











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkI. Introducción
El presente artículo se centra en los fundamentos metodológicos del procesamiento y análisis del Corpus Básico del Español de Chile© (Castillo Fadić 2012a). Este corpus, de algo más de 500.000 palabras en contexto, recibe este nombre porque a partir de él se elaboró el Léxico Básico del Español de Chile (Castillo Fadić 2020a). Fue obtenido mediante una serie de muestreos estratificados sobre publicaciones de autores chilenos de las categorías Drama, Narrativa, Ensayo, Técnico-Científico y Prensa, de un periodo de 26 años que abarca los siglos XX y XXI (véase Castillo Fadić 2020b). Los fundamentos teóricos de la investigación que dio origen a este corpus se encuentran en Castillo Fadić (2020a). Damos cuenta, a continuación, de los criterios para ordenar los materiales, segmentar y lematizar, empleando un programa elaborado ad hoc para esta investigación y especialmente preparado para procesar y analizar corpus de español de Chile.
II. Procesamiento del corpus: pasos y métodos
El procesamiento del corpus revistió muchísima complejidad y exigió el empleo de herramientas informáticas de alta especificidad. Para ello, utilizamos un programa computacional elaborado ad hoc para esta investigación1, que permite procesar de manera adecuada los materiales obtenidos tras los diversos muestreos, tanto en lo correspondiente a la lematización automática, como en lo relativo a la obtención de la frecuencia de cada unidad y a su dispersión, producto de las cuales se determina el uso. El programa computacional, que recibe el nombre de LexBas 1.0 y que se apoya en FreeLing 2.22, inició su marcha blanca a mediados de enero de 2011. Durante todo el primer semestre de ese año, se realizaron múltiples pruebas para perfeccionarlo en virtud de los objetivos de la investigación y se establecieron codificaciones para resolver casos que resultaban ambiguos para el procesamiento automático. “Los datos fueron preparados para el tratamiento informático y las fórmulas utilizadas fueron convertidas, actualizando los postulados iniciales y las fórmulas de Juilland y Chang-Rodríguez (1964), Juilland, Traversa, Beltramo, y Di Blasi (1973) y también los más actualizados de Morales (1986)” (Humberto López Morales 2020: en prensa).
Dado que para un procesamiento automático efectivo del lenguaje natural es fundamental la labor interdisciplinaria (véase Alvar Ezquerra, Blanco Rodríguez y Pérez Lagos 1994, Alvar Ezquerra y Corpas Pastor 1994, y Lavid 2005), trabajamos en estrecha colaboración con el informático encargado de LexBas 1.0, para corregir detalles y lograr un eficaz procesamiento automático que permitiera obtener el listado de frecuencia, dispersión y uso, que era lo central de nuestra investigación (véase Castillo Fadić 2015a). En conjunto, revisamos el funcionamiento de distintos modos de consulta del programa3 y detectamos falencias en el análisis automático que estimamos necesario corregir, en virtud de los objetivos de la investigación; algunas de estas inexactitudes derivaban de la falta de acuerdo que existe aún en el ámbito teórico respecto de la clasificación de ciertas unidades, especialmente en las llamadas palabras gramaticales; otras tenían relación con limitaciones propias del procesamiento automático, que pierde precisión ante construcciones inhabituales (Almela, Cantos, Sánchez, Sarmiento y Almela 2005); otras muchas se desprendían de las necesidades particulares de esta investigación, centrada en un corpus extraído de fuentes chilenas, donde la variedad idiomática representada exhibe múltiples peculiaridades que la alejan del estándar panhispánico (veáse, por ejemplo, Rona 1962; Zamora Munné y Guitart 1982; y Moreno Fernández 2016) y que, por lo mismo, no están contempladas por el diccionario interno de FreeLing 2.2. Respecto de las primeras imperfecciones, que consideramos inevitables en un trabajo de esta naturaleza, intentamos establecer ciertas precisiones teóricas; sobre las segundas, vimos la necesidad de incorporar al programa mecanismos de edición manual, para modificar el análisis realizado por LexBas 1.0, cuando resultara necesario; como es lógico, la revisión manual acabada de todas y cada una de las oraciones suponía un esfuerzo de largo aliento, por lo que decidimos comenzar por la revisión de las oraciones correspondientes a vocablos contenidos en el recuento inicial de los 5.000 más usados, especialmente cuando el índice de certeza de análisis del software era distinto de 100%. Tomamos esta decisión basados en que los errores de análisis que incrementen o disminuyan el conteo de vocablos de muy bajo uso no tendrían prácticamente relevancia desde el punto de vista estadístico. Por el contrario, las imprecisiones en el análisis de vocablos de alto uso podrían alterar su rango o, incluso, podrían incidir en que quedaran dentro o no de las 100 palabras de mayor uso, o incluso de las 5000, sobre todo si estaban en posiciones de corte. Por ejemplo, si observamos el caso de los nombres propios, que solo se detectaron para ser eliminados, puesto que no tienen interés en un léxico básico, la aplicación encontró 51 645 formas distintas; si de estas hubiera 50 ocurrencias de una palabra analizadas incorrectamente, es decir, clasificadas como nombres propios siendo nombres comunes, o a la inversa, estaríamos hablando de una desviación de un 1 ‰ (0, 1%), lo que, desde el punto de vista estadístico, sería un margen irrelevante. Por último, respecto de las últimas imperfecciones, su solución pasa no solo por la incorporación de nuevas etiquetas y el incremento del procesamiento manual, sino que exige el mejoramiento del diccionario interno de FreeLing 2.2; vistas nuestras particularidades regionales (algunas de las cuales pueden revisarse en el apartado 2.4.3), consideramos que de todas ellas la más susceptible de análisis automático por medio de un diccionario4 y la de mayor impacto estadístico era el voseo verbal; por ello, creamos un diccionario de formas conjugadas voseantes, etiquetadas en EAGLES (Expert Advisory Group on Language Engineering Standards), a fin de alimentar el diccionario interno de FreeLing 2.2.
