léxica encontrada como un carácter independiente y lo que se mide es su presencia o ausencia en las lenguas de nuestra muestra.
Ilustremos esta metodología tomando como ejemplo las diversas formas para el concepto ‘perro’ encontradas en nuestra base de datos: paʂdá, utʃíti, kamá(n), piru e induʔ. Según nuestra metodología, cada una de estas formas es tratada como un carácter y la pregunta es si cada uno de estos caracteres aparece en las variedades lingüísticas estudiadas. Entonces, es la presencia o ausencia de cada una de las formas en el corpus lo que se usa como punto de partida para la comparación. Estas presencias y ausencias son plasmadas en datos binarios (1 vs. 0), que son los que fueron procesados para el análisis (ver acápite b).
b. Se emplean valores númericos binarios.
La presencia o ausencia de cada forma se consigna para cada lengua empleando los valores númericos 1 y 0. La matriz de rasgos empleada en este estudio se parece más a la ilustrada en la tabla 4 que a la ilustrada en la tabla 3, la cual corresponde a una matriz comparativa de tipo más tradicional. En ambos casos, el concepto illustrado es ‘perro’.
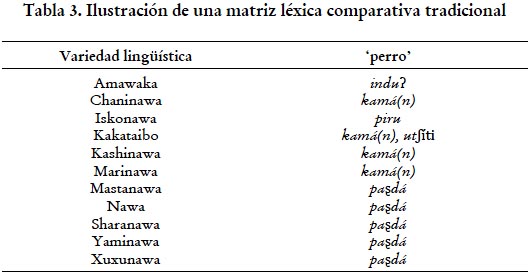
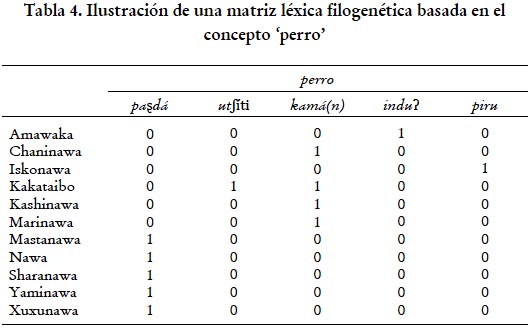
A partir de los doscientos significados de la lista Swadesh, obtuvimos un total de 516 caracteres, procesados de acuerdo a lo ilustrado en la tabla 4. Estos caracteres incluyen todas las formas léxicas en nuestra base de datos para 180 de los 200 conceptos de la lista Swadesh. Es importante mencionar que se optó por descartar de nuestro análisis final un total de 20 conceptos incluidos en la lista Swadesh que se revelaron especialmente difíciles de elicitar (ver principio (c)). Este tipo de procesamiento se reveló laborioso, pero nos permitió construir una matriz de rasgos empleable en los análisis explicados en la subsección 2.3.
c. Se filtraron los datos dudosos
El proceso de recojo de los datos léxicos reveló que algunos de los conceptos en la lista Swadesh son difíciles de elicitar y, por ello, suscitaron respuestas dudosas de parte de los hablantes. Esos casos fueron cuidadosamente anotados durante las sesiones de campo y, en el procesamiento final de los datos, fueron excluidos de los conteos y de las comparaciones.
Varios de estos conceptos de difícil elicitación estaban asociados a sufijos (‘si’, ‘como’, ‘en’, ‘porque’, ‘y’). Sin embargo, problemas similares se suscitaron en otros contextos. Conceptos como ‘tres’, ‘cuatro’ y ‘cinco’, que forman parte de la lista Swadesh, no contaban con términos en las lenguas estudiadas y los hablantes solían dar frases complejas que parecían acuñadas en el momento. Estas frases fueron catalogadas de dudosas. Es interesante señalar que entre estas entradas sin correspondencia léxica en las lenguas investigadas no solo encontramos número sino también conceptos culturalmente relevantes, como ‘cazar’, para el cual nos fue imposible encontrar una forma léxica para varias de las lenguas (los hablantes traducían ese concepto como ‘ir al monte’, ‘matar animal’, etc.). Conceptos culturalmente irrelevantes como ‘nieve’ tuvieron la misma suerte y no fueron incorporados a nuestra matriz comparativa final.
Del mismo modo, algunos conceptos de valor relacional o deíctico (derecha vs. izquierda o el pronombre de tercera persona) fueron finalmente excluidos del proceso de análisis, dado que su elicitación se mostró muy complicada.
Uno de los aprendizajes más significativos de este estudio es que es menester trabajar en una lista de tipo Swadesh más eficiente, en la que se excluyan conceptos relacionales de difícil elicitación (como pronombres de tercera persona, adposiciones y particulas deíciticas). Por otro lado, una lista de tipo Swadesh a emplearse con lenguas amazónicas no debería contener conceptos poco pertinentes en el contexto geográfico y cultural en el que estas lenguas son habladas.
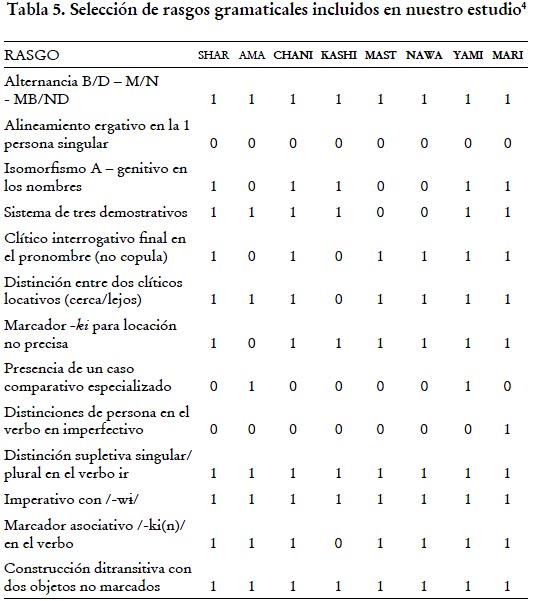
A diferencia del preprocesamiento de los datos léxicos, que ha sido muy arduo, el trabajo con los datos gramaticales se desarrollo de una forma más fluida. Básicamente, el cuestionario mencionado en la subsección 2.1 fue adaptado a una lista de 68 items formulados de manera tal que puedan ser respondidos a partir de afirmaciones de tipo sí / no. Posteriormente, se le atribuyó valores numéricos a cada una de estas posibilidades: "sí" recibió el valor numérico de "1", mientras que "no", el valor número de "0". De esta forma, se produjó una matriz de rasgos en la que cada característica gramatical fue tratada como un caracter, tal como se hizo para el material léxico. Ahora bien, es necesario explicar que la elaboración del listado de rasgos gramaticales será siempre un tanto arbitraria, ya que hubiera sido posible proponer más, proponer menos o proponer otros. La selección de estos rasgos se basa categorías relevantes desde una perspectiva pano y, de ninguna manera, es replicable en otros contextos. Hasta la fecha no contamos con un sistema de procesamiento de rasgos gramaticales para estudios comparativos que parta de un consenso relativamente extendido, tal como ocurre con la lista Swadesh (aunque esta lista léxica ha sido también el centro de importantes críticas y es en gran medida arbitraria; ver Holman et al. 2008).
