











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
1. INTRODUCCIÓN
El presente artículo se enmarca en el estudio de la variación del español de Colombia con base en el análisis dialectométrico de datos léxicos del Atlas Lingüístico-Etnográfico de Colombia (ALEC) recolectados entre 1956 y 1978 por el Departamento de Dialectología del Instituto Caro y Cuervo. A la fecha, en Colombia se han realizado tres propuestas de división dialectal desde el análisis de los datos del ALEC (Flórez 1961; Montes Giraldo 1995; Mora, Lozano, Ramírez, Espejo y Duarte 2004), las cuales tienen en común que parten de la identificación, por parte de los autores, de rasgos formales, generalmente fonéticos, desde los que se han trazado de forma manual las agrupaciones o isoglosas en superdialectos, dialectos y subdialectos. En el mismo orden, las isoglosas planteadas hasta el momento se constituyen como límites cerrados donde inicia y/o termina una variedad del español del país. Si bien dichas propuestas están debidamente argumentadas, los avances de los últimos años en el análisis estadístico de datos lingüísticos y la medición automática de diferencias lingüísticas mediante técnicas dialectométricas permiten, desde un enfoque alternativo que brinda un reanálisis instrumental con representaciones más graduales de los registros consignados, agregar una mayor cantidad de datos y proporcionar resultados de similitud o diferencia lingüística con un mayor grado de precisión.
De acuerdo con lo anterior, el presente trabajo tiene dos objetivos: en primer lugar, proponer una división dialectal del español de Colombia desde el análisis dialectométrico de datos estrictamente léxicos; y, en segundo lugar, revisar y comparar las propuestas de clasificación dialectal del español de Colombia realizadas con base en datos del ALEC con los resultados del análisis estadístico y sus visualizaciones. Los resultados obtenidos son relevantes para los estudios del español de Colombia en la medida en que ponen en discusión las metodologías tradicionales para el establecimiento de isoglosas y permiten detectar, y establecer los límites y transiciones dialectales del país en el nivel léxico.
2. METODOLOGÍA
Aunque el estudio de los dialectos ha sido una preocupación constante de la lingüística desde sus inicios, la dialectometría como disciplina separada surge con el advenimiento de la informática y la capacidad de procesar grandes volúmenes de datos. La dialectometría es una disciplina que se sitúa en la intersección de la lingüística y la estadística. Esta área de estudio se centra en cuantificar y analizar las diferencias entre los dialectos de una lengua, utilizando métodos cuantitativos para clasificar y agrupar las variantes dialectales basándose en su similitud (Goebl 1984).
En el contexto hispanoamericano, el primer estadístico sobre datos geolocalizados fue llevado a cabo por Alvar (1955), quien realizó un estudio cuantitativo de la frontera entre Aragón y Cataluña utilizando el Atlas lingüístic de Catalunya (ALC). Posteriormente, Séguy (1973) acuñó el término “dialectométrie”, promoviendo el uso de métodos cuantitativos en dialectología. Usando el mismo enfoque, Moreno Fernández (1991) analizó la morfología verbal con materiales del Atlas lingüístico y etnográfico de Aragón, Navarra y la Rioja (ALEANR). Otros estudios notables incluyen el de Ueda (1993), que empleó el Atlas lingüístico y etnográfico de Andalucía (ALEA) para analizar la gradación dialectal en Andalucía, y el de Moreno Fernández (1997) que, con datos del ALeCMan, estableció cuantitativamente la frontera entre Cuenca y Toledo. Además, Aliaga Jiménez (2003) usó el método de Goebl para estudiar el léxico de Teruel. Más recientemente, Goebl (2011, 2013) y Peña Arce (2018) han aplicado la dialectometría a los datos del Atlas lingüístico de la Península Ibérica (ALPI) y el Atlas lingüístico y etnográfico de Cantabria (ALECant), respectivamente. En América, destaca el trabajo de Paredes García (2002) sobre el léxico de Venezuela, y el de Ávila, Mendieta, Álvarez, Rodríguez y Silva (2015) en Colombia con el ALEC.
2.1. Informatización y análisis dialectométrico de los datos léxicos del ALEC
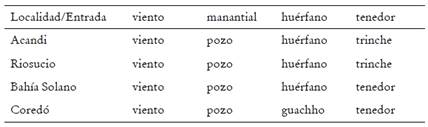
El software seleccionado para el procesamiento dialectométrico de los datos léxicos del ALEC fue Gabmap1 (Nerbonne, Colen, Gooskens, Kleiweg y Leinonen 2011). La información, en formato digital, fue obtenida de la base de datos espacial del ALEC (Bonilla y Bernal Chávez 2020), elaborada por la línea de investigación en Lingüística de Corpus del Instituto Caro y Cuervo. Para el análisis en Gabmap fue necesario transcribir la información en una hoja de cálculo (Tabla 1). En la primera columna, se encuentran los nombres de las 237 localidades cartografiadas; y, en las siguientes, cada una de las primeras variantes por entrada en cada localidad. Por cuestiones de visualización, no se incluyeron las variantes de Leticia, ya que en el mapa ocuparía toda la región no explorada durante la investigación.
La información fue cargada en Gabmap junto a un polígono del ALEC (archivo .kml) con los puntos de las 237 localidades cartografiadas para su georreferenciación en el aplicativo (Figura 1). En resumen, el análisis fue realizado con 43858 variantes léxicas de 237 localidades del país pertenecientes a 200 mapas del ALEC.