Los pasos que seguimos para procesar de manera automática el corpus fueron los siguientes:
2.1. Orden de los materiales
Los materiales recogidos se ordenaron inicialmente en una hoja de cálculo por cada mundo, como se observa en la Figura 1, donde registramos el número de sistema (columna A) con que cada obra se identificaba en la bibliografía proporcionada por la Biblioteca Nacional de Chile (véase Castillo Fadić 2020b), el nombre del autor (B), el título de la obra (C), los detalles de impresión (lugar, editorial y año) (D), la descripción (formato y número de páginas) (E) y la clasificación Dewey (F). A estas informaciones, agregamos la interpretación de la clasificación Dewey5, con indicación de género o materia (G-H), y el año de publicación (I), en columna separada.
Acto seguido (véase Figura 2), listamos alternadamente las oraciones que extraeríamos de cada una de las obras (J, M, P, S, V, Y, etc.), indicando la página de la que se sacaba la cita (K, N, Q, T, W, Z, etc.) y la línea sorteada (L, O, R, U, X, AA, etc.). Puesto que los sorteos fueron por azar sistemático, los números de página se ingresaron en las planillas de antemano; respecto de los números de línea, se ingresó el primero sorteado y luego se completó con números consecutivos; las columnas correspondientes a las oraciones fueron las últimas en llenarse.
De este modo, pudimos mantener un registro de las oraciones extraídas de cada fuente, con sus referencias completas, lo que permite citarlas si es preciso.

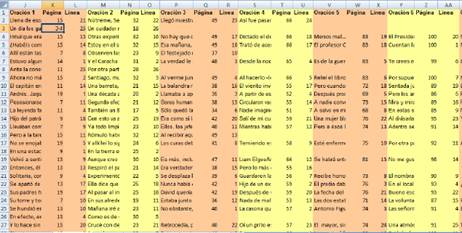
Una vez finalizado el proceso de recolección de corpus, el material de cada uno de los mundos se reunió en un archivo Excel único, con una hoja para cada mundo, respetando el orden y estructura de las bases iniciales y procurando ingresar solo un valor por campo, de modo de permitir el procesamiento automático. Este archivo fue ingresado sin cambios a LexBas 1.0, que lo procesó de manera automática distinguiendo mundos, referencias bibliográficas y oraciones.
2.2. Segmentación
2.2.1. Palabras y vocablos
Esta investigación considera como unidad mínima la palabra. Una de las ventajas de esta opción es que el hecho de que gráficamente esté separada de otras unidades similares por espacios en blanco permite una identificación automática eficaz.
No obstante, recurrimos también a otras unidades que han exigido procesamientos de mayor complejidad: los vocablos, que permiten agrupar distintas realizaciones bajo un único lema (véase Lyons 1997, Lara 2006), y las agrupaciones de palabras, que engloban todas las unidades fraseológicas, vale decir, todas aquellas formas que, estando compuestas por más de una palabra, funcionan como un todo (Corpas Pastor 1997).
2.2.2. Agrupaciones frecuentes
Se confeccionó un listado de agrupaciones frecuentes de palabras, para evitar que el programa lematizara separadamente palabras que, funcionalmente, constituyen una sola unidad; consideramos aquí tanto formas compuestas de los verbos como locuciones de distintos tipos (véase Figura 3). No obstante, dejamos fuera todo aquello que no fuera susceptible de sistematización, por cuanto no existía la posibilidad de un procesamiento automático. Este es el caso de perífrasis verbales y de formas cuyo análisis está sujeto a discusión.

Respecto de los verbos, se tratan como una unidad los tiempos verbales compuestos y las construcciones en forma pasiva. Esto es: <he comido>, que responde a la estructura <haber conjugado+ participio>, se analiza como una aparición del verbo en participio <comer> y no como una ocurrencia del verbo <haber>; la pasiva <ha sido olvidado>, que obedece a la estructura <ser conjugado+ participio>, se considera como ocurrencia del verbo en participio <olvidar>. En este último caso, el programa LexBas 1.0 analiza la pasiva como unidad, aun cuando haya palabras intercaladas, aunque ciertas ocurrencias deben tratarse manualmente; así, <es frecuentemente observado> se analiza como <es observado> + <frecuentemente> y se lematiza bajo <observar> y <frecuentemente> respectivamente.
No se unifican formas verbales de mayor complejidad, como perífrasis del tipo <ir buscando>, pues la falta de consenso en el análisis y la alta variabilidad impiden el tratamiento automático, como bien lo indica Morales (1986: 21):
Si bien en una secuencia como ha comido o había ido nadie duda de su funcionamiento como una sola unidad, hay un proceso gradual de independencia en está cosiendo, es castigado, ha de comenzar, tiene señalado, etc., que ya no la ofrecen con tanta claridad. Para mayor complejidad, todas estas formas, incluso las formas compuestas tradicionales, permiten la intercalación de un elemento adverbial, con lo cual se viola uno de los requisitos que exigen las formas para su consideración de independientes.