Una ilustración de algunos de los items gramaticales en la lista mencionada son presentados en la tabla 5, que incluye además los valores numéricos correspondientes a las variedades lingüísticas purusinas estudiadas.
2.3. Procesamiento de los datos
Una vez culminado el preprocesamiento de los datos, el procesamiento de los mismos se condujo empleando el software SplitsTree4 (Hudson y Bryant 2006), diseñado especialmente para el análisis filogenético. Este programa ofrece un repertorio de los algoritmos más difundidos para este tipo de estudio y permite construir diversas clases de árboles y de redes filogenéticas a partir de matrices de datos similares a la que hemos descrito en la sección 2.2. En este artículo, hemos aplicado tanto redes filogenéticas (phylogenetic networks; Hudson y Bryant 2006; Bryant y Moulton 2004) como árboles de consenso basados en la mayoría (majority-ruled consensus trees; Michael et al. 2015) como recursos de formalización y presentación de los análisis de los datos (aunque se le ha dado una mayor importancia a las redes filogenéticas). A continuación, ofrecemos una breve descripción de cada método (ambos han sido aplicados a partir de las herramientas informáticas brindadas como parte del paquete básico de Splitstree4 (Hudson y Bryant 2006). Para ello, los datos obtenidos a partir del preprocesamiento descrito en la subsección 2.2 han sido insertados en Splitstree4, siguiendo la sintaxis de programación de dicho software.5
2.3.1. Redes filogenéticas
Las redes filogenéticas pueden ser de varios tipos y responden a principios diferentes (ver Hudson y Bryant 2006 para una tipología), pero lo que las une es el esfuerzo por incluir en su representación las potenciales colisiones entre las diversas formas de estructurar un conjunto de entidades o taxones a partir de una lista cerrada de rasgos o caracteres. Esto les da la apariencia más de una neurona que de un árbol de tipo tradicional, que ofrece una representación única basada en la selección de lo que se considera la mejor combinación.
Los análisis presentados en la sección 4 han sido formulados mediante redes filogenéticas. Para ello, hemos optado por un tipo específico de red conocida como Neighbor-net, que tiene cierta presencia en la literatura lingüística (Van Gijn 2014 es un ejemplo reciente en Sudamérica), aunque viene siendo también objeto de algunas críticas.6
2.3.2. Árboles de consenso basados en la mayoría
En la sección 5, por su parte, hemos recurrido a la inclusión de estructuras arbóreas de consenso basadas en la mayoría (mayorityruled consensus trees). Estos árboles se basan en la integración en una sola representación arbórea de los subgrupos que se manifiestan de forma más sistemática en el análisis de un conjunto de individuos o taxones y son también frecuentemente utilizados en estudios de corte lingüístico (ver, por ejemplo, Michael et al. 2015 para la familia Tupí Guaraní).
La razón por la que hemos combinado redes y árboles filo-genéticos en este estudio tiene que ver con las dificultades que encontramos al clasificar una de las lenguas estudiadas. Nos referimos al iskonawa, cuya pertenencia al grupo pano del Purús (que llamaremos de Pano de las Cabeceras, más adelante) termina siendo difícil de demostrar de forma definitiva. Confiamos que el emplear dos métodos distintos, basados en procesos matemáticos diferentes, contribuirá al mejor entendimiento del problema y nos permitirá dar una interpretación más confiable de los datos.
2.4. Almacenamiento de los datos
Todos los datos léxicos han sido puestos a disposición de los interesados en el Archivo Digital de Lenguas Peruanas del Departamento de Humanidades de la Pontificia Universidad Católica del Perú (PUCP) (http://repositorio.pucp.edu.pe/index/handle/123456789/15344). Desde esa plataforma es posible descargar tanto archivos de pdf con las transcripciones en alfabeto fonético internacional de las palabras de la lista Swadesh para cada lengua estudiada, como todas las grabaciones, segmentadas por hablante y por palabra, y ofrecidas a la comunidad científica en formato no comprimido wav (ver subsección 2.1, para más detalles).
3. Las lenguas pano del Purús y su clasificación
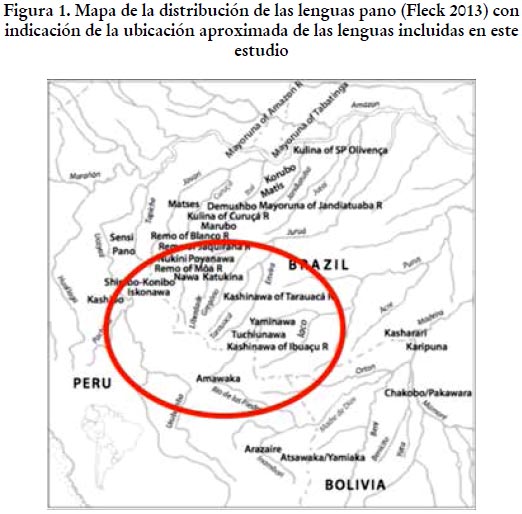
Las lenguas vivas y extintas que podrían haber pertenecido a la familia lingüística pano suman alrededor de 30. Actualmente, encontramos presencia de lenguas pano en el Perú (en los departamentos de Loreto, Huánuco, Ucayali y Madre de Dios), Brasil (en los estados de Acre, Amazonía y Rondônia) y Bolivia (en los departamentos de Beni y Pando). La mayor diversidad lingüística dentro de la familia y el mayor número de hablantes se encuentran en el Perú, aunque no contamos con cifras precisas. El mapa presentado en la figura 1, tomado y adaptado de Fleck (2013), muestra la ubicación actual de las distintas lenguas pano y señala con un círculo la ubicación aproximada de las lenguas documentadas en este estudio.
La primera clasificación de la familia lingüística pano basada en una aplicación del método comparativo vio la luz en la década de 1960 gracias a la tesis doctoral de Olivia Shell (1965), que fue publicada en español en 1975. Shell basa su agrupación en una comparación extensiva de material léxico de siete lenguas pano (tres de dichas lenguas corresponden a lenguas habladas en el Purús y se listan en negritas): amawaka, kapanawa, kakataibo, kashinawa, chakobo, marinawa y shipibo-konibo.7 Shell se concentra en ofrecer una explicación de los procesos a través de los cuales estas lenguas se han separado unas de otras; por lo tanto, su trabajo no es una clasificación completa de la familia, sino una descripción de cómo las lenguas en su muestra han evolucionado a partir de lo que la autora llama pano reconstruido (PR). Su propuesta es plasmada en la figura 2.
