










Servicios Personalizados
Revista

Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkLexis
versión impresa ISSN 0254-9239
Lexis vol.43 no.2 Lima Jul./Dic. 2019
http://dx.doi.org/10.18800/lexis.201902.003
ARTÍCULOS
Proceso de adaptación de los Inventarios de Desarrollo Comunicativo MacArthur-Bates al castellano estándar del Perú*
María Blume del Río1, María Fernández-Flecha1, Andrea Junyent Moreno1, Talía Tijero Neyra1,2
1 Pontificia Universidad Católica del Perú. Lima, Perú.
2 Universidad de Tecnología e Ingeniería.
RESUMEN
Presentamos aquí el proceso de adaptación de los MacArthur-Bates Communicative Development Inventories (CDI) al castellano peruano estándar y la versión de los inventarios resultado de este proceso. Estos son una herramienta para el estudio de la comunicación temprana (gestos y vocalizaciones), el vocabulario inicial y las primeras construcciones gramaticales, así como determinadas acciones y juegos típicos en el desarrollo, para niños entre 8 y 30 meses de edad, divididos en dos rangos: 8 a 15 y 16 a 30 meses. Contar con una versión adaptada al castellano peruano potenciará el desarrollo de investigaciones en temas de desarrollo temprano en nuestro país, especialmente el lingüístico y comunicativo, aunque no únicamente.
En el ámbito aplicado, estos inventarios son utilizados para examinar el desarrollo lingüístico-comunicativo individual, y permitir la detección y descarte de posibles trastornos del lenguaje y del desarrollo. Son, entonces, herramientas indispensables, de demostrada confiabilidad y validez, para medir el desarrollo comunicativo de nuestros niños.
Palabras clave: Inventarios de Desarrollo Comunicativo MacArthur-Bates (CDI), castellano del Perú, lenguaje y comunicación tempranos, instrumentos de investigación.
ABSTRACT
We present here the adaptation process of the MacArthur-Bates Communicative Development Inventories (CDI) to the standard Peruvian Spanish and the version of the inventories resulting from this process. These are a tool for the study of early communication (gestures and vocalizations), the initial vocabulary and the first grammatical constructions, for children between 8 and 15 months and children between 16 and 30 months of age. Having a version adapted to Peruvian Spanish will enhance the development of research on early development issues in our country, especially, but not only, linguistic and communicative aspects. In the applied sphere, these inventories are used to detect possible language and developmental disorders. They are, then, indispensable tools, of proven reliability and validity, to measure the communicative development of our children.
Keywords: MacArthur-Bates Communicative Development Inventories (CDI), Peruvian Spanish, early language and communication, research tools.
1. El estudio del desarrollo comunicativo infantil
El léxico es una parte fundamental de todas las lenguas y, tal vez, la única área que continúa desarrollándose a lo largo de nuestra vida. Aunque los niños empiezan a comunicarse incluso antes de ser capaces de producir palabras convencionales, de la lengua adulta, en todo el mundo los padres sienten que han alcanzado un hito especial al momento que producen su primera palabra reconocible.
No es sorprendente, pues, que el desarrollo del léxico haya causado tanto interés en los estudios de adquisición de primeras lenguas. Este se relaciona con otras áreas del lenguaje y ayuda a predecir su desarrollo. Se ha encontrado, por ejemplo, relación entre vocabulario y gestos comunicativos tempranos (Gallego y López-Ornat 2005; Fernández-Flecha, Junyent, Blume y Tijero, en evaluación), vocabulario y gramática (Dale, Dionne, Eley y Plomin 2000; Junyent, Blume, Fernández-Flecha y Tijero, en prensa), vocalizaciones y vocabulario (López-Ornat y Karousou 2005), gramática y gestos (López-Ornat y Karousou 2005), LME1 y vocabulario (Mariscal et al. 2007; Dollaghan et al. 1999), y entre vocabulario y habilidades de lectura (Devries 2012). Por eso, es fundamental contar con instrumentos que nos permitan medir de manera precisa el desarrollo del vocabulario y el lenguaje en general en nuestro país. Nos propusimos, por lo tanto, crear una adaptación de los reconocidos MacArthur-Bates Communicative Development Inventories (CDI)2 al castellano del Perú. Aquí describimos el proceso y los resultados de la adaptación al español peruano,3 a cargo del Grupo de Investigación en Adquisición del Lenguaje (GRIAL).4
2. Los Inventarios MacArthur-Bates
Dado que el nombre de los Inventarios MacArthur Bates de Desarrollo Comunicativo es extenso, es común llamarlos CDI por las siglas en inglés de Communicative Development Inventories. Se habla de los CDI, en plural, porque, en realidad, se trata de dos cuestionarios o inventarios distintos. El primer cuestionario o cuadernillo es la Forma I, llamada Words and Gestures, ‘Palabras y Gestos’, y evalúa el desarrollo de los niños de 8 a 15 meses de edad. El segundo cuadernillo o Forma II, Words and Sentences, ‘Palabras y Oraciones’, evalúa la producción de los niños de 16 a 30 meses de edad.
Los CDI fueron desarrollados por Larry Fenson (Fenson et al. 1993; 1994) a partir de una versión previa de Bates, Camaioni y Volterra (1975), quienes construyeron estas herramientas para obtener información objetiva sobre las habilidades comunicativas tempranas de los niños, ya que, en ese entonces, los instrumentos existentes evaluaban solo aspectos mínimos del desarrollo lingüístico temprano con la finalidad de identificar a niños con problemas en esta área (Fenson et al. 1994). Estos inventarios evalúan el desarrollo comunicativo y lingüístico del niño por medio de preguntas que deben ser respondidas por sus padres.5 Los padres, entonces, reciben los cuestionarios y deben marcar aquellas conductas que creen que el niño realiza, si produce o comprende alguna palabra o expresión, según cual sea la instrucción.
Los CDI han sido adaptados a decenas de lenguas. Actualmente, existen tanto adaptaciones a ochenta y un lenguas, como a distintas variedades de una misma lengua (aunque algunas están en prensa): tres para el alemán, cuatro para el árabe, dos para el griego, seis para el inglés, dos para el francés, tres para el mandarín, cuatro para el portugués y seis para el español (sin contar la versión peruana aún en prensa).
En el caso específico del español, los CDI fueron originalmente adaptados a la variedad de México por Jackson-Maldonado et al. (2003). Además de la versión mexicana, se tienen actualmente versiones para las siguientes variedades: cubano (Fernández y Umbel 1991), peninsular (López Ornat, Gallego, Gallo, Karousou, Mariscal, y Martínez 2005) y, más recientemente, colombiano (Lara, Mesa, Gómez, Gálvez y Serrat 2011); además, para el castellano chileno, se tiene una versión resumida (Farkas 2011) y una versión completa en preparación (Velásquez, Cepeda, Alarcón, Silva y Muñoz, manuscrito, no publicado). Hay también una versión para el castellano argentino actualmente en proceso de baremación (Resches, Querejeta, Laguens, Maglio y Luque, manuscrito, no publicado). De las anteriores, las únicas versiones publicadas y accesibles son la del español peninsular y la del mexicano.
Los CDI han demostrado ser instrumentos con un alto grado de confiabilidad (Dale, Bates, Reznick y Morisset 1989; Fenson et al. 1994; Thal, O’Hanlon, Clemmons y Frailin 1999; Thal, Jackson-Maldonado y Acosta 2000; Marchman y Martínez-Sussmann 2002). Además, diversos estudios que han empleado los inventarios MacArthur-Bates han obtenido resultados interesantes. López Ornat y Karousou (2005) hallaron, a partir de la aplicación de la versión en castellano peninsular, que las vocalizaciones infantiles se correlacionan con el vocabulario, la gramática y los gestos, lo que apoyaría la noción de continuidad evolutiva entre las vocalizaciones tempranas y el posterior desarrollo lingüístico. Basándose en la misma versión, Mariscal et al. (2007) también hallaron una importante correlación entre la longitud media del enunciado (LME) y el vocabulario, un efecto significativo de la edad en el desarrollo de varios de los componentes involucrados en el desarrollo lingüístico, además de un efecto significativo del nivel educativo de la madre en la comprensión de frases y palabras en los niños de 16 a 30 meses de edad: es decir, a mayor nivel educativo de la madre, mayor cantidad de frases y palabras produce el niño. Finalmente, observaron el ya conocido desfase entre la comprensión y la producción lingüística en las fases tempranas del desarrollo de la lengua.
En cuanto a la adaptación al español de México, Jackson-Maldonado (2004) ha empleado dicha herramienta para la caracterización del retraso lingüístico en niños mexicanos, específicamente en relación con su vocabulario y uso gestual, ya que se sabe que ambos son buenos predictores del desarrollo lingüístico posterior (Jackson-Maldonado 2004; Jackson-Maldonado y Bárcenas 2006). Dicha investigación nota, sin embargo, que las distintas herramientas usadas para evaluar a los niños, entre las que se encuentran los CDI, arrojan resultados distintos entre sí acerca del grado de retraso lingüístico de los niños, por lo que se requiere más investigación. Jackson-Maldonado y Bárcenas (2006) hallaron, en un estudio con niños de entre 10 y 12 meses de nivel socioeconómico bajo, que el uso de los CDI proveía una información más rica sobre sus gestos y habla que la observación directa, ya que los niños a esta edad producían muy poca habla espontánea. A diferencia de algunos estudios previos (Hart y Risley 1995; Dolloghan et al. 1999; Hoff 2003; Hoff-Ginsberg 1991), no encontraron que el nivel socioeconómico de la madre se correlacionara con la comprensión y la producción de vocabulario en niños.
Existen relativamente pocas publicaciones que den cuenta propiamente de los procesos de adaptación seguidos para el castellano. Lara et al. (2011) dan cuenta del proceso de adaptación del CDI al contexto específico colombiano y de su primera fase de baremación. Con respecto a la adaptación resumida al castellano chileno, Farkas (2011) se vale, para la elaboración de su adaptación, de una metodología que podríamos considerar afín a la empleada en nuestro proyecto. Así, la investigadora recurre a una metodología mixta, que combina los juicios de especialistas acerca de los ítems de vocabulario comunes en el castellano chileno con la aplicación de la herramienta a una muestra de padres o madres, además del registro en video de situaciones de comunicación espontánea cuidador-niño.
3. Necesidad de una adaptación al castellano peruano
El Perú tiene una población de más de 31 millones de habitantes. Es un país multilingüe donde aproximadamente 47 idiomas nativos (Ministerio de Educación 2013) y el español están en contacto. En varios momentos de su historia, y más recientemente desde los años 80, grandes porciones de la población de las regiones andina y amazónica migraron a Lima, la capital, y otros centros urbanos en la región costera. Debido a ello, el dialecto de Lima se ha enriquecido con variedades de todo el país, así como con los otros idiomas hablados en el territorio nacional. El dialecto del español hablado en Lima, que tiene actualmente más de 9 millones de habitantes, se considera el estándar del país, con otras formas claramente distintas de español en las regiones andinas y amazónicas. El español estándar de Lima, al igual que todos los dialectos, tiene características fonológicas y léxicas que lo distinguen de otros dialectos americanos y que deben ser adquiridas por los niños para convertirse en hablantes competentes en sus comunidades. Dado que esta versión de los CDI es la primera adaptación para nuestro país, nos hemos centrado en el dialecto estándar del país, como lo han hecho también otras versiones del CDI antes que nosotros. Estas, aunque no dicen explícitamente que se han basado en el dialecto estándar, han centrado su recolección de datos alrededor de las capitales: Bogotá para el caso colombiano; Buenos Aires para el caso argentino; Santiago de Chile para la versión corta del caso chileno. En el caso de la versión peninsular, se da información sobre la procedencia de los padres de los niños,6 quienes provienen de toda España, pero especialmente de Madrid (entre el 41.3 % y el 46.6 %). Este no parece ser el caso de la versión mexicana, para la cual se dice que una pequeña parte de la muestra viene de la Ciudad de México; y el resto, de familias hispanas en el sudoeste de los EE. UU (Jackson-Maldonado, Thal, Marchman, Bates y Gutiérrez-Clellen 1993). Esperamos probar nuestra versión más tarde en otras regiones y continuar con su adaptación a dialectos particulares del castellano peruano para tener un instrumento que mida de manera justa el desarrollo del lenguaje infantil en nuestro país.