Respecto de las locuciones y demás unidades fraseológicas, se distinguen todas aquellas que forman parte del diccionario interno de FreeLing 2.2, lematizador de base del programa LexBas 1.0. A estas se han agregado manualmente otras combinaciones frecuentes que admiten sistematización, básicamente porque no permiten elementos intercalados o porque presentan una forma estable. En este sentido, adoptamos una solución distinta de la de Morales (1986: 22), quien no tiene en cuenta lo que llama “«unidad de función», por lo menos en un primer nivel de análisis”, y más parecida a la de Juilland y Chang-Rodríguez (1964), aun cuando intentamos aquí superar algunas de las falencias que presenta la mencionada obra en el procesamiento de unidades complejas, por medio de la combinación entre el tratamiento automático y el manual.
2.2.3. Amalgamas
En el caso de las amalgamas, procuramos seguir el tratamiento de Morales (1986: 20), a saber: “El español presenta dos casos típicos de amalgama que son los artículos contractos, al y del, y en cuanto a su tratamiento todos los estudiosos están de acuerdo en el conteo separado de las unidades que representan (a el y de el)”. De este modo, el programa LexBas 1.0 separa al y del en sus formantes y lematiza las ocurrencias de dichos formantes bajo los vocablos a, el y de respectivamente.
Respecto de los verbos con pronombres enclíticos, como Juilland y Chang-Rodríguez (1964) y Morales (1986: 20-21), tratamos separadamente los verbos y los pronombres (véase Figura 4).
2.3. Unidades excluidas
Nuestra investigación excluye números en dígitos, siglas y nombres propios. Puesto que el lematizador considera la presencia de mayúsculas en una posición distinta de “después de punto” como indicador de que se encuentra ante un nombre propio, se elaboró un listado etiquetado de las palabras que no son nombres propios pese a escribirse con mayúscula inicial, como <Gobierno> o <Padre> “sacerdote”, y otro de las que pueden no ser nombres propios pese a escribirse en mayúscula, como <Estado> o <Benigno>, para que el programa indicara su poca certeza en el tratamiento de esos casos y, de ese modo, los casos pudieran marcarse para desambiguación manual.
2.4. Lematización
Para la lematización, se utilizó el programa computacional LexBas 1.0. Este programa fue instalado para nuestro uso exclusivo en <http://vls43.dinaserver.com/> 6 (véase Figura 5) y estuvo operativo en ese servidor hasta el 15 de febrero de 2012. Actualmente, se encuentra operativo por medio de una máquina virtual instalada en nuestro ordenador que, para estos efectos, funciona como servidor.

LexBas 1.0 es un sistema de análisis morfológico automático que permite, basándose en FreeLing 2.2, asociar palabras a un vocablo, indicando a qué lema pertenecen, y categorizarlas, distinguiendo su clase gramatical por probabilidades, según su combinatoria. No permite, sin embargo, discriminar automáticamente entre acepciones, por lo que la homonimia léxica deberá ser resuelta en una etapa posterior7. De hecho,
[…] tanto si utilizamos un sistema estadístico como otro basado en el conocimiento lingüístico, el problema de la desambiguación morfológica es un problema, con todas las salvedades, resuelto, ya que son varios y de diverso tipo los sistemas que ofrecen márgenes de acierto superiores al 97%. Por desgracia, […] no sucede lo mismo con la desambiguación semántica. (Marín 2009: 475)
En efecto, “los índices de acierto que hallamos en la actualidad (rara vez superiores al 70%) distan de ser mínimamente aceptables” (Marín 2009: 480), lo que no tiene que ver solo con las dificultades para traspasar al ordenador reglas o pautas de discernimiento, sino también con la baja precisión humana al realizar manualmente la misma tarea, que llega apenas al 80%, mientras que en las demás tareas de procesamiento de lenguajes naturales ronda el 95% (Marín 2009: 481). Esto se debe, por una parte, a la enorme desproporción cuantitativa entre la ambigüedad semántica y la morfológica: mientras la última presenta un inventario acotado de homónimos, la primera debe lidiar con un elevado número de acepciones; por otra parte, si las clases o categorías que permiten distinguir homónimos morfológicos o sintácticos pueden ubicarse en una lista cerrada y claramente delimitada, los distintos significados de las unidades léxicas homónimas no siempre se encuentran delimitadas del mismo modo por los diversos lexicógrafos (Marín 2009: 480), lo que afecta tanto al número de acepciones contempladas para cada palabra, como al límite entre las acepciones reconocidas.
2.4.1. Desambiguación y etiquetación
Puesto que el lematizador funciona sobre la base de combinaciones sintácticas, fue necesario desambiguar las palabras que presentaban homonimia, mediante el uso de etiquetas en formato *XML en el archivo original del corpus. Este trabajo, arduo y manual, resulta básico para distinguir homónimos morfológicos o sintácticos, que en ciertos contextos podrían ser confundidos por el lematizador, especialmente si no hay marcas expresas en el texto, como un pronombre antes de un verbo, un sustantivo antes de un adjetivo o un artículo antes de un sustantivo. En estos casos, usamos etiquetas EAGLES (Expert Advisory Group on Language Engineering Standards, s/f)8, para que el lematizador pudiera reconocerlas. Estas etiquetas permiten asignar palabras a clases y se basan en las anotaciones y comentarios apuntados en el momento de la recolección del corpus, toda vez que se detectaba riesgo de ambigüedad, especialmente cuando se observaba que la oración, desprovista de un contexto mayor, podría presentar interpretaciones diversas. Esto fue más frecuente en Drama, donde las oraciones eran más breves que en los demás mundos (las de una palabra sola no eran inhabituales) y formaban, por lo general, parte de un diálogo; ello, sumado al recurso a lenguaje paraverbal, propio del género, significaba la común ausencia de sujetos expresos, lo que redundaba en la necesidad de indicar con gran frecuencia si el verbo se encontraba en segunda o tercera persona, ya se tratara del singular o del plural, por el sincretismo existente entre las conjugaciones correspondientes a usted y él/ella, y a ustedes y ellos/ellas, respectivamente, y entre yo y él/ella en algunos tiempos verbales.