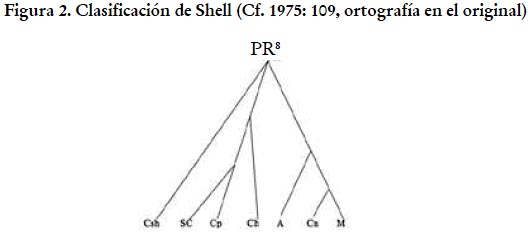
Las tres lenguas del Purús que Shell incluye en su estudio forman parte de la matriz de datos en la que se basa este artículo (ver Tabla 1) y en ese sentido, a pesar de los límites del trabajo de Shell, sus resultados son muy relevantes para nosotros. Entre los puntos que merecen nuestra atención, podemos listar los siguientes: (1) Shell propone que amawaka (A), kashinawa (Cn) y marinawa (M) forman un subgrupo; (2) dentro de este subgrupo, amawaka (A) es la lengua más divergente. Esto se condice con nuestros resultados.
Ocho años después de la publicación de la tesis de Shell, D’Ans (1973) ofrece un análisis léxico-estadístico de diez lenguas pano, entre las que se incluye cuatro lenguas claramente purusinas y el iskonawa, tal como se indica en negritas: kakataibo, pano, shipibo, kapanawa, amawaka, iskonawa, kashinawa, yaminawa, sharanawa y chakobo. Basándose en datos de estas lenguas, D’Ans propone una clasificación interna de la familia en la que se distingue cinco ramas: pano del Ucayali, pano preandino, Pano de las cabeceras, pano del Beni (Bolivia) y pano norteño. En su grupo pano de las cabeceras, D’Ans incluye las lenguas del Purús, tal como se muestra a continuación en la tabla 6. Es importante notar que las lenguas incluidas por el autor se corresponden en gran medida con las empleadas en este estudio, las mismas que se señalan en negritas.

En el caso de D’Ans, notamos que se distingue cuatro subgrupos dentro del pano de las cabeceras. Además, el autor incluye al iskonawa (Isconahuano) dentro de este grupo (ver subsección 4.3), algo que no ocurrirá en las clasificaciones posteriores, pero que parece encontrar sustento en nuestros datos.
Pasaron más de 25 años antes de que apareciera una nueva clasificación de las lenguas pano. En 1999, Loos propone la existencia de 30 lenguas, de las cuales 22 se agrupan en tres subgrupos tentativos (el subgrupo yaminawa, que es el que nos interesa en este estudio, el subgrupo chakobo y el subgrupo kapanawa). Por otra parte, ocho lenguas se postulan como no agrupadas. El subgrupo yaminawa es presentado a continuación en la tabla 7 y, tal como lo hemos hecho antes, las lenguas o variedades lingüísticas incluidas en nuestro corpus son señaladas en negritas.

En el caso de Loos encontramos que se propone un subgrupo yaminawa que alberga a todas las lenguas del Purús. Lamentablemente, el autor no ofrece una clasificación interna de este subgrupo y todas las lenguas incluidas allí son listadas de manera arbitraria. Otro dato importante es que Loos no incluye al iskonawa. Ello constituye una diferencia con la clasificación de D’Ans. Un aspecto final a considerar tiene que ver con el uso poco convencional de algunos glotónimos. Desafortunadamente, algunos de los nombres que Loos usa para referirse a algunas de las lenguas o variedades lingüísticas del área no son de fácil identificación. Además, no se entiende del todo las razones por las que lista en una misma línea a más de una denominación lingüística. Es decir, no se llega a saber si se trata de nombres de dialectos distintos o de sinónimos.
Fleck (2013) propone una clasificación muy detallada de las lenguas pano. En su propuesta, existen dos ramas mayores en la familia: la rama mayoruna y la rama principal (mainline). La clasificación de Fleck (2013), que incluye 18 lenguas vivas y 14 lenguas extintas (pero documentadas), propone un "Subgrupo de las cabeceras" al interior de la rama principal. Este subgrupo se presenta en la tabla 8, donde las lenguas incluidas en nuestra base de datos aparecen en negritas (nótese que en términos de Fleck varias de las "lenguas" documentadas por nosotros corresponden a dialectos).

La clasificación de Fleck incluye cinco unidades lingüísticas (que el autor considera lenguas) al interior de su subgrupo de las cabeceras, dos de ellas ya extintas. El panorama es similar al presentado por D’Ans: tenemos kashinawa, amawaka y yaminawa (este último sería un conjunto de dialectos, varios de los cuales se corresponden con variedades lingüísticas recogidas por nosotros). Un punto crucial a tomar en cuenta es que el iskonawa no es una lengua de las cabeceras para Fleck.
Finalmente, Valenzuela y Guillaume (2016) postulan en una reciente clasificación de las lenguas pano un subgrupo de las cabeceras que reúne a todas las lenguas del Purús. En este caso, se proponen tres unidades lingüísticas, equiparables a lenguas, similares a las propuestas anteriormente por otros autores: amawaka, kashinawa y yaminawa (que se postula como un complejo dialectal, en forma similar a lo propuesto por Fleck 2013). Potenciales relaciones entre el iskonawa y las lenguas de las cabeceras no son planteadas por los autores. La propuesta de Valenzuela y Guillaume (2016) se presenta en la tabla 9, en donde las lenguas de nuestro corpus aparecen en negritas.
En esta sección hemos presentado las distintas propuestas para el tratamiento de las lenguas pano del Purús o "de las cabeceras". Las similitudes son claras: con la excepción de Loos (1999), los distintos autores apuntan a la existencia de, por lo menos, tres unidades lingüisticas potencialmente equiparables a lenguas: amawaka, kashinawa y yaminawa. En el caso del yaminawa, estaríamos ante un complejo dialectal que albergaría variedades que aparecen con nombres propios en la literatura. Un detalle que no debe perderse de vista y no debe confundir al lector es la variación en el número y los nombres de las lenguas presentadas por cada autor. Muchos de estos nombres han sido brevemente mencionados en documentos tempranos que, como se sabe, están abiertos a confusiones y contradicciones.10 Lo importante es tener en cuenta que algunas de las lenguas presentadas en las distintas clasificaciones se condicen con las lenguas incluidas en la muestra de este estudio. Son estas lenguas las que serán más relevantes para la discusión posterior.
Finalmente, queda abierta la pregunta sobre la posición del iskonawa en relación con el grupo del Purús o de las cabeceras. Los autores citados parecen tener opiniones distintas al respecto. En la sección 4, exploramos este y otros puntos a partir de la aplicación de la metodología presentada en la sección 2.