Una diferencia importante que distingue al Perú de otros países en nuestro continente es la existencia del español andino, el dialecto de los hablantes nativos de español en la región andina (Escobar 1978; Escobar 2011), que tiene características de las lenguas andinas debido al intenso contacto. Este dialecto no es exclusivo del Perú, sino que se extiende a otros países andinos como Bolivia, Ecuador y algunas regiones de Colombia, Chile y Argentina. Aunque este dialecto exhibe características fonológicas particulares, no las mencionamos, ya que no son verificables con el CDI. Gramaticalmente, el español andino se caracteriza, entre otros fenómenos gramaticales, por el uso no estándar de pronombres clíticos, el uso extensivo del diminutivo y el uso de formas deícticas adverbiales con preposiciones. Aunque el español andino es muy prominente en nuestro país, la mayoría de sus características gramaticales y morfológicas aún no se han asimilado al dialecto estándar y se encuentran estigmatizadas (Vigil 2003). Debido a ello, concluimos que las características gramaticales del español andino no deberían incluirse en esta primera versión, aunque esperamos trabajar en una adaptación para este dialecto con la colaboración de expertos regionales más adelante.
Si bien muchas características del español andino están ausentes en el estándar, varios elementos léxicos tomados de nuestros idiomas nativos han pasado a formar parte de los léxicos familiares cotidianos en Lima. Es el caso, por ejemplo, de choclo del quechua, poto del mochica y lampa del aimara. Como en otros idiomas, el español estándar del Perú también incluye palabras tomadas del inglés, como grass y laptop, y de idiomas europeos, como chau del italiano y tacho del portugués. Además, el español peruano usa —en muchos casos como término preferido (o el único término)— palabras que son diferentes de las usadas en los dialectos estándar mexicano y peninsular en los CDI (por ejemplo, medias en lugar de calcetines). El español peruano también comprende algunas palabras que tienen significados adicionales en nuestro dialecto que no existen en los otros (por ejemplo, asado es una forma común de decir enojado, pero en otros dialectos esta palabra simplemente tiene el significado de ‘cocinar directamente al fuego’ y churro se entiende como guapo además de referirse al dulce de origen español).
Además de estas características específicas del Perú, nuestra versión difiere de la del español peninsular en tanto recoge la conocida variación léxica y morfológica que distingue a América de España, tal como hace la versión mexicana. También difiere de esta última al incluir muchos ítems que no estaban en ella y que tomamos directamente de la versión peninsular. Difiere de ambas versiones, mexicana y peninsular, al incorporar una serie de términos comunes solo en América del Sur o en la región andina, además de algunos elementos tomados directamente de la versión original del inglés norteamericano. Nuestra versión constituye, pues, una nueva adaptación que incorpora todos los elementos culturalmente relevantes de las versiones del CDI revisadas (la original del inglés norteamericano y las dos adaptaciones mejor conocidas al español) y esperamos que pueda ser utilizada en otros países andinos con solo algunas adaptaciones.
4. El proceso de adaptación
Es preciso destacar que la adaptación de herramientas como los CDI constituye un proceso de trabajo arduo y continuado. En el caso de la adaptación peruana, primero se compararon las versiones disponibles del castellano con la versión original norteamericana para decidir qué secciones e ítems incluir, cuáles debían ser reemplazados por términos más apropiados para nuestro dialecto, y cuáles debíamos añadir o eliminar. En el caso de otras lenguas o variedades para las que se ha adaptado el CDI, este proceso se vio facilitado porque cuentan ya con bases de datos de habla natural de niños. En nuestro caso, sin embargo, tal base de datos no existía, por lo que fue necesario construir una, que usaremos en el futuro para afinar nuestros CDI.
Una parte imprescindible de este trabajo de adaptación la constituyen los análisis de confiabilidad necesarios para asegurar su efectividad como herramienta de medición y evaluación (Fenson et al. 2014; Farkas 2011). Resulta, pues, crucial asegurarse de que los distintos ítems en ambos CDI sean todos efectivos medidores y discriminadores del desarrollo comunicativo y lingüístico infantil. Es importante, en ese sentido, analizar estadísticamente cada uno de los ítems para deshacerse de aquellos que no miden realmente la trayectoria evolutiva de los niños peruanos castellano hablantes y conservar solamente aquellos que sí podrán brindar información acerca de ella. Los datos recogidos durante el proceso de adaptación han sido empleados para evaluar la adquisición de gestos entre los 8 y 15 meses (Fernández-Flecha et al., en evaluación) y la relación entre la producción del vocabulario y la gramática entre los 16 y 30 meses, con buenos resultados (Junyent et al., en prensa).
La versión de los cuestionarios que tenemos ahora deberá luego pasar por dos fases más, la de los análisis de validez y la última fase de la adaptación. La validez concurrente será evaluada a través de la comparación en un sub grupo entre los resultados de los CDI y las muestras de habla natural recogida durante la fase 1 de nuestro proyecto (ver apartado 4.2.1). La baremación resulta de la aplicación del cuestionario a una muestra lo suficientemente amplia y representativa como para establecer los percentiles de desarrollo en los que se podrán ubicar los niños peruanos que sean evaluados después con el instrumento, en función de las respuestas que hayan dado sus padres a los cuestionarios. La baremación es indispensable para que la herramienta pueda ser efectivamente usada como instrumento de medición y, eventualmente, de detección de desviación respecto del patrón estándar de desarrollo. Este proceso requiere el apoyo de instituciones del gobierno tales como los Ministerios de Educación, Salud y/o Cultura, a los que contactaremos posteriormente para tener acceso a un número de participantes suficiente.
Nuestro proyecto, hasta el momento, ha tenido las siguientes fases:
Fase 1: Comparación con la versión peninsular y piloto 1
-
Preparación de la versión preliminar a partir de la adaptación de ítems de la versión peninsular a nuestro dialecto
-
Aplicación de los CDI en el primer piloto
-
Análisis de confiabilidad de los resultados del primer piloto y selección de ítems
Fase 2: Comparación con la versión peninsular y piloto 2
-
Aplicación de los CDI en el segundo piloto
-
Nuevos análisis de confiabilidad y selección de ítems
Fase 3: Comparaciones finales y cuestionarios en línea
-
Comparación con las versiones norteamericana y mexicana, ayudados por los datos de Wordbank, y selección y adaptación de nuevos ítems a nuestro dialecto
-
Aplicación de cuestionarios en línea para evaluar la conveniencia de añadir ítems que estaban en la versiones norteamericana y mexicana
Como puede verse, para cada piloto y para la versión actual, se discutieron los posibles ítems por ser incluidos de acuerdo con las peculiaridades lingüísticas y culturales de nuestro país. También consultamos el diccionario de la RAE (2017), Hildebrandt (2013) y Álvarez Vita (2009) para seleccionar posibles ítems.
4.1. Datos de Wordbank
Una herramienta fundamental en nuestro trabajo fue la página de Wordbank,7 una base de datos del desarrollo léxico de niños, de acceso público, que contiene, a la fecha, datos de 75,144 niños en 29 lenguas y basados en el uso de 56 instrumentos. Esta base de datos nos permitió, ante la gran variación de ítems de una versión a otra, consultar los resultados de cada término en las otras versiones y juzgar así qué ítems incluir o no según los puntajes que hubieran obtenido.
4.2. Fase 1. Comparación con la versión peninsular y piloto 1
4.2.1. Preparación de la versión preliminar a partir de la adaptación de ítems de la versión peninsular a nuestro dialecto
Como ya se dijo antes, no se cuenta actualmente con una base de datos disponible de grabaciones y transcripciones de niños peruanos, por lo que nos vimos obligados a seleccionar los ítems para los inventarios a partir de las versiones ya disponibles.
En la primera fase del proyecto, se preparó una versión preliminar utilizando como referencia principal la versión peninsular. Probamos primero esa versión porque incorporaba una nueva sección (Vocalizaciones) que nos pareció pertinente mantener y porque incluía muchos elementos de vocabulario no disponibles en las versiones en inglés norteamericano y español mexicano. Como los datos de la versión peninsular aún no estaban disponibles en Wordbank en ese momento, incorporamos los ítems de la versión peninsular en nuestros dos pilotos con el fin de saber si debíamos incorporar los nuevos elementos.
4.2.2. Aplicación de los CDI en el primer piloto
La primera versión de los CDI que adaptamos incluía ítems de la versión peninsular y algunas palabras de nuestro dialecto que nos parecían frecuentes en el habla infantil.8 La intención era aplicar estas versiones preliminares de ambos cuestionarios (Forma I de 8 a 15 meses y Forma II de 16 a 30 meses) a un grupo pequeño de padres con el objetivo de evaluar su funcionamiento y pertinencia.
Este primer piloto se aplicó a un grupo de 26 padres de niños de 8 a 15 meses de edad y 24 padres de niños de 16 a 30 meses de edad. Proporcionamos en los cuadernillos formas alternativas para varios de los ítems (por ejemplo, no hay/pau pau, ratón/pericote, abuela/mamama) y les pedimos a los padres que subrayaran las que su hijo(a) entendía y/o producía con el objetivo de escoger entre variantes para nuestra adaptación y medir cuál es la forma más frecuente en caso que usaran ambas. También tomamos nota de los ítems que los padres sugirieron que debíamos incluir o excluir.
Tanto para este piloto como pare el segundo, los padres fueron contactados a través de guarderías y preescolares, así como por contactos de los investigadores.
En esta primera fase, también recolectamos datos de habla natural en situaciones de comunicación espontánea entre los niños y sus cuidadores en el hogar, que forman el inicio de una primera base de datos del castellano peruano infantil. Estas grabaciones constituyen un recurso adicional que servirá, más adelante, para evaluar la validez concurrente, es decir, confirmar nuestra selección de palabras de los inventarios a la luz de lo hallado en las grabaciones.
Los CDI fueron administrados por un asistente de investigación en todos los casos para asegurarnos que la aplicación se llevara a cabo adecuadamente, las instrucciones fueran comprendidas, se seleccionaran las formas alternativas cuando fuera necesario y se recogieran otras sugerencias de los entrevistados.
4.2.3. Análisis de confiabilidad de los resultados del primer piloto para medir su confiabilidad y selección de ítems
Este proceso nos permitió, posteriormente, poner a prueba la adecuación de los nuevos ítems propuestos y estimar la confiabilidad de esta versión del instrumento con el método de consistencia interna basado en el cálculo del Alfa de Cronbach. No reportamos aquí dichos resultados, porque estos datos se juntaron más adelante con los del piloto 2 para un nuevo análisis de confiabilidad que reportamos en el apartado 4.3.2.
Una vez terminado el primer piloto y a partir de los resultados obtenidos, procedimos a eliminar ítems con los siguientes criterios (los mismos para ambos pilotos):
-
1) todos aquellos que tenían una frecuencia inferior al 25% y baja confiabilidad, evidenciada por un Alfa de Cronbach de 0.30 o menos,
-
2) excepto los que se encontraran en los CDI de al menos dos países de los considerados (CDI norteamericano, mexicano y peninsular).
Después de seleccionar los ítems pertinentes en función de los análisis de confiabilidad, procedimos a conducir el segundo piloto.