Sin embargo, la relevancia mayor de las etiquetas aparece en el caso de la homonimia léxica, puesto que el programa no tiene la capacidad de distinguir por sí solo entre dos unidades de igual categoría gramatical que presenten diferencias semánticas de extensión o comprensión, como sucede con <as> “carta de naipe” y <as> “campeón”. Las etiquetas utilizadas procuran ser lo más simples posibles y no necesitan definir con exactitud las unidades léxicas, sino únicamente desambiguar, como en los casos de <carta>as</carta>, v/s <campeón>as</campeón>. En los casos de homonimia léxica, usamos definiciones operacionales propias y las insertamos en formato *XML. Las etiquetas EAGLES, en tanto, se concentran en aspectos gramaticales.
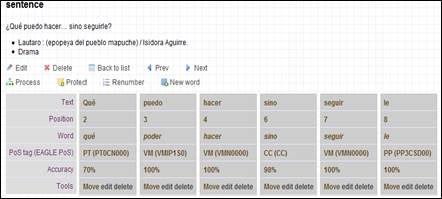
Ahora bien, más allá de la acuciosidad que se desee en la etiquetación de las unidades, es preciso enfatizar con Morales (1986: 24) que “cualquier decisión que se tome ofrecerá reparos debido a la asistematicidad que aún presenta la teoría en muchos de estos casos, lo cual impide llegar a acuerdos generales en cada una de las lenguas”. Esta asistematicidad, evidente al pretender resolver, por ejemplo, la complejidad funcional de <se> (véase Morales 1986: 23-25) o al intentar definir cuán fino se debe hilar en la distinción de acepciones de una palabra, no se queda en lo teórico, sino que alcanza el plano metodológico: así, el procesamiento automático será más o menos eficiente en la medida en que se le puedan proporcionar reglas claras de funcionamiento que operen en todos los casos. En otras palabras, la complejidad de la tarea no radica tan solo en entender o explicar teóricamente la diferencia entre homónimos, sino en lograr distinguir las marcas formales que pueden dar cuenta de la diferencia entre uno y otro, para luego traspasar ese conocimiento a un lenguaje inteligible para el ordenador. Con todo ello, en una lengua como el español, donde las posibilidades de ordenación de elementos al interior de la oración presentan una flexibilidad mayor que en otras lenguas, es imposible predecir todas las asistematicidades que pudieran producirse en un texto, por lo que cada una de ellas significará una pérdida de fiabilidad en el procesamiento automático de ese caso en particular. Por lo mismo, nuestro programa computacional explicita en términos de porcentajes el grado de certeza del análisis de cada una de las unidades (véase Figura 6, fila “Accuracy”). Como se puede observar en “viejos sistemas políticos” (véase Figura 6, fila “Text”, posiciones
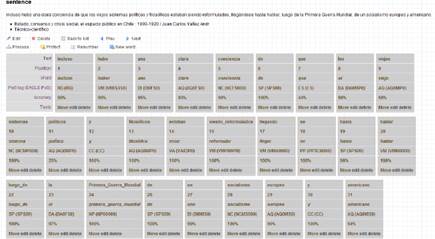
9, 10 y 11), la certeza del software tiende a disminuir cuando un sustantivo se ve modificado por dos o más adjetivos, especialmente cuando estos adjetivos no están coordinados expresamente, sino que uno se ubica antes y el otro después del mismo sustantivo. Esto puede explicarse por el hecho de que: 1) las formas nominales pueden cumplir tanto la función sustantiva como la adjetiva y 2) los adjetivos suelen ubicarse después del sustantivo, aunque pueden situarse también antes de este, según lo expliquen o especifiquen; como es lógico, el computador no tiene la capacidad humana de discernir entre estas opciones, de modo que requiere reglas que no tengan excepciones; todas las condiciones incrementan la pérdida de certeza del análisis automático.
2.4.2.1 Las formas nominales
Las formas singulares y plurales, masculinas y femeninas de los adjetivos se lematizan bajo el masculino singular. En el caso se los sustantivos, cuando la flexión de género redunda en un cambio de significado, como es el caso de el <editorial> o la <editorial>, ambas formas se lematizan por separado; si, en cambio, la flexión de género no obedece a un cambio semántico, se procede del mismo modo que con los adjetivos, como ocurre con el <gato> y la <gata>; del mismo modo se procede con las unidades que poseen diferente número. Con esta decisión, “no hace sino seguirse una tradición ampliamente justificada en teoría gramatical” (Morales 1986: 25).
2.4.2.2. Los pronombres personales
Los pronombres personales se agrupan, de acuerdo con los procesamientos de FreeLing 2.2, por persona, número y caso. En el caso de la tercera persona, que tiene flexión de género, los femeninos se lematizan bajo la forma masculina que corresponde.