4. Resultados
Nuestro estudio de las variedades lingüísticas pano habladas en el Purús peruano se propone contribuir a la evaluación de las propuestas de clasificación presentadas en la sección 3. Para ello, en esta sección nos basamos en el empleo de un método matemático denominado Neighbor-net, que ha sido usado en los estudios filo-genéticos y está disponible como parte del paquete de software del programa Splitstree4 (Hudson 1998). Básicamente, buscamos responder a las siguientes preguntas de investigación:
-
¿Constituyen las lenguas del Purús una agrupación en términos no solo geográficos sino también léxicos y gramaticales, tal como ha sido propuesto en todas las clasificaciones internas de la familia pano?
-
Si la respuesta a la pregunta anterior es afirmativa, ¿es posible proponer subagrupaciones lingüísticas al interior de esta agrupación?
-
De existir tales agrupaciones, ¿se corresponden con las que han sido propuestas con anterioridad en la literatura (ver sección 3)?
-
Finalmente, ¿cuál es la posición del iskonawa en relación con las lenguas habladas en la región del Purús?
Estas preguntas han sido ya abordadas en estudios previos, aunque ninguno de ellos se haya concentrado en las lenguas del Purús específicamente y ninguno haya aplicado los métodos filo-genéticos empleados en este estudio. Es de particular interés determinar si el empleo de esta nueva metodología refrenda o contradice los análisis propuestos en la literatura (Michael et al. 2015 ofrecen un estudio más ambicioso, pero de objetivos similares para toda la familia lingüística Tupí-Guaraní).
Los detalles de los métodos filogenéticos empleados en este estudio han sido ya descritos en la sección 2. Básicamente, se han recogido listas léxicas de tipo Swadesh y se han elicitado cuestionarios gramaticales para un conjunto de variedades pano habladas en el Purús peruano (se estudiarán ocho de estas variedades en la discusión que sigue). Estos datos han sido procesados de acuerdo con los procedimientos empleados para el análisis filogenético de datos lingüísticos (ver sección 2 y Dunn 2014) y han sido organizados en una base de datos que, además, incluye información tanto léxica como gramátical sobre otros dos idiomas pano: kakataibo (la lengua pano más occidental) e iskonawa (una lengua pano potencialmente relacionada con las lenguas del Purús). El kakataibo ha sido incluido en los análisis a continuación como elemento de control (o outlayer).
En lo que sigue presentamos los resultados de nuestro estudio. En la sección 4.1. ofrecemos los resultados a partir de rasgos léxicos; en la sección 4.2 brindamos los resultados de nuestros datos gramaticales (que incluyen rasgos fonológicos); y en la sección 4.3 discutimos la posición del iskonawa en relación con las lenguas pano del Purús o de las cabeceras (a partir de evidencia gramatical y léxica). Lo que veremos es que, en general, lo propuesto en la literatura sobre las lenguas del Purús coincide con lo encontrado en este nuevo estudio, aunque hay algunos puntos que requieren atención y serán el centro de la discusión presentada en la sección 5.
Más específicamente, veremos que —aunque el carácter purusino del yaminawa es indiscutible— encontramos diferencias con respecto a la posición de esta lengua de acuerdo a si evaluamos datos léxicos o gramaticales. Por su parte, quedará en evidencia que la inclusión o exclusión del iskonawa como lengua purusina resulta difícil de determinar, tal como puede concluirse a partir de la revisión de la literatura. Nuestra solución se basa en el empleo de una metodología distinta (árboles de consenso basados en la mayoría). Nuestro objetivo es que el algoritmo en el que se basan los árboles de consenso nos dé luces sobre la adecuada interpretación de las distancias halladas entre las lenguas de las cabeceras y el iskonawa, y nos lleve a la identificación de clusters relativamente confiables. Aplicando dicho método, postularemos al iskonawa como una lengua muy cercana a las lenguas del Purús.
4.1. Rasgos léxicos
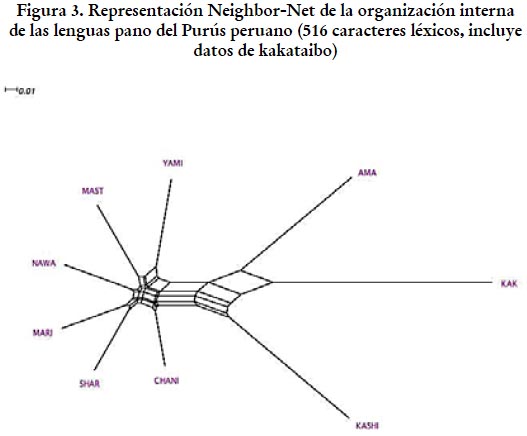
Los resultados obtenidos a partir de las 516 entradas léxicas procesadas son presentados en la figura 3. Estos revelan aspectos cruciales para responder a algunas de las preguntas de investigación que motivan este estudio. De acuerdo a lo esperado, el kakataibo muestra su posición de outlayer y toma una distancia significativa con respecto a las demás lenguas comparadas. Si tomamos al kakataibo como punto de distancia máxima en la muestra, se vislumbra un patrón bastante claro que sugiere dos ideas cruciales: (i) el kakataibo se distancia considerablemente del resto de lenguas y, por tanto, las lenguas pano del Purús sí muestran un grado de unidad que permite postularlas como un subgrupo al interior de la familia pano; y (ii) kashinawa y amawaka muestran un nivel prácticamente equivalente de divergencia al interior del agrupamiento purusino, tal como ha sido propuesto en otras clasificaciones reseñadas en este artículo (excepto Loos 1999). Otro dato interesante es que (iii) encontramos hacia la izquierda de la figura una configuración de tipo estrella, que no permite postular una organización interna compleja entre las lenguas allí listadas. En términos de los rasgos léxicos, encontramos una suerte de continuo de variedades lingüísticas que se adecua muy bien a la idea de un "complejo dialectal". Este complejo dialectal incluye al yaminawa y, por lo tanto, nuestros resultados coinciden con lo postulado por Fleck (2013), y Valenzuela y Guillaume (2016). Es decir, en términos del léxico, la idea de complejo dialectal yaminawa cobra total sentido.
4.2. Rasgos gramaticales
Los resultados obtenidos a partir de los 68 datos gramaticales (que incluyen ocho rasgos fonológicos) son presentados en la figura 4. En primer lugar, notamos que (i) kakataibo, de acuerdo a lo esperado, se posiciona otra vez como el outlayer dentro de la muestra. Si tomamos esta lengua como el punto de distancia máxima, entonces comprobamos otra vez que, tal como se ha sugerido en la literatura precedente, el agrupamiento de las lenguas del Purús al interior de la familia pano encuentra sustento en la gramática. Sin embargo, (ii) kashinawa y amawaka y yaminawa son, esta vez, las lenguas más divergentes al interior esa agrupación; mientras que (iii) las lenguas hacia la izquierda son menos similares entre sí que lo que encontrábamos en el léxico.