4.3. Fase 2. Comparación con la versión peninsular y piloto 2
4.3.1. Aplicación de los CDI en el segundo piloto
En el segundo piloto, se utilizó la nueva versión del instrumento, elaborada a partir de algunas modificaciones a la versión empleada en el piloto anterior. Esta nueva versión se aplicó a un nuevo grupo de niños, de manera que, juntando estos datos con los del primer piloto, tenemos un grupo total de 87 niños de 8 a 15 meses (edad media: 11.4 meses, 46 niñas y 41 niños) y 105 de 16 a 30 meses (edad media: 22.4 meses, 46 niñas y 59 niños). El nivel socioeconómico de los padres fue medido a partir del nivel máximo de educación alcanzado por la madre, como se ha hecho en estudios previos (Hoff-Ginsberg 1991; Hart y Risley 1995; Dollaghan et al. 1999; Hoff 2003; Jackson-Maldonado y Bárcenas 2006). Los análisis mostraron que 72.1% de las madres de niños de 8-15 meses y 72.0% de las de 16-30 meses tenían estudios universitarios, y que 27.9% de las madres de niños de 8-15 meses y 28% de las de 16-30 meses tenían educación técnica o secundaria. La variedad total de la muestra en el aspecto socioeconómico no fue tan amplia como hubiera sido deseable, lo que esperamos mejorar a medida que recolectemos más datos con esta versión preliminar. Los datos obtenidos en el segundo piloto fueron analizados de manera conjunta con los datos del piloto anterior.
4.3.2. Nuevos análisis de confiabilidad y selección de ítems
Los datos provenientes de ambos pilotos se analizaron empleando el paquete estadístico SPSS versión 21. Con la finalidad de analizar la confiabilidad por consistencia interna, se empleó el estadístico Alfa de Cronbach. Así, se consideró adecuada la consistencia interna de las escalas con un Alfa de .70 a más.
En primer lugar, como se aprecia en la Tabla 1, los análisis arrojaron, para la Forma I, una adecuada consistencia interna en las escalas Comprensión global, Vocabulario receptivo, Gestos y Acciones; pero no en Vocalizaciones, Producción temprana y Vocabulario expresivo.

Para calcular el Alfa de Cronbach de la escala, primero se calculan las correlaciones ítem-test por cada ítem. En el caso de Vocalizaciones (escala con 12 ítems), se encontró que las correlaciones ítem-test corregidas oscilaron entre .08 (ítem llamar la atención) y .37 (ítems imitación de palabras y protopalabras), las cuales se consideran bajas. Pasamos entonces a revisar las frecuencias de las respuestas de los niños en esta sección. Descubrimos que 11 de los 12 tipos de vocalizaciones son producidos por la mayoría de los niños de 8 a 15 meses y, lo que es más relevante, 5 ítems son producidos por casi todos los niños (balbuceo reduplicado: 99%, conversar (aunque no se le entienda): 94%, llamar la atención del adulto: 87%, habla privada: 83% y pedir: 80%). Esta poca variabilidad en las respuestas explicaría el bajo Alfa de Cronbach (.61) de esta escala. Por otro lado, en relación con la escala Producción temprana, aunque se obtuvo un Alfa de Cronbach de solo .61, este puede explicarse debido a su bajo número de ítems, solo tres. Por último, la escala Vocabulario expresivo presentó el Alfa más bajo, .16, por lo que se desestimó la confiabilidad de la consistencia interna de esta escala y no se empleó en análisis posteriores como los que se presentan en Fernández-Flecha et al. (en evaluación). La razón de esto probablemente se deba a los bajos resultados obtenidos por los niños en vocabulario expresivo, aunque no en receptivo: a estas edades, comprenden mucho más de lo que dicen, que es más bien poco. En efecto, hay 97 ítems de 306 que son desconocidos por más del 80% de los niños. Dado que la producción de todos los niños es muy baja, hay un efecto suelo y poca variabilidad, lo que no permite que se hagan evidentes las diferencias entre niños.
En cambio, para la Forma II, se encontró una adecuada consistencia interna para todas las escalas del instrumento, con Alfas de Cronbach que reflejan una confiabilidad de buena a excelente (.70 a .99).
4.4. Fase 3. Comparaciones finales y cuestionarios en línea
4.4.1. Comparación con las versiones norteamericana y mexicana, ayudados por los datos de Wordbank, y selección y adaptación de nuevos ítems a nuestro dialecto
Para crear la versión peruana preliminar de los inventarios de CDI emprendimos un largo proceso de comparación de la versión original estadounidense con las dos versiones del español más conocidas, la mexicana y la peninsular. En esta comparación, descubrimos que las tres presentaban ciertas diferencias a pesar de seguir una línea común. En primer lugar, algunas secciones estaban en una versión, pero no en otras. La Tabla 2 muestra la estructura de nuestra versión.

La Parte 0. Vocalizaciones de ambas Formas se encuentra solo en la versión peninsular. En la Forma I Parte II, Gestos, juegos y acciones, la sección 4. Acciones con un objeto en lugar de otro está solo en la versión peninsular, y las secciones 5. Jugar a ser un adulto (un padre) y 6. Imitación de otros tipos de actividades de adultos están en las versiones norteamericana y mexicana, pero no en la peninsular.
En la Forma II, Parte I, Palabras, las secciones 1. Producción temprana y 2. Desarrollo del vocabulario están solo en la versión peninsular, y las secciones 2. Verbos difíciles y 3. Palabras sorprendentes no están en la versión mexicana, aunque sí en la norteamericana y la peninsular.
La sección de Vocabulario en ambas Formas es la más extensa de los cuadernillos y contiene muchas subsecciones, en las cuales se agrupan los ítems por campos semánticos o temáticos. La Tabla 3 presenta dichas subsecciones, así como el número de ítems por versión en cada una. Se indica la versión norteamericana con NA, la mexicana con M, la peninsular con E (por España) y la nuestra con P.


Las subsecciones semánticas/temáticas son prácticamente idénticas en las distintas versiones consultadas del CDI, pero la mexicana no contiene Auxiliares y perífrasis. Las versiones norteamericana y mexicana incluyen Muebles y cuartos, y Utensilios de la casa, que la versión peninsular junta en una sola llamada Objetos y lugares de la casa. La versión norteamericana tiene Pronombres, Cuantificadores y artículos, y Preposiciones y locativos, mientras que la versión mexicana tiene Pronombres y modificadores, Preposiciones y artículos, Cuantificadores y adverbios, y Locativos, y la versión peninsular tiene Pronombres y determinantes, Preposiciones y locativos, y Cuantificadores y artículos. Ante esta variedad, optamos por reunir pronombres, determinantes y cuantificadores en una sola subsección, debido a que los artículos son un tipo de determinante, por lo que no se justifica su separación en dos subsecciones —como hacen las versiones mexicana y peninsular—, ya que, dado que varios de los ítems se presentan en los CDI sin un contexto, no es posible distinguir entre su uso como pronombre o determinante (por ejemplo, piénsese en esa y una); optamos también por mantener preposiciones y locativos en otra subsección, tal como lo hacen dos de las tres versiones.
Nos encontramos, también, con que, dentro de las subsecciones comunes, no necesariamente coincidían los ítems, aunque hubiera un número similar por subsección; por ejemplo, una subsección relativamente pequeña como la de Conectivas de la Forma II tenía seis ítems en la versión norteamericana y siete en las versiones mexicana y peninsular. Sin embargo, de estos siete, solo tres se encontraban en las tres versiones (entonces, pero e y), dos estaban en las versiones norteamericana y peninsular pero no en la mexicana (porque y si), y dos en la mexicana y peninsular pero no en la norteamericana (o y que). Adicionalmente, la versión mexicana incluía pues, que no incluimos en nuestra versión por no tratarse de un conector común en el habla coloquial dirigida a los niños y porque se usa frecuentemente con función enfática en nuestro país, lo que podía llevar a dificultades por parte de los padres para entender a qué uso aludía nuestro inventario. Este problema era aún mayor en subsecciones largas como las de Alimentos y bebidas de la Forma II, con 68 ítems en las versiones norteamericana y mexicana, y 59 en la versión peninsular.
4.4.2. Aplicación de cuestionarios en línea para evaluar la conveniencia de añadir ítems que estaban en las versiones norteamericana y mexicana
Ante estas diferencias y a partir de los resultados obtenidos de los dos pilotos, optamos por aplicar unos cuestionarios en línea. La razón fue que, a partir de los resultados estadísticos producto de los dos pilotos (ver apartado 4.3.2), se descartó un nuevo grupo de ítems, lo que hizo que, en el caso de algunas subsecciones de vocabulario, tuviéramos menos que las otras versiones revisadas. Una revisión de los ítems de las versiones norteamericana y mexicana no incluidos nos permitió elaborar dos pequeñas encuestas en línea con el objetivo de evaluar la pertinencia de incluir dichos ítems. Así, los cuestionarios en línea buscaron evaluar aquellos ítems que estuvieran en las versiones norteamericana y mexicana, pero no en la peninsular, que consideramos podían ser relevantes para nuestra versión pero que no habían sido probados en los pilotos. El propósito era contar con una versión que incluyera los ítems de la versión peninsular y que, a la vez, no resultara tan distinta de las versiones norteamericana y mexicana, de modo que fuera comparable.
La encuesta fue enviada a 27 padres de niños de 8 a 15 meses y 27 de niños de 16 a 30 meses, algunos de los cuales habían participado en los pilotos. Los padres accedían a través de un enlace a la encuesta, en la que debían marcar cuáles de las palabras presentadas conocían sus hijos. En la encuesta para los niños pequeños, se preguntaba si estos comprendían las palabras en cuestión solamente, ya que las medidas de producción en general resultaron bajas en nuestros pilotos. En cambio, en la encuesta para los niños más grandes, solo se preguntaba si producían la palabra, tal como lo hace la Forma II. Se aceptaron aquellos ítems que tuvieran un puntaje de 5 o más.
5. Descripción de la versión peruana
El proceso de adaptación dio lugar a una versión que usaremos para la baremación y que podrá aún ser modificada. A continuación, describimos esta versión.
La decisión sobre qué ítems incluir se basó en el análisis del grupo de investigación, así como en los resultados de los estudios piloto y las encuestas relacionadas. En general, para nuestra versión de los inventarios, incluimos todos los ítems que cumplieran con una de las siguientes condiciones:
-
(a) aparecían en las tres versiones de los inventarios que comparamos (a excepción de algunos términos que hacen referencia a entidades no habituales en nuestro país; por ejemplo, alce, traje de nieve),
-
(b) aparecían en al menos dos de las versiones (con similares excepciones), o
-
(c) aparecían en solo una de las versiones o eran innovaciones, siempre que fueran consideradas importantes por nuestro grupo y obtuvieran buenos resultados en los pilotos o en los cuestionarios en línea que hicimos.9
Además de la selección de ítems por incluir, adaptamos los ítems a nuestro dialecto, como se describe en el resto de este apartado, e introdujimos algunos cambios menores, que incluían la adición de instrucciones, ejemplos y explicaciones.
Las instrucciones fueron adaptadas para ser más fácilmente comprensibles, usando ejemplos más cercanos al contexto peruano, así como expresiones que resultaran más naturales para los hablantes de español peruano. Por ejemplo, la instrucción en Vocalizaciones de la versión en español peninsular decía: A veces los niños cantan por su cuenta, por ejemplo, tras oír que un adulto o un muñeco suyo ... ¿hace eso su hijo? Reemplazamos tras con después de por ser una forma más frecuente en el español peruano coloquial. El texto original decía que los niños pueden cantar solos después de escuchar a un adulto o a su muñeca cantar (algún muñeco suyo). Aunque puede haber muñecas que "cantan", pensamos que una situación más común era escuchar una canción en el televisor o en la radio, y cambiamos el texto en consecuencia.
Insertamos algunos textos entre paréntesis para aclarar ciertos ítems; por ejemplo, dentro de la sección de Vocabulario de la versión peninsular (Formas I y II), había una explicación para el sonido del caballo, pero no para el sonido del perro. En la versión en español del Perú, agregamos explicaciones a estos sonidos —tocotoc (caballo) y gua-guáu (perro)— y, en general, a todas las onomatopeyas. Movimos algunos ítems de una subsección a otra cuando consideramos que facilitaría la administración de los inventarios. Por ejemplo, música y lápiz se movieron de Juguetes a Utensilios de la casa (Formas I y II).