La opción de listar separadamente los pronombres personales plurales de los singulares (véase Figuras 7 y 8) permite, a nuestro juicio, una mejor discriminación de las unidades léxicas. Cabe precisar que esta alternativa es distinta de la de Morales (1986), quien los contabiliza en conjunto.
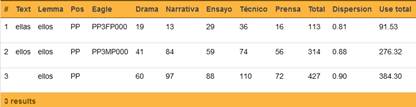
A su vez, los pronombres personales que se encuentran en casos distintos se contabilizan por separado (véase Figuras 9 y 10). Inicialmente, este era uno de los aspectos que nos interesaba enmendar, subordinado al desarrollo de una solución por parte de LexBas. No obstante, pese a que lematizar todos los casos de un pronombre bajo un mismo vocablo facilitaría la comparación con otros estudios, como el de Morales (1986), nos parece también de interés facilitar la revisión de las frecuencias de los pronombres correspondientes a los distintos casos por separado. Más aún, desde un punto de vista lexicográfico, estimamos que el abordaje de un diccionario estadístico como el de Castillo Fadić (2020a), de por sí complejo, puede dificultarse en demasía si se exige al usuario discriminación de casos gramaticales para las búsquedas y no solo conocimiento del orden alfabético.


2.4.2.2.1. El caso de tú /vos / usted
Puesto que en español de Chile estos tres pronombres personales coexisten, los hemos registrado separadamente, con indicación de sus respectivos índices de frecuencia, dispersión y uso. Todos ellos se agrupan bajo el lema <tú>. Como se aprecia en la Figura 11, en la columna correspondiente a la etiqueta EAGLES, tanto <vos> como <usted> incluyen al final de la etiqueta la letra <P>, correspondiente al valor “Polite”, que marca la existencia de una deferencialidad marcada, ya sea en sentido positivo <usted> como negativo <vos>.
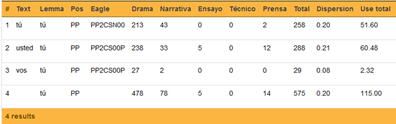
2.4.2.2.2. El caso de ustedes /vosotros
Como hemos indicado, a diferencia de Morales (1986), los pronombres personales de personas plurales se listan separadamente de los singulares. Por lo mismo, <vosotros> y <ustedes> no se lematizan bajo <tú>, como en Morales (1986), sino bajo <vosotros>9, como se observa en la Figura 12.
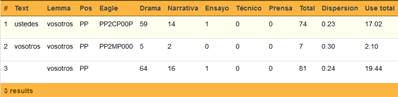
En atención a la pérdida en Latinoamérica de la oposición +/- deferencial de <vosotros> y <ustedes>, y al uso generalizado de <ustedes>, nos parece preferible lematizar bajo esta última forma y no bajo <vosotros>, como hace automáticamente LexBas 1.0, basándose en FreeLing 2.2. No obstante, hemos preferido, en esta etapa de análisis, no modificar manualmente esta lematización, en espera de que la siguiente versión de nuestro programa de análisis acoja este rasgo dialectal. Cabe precisar que en Castillo Fadić (2020a) esto ya se encuentra corregido.
2.4.3. Dificultades adicionales de análisis automático de corpus chilenos
Hemos detectado ciertas dificultades especiales en el procesamiento automático de nuestro corpus, no contempladas por los lematizadores centrados en el español estándar, preferentemente peninsular. Al respecto, destacamos: tratamiento de formas verbales, aspiración de /-s/ e inestabilidad vocálica y consonántica. A continuación, damos cuenta de cada una de estas problemáticas y del modo en que las hemos abordado.
2.4.3.1.1. Conjugaciones verbales de segunda y tercera persona
Como bien indica (Morales 1986: 24), Juilland y Chang-Rodríguez (1964) “no distinguen entre las formas verbales de tercera persona y segunda con usted, y teniendo en cuenta la importancia de esta distinción en la norma hispanoamericana, en el recuento de Puerto Rico se hizo el desglose de estas formas” Puesto que esta solución nos parece adecuada para reflejar más fielmente la realidad lingüística, hemos decidido, como Morales, distinguir entre estas formas verbales.
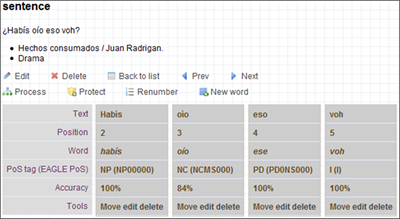
No obstante, el procesamiento de las formas conjugadas de los verbos presentó ciertas dificultades, originadas por el hecho de que FreeLing 2.2 está enfocado a la norma peninsular. Por lo mismo, no siempre discrimina adecuadamente las conjugaciones verbales de tercera y segunda persona, cuando la segunda persona está representada por <usted> o <ustedes>. En los casos en que el sincretismo alcanza también a la primera persona, la fiabilidad del análisis baja drásticamente y ni siquiera la presencia expresa del sujeto permite una desambiguación automática totalmente fiable. Por ello, LexBas 1.0 incorpora un índice de fiabilidad del análisis (Freeling accuracy); mientras más alejado esté del 100% (1), más evidente es la necesidad de revisión manual. En el caso de <reía> (véase Figura 13), por ejemplo, la etiqueta indica que se trata de un verbo principal, modo indicativo, imperfecto, primera persona de singular; la razón de que el índice de fiabilidad esté solo en el 50% (0.50) radica en que los verbos conjugados en este modo, tiempo y persona presentan sincretismo con segunda y tercera persona de singular.