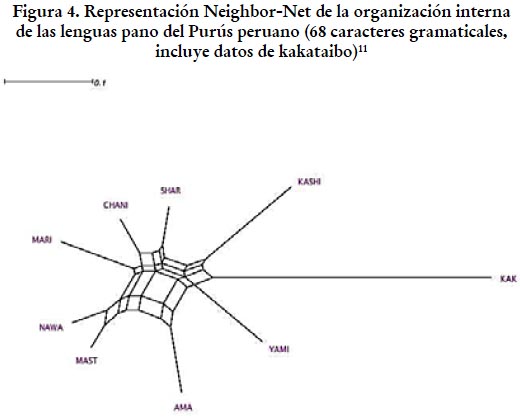
El analisis filogenético a partir del método de Neighbor-Net sugiere, entonces, dos aspectos cruciales. El primero se condice con lo dicho por otros autores sobre las lenguas del Purús: kashinawa y amawaka pueden postularse ciertamente como unidades lingüísticas divergentes, a las que podríamos considerar lenguas. Sin embargo, nuestros datos apuntan hacia la idea de que el complejo dialectal yaminawa, propuesto por Fleck (2013) y Valenzuela y Guillaume (2016), se aprecia solo en el léxico y no se percibe en relación con los datos gramaticales. Gramaticalmente, el yaminawa es en realidad tan divergente como el kashinawa (y pareciera ser más divergente que el amawaka). Esto constituye un dato muy importante para la comprensión de la estructura interna de la familia pano y en la sección 5 volveremos a este punto.
4.3. La posición del iskonawa en el subgrupo Purús12
El idioma iskonawa es particularmente interesante para el estudio de las lenguas pano del Purús. D’Ans (1973) incluye un subgrupo "isconahuano" en su agrupación pano de las cabeceras, que es la que reúne en su propuesta a las lenguas del Purús. En un estudio más reciente, Fleck (2013), por su parte, sostiene que, aunque es muy similar al idioma poyanawa y lo agrupa con este, el iskonawa tiene un gran parecido con el shipibo-konibo y, crucialmente, con el amawaka. En realidad, Fleck (2013) desliza la idea de que el iskonawa es una suerte de idioma intermedio que podría tener nexos con el subgrupo de lenguas del Purús. Casi en concordancia con esto, Zariquiey (2015) refiere que los propios iskonawas sostienen haber tenido una larga historia que los une a los grupos purusinos, particularmente a los yaminawa, con quienes habrían convivido por largas temporadas. En los párrafos siguientes, exploramos, siguiendo la metodología de Neighbor-net, las posibles relaciones de similitud lingüística entre el iskonawa y las lenguas del Purús.
Empecemos con la gramática, ya que resulta ser el ámbito menos problemático. Si incluimos nuevamente al kakataibo como outlayer, encontramos un patrón similar al descrito ya en la sección 4.2. Es decir, el kakataibo representa el punto de distancia máxima, mientras que el amawaka, el kashinawa y el yaminawa son otra vez las lenguas divergentes. El punto crucial es que el iskonawa mantiene una cercanía considerable con el conglomerado purusino y se alinea con él mostrando una distancia relativa solo ligeramente mayor a la que muestran el yaminawa y el kashinawa. El resultado presentado en la figura 5 revela que el iskonawa tiene una base gramatical indiscutiblemente purusina. Si solo empleásemos datos gramaticales, nuestra conclusión sería que el iskonawa debería ser postulada como parte del subgrupo de lenguas pano del Purús.
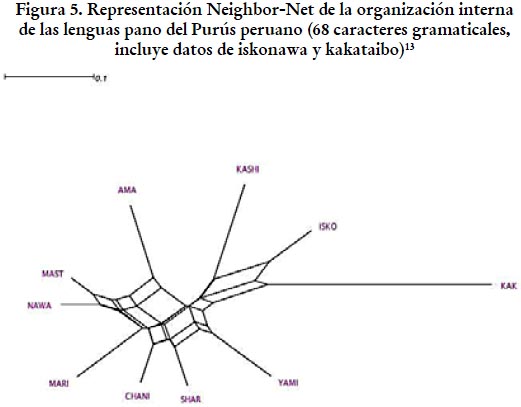
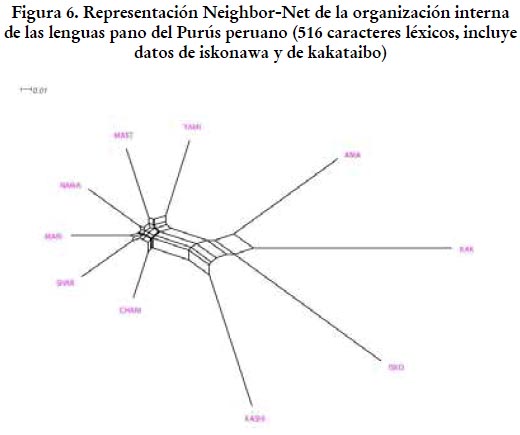
Cuando estudiamos los datos léxicos del iskonawa, sin embargo, el panorama se torna menos claro. Léxicamente, el yaminawa vuelve a formar parte del continuo dialectal que ha sido descrito en otros estudios y deja como lenguas divergentes al amawaka, al kashinawa y al iskonawa. Si bien las variedades lingüísticas divergentes (amawaka, kashinawa e iskonawa) se separan considerablemente de las lenguas del Purús y se acercan mucho al outlayer, la cercanía del iskonawa con el kakataibo es tan fuerte que abre la pregunta sobre su adecuada clasificación. Si tomásemos solo el léxico, es probable que nuestra conclusión sería que el iskonawa no es una lengua pano purusina. Sin embargo, esto podría llevarnos también a excluir al amawaka y al kashinawa de nuestro grupo de las cabeceras. Aquí, entonces, encontramos un problema de análisis, ya que separar al iskonawa al mismo tiempo abriría preguntas sobre la posición de esas dos lenguas y eso es algo que contradice nuestras intuiciones y las de todos los autores que han trabajado en clasificaciones de la familia pano (véase sección 3). Retornaremos a este punto en la sección 5.