A continuación, describimos la estructura general de los inventarios, y cada una de sus partes y secciones, indicando las adaptaciones que se hicieron en cada una.
5.1. Estructura general de la versión peruana
A continuación, describimos las diferentes partes y secciones de la versión peruana tal como quedó después del proceso de adaptación (ver apartado 4) y las decisiones generales tomadas (ver inicio del apartado 5). Esta estructura general se muestra en la Tabla 2 del apartado 4.4.1.
La Parte 0. Vocalizaciones incluye sonidos que son principalmente comunicativos (aunque también se incluyen casos de habla privada) pero que no llegan a ser palabras, tales como el balbuceo, los sonidos que hacen los niños para pedir cosas (a-a-a), los sonidos que acompañan gestos, la repetición de patrones entonacionales, la jerigonza (largos enunciados formados de sonidos ininteligibles pero que contienen los patrones entonacionales del lenguaje adulto, de manera que parece que expresan afirmaciones, preguntas, mandatos, etc.) y las protopalabras.10
La Parte I, Primeras palabras/Palabras, es la dedicada al vocabulario e incluye el grueso del inventario, como ya se explicó en el apartado 4.4.1 (ver Tabla 3). En el caso de la Forma I, se pregunta por el vocabulario comprensivo y productivo, mientras que, en la Forma II, se pregunta únicamente por el productivo. De aquí en adelante, ambas Formas difieren completamente. La Forma I pregunta por gestos, juegos y acciones específicas relacionadas con las capacidades motoras y lúdicas del niño, mientras la Forma II inquiere acerca de las habilidades de construcción de enunciados del niño (ver apartado 4.4.1, Tabla 2).
A continuación, describimos las adaptaciones de las distintas partes de las Formas I y II en conjunto, para evitar repeticiones, aunque ciertas secciones estén en solo una de las formas, como se puede ver en la Tabla 2.
5.2. Parte 0. Vocalizaciones (Formas I y II)
Esta sección proviene de la versión peninsular, que es la única que considera estas "producciones tempranas interpretables por los padres, con o sin contenido segmental, en las que el niño produce grupos prosódicos de duración variable" (López-Ornat y Karosou 2005: 1). Decidimos adoptar la innovación porque nos permitía estudiar la continuidad entre gestos, vocalizaciones y vocabulario (Fernández-Flecha et al., en evaluación). Esta sección incluye doce ítems y la única adaptación necesaria consistió en acercar más la forma del texto al dialecto peruano, por ejemplo, cambiando el término coche por carro e incluyendo el clítico le en los contextos en los que es común en nuestro dialecto.
5.3. Parte I. Primeras palabras (Forma I) y Palabras (Forma II)
Como se puede ver en la Tabla 2, la Forma I incluye una Parte 1 llamada Primeras palabras; y la Forma II, una sección similar llamada Palabras. Ambas formas comparten las subsecciones Producción temprana y Vocabulario, y difieren en las demás. La Forma I contiene Comprensión temprana y Comprensión global de frases, que no están en la Forma II, la cual incluye, a su vez, Producción temprana y Usos del lenguaje, que no están en la Forma I.
5.3.1. Comprensión temprana y Comprensión global de frases. Forma I
En esta sección, mantuvimos los ítems de Comprensión temprana y Comprensión global de frases, adaptándolos a nuestro dialecto. La primera tiene los mismos tres ítems en todas las versiones y pregunta sobre capacidades básicas del niño, es decir, si responde cuando se le llama, deja de hacer algo (algunas veces, por lo menos) cuando se le dice no y mira alrededor buscando cuando escucha que llaman a alguno de sus padres.
Comprensión global de frases inquiere si el niño entiende frases comunes en la conversación del hogar, tales como cuidado, di chau, ¿qué haces?, ven aquí, ¿te has hecho pila?, etc. Aquí había mucha variación entre versiones: las versiones norteamericana y mexicana tenían 28 ítems, la peninsular 32 y la nuestra 24. En general, encontramos cierta redundancia con la subsección de Vocabulario llamada Juegos, rutinas y fórmulas sociales, que pregunta si el niño comprende, o comprende y dice varios de los términos y decidimos dejar en dicha subsección aquellos que resultaran redundantes.
5.3.2. Producción temprana. Formas I y II
Esta sección se encuentra en todas las versiones en la Forma I, pero solo en la peninsular y en la nuestra para la Forma II. Producción temprana pregunta sobre habilidades básicas, similares a las de Comprensión temprana pero más avanzadas y que, como las de comprensión, pueden servir para evaluar rápidamente si el niño exhibe conductas comunicativas normales para su edad. Se pregunta, por ejemplo, si el niño intenta repetir frases, pide que se le diga el nombre de las cosas o va nombrando cosas él mismo. En la Forma I, tiene tres ítems en la versión peninsular, pero solo dos en las norteamericana y mexicana. Añadimos a nuestra versión el ítem 2 de la peninsular, que no estaba en las otras versiones: A veces los niños, aunque hablen muy poco, van "pidiendo" que se les diga el nombre de las cosas que ven. Puede que señalen algo con el dedo y le pregunten al adulto ¿eto? (‘¿esto?’). ¿Hace eso su hijo? En la Forma II, mantuvimos las dos preguntas que tenía la versión peninsular.
5.3.3. Desarrollo del vocabulario. Forma II
Incluimos esta sección que estaba en la versión peninsular, pero no en la mexicana ni la norteamericana, pues nos permitía evaluar el ritmo de adquisición del vocabulario del niño. En ella, se pide a los padres que escojan una de cinco opciones sobre el ritmo de desarrollo del vocabulario del niño: (i) Una vez que dijo su primera palabra, empezó enseguida a decir muchas más, (ii) Dijo su primera palabra y desde entonces ha ido diciendo palabras nuevas, pero muy poquito a poco, (iii) Empezó poquito a poco y pasado un tiempo de pronto empezó a decir muchas más, (iv) Aún está diciendo las primeras palabras, muy pocas y (v) Todavía no dice palabras.
5.3.4. Vocabulario. Formas I y II
En las secciones de vocabulario de ambas formas, hicimos una serie de cambios generales. En primer lugar, adoptamos los criterios generales mencionados ya en la parte inicial de este apartado. Además, como mencionamos en el apartado 4.4.1 y mostramos en la Tabla 3, esta sección suponía un reto mayor en tanto incluía muchas subsecciones en todas las versiones —que organizan el vocabulario en áreas semánticas— aunque los ítems incluidos variaban mucho de una versión a otra, incluso en el caso de aquellas con un número similar de ítems. Si manteníamos todos los ítems de cada subsección, hubiéramos terminado con un número muchísimo mayor por sección que las otras versiones. Ya dimos en el apartado 4.4.1 el ejemplo de la subsección Conectivas, cuyos ítems, a pesar de ser pocos, no eran los mismos en todas las versiones.
Para dar una mejor idea del reto que implicó decidir los ítems por incluir en nuestra versión, presentamos aquí el caso de Alimentos y bebidas de la Forma II que, como ya mencionamos, tenía 68 ítems en las versiones norteamericana y mexicana, y 59 ítems en la peninsular. En esta subsección, terminamos incluyendo en nuestra versión un total de 69 ítems: 29 que estaban en todas las versiones; 25 en dos; 11 que, a pesar de estar en una sola, habían tenido buenos resultados en nuestros pilotos y cuestionarios en línea; y cuatro innovaciones propias también con buenos resultados (brócoli, espinaca, granadilla y mazamorra). Además, descartamos 31 ítems que no habían obtenido buenos resultados, estaban en una sola versión, o nombraban alimentos desconocidos o poco frecuentes (atole, paella, cheerios, pretzels, por ejemplo). Finalmente, eliminamos cuatro ítems que habíamos propuesto como innovaciones debido a sus bajos resultados en los pilotos (camote, palta, piña y yuca).
Entonces, para cada subsección, seguimos un largo proceso de comparación y selección de ítems. En general, la versión mexicana sigue más fielmente a la norteamericana, mientras que la peninsular es más distinta debido a que se basó en sus propios corpus. Una diferencia clave entre nuestra versión y las demás es que la mexicana y peninsular se ciñen más a la norteamericana al mantener niño y niña como ítems separados, ya que corresponden a dos lexemas distintos del inglés: boy and girl. Lo mismo ocurre en Pronombres y determinantes (Forma II) con esa, ese y eso, que eran ítems independientes en las otras versiones, pero fueron juntadas en la versión del castellano peruano, como se puede ver en los ejemplos niño(a) y ese(a,o). Había que tomar una decisión sobre si crear una versión más directamente comparable a las otras versiones o una que se ajustara mejor a la gramática castellana. Nosotros optamos por la segunda opción, lo que causó que, en algunos casos, tuviéramos menos ítems que las otras versiones porque habíamos juntado dos ítems en uno.
Pasamos a describir la inclusión de ítems que provenían de una sola versión, casos que requieren mayor explicación. En todo este apartado, los cambios mostrados pueden ser de la Forma I, de la Forma II o de ambas; la intención es mostrar el tipo de cambio y no los cambios específicos para cada Forma (lo que resulta inviable, además, por limitaciones de espacio).
a. Ítems seleccionados que provenían de una sola versión
Además de los ítems que estaban en todas o al menos dos versiones, examinamos aquellos que estaban presentes en solo una versión. La mayoría provenían de la versión peninsular, la más distinta de las tres revisadas. Incluimos aquellas palabras que consideramos adecuadas en las primeras versiones de la adaptación peruana y las probamos en nuestros pilotos. En la fase 3, al revisar las versiones norteamericana y mexicana, consideramos nuevas palabras para incluir que estuvieran en una sola de las versiones. El criterio fue que nos parecieran bastante frecuentes en el habla infantil en el Perú o que tuvieran un referente correspondiente en nuestra realidad, aunque fueran nombrados con otro lexema. Algunas palabras que solo estaban en la versión en inglés, pero no en ninguna de las versiones en castellano también fueron incluidas. Ya que las consideramos innovaciones, las explicamos bajo dicha categoría.
b. Innovaciones
Además de esta exhaustiva selección de ítems, introdujimos algunas innovaciones. Consideramos innovaciones las siguientes: palabras que no estaban en las versiones en español consultadas, pero sí en la versión en inglés (Innovación tipo 1: Ítems nuevos para el castellano); palabras nuevas añadidas por nosotros (Innovación tipo 2: Ítems nuevos), palabras que cambiamos porque el término en nuestro dialecto era diferente a los que estaban en la versión mexicana o peninsular (Innovación tipo 3: Reemplazos de términos de otras versiones por términos del castellano peruano).
Innovación tipo 1: Ítems nuevos para el castellano
Algunas palabras que solo estaban en la versión norteamericana pero no en ninguna de las versiones en castellano también fueron incluidas y consideradas como innovaciones si tenían buenos resultados en nuestros cuestionarios en línea. Algunos ejemplos son el sonido chuchu de tren y las palabras sí, caca/pufi/popó (como traducción de la expresión go potty del inglés), gallo, hombre, regalo y abrazar.