Este índice de fiabilidad no solo aparece junto a cada palabra analizada, sino que constituye también un parámetro de búsqueda de unidades dentro de todo el corpus. Así, por ejemplo, es posible buscar todas las palabras cuyo análisis tenga una fiabilidad igual o menor a un número determinado; en el ejemplo de la Figura 14, hemos ingresado 0.5 en la casilla Freeling accuracy, lo que indica que se mostrarán los casos cuya desambiguación tenga una fiabilidad igual o menor al 50%.
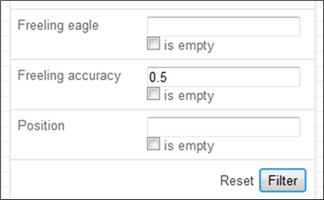
Este filtro puede combinarse con otros, como el lema, la categoría gramatical, la etiqueta EAGLES, etc.
Además, para fortalecer la desambiguación de casos como estos, procuramos identificar los modos, tiempos y personas que pueden requerir revisión manual, por tender a presentar sincretismos. Esto nos permitió concentrar la revisión manual en los verbos conjugados más susceptibles a la homonimia. En la Tabla 1, las etiquetas EAGLES de la última columna permiten discernir de manera inequívoca si un verbo conjugado del corpus corresponde a uno u otro tiempo, a una u otra persona, o incluso, a uno u otro modo.
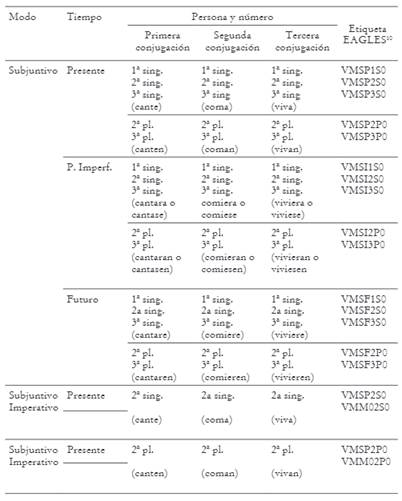
2.4.3.1.2. Formas voseantes
En julio de 2011, apreciamos que el voseo morfológico chileno, el cual se expresa en las desinencias verbales de un modo único en Hispanoamérica, especialmente en la primera conjugación (véase Rona 1962), no era reconocido por el lematizador. Planteado el problema a nuestro informático, quien lo trasladó a los creadores de FreeLing, advertimos que esto no tenía una solución contemplada en la versión 3.0 del mencionado programa -en preparación entonces-, por lo que actualizar LexBas a partir de la versión por salir no era una alternativa; la única solución era, entonces, que nosotros proporcionáramos un listado de verbos frecuentes en conjugación voseante, etiquetados en EAGLES según un patrón establecido. Para conocer cómo se realiza esta etiquetación, puede observarse el ejemplo del verbo conjugado hablaste, que se etiqueta como sigue: <hablaste hablar VMIS2S0>, donde <hablaste> es la forma conjugada que se analiza, <hablar> es el infinitivo que debe funcionar como lema y <VMIS2S0> señala que se trata de un verbo principal <VM>, en modo indicativo <I>, tiempo pasado <S>, segunda persona <2>, singular <S>10.
Por esta razón, creamos un diccionario de conjugaciones voseantes, etiquetado, que permitió procesar automáticamente y de manera exitosa el voseo verbal chileno. Cabe precisar que el voseo chileno puede aparecer en todos los tiempos verbales y tanto en modo indicativo como subjuntivo, excepto en futuro simple y pretérito perfecto simple del modo indicativo y en modo imperativo11, como ejemplificamos en la Tabla 2. Se usa en todos los niveles sociales, en estilo coloquial, y puede combinarse con el pronombre <tú> (no marcado), o con <vos> (marcado pragmáticamente)12.
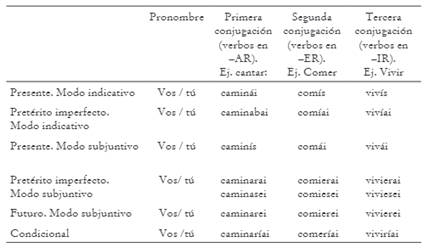
Como es lógico, y puesto que el voseo morfológico es exclusivo de situaciones informales, si bien existe la posibilidad de que aparezca en la opción b) del imperfecto subjuntivo (véase Castillo Fadić y Sologuren Insúa 2018) y en futuro subjuntivo -en cuyo caso se conjugarían como se indica-, su frecuencia ha de ser bajísima, justamente porque estas dos conjugaciones se estiman en Chile como propias de intercambios formales e incluso, en el caso del futuro, de comunicaciones legales. Por lo mismo, en los listados que preparamos para alimentar el diccionario del lematizador, solo incluimos los siguientes tiempos y etiquetas consignados en la Tabla 3.
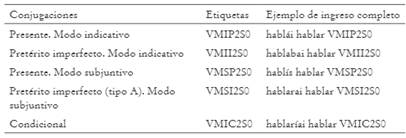
2.4.3.2. Aspiración de /-s/
La aspiración de /-s/, rasgo característico del español de Chile, conlleva un serio problema para el análisis automático. Aunque solo está presente gráficamente en Drama y Narrativa, toda vez que los autores intentan reproducir en la escritura el lenguaje oral, su presencia constituye una severa traba para el lematizador, dada la enorme asistematicidad de su presentación gráfica y la ausencia de una regla fija que pueda orientar al programa.
Así, en algunos casos la aspiración de /-s/ es representada por el autor mediante una <-h> (véase Figura 15).