5. Discusión de los resultados
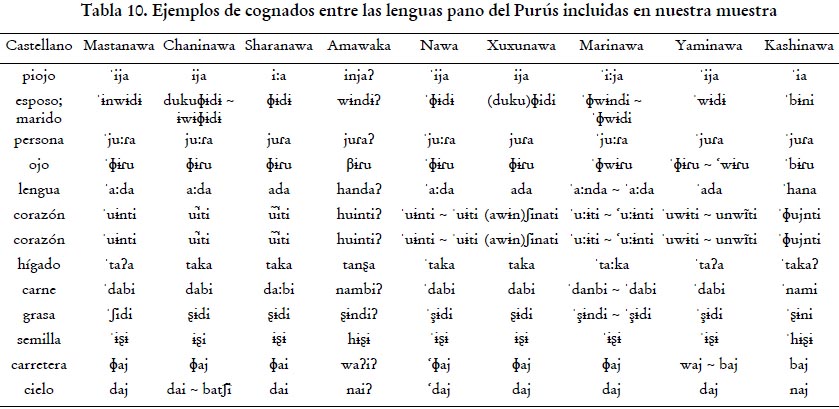
Los datos presentados hasta aquí apuntan claramente hacia la existencia de un conglomerado de lenguas que debe analizarse como un subgrupo al interior de la familia lingüística pano. Esto es importante, ya que nos permite concluir que nuestro método apoya lo que se dice en la literatura. En otras palabras, los estudios comparativos emprendidos por los autores que nos preceden (que se basan en la noción tradicional de cognado) y el nuestro (que emplea los principios filogenéticos explicados en la sección 2) sugieren de forma general los mismos patrones clasificatorios y concluyen que las lenguas purusinas estudiadas pueden ser agrupadas en una sola unidad o subgrupo. En concordancia con lo propuesto en la literatura precedente, llamaremos a este subgrupo pano de las cabeceras. Las lenguas estudiadas muestran un alto grado de semejanza, que se manifiesta en una lista significativa de correspondencias léxicas (o cognados) entre ellas. Algunos de estos cognados son presentados a continuación (pero es importante mencionar que algunos de ellos probablemente se remonten a la protolengua y al ser retenciones no son de utilidad para fines clasificatorios; véase Oliveira 2014).
Ahora bien, los resultados de nuestro estudio no son sencillos de interpretar en tanto que encontramos divergencias entre lo visto para el léxico y lo visto para la gramática. Estas divergencias abren interesantes preguntas sobre la posición y naturaleza de dos de las lenguas en nuestra muestra: yaminawa e iskonawa.
Empecemos por el yaminawa ¿Por qué el yaminawa es gramaticalmente una lengua purusina divergente, tal como ocurre con el amawaka y el kashinawa, mientras que, en lo que compete al léxico, se alinea con otras lenguas en un complejo dialectal? Existen (por lo menos) dos explicaciones posibles para esta situación: (i) el yaminawa ha experimentado cambios gramáticales y fonológicos que la han separado de sus variedades hermanas (con quienes comparte todavía mucho léxico); (ii) el yaminawa ha experimentado cambios léxicos fruto del contacto con otras lenguas del área. Ambas explicaciones, en realidad, no son excluyentes y pueden darse al mismo tiempo. Sin embargo, los datos presentados aquí parecen sugerir la existencia de una suerte de nivelación léxica entre un grupo de lenguas de las cabeceras. Esto se aprecia en el hecho de que los datos gramaticales y fonológicos no solo muestran al yaminawa como una lengua divergente, sino que además revelan subagrupaciones entre las lenguas purusinas menos divergentes: chaninawa-sharanawa; marinawa y nawa-mastanawa, tal como se señala a continuación.
Tal ordenamiento no se aprecia en el caso de los datos léxicos, que, por un lado, incluyen al yaminawa entre las lenguas no divergentes y, por el otro, muestran un patrón de tipo estrella en el que no es posible proponer ninguna subagrupación clara (véase figura 3). Esto podría sugerir que, en realidad, los efectos areales han producido una homogeneización léxica no solo en el yaminawa, sino en todas las lenguas mencionadas. Estas lenguas, aunque muy parecidas, parecen tener un mayor grado de diversificación interna en términos gramaticales y fonológicos. Ello resulta en los patrones que se aprecian en la figura 7.
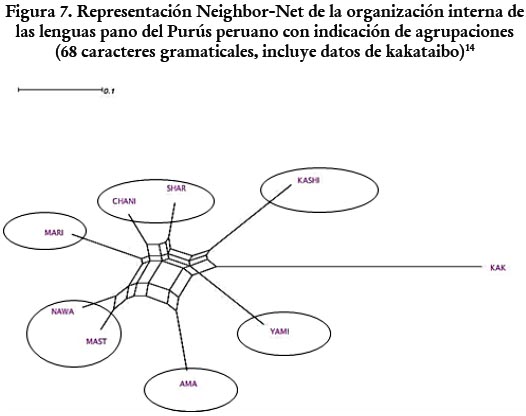
Los datos presentados aquí, entonces, sugieren que en realidad la idea de un complejo dialectal "yaminawa" (Fleck 2013; Valenzuela y Guillaume 2016) provendría más de la evaluación de datos léxicos que de datos gramaticales. La consideración de datos gramaticales sugiere una mayor diversificación al interior de ese complejo dialectal. Esto es algo a lo que debemos prestar atención, considerando que el préstamo léxico es una consecuencia directa del contacto areal y podría estar nivelando variedades lingüísticas que en realidad eran más divergentes antes del contacto hipotetizado aquí.
Esta diferencia entre el comportamiento léxico y gramatical de las lenguas pano no es nuevo y ha sido ya referido en la literatura. En realidad, la misma Shell (1965: 11) señalaba que "[a]lthough Panoan languages share a large number of cognate lexical roots, suffixes differ greatly in form and use". Entonces, este escenario aplica no solo a las lenguas de las cabeceras, sino a toda la familia y no cuenta con una explicación del todo satisfactoria. Nuestros datos parecen apuntar hacia la idea de una nivelación léxica muy fuerte en la región de las cabeceras. Sin embargo, la posibilidad de que lenguas como el yaminawa hayan atravesado por procesos intensos de innovación gramatical y fonológica (ver nuestra explicación (i) más arriba) no es del todo improbable. Por ejemplo, de acuerdo con nuestros datos, el yaminawa es fonológicamente muy divergente en relación con sus lenguas hermanas del Purús y tiene cambios y alternancias poco difundidas en esa área: β >ɸ > h; k > ʔ y ɾ > l. Todos estos cambios parecen ser innovaciones (aunque Oliveira 2014 reconstruye una l para protopano). Es decir, la posibilidad de que la similitud léxica sea reveladora de un estado más conservador y que la gramática de lenguas como el yaminawa sea innovadora no puede descartarse. En realidad, el tema requiere de más investigación y podría dar importantes luces para la comprensión de toda la familia. Lo importante es que, independientemente de cuál sea la explicación que asumamos, el llamado complejo dialectal yaminawa se aprecia solo en el léxico. Esto constituye un hallazgo relevante para la lingüística pano.