Innovación tipo 2: Ítems nuevos Agregamos ítems a nuestra versión por diferentes razones:
-
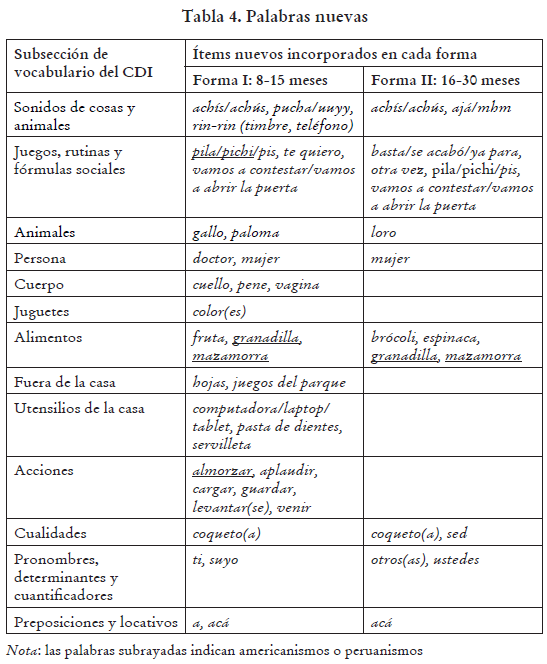
Para mantener la continuidad entre las Formas I y II (es decir entre ambos grupos de edad), ya que en algunos casos teníamos ítems que estaban en la Forma II, pero no en la Forma I y viceversa. La continuidad entre las Formas I y II resulta clave considerando que no contamos aún con una base de datos de lenguaje infantil peruano que muestre una progresión en la adquisición de palabras. Por ejemplo, aunque la palabra sed era parte de la Forma I, pero no de la II en la versión peninsular, la incluimos en ambas formas de la versión peruana en tanto no tenemos forma de conocer el rango de edad habitual de adquisición de esta palabra en el contexto peruano. Otro ejemplo es espejo, que obtuvo buenos resultados en la Forma I en comprensión, pero no en la Forma II en producción; sin embargo, la mantuvimos en la Forma II para poder medir cuándo los niños, que ya la comprendían, la empezaban a producir. Un tercer ejemplo es el determinante/ pronombre otro(a), que estaba en la Forma II, pero no en la Forma I, lo que no nos permitía medir cuándo se empieza a comprender y producir.
-
Por coherencia con los elementos ya existentes en una determinada Forma: por ejemplo, se incluyó mujer porque teníamos hombre, vagina porque teníamos pene y gallo porque teníamos gallina. Algunas de estas palabras no estaban en ninguna de las versiones anteriores y otras (como gallo) son innovaciones porque solo estaban en la versión norteamericana, pero no en las versiones en castellano consultadas.
-
Para incluir palabras que consideramos relacionadas con el entorno de los niños peruanos que no se habían incluido en ninguna otra versión (por ejemplo, granadilla y mazamorra, que en Perú se refiere a un postre típico hecho de maíz).
La Tabla 4 muestra todos los ítems nuevos; las palabras subrayadas son consideradas peruanismos o americanismos (véase el apartado 5.3.4 (d) donde discutimos esta clasificación en más detalle). En el caso de mazamorra, si bien es una palabra más general, la consideramos un peruanismo debido al significado específico que tiene en el Perú. Almorzar existe, pero no se usa coloquialmente en la España actual y, en México, designa un desayuno tardío y no la comida principal del mediodía.
Innovación tipo 3: Reemplazos de términos de otras versiones por términos del castellano peruano
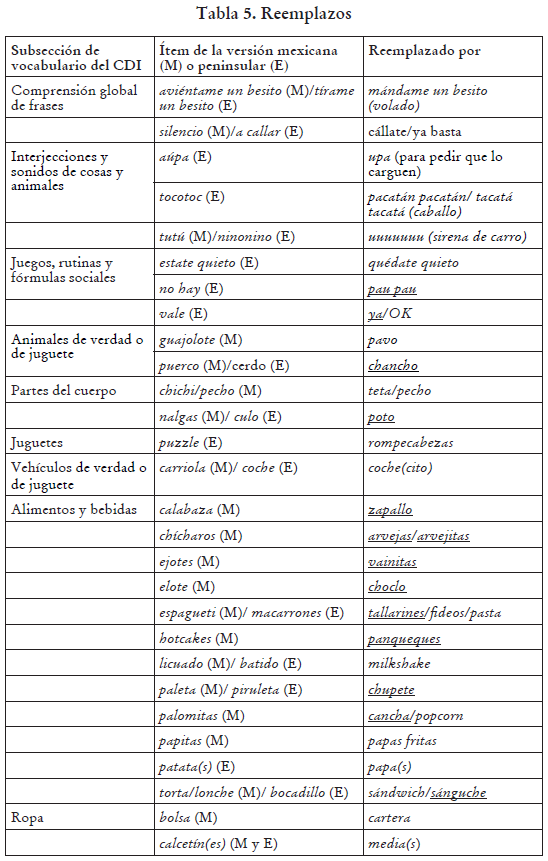
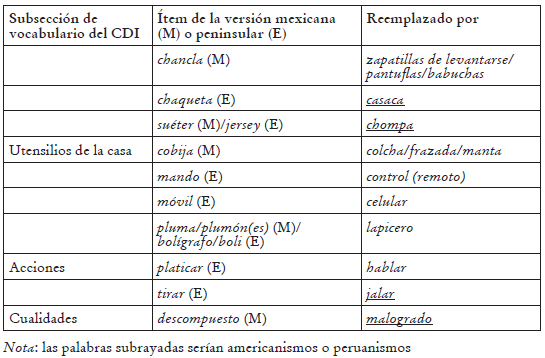
Para varios ítems, como ya se mostró antes para el caso cartera del Perú vs. bolsa de México, mantuvimos ítems de las versiones previas, pero tuvimos que reemplazar la forma listada en dichas versiones por formas equivalentes en nuestro dialecto. Por ejemplo, reemplazamos con chancho el español peninsular cerdo y el español mexicano puerco. Análogamente, poto, una palabra de origen mochica, sustituyó a la palabra peninsular culo (que se considera una "mala palabra" en español peruano) y a la palabra mexicana nalgas. Algunas de estas palabras son peruanismos porque provienen de un idioma peruano (cancha del quechua) o porque su significado en el Perú difiere del de otras áreas (por ejemplo, casaca, que en el Perú designa una prenda de vestir de uso diario, pero que en otros dialectos se restringe solo a la prenda militar, y malogrado, que en nuestro caso se usa principalmente para máquinas o artefactos con el sentido de ‘descompuesto’ pero que en otras zonas se entiende solo como ‘echado a perder’ o ‘podrido’).
Algunas de las palabras con las que hemos reemplazado las de otras versiones del CDI se usan solo en los países andinos (por ejemplo, vainitas, panqueque), otras solo en América del Sur (choclo del quechua y chompa, adaptación del inglés jumper) y algunas solo en América, aunque no en España según las fuentes consultadas. Dentro de estas últimas, algunas eran diferentes de las palabras de la versión mexicana (por ejemplo, arveja/arvejita en vez del chícharo mexicano y el guisante peninsular, y medias en lugar del calcetín(es) mexicano y peninsular). Los reemplazos se muestran en la Tabla 5. En los casos en que solo se muestra una versión en la columna del medio, la palabra solo estaba en esa versión. Así, por ejemplo, pavo se considera un cambio, aunque en España también se use dicha palabra, porque la versión peninsular del CDI no la incluía y, por lo tanto, la única palabra que teníamos en castellano era guajolote (proveniente del CDI mexicano). Los peruanismos y americanismos aparecen subrayados (véase el apartado 5.3.4 (d), donde discutimos esta clasificación en más detalle). En el caso de pau pau para indicar que algo se ha acabado, no hemos podido identificar su origen, pero sabemos que no se usa así en ninguno de los otros dialectos consultados.
Con esto, se acaban los cambios que podemos considerar innovaciones. Pasamos ahora a considerar cambios que no lo son.
c. Ítems añadidos como alternativas a otros ya existentes
En el caso de algunos ítems, agregamos una variante en español peruano a una palabra ya listada con el objetivo de proporcionar a los padres una alternativa que, tal vez, fuera más frecuente. En estos casos, pedimos a los padres que subrayaran la forma que sus niños comprendían y/o producían. Agregamos, por ejemplo, pericote a ratón y mamama a abuela dentro de Vocabulario en ambas Formas, I y II. De estas, algunas son peruanismos (ñaño(a) como variante de niño, del quechua ñaña ‘hermana de una mujer’, y asado por enojado, que solo tiene esa interpretación en el Perú pero en otros países significa ‘carne asada’). Otras se usan en los países andinos (pericote de origen desconocido, churro como equivalente a guapo, y lampa de origen aimara). Algunas son sudamericanas (tacho —de basura—, al parecer del portugués, y torta, de origen desconocido, como equivalente a pastel) y otras se usan en América en general, no solo en América del Sur (parar(se) por poner(se) de pie y pasto por césped son un ejemplo de las formas listadas como americanismos).
En otros casos, agregamos a un ítem ya existente una alternativa adicional que, a pesar de no ser un sinónimo de la palabra, era una posible variante tan frecuente o más en el español peruano. Por ejemplo, para espérate en Juegos, rutinas y fórmulas sociales (Forma II), agregamos un ratito, mucho más común en español peruano. Análogamente, agregamos el diminutivo —cito a coche para hacer coche(cito), mucho más común que la primera variante—. No mostramos aquí todos los añadidos por limitaciones de espacio.
d. Peruanismos y americanismos
Algunas de las palabras nuevas, reemplazos y añadidos eran peruanismos o americanismos (véanse Tablas 4 y 5). Dado que este tipo de adaptación constituyó una parte central de nuestro proyecto, queremos dar aquí algunos ejemplos adicionales y profundizar un poco más en este proceso.
Para conseguir la aprobación del MacArthur-Bates CDI Board11 para realizar nuestra versión, fue necesario demostrar la necesidad de crear una adaptación específica para nuestro dialecto. Para juzgar qué términos eran del castellano general y cuáles eran locales o regionales, basamos nuestras descripciones de los orígenes de las palabras y su uso en el mundo hispanohablante en el Diccionario del Español de la Real Academia Española en línea,12 y en Hildebrandt (2013) y Álvarez Vita (2009), como ya habíamos indicado. En algunos casos, basamos el juicio de la extensión del uso de las palabras en nuestro conocimiento colectivo. Aunque las tres investigadoras principales somos peruanas, tenemos vínculos familiares con España (Fernández), Argentina (Junyent) y México (Blume), y hemos vivido en esos países en diferentes momentos, por lo que tenemos un nivel bastante bueno de conocimiento de sus dialectos estándar representados en los inventarios del CDI.
Además de los ítems ya mostrados en las Tablas 4 y 5, varios fueron añadidos como variantes de alguna palabra. De estos términos, alrededor de 8 son peruanismos. Tenemos asado como variante de enojado, ñaño(a) como variante de niño(a), y pichi y pila por orina. Otros 8 aproximadamente son andinismos: chupón (como reemplazo de chupete), churro como variante de guapo, lampa como variante de pala y pericote como variante de ratón. Otros 4 términos son sudamericanismos, por ejemplo, tacho por ‘recipiente de basura’ torta por pastel. Entre los americanismos, tenemos alrededor de 19: apurar(se) por darse prisa, botar por aventar/tirar, chau por adiós, jalar por tirar —según Hildebrandt (2013), jalar/ halar era un término exclusivamente marinero que se extendió en su uso solo en América—, mamadera por biberón, nana por niñera y plata por dinero. Como se puede ver, todos son muy comunes en nuestro dialecto.
e. Ítems eliminados
Parte del proceso de adaptación consistió en eliminar ítems, pues, como ya se indicó, las diferencias entre las versiones hacían que fuera imposible simplemente usar todos los ítems de las tres versiones además de nuestras palabras nuevas. Se eliminaron ítems cuando (a) los pilotos y las encuestas en línea nos mostraron que muy pocos niños los conocían (por ejemplo, manejar, morado); (b) aparecían en más de una versión pero se referían a entidades no conocidas o frecuentes en nuestro país (por ejemplo, trineo, ganso, mantequilla de maní o atole, que hace referencia a una bebida mexicana) y (c) aparecían solo en una de las versiones del CDI que comparamos y no se les juzgó lo suficientemente frecuentes/importantes como para agregarlos (por ejemplo, cartas en el sentido de naipes, colador como equivalente al coladera mexicano). Dada la gran variación entre las diferentes versiones de los CDI, el número total de elementos eliminados fue elevado.