En otros, mediante <> (véase Figura 16).

En ambos casos, como se observa, la versión inicial de LexBas 1.0 realiza análisis incorrectos. Al buscar alguna regla que pudiera guiar al lematizador, se revisó la posibilidad de programar al software para que reconociera como <s> las <h> que no antecedían a una vocal, por el hecho de que la distribución de <h> la sitúa, en español, en posición prenuclear y no postnuclear; no obstante, el hecho de que interjecciones como <oh>, <ah> o <eh>, de frecuencia no despreciable en el corpus, contuvieran este grafema en posición final, nos llevó a descartar esta posibilidad. La revisión de estos casos debió hacerse manualmente.
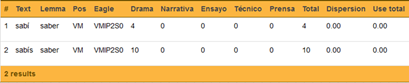
En el caso de las conjugaciones voseantes con aspiración, el ingreso de las variantes aspiradas al diccionario de conjugaciones verbales permitió solucionar errores, como se aprecia en el análisis mejorado de la palabra <sabí>, reconocida junto a <sabís> como variantes del indicativo, presente, segunda persona singular del verbo <saber>, por lo que comparten la misma etiqueta EAGLES (véase Figura 17).
2.4.3.3. Inestabilidad vocálica y consonántica
La inestabilidad, tanto vocálica como consonántica, que caracteriza al español de Chile, especialmente popular, y que se expresa preferentemente en situaciones coloquiales, es también una traba para el análisis automático, cuando los autores intentan reflejar la realidad hablada. En el caso de <dispertaste>, por ejemplo (véase Figura 18), aunque el programa logra determinar que se trata de un verbo conjugado, basado en reglas de combinatoria, no posee las herramientas para vincularlo con el verbo <despertar>, lo que redunda en una lematización inadecuada. La bajísima frecuencia de esta unidad, amén de su baja dispersión, la dejan en un margen irrelevante, desde el punto de vista estadístico, como suele ocurrir con estas formas populares que, por no estar estandarizadas, presentan una enorme asistematicidad.

Puesto que el lematizador opera a partir de combinaciones sintácticas, la dificultad para procesar una de las unidades de una oración puede repercutir en el análisis incorrecto de toda la estructura, como se observa en la Figura 19.
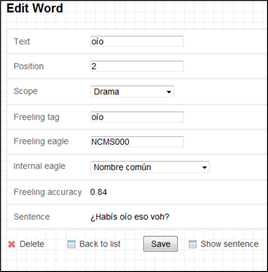
Para resolver estos casos, trabajamos con herramientas de edición al interior del mismo programa de análisis (véase Figura 20); al seleccionar la opción Edit, se abre una ventana que permite realizar cambios manuales; para ello, es preciso revisar todos los campos asociados a cada unidad léxica, sin limitarse exclusivamente a indicar el lema correcto en la casilla Freeling tag; en Internal eagle se despliegan las distintas categorías gramaticales que considera el programa, pero esta sola categoría es insuficiente para el análisis, pues solo Freeling Eagle permite precisar género y número -en el caso de las formas nominales- y modo, tiempo, persona y número -en el caso de las formas verbales-.
III. Análisis del corpus
Una vez concluido el proceso de orden, segmentación, depuración y lematización del corpus, se realizó un análisis estadístico para obtener la frecuencia de las palabras y vocablos, su dispersión y su uso. Para ello, se contó con la ayuda de LexBas 1.0 y se usaron las fórmulas mejoradas de Morales (1986). Así, se contabilizaron las frecuencias absolutas de las unidades y se calculó su dispersión mediante la fórmula
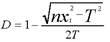
Para el cálculo del uso, se multiplicó la frecuencia por la dispersión: U = F x D.
Puesto que LexBas 1.0 solo permite hacer consultas predeterminadas y no soporta ciertos análisis, de manera complementaria recurrimos a Excel. Esto nos permitió no solo acceder al léxico básico del español de Chile -presentado en la forma de un diccionario no definitorio (Castillo Fadić 2020a)-, sino también obtener listados comparados de los vocablos de mayor uso y frecuencia, estableciendo cortes en los rangos 100, 500 y 1505, a fin de cotejar, además, con obras previas que realizan cortes en los mismos rangos.
Por otra parte, la posibilidad que ofrece LexBas 1.0 de aislar las unidades por categoría gramatical (véase Figura 21), nos brindó la opción de revisar separadamente unidades pertenecientes a distintas categorías, lo que permitió un análisis fino de casos particulares (véase Figura 22).
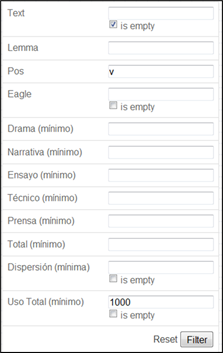
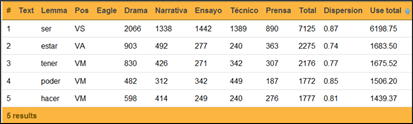
En otros casos, la posibilidad de buscar palabras -Text- a partir de un segmento permitía acceder a unidades que compartieran una misma base léxica o, al menos, una misma configuración grafemática, lo que facilitaba la revisión del procesamiento automático. En el caso de la Figura 23, la búsqueda de <pudr>, sin precisión del lema ni de la categoría gramatical, nos remite a un listado de tipos; para acceder a las oraciones en las que aparecen las palabras correspondientes, es preciso clickear en Show.