Creemos que una situación contraria es apreciada en relación con el iskonawa. En el caso de esta lengua, sus rasgos gramaticales y fonológicos parecen acercarla más a las lenguas del Purús que sus rasgos léxicos. En realidad, gramaticalmente la base purusina del iskonawa resulta casi indiscutible y los datos sugieren que el nivel de divergencia mostrado por esta lengua es prácticamente equivalente al que muestran el yaminawa y el kashinawa. Basados solo en datos gramaticales, proponer que el iskonawa es una lengua purusina parece adecuado (véase la figura 5). El problema surge con el léxico, en relación con el cual, como muestra la figura 6, el iskonawa se acerca demasiado al outlayer (kakataibo). El asunto es que, en general, las lenguas purusinas divergentes se alejan considerablemente del complejo dialectal yaminawa. Esto añade una complicación al análisis, ya que, si consideramos al iskonawa como una lengua no purusina, nada impide que el amawaka y el kashinawa corran la misma suerte. En realidad, establecer el corte entre las lenguas purusinas y las no purusinas en esquemas como el presentado en la figura 6 puede devenir en un resultado arbitrario. Es en este contexto que optamos por introducir un segundo método a nuestro análisis y produjimos, a partir de nuestros datos, un árbol de consenso basado en la mayoría. En este árbol, las variedades lingüísticas fueron organizadas en un esquema en el que es posible identificar una primera agrupación en la que el kakataibo es separada del resto de lenguas en la muestra (esta primera agrupación correspondería al nivel de los subgrupos: subgrupo de las cabeceras vs. kakataibo). Hay una segunda organización que divide el subgrupo de las cabeceras en cuatro entidades, cada una identificable como una lengua: amawaka, continuo dialectal yaminawa, iskonawa y kashinawa. Finalmente, encontramos un tercer nivel de agrupación, que coloca juntas a todas las variedades que conforman el continuo dialectal referido. Lo importante en relación con el análisis del léxico empleando un árbol de consenso basado en la mayoría es que el algoritmo separa al kakataibo del resto de lenguas y coloca al iskonawa dentro del subgrupo de las cabeceras.
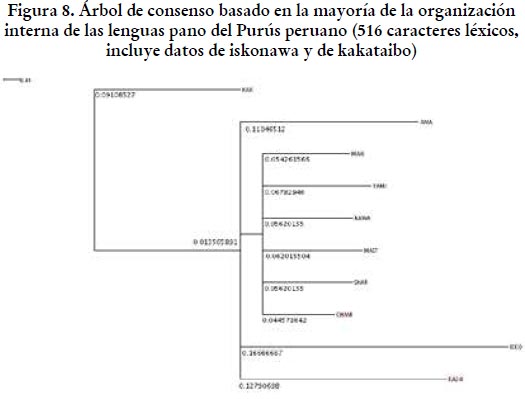
Tal como se aprecia en la figura 9, si aplicamos la misma técnica a los datos gramaticales, la separación entre kakataibo y el resto de lenguas en nuestra muestra se reafirma. Un dato muy interesante que se encuentra en la figura 9 es que, nuevamente, la idea del complejo dialectal yaminawa se pierde, lo cual reafirma nuestra hipótesis de que tal continuo se aprecia solo en el léxico.
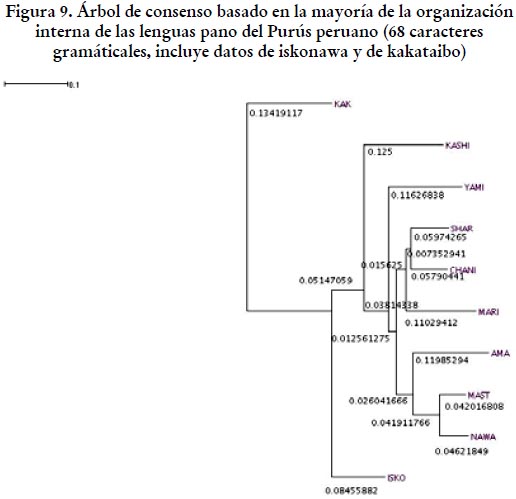
Entonces, aunque el carácter purusino del iskonawa (postulado por D’Ans 1973, por ejemplo) es difícil de determinar, los árboles de consenso basados en la mayoría que hemos presentado en esta sección sugieren que el corte estadísticamente más adecuado es aquel que separa al kakataibo del resto de lenguas y que, por lo tanto, pese a las dificultades, el iskonawa es una lengua muy cercana a las del Purús. La cercanía puede interpretarse como pertenencia al grupo pano de las cabeceras (D’Ans 1973), como adscripción a un grupo cercano o, en la línea con lo propuesto por Fleck (2013), como evidencia de que el iskonawa podría ser una lengua intermedia o mixta, atribuible a dos grupos diferentes. Solo un estudio más ambicioso ofrecerá más luces sobre este tema.
6. Conclusiones
El presente estudio presenta los resultados de la aplicación de métodos filogenéticos a un corpus léxico y gramatical de ocho lenguas pano habladas en el Purús (Ucayali, Perú), a partir de datos de primera mano recogidos por los autores. Nuestros datos muestran que, tal como ha sido propuesto en todas las clasificaciones de la familia pano, es necesario postular un subgrupo de lenguas del Purús o de las cabeceras. Ahora bien, se han encontrado diferencias entre los datos léxicos y gramaticales. Ello constituye posible evidencia de efectos areales en la configuración lingüística de la región. En realidad, el llamado "complejo dialectal yaminawa" (Fleck 2013; Valenzuela y Guillaume 2016) se aprecia únicamente en el léxico de las lenguas implicadas y sugiere un proceso de nivelación léxica fruto del contacto. Nuestros datos muestran que el referido complejo dialectal no se aprecia tan claramente en los datos gramaticales. Más allá de estas diferencias, nuestro estudio muestra importantes similitudes entre los resultados obtenidos mediante la aplicación de los métodos filogenéticos y el método histórico-comparativo tradicional. Esto es importante, porque el hecho de encontrar correspondencias entre resultados basados en métodos tan distintos sugiere que estos resultados tienen alta probabilidad de ser correctos.
Por otro lado, otro de los puntos importantes discutidos en este artículo es el de la posición del iskonawa en relación con el grupo pano de las cabeceras. Nuestra propuesta es que esta lengua revela una base gramatical purusina, aunque léxicamente sea más divergente. No podemos descartar que estas diferencias léxicas se deban a contactos con una lengua pano no purusina, como el shipibo-konibo. Más allá de estas diferencias léxicas, la aplicación de árboles de consenso muestra que el iskonawa es bastante cercano a las lenguas del grupo de las cabeceras. En el supuesto de que más datos revelen que no debe clasificarse dentro de dicho grupo, el iskonawa será parte de un grupo muy próximo o una suerte de lengua intermedia.