5.3.5. Usos del lenguaje
Todas las versiones de la Forma II incluyen esta sección, aunque con nombres ligeramente diferentes, diferentes ítems y en distinto orden. En la versión norteamericana, se llama How children use words, ‘¿Cómo usan las palabras los niños?’; en la mexicana, ¿Cómo usa y comprende el niño/a el lenguaje?; y, en la versión peninsular, Usos del lenguaje. Nosotros adoptamos este último nombre. La versión peruana incluye los siguientes ítems, con opciones de contestar todavía no, a veces13 y muchas veces.
-
¿Habla su hijo de personas o cosas que no están presentes? Por ejemplo, ¿pide su juguete o comida favoritos o pregunta por una persona ausente?
-
¿Habla de situaciones pasadas? Si unos días antes vieron un payaso o un mago en una fiesta de cumpleaños, ¿lo menciona después?14
-
¿Habla su hijo de cosas que todavía no han ocurrido? Por ejemplo, ¿dice que va a ver a su abuela?
-
¿Hace preguntas?
-
¿Su hijo/a entiende cuando le piden que traiga algo de otro cuarto? Por ejemplo, si le preguntan, "¿dónde está tu pelota?", ¿el niño/a va a buscarla a otro cuarto?
-
Al señalar o tomar un objeto, ¿su hijo/a dice el nombre de la persona a la que pertenece aunque esa persona no esté presente? Por ejemplo, ¿encuentra los lentes de su papá y dice "papá"?
Las tres primeras se encuentran en todas las versiones. La cuarta solo estaba en la versión peninsular, y la quinta y la sexta solo en las versiones norteamericana y mexicana. Nosotros mantuvimos todas las preguntas de todas las versiones, por lo que terminamos con seis ítems.
5.4. Parte II. Gestos, juegos y acciones. Forma I
Esta sección está solo en la Forma I e investiga acciones comunes en los niños para medir si participan en actividades que indiquen un nivel de comunicación y socialización adecuados para su edad. Incluye una sección importante de gestos comunicativos producidos por los niños. Pregunta también sobre juegos comunes en el hogar que involucran al lenguaje, acciones que realizan los niños con un objeto (peinarse, comer con un cuchara, beber de un vaso, ponerse un zapato o media, oler una flor, empujar un carrito, patear una pelota, etc.), la capacidad del niño de participar en juego simbólico usando un objeto en lugar de otro (por ejemplo, hacer como que un control remoto es un avión o un teléfono) e imitar las acciones de los cuidadores con un muñeco (darle un beso, ponerle un pañal, acostarlo, pasearlo en un cochecito, mecerlo, darle una mamadera, taparlo con una manta). Además de incluir todas las secciones en nuestra versión, solo hicimos cambios, más allá de cuestiones de adaptación del texto de los ítems a nuestro dialecto, a la sección de Gestos. Debido a las limitaciones de espacio, no discutimos aquí las adaptaciones a esta sección que se pueden consultar en Fernández-Flecha et al. (en evaluación).
5.5. Parte II. Gramática. Forma II
La sección de gramática es la que más varía de una versión a otra, ya que las gramáticas del inglés y el castellano son muy diferentes en términos morfológicos, y las versiones mexicana y peninsular han abordado esta parte del instrumento de maneras distintas. Explicamos las diferencias y los cambios en cada sección.
5.5.1. Terminaciones de palabras
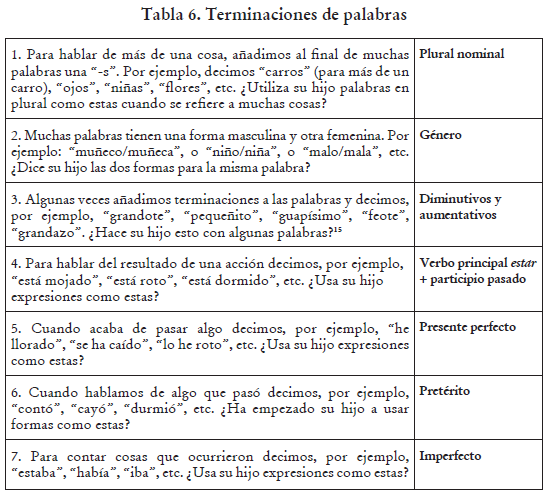
Todas las adaptaciones revisadas incluyen esta sección, pero el número de ítems varía mucho de una a otra. La versión norteamericana tiene solo cuatro ítems, que preguntan sobre el uso de los sufijos -s de plural, el morfema –‘s de posesivo, el progresivo -ing y el sufijo de pasado regular -ed. En todos se ofrece la opción de contestar todavía no, a veces y muchas veces.
En la versión mexicana, se opta por llamar a esta sección Formas de verbos y se listan formas de los verbos de las tres conjugaciones castellanas, usando como ejemplo los verbos acabar, comer y subir, para que el padre marque las formas que el niño usa. Se listan las formas primera singular, segunda singular informal, tercera singular, primera plural presente, y la primera singular y tercera singular del pasado perfectivo, además de las formas imperativas con y sin clítico con interpretación benefactiva (come y cómete (la carne)) de los tres verbos. La versión mexicana no pregunta aquí por la forma del plural nominal ni por el gerundio, como sí hace la norteamericana.
La versión peninsular adopta la estructura de la versión norteamericana, pero, dado que la morfología castellana es más compleja, añade 8 ítems. Uno de los ítems específicamente se enfoca en la conjugación de la persona y número en el verbo y, por lo tanto, cumple la misma función que la sección de la versión mexicana. Presentamos en la Tabla 6 la versión peruana, adaptada a partir de la peninsular con ligeras adaptaciones de léxico.
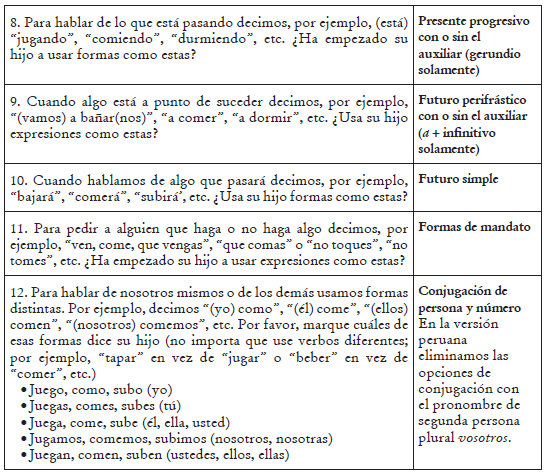
5.5.2. Verbos irregulares
Esta sección no está incluida en la versión mexicana. La versión norteamericana presenta una lista para marcar que incluye verbos irregulares (20 ítems) y plurales nominales irregulares (5 ítems). La versión peninsular incluye también una lista con 19 formas irregulares de verbos para marcar que hemos adoptado. Ya que los únicos plurales que se podrían considerar irregulares en castellano son las formas en las que el sustantivo no cambia y se marca el plural en el determinante (los oasis, esas crisis), que no forman parte del vocabulario temprano de los niños, las listas en castellano solo incluyen verbos. La lista completa se muestra en la Tabla 7 e incluye las formas de primera singular, segunda singular informal y tercera plural del presente de ser; la primera singular presente de ir, dar, caer, poner, caber, saber y decir; la primera singular pretérito de hacer, ser/ir, decir, dar y caer; y los participios pasados irregulares de romper, escribir, hacer y poner.

5.5.3. Sobrerregularizaciones
Se llama sobrerregularizaciones a formas irregulares de verbos o sustantivos que son flexionadas incorrectamente con sufijos regulares. Estas formas, aunque incorrectas en el lenguaje adulto estándar, evidencian la capacidad de los niños para aplicar los procesos de flexión en una lengua —en tanto no las pueden haber copiado del input adulto—. La importancia y frecuencia de estas formas ha llevado a interesantes debates teóricos (Pinker y Ullman 2002, McClelland y Patterson 2002, Tomasello 2003, entre otros).
La versión norteamericana llama a esta sección Word Endings/Part 2 y presenta 14 ejemplos de plurales nominales sobrerregularizados (blockses ‘bloques’, childrens ‘niños’, childs ‘niños’, feets ‘pies’, mouses ‘ratones’) y 31 verbos sobrerregularizados (ated ‘comió’, blewed, blowed ‘sopló’, bringed ‘trajo’), presentando para todos los casos la flexión regular y algunos casos con la raíz alternando entre las formas singular y plural o entre "presente" (blowed) y pasado (blewed).
La versión mexicana no incluye esta sección. La versión peninsular y la nuestra listan ejemplos de dos tipos de sobrerregularizaciones: verbales, y de género para sustantivos o adjetivos que no tienen un sufijo que indique su género. Se pregunta al padre si ha oído al niño decir algo parecido y debe marcar su respuesta para cada uno de los dos tipos. La Tabla 8 presenta la versión peruana, en la que hemos cambiado varias de las formas verbales de la versión peninsular por otras que nos parecieron más claras o frecuentes.

5.5.4. Combinación de palabras
Todas las versiones preguntan si el niño ha empezado a producir enunciados de más de una palabra y brindan ejemplos a los padres, como papá carro, más agua, pelota aquí o tú a(l) parque. Los padres deben responder todavía no, a veces o muchas veces según corresponda. Se pide a los padres, además, que den tres ejemplos de las frases más largas que recuerden que haya dicho el niño; estas se usan para medir la longitud media del enunciado.16
5.5.5. Complejidad morfosintáctica
Esta sección es la más distinta entre todas las versiones y, por lo tanto, la más difícil de adaptar. En la versión norteamericana se llama simplemente Complexity ‘Complejidad’, en la mexicana Complejidad de frases, y en la peninsular y la peruana Complejidad morfosintáctica. En esta sección, se listan una serie de frases y se pide a los padres que marquen la forma que se parezca más a cómo habla el niño. Las versiones norteamericana y mexicana listan 37 pares de frases; la versión peninsular, 34 grupos de tres frases que incluyen la opción Todavía no dice nada parecido. Además de esto, las frases de la versión mexicana no son traducciones de la versión norteamericana, ya que los fenómenos gramaticales de ambas lenguas no siempre coinciden. Las construcciones evaluadas en la versión mexicana tampoco coinciden con las de la versión peninsular, probablemente debido a que cada una se basó en su propio corpus. La versión norteamericana y mexicana, además, incluyen estructuras más sencillas que la peninsular.
Ante esta falta de coincidencia y tras una exhaustiva revisión de las frases de las tres versiones, optamos por listar los fenómenos que nos parecían más importantes, eliminar aquellos que ya fueran evaluados en otras secciones (por ejemplo, el plural nominal y la flexión verbal) y construir nuestra propia lista de 21 pares de frases, a los que añadimos la opción Todavía no dice nada parecido como alternativa de respuesta, que existía en la versión peninsular pero no en las demás. Las Tablas 9 a 12 listan los pares de frases que ven los padres y, del lado derecho, el fenómeno evaluado; hemos eliminado en esta presentación la opción de Todavía no dice nada parecido para acortar la tabla. Como se verá, para cada estructura se incluyó un contexto que ayudara a su comprensión, siguiendo a la versión peninsular.17
En la primera tabla, mostramos los ítems relacionados con sustantivos y sus modificadores.