Mediante las mencionadas herramientas informáticas, dimos cuenta de las características del corpus, tanto en lo relativo al número de vocablos y palabras registrados en total y por mundo, como en lo referente a la proporción en la que se presentan las distintas categorías gramaticales, según se refleja en las etiquetas EAGLES correspondientes.
Aplicando índices complementarios de medición propuestos por López Morales (1984) y retomados por Haché de Yunén 1991, determinamos la riqueza léxica de nuestro corpus como indicador de su suficiencia13 y observamos la covariación de la riqueza respecto de la variable mundo.

Establecimos la representatividad acumulada (R) de nuestro corpus en general y de nuestro léxico básico en particular, mediante la fórmula 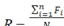 , que observa el cociente entre la sumatoria de las frecuencias totales de los vocablos contemplados dentro de un rango y el número total de vocablos contenidos en ese mismo rango (véase Castillo Fadić 2012b y Castillo Fadić y Sologuren Insúa 2020). En la fórmula, n representa el número de rango del vocablo de mínimo uso o frecuencia dentro del rango (la unidad ubicada en el rango de corte), mientras que N corresponde al número total de palabras consideradas en la muestra, vale decir, desde el rango uno (1) al de corte. La representatividad del corpus se calculó a partir de las frecuencias totales de los vocablos ordenados por uso de mayor a menor.
, que observa el cociente entre la sumatoria de las frecuencias totales de los vocablos contemplados dentro de un rango y el número total de vocablos contenidos en ese mismo rango (véase Castillo Fadić 2012b y Castillo Fadić y Sologuren Insúa 2020). En la fórmula, n representa el número de rango del vocablo de mínimo uso o frecuencia dentro del rango (la unidad ubicada en el rango de corte), mientras que N corresponde al número total de palabras consideradas en la muestra, vale decir, desde el rango uno (1) al de corte. La representatividad del corpus se calculó a partir de las frecuencias totales de los vocablos ordenados por uso de mayor a menor.
Se consideró de interés, además, determinar la curva de cobertura por mundo, para lo cual la fórmula se aplicó considerando cada mundo como una base independiente, donde, por no ser pertinente el índice de dispersión, las unidades se ordenaron por frecuencia total de modo decreciente.
Precisamos también qué unidades de alta frecuencia tienen baja dispersión y a la inversa, y cotejamos los resultados obtenidos en los distintos mundos desde diferentes enfoques, observando la covariación de diferentes variables en un estudio de implicancias sociolingüísticas. En esta línea, revisamos las unidades con dispersión máxima que no presentan necesariamente una alta frecuencia, sino que se caracterizan por el equilibrio de frecuencia entre los mundos; dimos cuenta también de las unidades con dispersión mínima y generamos listados de vocablos de alta frecuencia, pero con dispersión cero, organizados por mundos. Al respecto, levantamos gráficos para comparar la representación de las distintas clases gramaticales en cada mundo, observando diferencias de frecuencia y de inventario.
Nos pareció también de interés evaluar posibles afinidades entre mundos, para lo cual aislamos los vocablos que aparecen en solo dos de ellos, con independencia de sus índices de frecuencia, dispersión y uso, lo que nos permitió apreciar tendencias marcadas de afinidad entre unos y otros mundos y graficar dicha afinidad en general y por mundo.
Por último, aplicamos criterios de selección complementarios al índice de uso para determinar, dentro de las unidades de mayor uso, las que forman parte del núcleo estadístico de mayor estabilidad dentro del español de Chile, denominado léxico básico, y organizamos los resultados en un diccionario de frecuencia no definitorio (véase Castillo Fadić 2020a).
IV. Conclusiones
Los métodos empleados para procesar y analizar el corpus han resultado provechosos. Nos han permitido configurar un corpus de referencia etiquetado y estratificado del español de Chile, a partir del cual hemos podido no solo obtener el léxico básico del español de Chile (Castillo Fadić 2020a), sino también realizar una serie de investigaciones de implicancias sociolingüísticas (véase, por ejemplo, Castillo Fadić 2015by 2019; y Castillo Fadić y Sologuren Insúa 2017 y 2018).
Esperamos que los lineamientos para ordenar los materiales y los criterios propuestos para segmentar, excluir y lematizar unidades léxicas puedan ser de utilidad para quienes requieran procesar corpus lingüísticos hispánicos. Muy especialmente, esperamos que nuestras propuestas ofrezcan alguna orientación a quienes decidan emprender el procesamiento automático de corpus de español no castellano hispanoamericano, andaluz, canario, africano, etc., que probablemente se encuentren, como nosotros, ante soluciones pensadas para otras lenguas o para otras variedades de español.
En lo relativo al análisis estadístico, los cálculos de frecuencia, dispersión y uso permitieron obtener el Léxico Básico del Español de Chile (Castillo Fadić 2020a). Los cálculos adicionales de riqueza léxica, representatividad y curvas de cobertura por mundo, entre otros, pueden prestar utilidad en el ámbito educativo (véase, por ejemplo, Castillo Fadić y Sologuren Insúa 2020) y, particularmente, en la planificación de la enseñanza del español como lengua materna y como segunda lengua, donde pueden complementarse con otros métodos centrados en la selección (Santos Díaz 2017) y enseñanza del léxico (Santos Díaz, Trigo Ibáñez y Romero Oliva 2020a, 2020b).
Particularmente, en lo que atañe a los repertorios de léxico básico, esta línea de investigación es tan relevante como poco abordada, por lo que invitamos a los lingüistas interesados en lingüística de corpus a emprender trabajos en esta línea, dentro de sus respectivas comunidades.