REFERENCIAS BIBLIOGRÁFICAS
Bryant, David y Vincent moulton 2004. Neighbor-Net: An Agglomerative Method for the Construction of Phylogenetic Networks. Molecular Biology and Evolution. 21, 2, 255-265. https://doi.org/10.1093/molbev/msh018. [ Links ]
D’ans, Marcel 1973. Reclasificación de las lenguas an y datos glotocronológicos para la etnohistoria de la Amazonía peruana. Revista del Museo Nacional. 34, 349- 369.
Donnelly, Vivian Wauters, Sérgio Meira y Zachary O’Hagan 2015. A Bayesian Phylogenetic Classification of Tupí-Guaraní. Liames. 15, 2, 193-221. https://doi.org/10.20396/liames.v15i2.8642301.
Fleck, David W. 2013. Panoan languages and linguistics. Anthropological Papers of the American Museum of Natural History, 99. https://doi.org/10.5531/sp.anth.0099. [ Links ]
Gijn, Rik Van 2014 Subordination strategies in South American languages: nominalization. En The native languages of South America: origins, development, typology. Eds., L. O’Connor y P. Muysken. Cambridge: Cambridge University Press, 274-296. https://doi.org/10.1017/cbo9781107360105.015.
Holman, Eric W., Søren WicHmann, Cecil H. Brown, Viveka Velupillai, Daniel H. Huson y David Bryant 2006. Application of Phylogenetic Networks in Evolutionary Studies. Molecular Biology and Evolution. 23, 2, 254-267. https://doi.org/10.1093/molbev/msj030. [ Links ]
Loos, Eugene E. 1999 "Pano". En The Amazonian Languages. Eds., R. M. W. Dixon y Alexandra Y. Aikhenvald. Cambridge: Cambridge University Press, 227-249. [ Links ]
Müller, André y Dik Bakker 2008. Explorations in Automated Language Classification. Folia Lingüística. 42, 2, 331–354. https://doi.org/10.1515/flin.2008.331. [ Links ]
Oliveira, Sanderson 2014 Contribuições para a reconstrução do Protopáno. Tesis de doctorado. Universidad de Brasilia. [ Links ]
Shell, Olive A. [1965] 1975 Estudios Panos III: Las Lenguas Pano y su Reconstrucción. Yarinacocha, Pucallpa: Instituto Lingüístico de Verano. [ Links ]
Valenzuela, Pilar y Antoine Guillaume 2016 Estudios sincrónicos y diacrónicos sobre lenguas Pano y Takana: una introducción. Estudios sincrónicos y diacrónicos sobre lenguas Pano y Takana. Amerindia. 39, 1, 1-49. [ Links ]
Zariquiey, Roberto 2015 Bosquejo Gramatical de la lengua iskonawa. Boston: Centro de Estudios Literarios Antonio Cornejo Polar. [ Links ]
-
* Agradecemos muy especialmente a los hablantes de las lenguas pano estudiadas en este artículo que compartieron pacientemente con nosotros su conocimiento y nos permitieron construir la base de datos que dio origen a este artículo. Por otro lado, agradecemos a la Pontificia Universidad Católica del Perú por su apoyo a esta investigación. Finalmente, agradecemos a Pilar Valenzuela por sus comentarios y contribución a este artículo.
-
1 Un estudio que tome en cuenta un número mayor de lenguas pano podría posicionar al iskonawa dentro de un subgrupo independiente al purusino (Fleck 2013). Si ese fuera el caso, sin embargo, este subgrupo hipotético sería siempre cercano al subgrupo del Purús.
-
2 Proyecto 2015-01-0072: Aproximación filogenética a la clasificación interna de la familia lingüística pano, financiado por la Pontificia Universidad Católica del Perú (PUCP) a través de su Dirección de Gestión de la Investigación (DGI).
-
3 Los datos recogidos durante estos periodos fueron revisados durante una temporada de trabajo de campo realizada hacia finales de 2016, gracias a un fondo para trabajo de campo otorgado a dos de los autores por la Red Peruana de Universidades (RPU).
-
4 AMA = amawaka; CHANI = chaninawa; KASHI = kashinawa; MARI = marinawa; MAST = mastanawa; NAWA = nawa; SHAR = sharanawa; YAMI = yaminawa.
-
5 El programa puede ser descargado desde http://www.splitstree.org.
-
6 Es importante mencionar que la eficiencia del algoritmo Neighbor-net ha sido ya evaluada y validada por Hudson y Bryant (2006), quienes aplicaron el algoritmo a cadenas de ADN ya codificadas con resultados bastante precisos y similares a los obtenidos a partir de métodos computacionalmente más costosos.
-
7 Shell (1965; 1975) también ofrece esporádicamente materiales para otras lenguas de la familia pero son escasos y no forman parte de su argumentación central.
-
8 PR= ‘pano reconstruido’; Csh= ‘kakataibo’; SC= ‘shipibo-konibo’; Cp= ‘kapanawa’; Ch= ‘chakobo’; A= amawaka; Cn= ‘kashinawa’; M= ‘marinawa’.
-
9 Lenguas subrayadas; dialectos en cursivas; † = extinto; * = obsolescente. Los dialectos con diferencias menores son listadas en la misma línea.
-
10 En realidad estas denominaciones parecen corresponderse con clanes y no con grupos étnicos distintos y, tal como nosotros mismos lo hemos podido comprobar, las identidades en torno a estas denominaciones son altamente variables y dinámicas. Los propios hablantes pueden manifestar adscripciones a más de una de estas "etnias". Es decir, un mismo hablante puede considerarse sharanawa y mastanawa, sin que eso suponga ningún problema o contradicción.
-
11 AMA = amawaka; CHANI = chaninawa; KAK = kakataibo; KASHI = kashinawa; MARI = marinawa; MAST = mastanawa; NAWA = nawa; SHAR = sharanawa; YAMI = yaminawa.
-
12 Los datos del iskonawa provienen de un estudio anterior realizado por el primer autor de este artículo. Este estudio formó parte de un proyecto de investigación de tres años de duración titulado Documentación y revitalización del iskonawa: un proyecto interdisciplinario. El referido proyecto se alojó en dos universidades: la Universidad de Tufts (Boston) y la Pontificia Universidad Católica del Perú (Lima). Los datos provienen de los últimos hablantes de la lengua. La mayoría de estos hablantes son bilingües y hablan también shipibo-konibo (además de tener algún dominio de castellano) (para mayor información, véase Zariquiey 2015).
-
13 AMA = amawaka; CHANI = chaninawa; KAK = kakataibo; KASHI = kashinawa; MARI = marinawa; MAST = mastanawa; NAWA = nawa; SHAR = sharanawa; YAMI = yaminawa.
-
14 AMA = amawaka; CHANI = chaninawa; KAK = kakataibo; KASHI = kashinawa; MARI = marinawa; MAST = mastanawa; NAWA = nawa; SHAR = sharanawa; YAMI = yaminawa.
Fecha de recepción: 18/02/2016
Fecha de aceptación: 07/02/2017