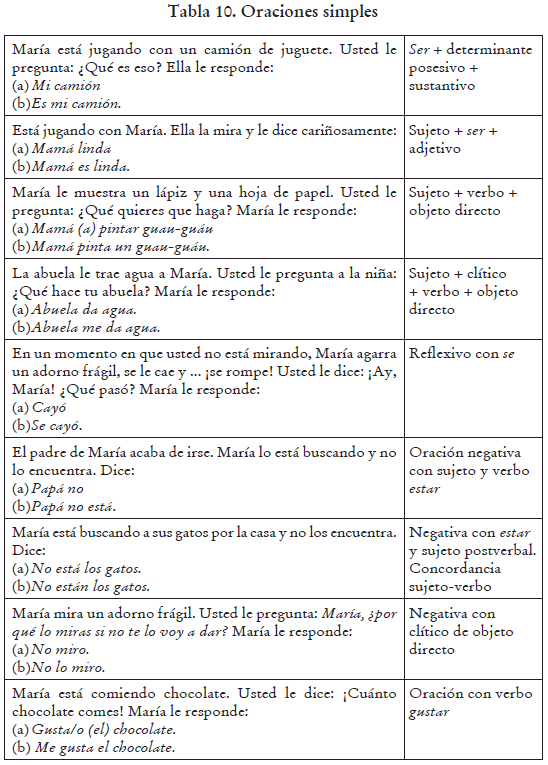
En la siguiente tabla, mostramos las oraciones simples evaluadas, en las que incluimos las estructuras oracionales más básicas y comunes en el habla infantil
La Tabla 11 muestra oraciones interrogativas e imperativas tempranas.

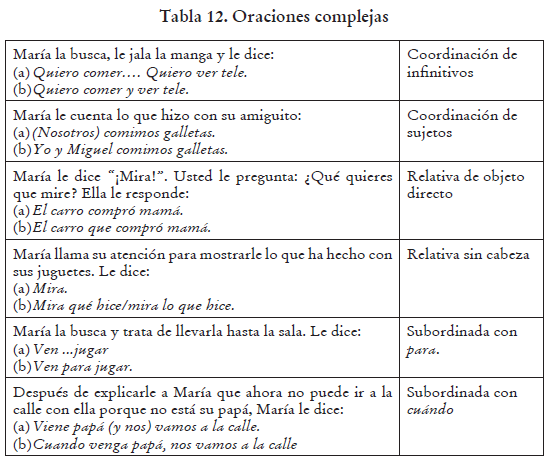
Por último, la Tabla 12 muestra las oraciones complejas.
Con esto finalizamos la descripción de la adaptación de la Parte III Gramática, y también nuestra descripción de todas las secciones de las Formas I y II y las adaptaciones que hicimos.
5.6. Versión peruana actual
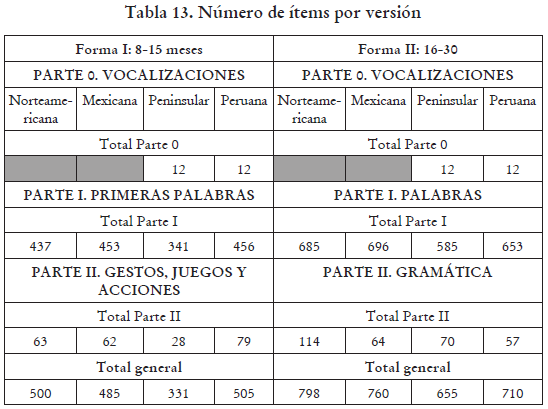
Este largo proceso nos ha permitido tener un instrumento que se asemeja mucho a las tres versiones comparadas, pero que recoge también elementos importantes de nuestro dialecto particular del castellano. Para terminar, mostramos en la Tabla 13 la cantidad de ítems en las secciones principales de los CDI, así como el número total de ítems para todas las versiones revisadas, además de la peruana.
6. Conclusiones
Tenemos ya una versión adaptada de las formas I y II para el castellano estándar peruano. El siguiente paso será examinar estas versiones a la luz de los datos obtenidos de las grabaciones de video del grupo de niños que participaron en la primera parte del estudio, tal como se ha hecho en otras versiones (Bates et al. 1975, Marchman y Martínez-Sussman 2002). Estas grabaciones han sido transcritas y podrán ser empleadas como una primera base de datos, que esperamos crezca, para determinar si hay concurrencia entre los resultados de los inventarios y la producción espontánea. Finalmente, exploraremos posibles colaboraciones con instituciones del Estado con miras a proceder a la estandarización necesaria con el objetivo de establecer baremos que permitan evaluar el desarrollo lingüístico y comunicativo individual en relación con la población general. La versión ya estandarizada nos permitirá, entonces, establecer cuáles son los puntos esperados o típicos de desarrollo en el proceso de aprendizaje del español peruano y, con esto, detectar aquellas trayectorias evolutivas atípicas, o que supongan un retraso o desviación frente a lo esperado. Así mismo, esta herramienta supondrá un apoyo invaluable para la evaluación del lenguaje de los niños peruanos antes de iniciar el proceso de escolarización, dado que podría aportar criterios o parámetros de desarrollo lingüístico mínimos tales que permitan un verdadero aprovechamiento del aprendizaje en aula. Sabemos que el desarrollo del lenguaje en etapas anteriores al inicio de la educación formal predice fuertemente el nivel de lenguaje posterior y el desarrollo de la comprensión de lectura (Oakhill y Cain 2012; Florit y Levorato 2012; y Morales 2011 y Junyent 2015 para niños peruanos). Así, observamos que, más allá de medir el nivel de desarrollo lingüístico del niño para fines académicos o de investigación, estos inventarios resultarán vitales en temas de salud y de educación, en tanto su aplicación podría contribuir en el ámbito educativo y de los trastornos del desarrollo.
Los inventarios MacArthur-Bates CDI constituyen, pues, un instrumento de medición confiable, válido y, además, valioso para el estudio tanto del desarrollo típico como atípico de primeras lenguas y segundas lenguas en los niños. Su valor en los campos de la investigación, la educación y la salud no puede ser suficientemente enfatizado. Una adaptación específica para el castellano peruano es no solo un aporte importantísimo sino urgentemente necesario.
REFERENCIAS BIBLIOGRÁFICAS
Álvarez vita, Juan 2009 Diccionario de Peruanismos. El habla castellana del Perú. 2ª edición. Lima: Universidad Alas Peruanas. [ Links ]
Bates, Elizabeth, Luigia Camaioni y Virginia Volterra 1975 "The acquisition of performatives prior to speech". MerrillPalmer Quarterly. 21, 3, 205-226. [ Links ]
Brown, Roger 1973 A first language: The early stages. Cambridge, MA: Harvard University Press. https://doi.org/10.4159/harvard.9780674732469. [ Links ]
Dale, Philip S., Elizabeth Bates, J. Steven Reznick y Colleen Morisset 1989 "The validity of parent reports instrument of child language at 20 months". Journal of Child Language. 16, 2, 239-250. https://doi.org/10.1017/S0305000900010394.
Dale, Philip S., Ginette Dionne, Thalia C. Eley y Robert Plomin 2000 "Lexical and grammatical development: A behavioural genetic perspective". Journal of Child Language. 27, 3, 619-642. https://doi.org/10.1017/S0305000900004281. [ Links ]
Devries, Beverly A. 2012 "Vocabulary assessment as predictor of literacy skills". The New England Reading Association Journal. 47, 2, 4-9. [ Links ]
Dollaghan, Christine A., Thomas F. Campbell, Jack L. Paradise, Heidi M. Feldman, Janine E., Jansoky, Dayna N. Pitcairn y Marcia Kurs-lasky 1999 "Maternal education and measures of early speech and language". Journal of Speech, Language and Hearing Research. 42, 6, 1432–1443. https://doi.org/10.1044/jslhr.4206.1432. [ Links ]
Escobar, Alberto 1978 Variaciones sociolingüísticas del castellano en el Perú. Lima: Instituto de Estudios Peruanos. [ Links ]
Escobar, Anna María 2011 "Spanish in contact with Quechua". En The Handbook of Hispanic Sociolinguistics. Ed., Manuel Díaz-Campos. Malden, MA: Blackwell, 323–352. https://doi.org/10.1002/9781444393446.ch16. [ Links ]
Farkas, Chamarrita 2011 "Inventario del Desarrollo de Habilidades Comunicativas MacArthur-Bates (CDI): propuesta de una versión abreviada". Universitas Psychologica. 10, 1, 33-50. https://doi.org/10.11144/Javeriana.upsy10-1.idh. [ Links ]
Fenson, Larry, Philip S. Dale, J Steven Reznick, Donna J. Thal, Elizabeth Bates., Jeffrey P. Hartung, Steve. Pethick y Judy S. Reilly 1993 The MacArthur Communicative Development Inventories: User´s guide and technical manual. San Diego, CA: Singular Publishing Group. https://doi.org/10.2307/1166093. [ Links ]
Fenson, Larry, Philip S. Dale, J Steven Reznick, Elizabeth Bates, Donna J. Thal y Stephen J. Pethick 1994 "Variability in early communicative development". Monographs of the Society for Research in Child Development. 59, 5, Serial N. 242, 1-175. [ Links ]
Fernández-Flecha, María 2012 "Evolución funcional de la conducta comunicativa infantil. Estudio de caso de un niño castellano-hablante". Tesis doctoral. Universidad Complutense de Madrid. [ Links ]
Fernández-Flecha, María, Andrea Junyent, María Blume y Talía Tijero (en evaluación) "Early gestural production in Peruvian children, and its correlations with vocalizations and receptive vocabulary". Enviado a la revista académica Gesture el 3 de julio de 2018. [ Links ]
Fernández, María C. y Umbel, Vivian M. 1991 Inventario del Desarrollo de las Habilidades Comunicativas: Adaptación Cubana. Miami, Florida: University of Miami / Mailman Center for Child Development. [ Links ]
Florit, Elena y M. Chiara Levorato 2012 "A longitudinal study on listening text comprehension and receptive vocabulary in preschoolers". Rivista di psicolinguistica applicata. 12, 1-2, 65-80. [ Links ]
Gallego, Carlos y Susana López-Ornat 2005 "El desarrollo del vocabulario temprano. Su evaluación con el i-LC1". En Estudios sobre la adquisición del lenguaje. Eds., Emiliano Díez-Villoria, Begoña Zubiauz de Pedro y María Ángeles Mayor Cinca. Aquilafuente: Universidad de Salamanca, 909-928. [ Links ]
Hart, Betty y Todd R. Risley 1995 Meaningful differences in the everyday experience of young American Children. Baltimore: Brookes. [ Links ]
Hildebrandt, Martha 2013 Peruanismos. Lima: Espasa. [ Links ]
Hoff, Erika 2003 "The specificity of environmental influence: Socioeconomic status affects early vocabulary development via maternal speech". Child Development, 74, 5, 1368–1378. https://doi.org/10.1111/1467-8624.00612. [ Links ]
Hoff-Ginsberg, Erika 1991 "Mother-child conversation in different social classes and communicative settings". Child Development. 63, 4, 782–796. [ Links ]
Jackson-Maldonado, Donna, Donna Thal, Virginia Marchman, Elizabeth Bates y Vera Gutiérrez-Clellen. 1993 "Early lexical development in Spanish-speaking infants and toddlers". Journal of Child Language. 20, 3, 523-549. https://doi.org/10.1017/S0305000900008461. [ Links ]
Jackson-Maldonado, Donna, Donna J. Thal, Virginia Marchman, Tyler Newton, Larry Fenson y Barbara Conboy 2003 MacArthur Inventarios del Desarrollo de Habilidades Comunicativas. User´s Guide and Technical Manual. Baltimore: Brookes. [ Links ]
Jackson-Maldonado, Donna 2004 "El retraso del lenguaje en niños mexicanos: vocabulario y gestos". Anuario de Psicología. 35, 2, 257-278. [ Links ]
Jackson-Maldonado, Donna y Rosa Patricia Bárcenas Acosta 2006 "Assessing early communicative abilities in Spanish-speaking children from low-SES families". Zero to Three. Septiembre, 1-6. [ Links ]
Junyent, Andrea 2015 Identificación de predictores del desempeño en la comprensión de textos orales y escritos. Lima: Consorcio de Investigación Económica y Social - Fortalecimiento de la Gestión de la Educación en el Perú - Grupo de Análisis para el Desarrollo. Consultado: s/f. http://cies.org.pe/sites/default/files/investigaciones/jun-yent_predictorescomprensionlectora_informe.pdf. [ Links ]
Junyent, Andrea, María Blume, María Fernández-Flecha y Talía Tijero (en prensa) "El vocabulario y su relación con la gramática en niños de 16 a 30 meses hablantes de castellano peruano". Ms., PUCP. [ Links ]
Lara, María Fernanda, Ángela María Gómez Fonseca, Diana Marcela Gálvez Bohórquez, Carol Mesa Guechá y Elisabet Serrat Sellabona 2011 "Normativización del CDI Inventario del Desarrollo Comunicativo MacArthur-Bates al Español-Colombia". Revista Latinoamericana de Psicología. 43, 2, 241-254. [ Links ]
López Ornat, Susana, Carlos Gallego, Pilar Gallo, Alexandra Karousou, Sonia Mariscal y María Martínez 2005 Inventarios de Desarrollo Comunicativo MacArthur. Manual. Madrid: TEA, Ediciones. [ Links ]
López-Ornat, Susana y Alexandra Karousou 2005 "Las vocalizaciones tempranas (8-30 meses) y su relación con el vocabulario y la gramática. Su medida en el ‘CDI español’: resultados preliminares". En Estudios sobre la adquisición del lenguaje. Eds., Emiliano Díez-Villoria, Begoña Zubiauz de Pedro y María Ángeles Mayor Cinca. Aquilafuente: Universidad de Salamanca, 401-420.
Marchman, Virginia A. y Carmen Martínez-Sussmann 2002 "Concurrent validity of caregiver/parent report measures of language for children who are learning both English and Spanish". Journal of Speech, Language & Hearing Research. 45, 5, 983-997. https://doi.org/10.1044/1092-4388(2002/080). [ Links ]
Mariscal, Sonia, Alexandra Karousou, María Martínez, Pilar Gallo, Carlos Gallego y Susana López Ornat 2007 "La evaluación del desarrollo comunicativo y lingüístico mediante la versión española de los inventarios Mac ArthurBates". Psicothema. 19, 2, 190-197. [ Links ]
Mcclelland, James L. y Karalyn Patterson 2002 "‘Words or Rules’ cannot exploit the regularity in exceptions: Reply to Pinker and Ullman". Trends in Cognitive Sciences. 6, 11 464-465. https://doi.org/10.1016/S1364-6613(02)02012-0.
Ministerio de Educación 2013 Documento Nacional de Lenguas Originarias del Perú. Consultado: 11 de diciembre de 2019. [ Links ]
Morales, Silvia 2011 "Variables socioculturales y cognitivas en el desarrollo de la comprensión de lectura en Lima, Perú". Revista Peruana de Investigación Educativa. 3, 96-129. [ Links ]
Oakhill, Jane V. y Kate Cain 2012. "The precursors of reading ability in young readers: Evidence from a four-year longitudinal study". Scientific Studies of Reading. 16, 2, 91-121. https://doi.org/10.1080/10888438.2010.529219. [ Links ]
Pinker, Steven y Michael T. Ullman 2002 "The past and future of the past tense". Trends in Cognitive Sciences. 6, 11 456-463. https://doi.org/10.1016/S1364-6613(02)01990-3. [ Links ]
Real Academia Española 2017 Diccionario de la Lengua Española. Consultado: julio 2018. http://dle.rae.es/. [ Links ]
Resches, Mariela, Norma Maglio y Adriana Luque (Manuscrito, no publicado) "Inventario del Desarrollo Comunicativo MacArthur-Bates. Adaptación al español-rioplatense" [ Links ]
Tomasello, Michael 2003 Constructing a language: A usage-based theory of language acquisition. Cambridge, MA: Harvard University Press. [ Links ]
Thal, Donna, Donna Jackson-Maldonado y Dora Acosta 2000 "Validity of parent-report measure of vocabulary and grammar for Spanish-speaking toddlers". Journal of Speech, Language & Hearing Research. 43, 5, 1087-1100. https://doi.org/10.1044/jslhr.4305.1087. [ Links ]
Thal, Donna J., Laureen O’hanlon, Mary Clemmons y LaShon Frailin 1999 "Validity of a parent report measure of vocabulary and syntax for preschool children with language impairment". Journal of Speech, Language & Hearing Research. 42, 2, 482-496. https://doi.org/10.1044/jslhr.4202.482.
Velásquez, Mónica, Leonardo Cepeda, Raúl Alarcón, María Pía Silva y Sergio Muñoz (Manuscrito, no publicado) "Inventario del Desarrollo Comunicativo MacArthur-Bates. Adaptación al español chileno". [ Links ]
Vigil, Nila 2003 "Enseñanza de castellano como lengua maternal en un modelo de educación intercultural". En Actas del V Congreso Latinoamericano de Educación Intercultural Bilingüe: Realidad multilingüe y desafío intercultural: Ciudadanía, política y educación. Ed., Roberto Zariquiey. Lima: Fondo Editorial de la Pontificia Universidad Católica del Perú, 247–261. [ Links ]
-
* Este trabajo fue financiado por la Dirección de Gestión de la Investigación de la PUCP, a través de la subvención DGI-2015-1-0020 y 2016-1-0065. Queremos agradecer a los niños que participaron en nuestra recolección de habla natural y a sus padres que nos permitieron entrar a sus casas a grabarlos y que pacientemente contestaron los inventarios y los cuestionarios en línea. De igual manera, queremos agradecer a las instituciones educativas de nivel inicial que nos ayudaron a contactar a niños y padres. Finalmente, queremos agradecer a nuestro excelente equipo de asistentes de investigación, todos estudiantes de pregrado, que trabajaron incansablemente y con entusiasmo para llevar esta investigación a cabo: Aixa Chaparro, Karina Aguirre, Victoria Maraví, Jorge Narváez, Marcela Damonte y Freyda Schuler. También agradecemos a las colaboradoras que nos ayudan aún en el proceso de codificación de los datos de habla natural: Minerva Cerna, Stefanny Ibarra, Silvia Sinchitullo y Geraldine Arias. Finalmente, gracias especiales a Fiorella Otiniano por su invaluable ayuda en el análisis estadístico de nuestros datos. Este es un proyecto del Grupo de Investigación en Adquisición del Lenguaje (GRIAL) de la Pontificia Universidad Católica del Perú.
-
1 La Longitud Media del Enunciado (LME) o Promedio de Longitud del Enunciado (PLE) corresponde al Mean Length of Utterance (MLU), una medida establecida por Roger Brown (1973) para medir el desarrollo lingüístico de los niños, ya que se sabe que los niños pequeños desarrollan sus habilidades lingüísticas a diferentes ritmos, por lo que la edad no es siempre un buen predictor. La MLE se calcula sumando el número de morfemas por enunciado en una muestra de enunciados de habla natural y dividiéndolas por el número de enunciados producidos por el niño.
-
2 http://mb-cdi.stanford.edu. Consultado: julio 2018.
-
3 Como el proyecto es bastante extenso, reportamos aquí solamente la adaptación. Junyent et al. (en prensa) reporta los resultados en términos de la relación entre vocabulario y gramática de los pilotos que hemos llevado a cabo, y Fernández-Flecha et al. (en evaluación) reporta las correlaciones entre gestos, por un lado, y vocalizaciones y vocabulario, por otro lado.
-
4 Entre las investigadoras de GRIAL, María Fernández-Flecha ha colaborado previamente con Susana López Ornat, quien estuvo a cargo de la adaptación al español peninsular del CDI, y Andrea Junyent colabora actualmente en la estandarización de la adaptación argentina del CDI con el equipo de Mariela Resches.
-
5 De aquí en adelante, y para facilitar la lectura del texto, hablaremos de el padre/ los padres para referirnos tanto a padres y a madres como a otros cuidadores. De igual manera, diremos el niño/los niños, aunque nos refiramos a niños y niñas.
-
6 Si entendemos bien la tabla 4.1 del manual para la versión peninsular, el lugar de procedencia de los padres corresponde al lugar en el que se recogieron los datos (López-Ornat y Karousou 2005: 48).
-
7 http://wordbank.stanford.edu/. Consultado: julio 2018.
-
8 Para nuestra decepción tuvimos que eliminar algunas como cuy y llama, que obtuvieron bajos resultados incluso en los niños de 16-30 meses.
-
9 Un pequeño número de ítems (17) de la Forma I no fue probado ni en los pilotos ni en los cuestionarios en línea por un cambio en las decisiones durante el proceso, pero fue incluido porque había tenido resultados altos en el cuestionario en línea de la Fase II y estaban por lo menos en una de las otras versiones de la Fase I. En un inicio, hicimos el cuestionario en línea para la Fase II, bajo la lógica de que, si los nuevos ítems no tenían un buen puntaje en esta edad, no tenía sentido incluirlos en la Fase I. Decidimos aceptar todos los ítems que tuvieran un puntaje de 10 o más, de un máximo de 27. Sin embargo, debido a que nuestro número de ítems seguía siendo muy bajo, decidimos luego aceptar todos los ítems que tuvieran un puntaje de 5 o más, lo que nos permitió tener un número de ítems similar a las otras versiones. Este cambio de decisión nos causó un pequeño dilema. Al reducir el criterio de inclusión en la Forma II, descubrimos que teníamos una serie ítems que habían tenido más de 5 y menos de 10 puntos en el cuestionario de la Fase II que no habían sido incluidos en el cuestionario en línea para la Fase I.
-
10 Definimos protopalabra (Fernández-Flecha 2012) como una emisión cuyo significado se superpone con el de la versión adulta, al margen de que guarde o no un parecido fonético con esta. Ejemplo: el niño usa la forma /mai/ para referirse al CD o a la música o a la imagen de Michael Jackson. En este caso, aunque el parecido fonético sea muy primario, la sistematicidad en el uso para referirse siempre al mismo personaje —o a elementos relacionados con él— motiva su codificación como protopalabra.
-
11 Ver http://mb-cdi.stanford.edu/board.html (esta página presenta la información del CDI Advisory Board) y http://mb-cdi.stanford.edu/adaptations.html (esta página indica que se debe pedir autorización y da acceso a la guía para las adaptaciones). Consultado: julio 2018.
-
12 Ver http://dle.rae.es/. Consultado: julio 2018
-
13 La versión mexicana usa de vez en cuando.
-
14 La versión peninsular dice vieron un payaso en el circo en lugar de vieron un payaso o un mago en una fiesta de cumpleaños. Cambiamos la situación porque los circos no son tan comunes en el Perú.
-
15 Aquí eliminamos la opción bonico que no nos pareció frecuente en nuestro dialecto.
-
16 La versión de los CDI de la LME es diferente a la tradicional, ya que se basa solo en los tres enunciados más largos, tal como los recuerdan los padres y no grabados en una sesión.
-
17 La sección empieza con la siguiente instrucción (aquí resumida por limitaciones de espacio)
-
En esta sección […], le vamos a mostrar ejemplos de frases, imaginando que su hijo se llama María. Por favor, MARQUE LA MANERA DE HABLAR QUE LE SUENE MÁS PARECIDA A COMO HABLA SU HIJO EN ESTE MOMENTO. No es necesario que las palabras de su hijo sean las mismas que las de los ejemplos; lo que le pedimos es que marque la frase que más se parece a la manera en que habla su hijo. […]
-
Marque la opción (a) si las frases de su hijo son equivalentes a esta alternativa [carro papá], pero todavía no dice frases como (b) [carro de papá]. Marque la opción (b), si su hijo dice, por ejemplo, "zapato de mamá" o "pelota de Juan", etc. Si ya dice frases como (b), marque esta alternativa, aunque no lo haga siempre y aunque, en ciertas ocasiones, diga frases como (a). Marque la opción (c) [todavía no dice nada parecido], si su hijo aún no dice frases como (a) ni como (b).
Recepción: 09/08/2018
Aceptación: 26/08/2019