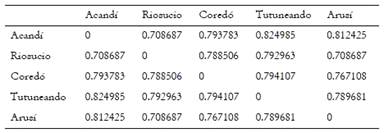
El cálculo de las diferencias lingüísticas se realizó mediante el Índice Relativo de Identidad (IRI). Este es un valor de similitud ponderado en frecuencia que fue introducido en la dialectometría por Goebl (1984). El IRI considera que las distancias o diferencias contienen menos valor, mientras que la cercanía y las semejanzas permiten establecer redes comunicativas entre distintos puntos. Es decir, este índice resalta aquello que dos puntos tienen en común. La distancia lingüística se obtiene dividiendo el número de co-identidades por el de co-ocurrencias y multiplicando por cien el resultado. El número de co-ocurrencias equivale al número de mapas del corpus descontando los casos en que no exista respuesta en una localidad o en ninguna de las dos comparadas. Además, de producirse esta última circunstancia, no se computa ni una semejanza ni una diferencia, de modo que, en la práctica, se utiliza un mapa menos (Aliaga Jiménez 2003). El IRI considera la frecuencia de las variantes léxicas en la comparación, variantes con baja frecuencia tienen más peso que aquellas de alta frecuencia. Como resultado la distancia obtenida varía entre 0 y 1. La Tabla 2 presenta, a modo de ejemplo, un extracto de la matriz de distancia lingüística entre localidades del ALEC obtenida en Gabmap con el método IRI.
2.2. Métodos de agrupamiento y visualización
Gabmap ofrece diversos algoritmos para el análisis de agrupamiento de la matriz de diferencias lingüísticas. La agrupación de datos es una técnica común para análisis estadístico de datos y consiste en la identificación de agrupaciones naturales o agrupaciones dentro de datos multidimensionales basados en alguna medida de similitud (Omran, Engelbrecht y Salman 2007). Para dicha tarea, Gabmap propone cuatro algoritmos de agrupamiento jerárquicos que son Complete link, Weighted Average, Group Average y Ward’s Method. Estos algoritmos determinan de diferente manera cómo se calculan las distancias entre los clústeres que se van formando en el proceso de agrupamiento, lo que implica que cada método tenga un sesgo diferente. Por ejemplo, el método de Ward, uno de los algoritmos más apropiados para este tipo de análisis, favorece los grupos de igual tamaño, mientras que los demás son más fieles a las distancias lingüísticas originales (Kleiweg 2006).
De acuerdo con Leinonen (s/f), el análisis de agrupamiento mediante los algoritmos jerárquicos es un método poco estable, ya que pequeños cambios en la matriz de diferencia lingüística pueden generar variaciones en los resultados de visualización. Uno de los algoritmos desarrollados para solucionar este problema y el seleccionado para nuestro análisis final es el agrupamiento difuso (fuzzy clustering), que consiste en la “contaminación” de la matriz de distancias original con pequeñas cantidades de ruido aleatorio (ver Pröll 2013, Nerbonne y Kretzschmar 2013). El mapa resultante visualiza algo entre escalamiento multidimensional y el análisis de agrupamiento: los grupos de dialectos principales se identifican en el mapa, pero se muestran relaciones continuas para los lugares que no se pueden colocar en un grupo con alta probabilidad. El mapa se crea ejecutando escalamiento multidimensional en las longitudes de rama del dendrograma (las llamadas distancias de copenética) en lugar de hacerlo sobre las distancias lingüísticas originales (Nerbonne, Kleiweg, Heeringa y Manni 2008).
3. RESULTADOS
3.1. Matriz de diferencias lingüísticas
La consistencia de los datos de la matriz de diferencias lingüísticas es alta de acuerdo con el coeficiente alfa de Cronbach2 (α = 0.81). Heeringa (2004) explica que en dialectometría se prefiere un grado relativamente alto de consistencia interna, ya que demuestra que el conjunto de variables lingüísticas sigue un patrón similar.
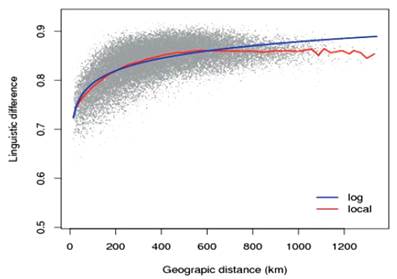
En el mismo orden, la correlación entre distancia geográfica y distancia lingüística en Colombia se ajusta al postulado dialectológico de Nerbonne y Kleiweg (2007), quienes afirman que las variedades cercanas geográficamente tienden a ser más similares que las distantes. Dicha correlación puede ser observada en la Figura 2, donde se muestra una distribución logarítmica bastante clara de las relaciones distancia lingüística / distancia geográfica, tanto en su versión de dispersión (puntos en gris) como en las versiones linealizadas locales (en rojo) y logarítmica (en azul). Se puede apreciar que las distancias lingüísticas empiezan a volverse constantes luego de los 600 km aproximadamente. Lo anterior indica que las características lingüísticas analizadas están correctamente seleccionadas para dar una idea de la distribución de las variedades lingüísticas del territorio colombiano, asumiendo que el postulado dialectológico se cumple.
3.2. Agrupamiento difuso
El mapa resultado del agrupamiento difuso muestra ocho grandes grupos (Figura 3) que son el máximo de distribuciones producidas por el algoritmo, es decir, sin importar que se seleccionen mapas de 2, 4, 5 o 7 distribuciones, los ocho grupos mantendrán sus límites en la redistribución.
La primera agrupación se identifica al norte del país y está conformada por los departamentos de la Guajira, Bolívar, Sucre, Córdoba, Cesar, Magdalena y Atlántico. Esta zona tiene continuidad hacia los límites de las localidades antioqueñas de Turbo y Chigorodó y Acandí y Riosucio en el Chocó. Ahora bien, se identifica una zona transicional hacia la región de los Santanderes, específicamente desde Simití en el Bolívar, Gamarra, Pailitas y Loma de Corredor en el Cesar hasta Bocas del Rosario, Puerto Wilches y Barrancabermeja en Santander.
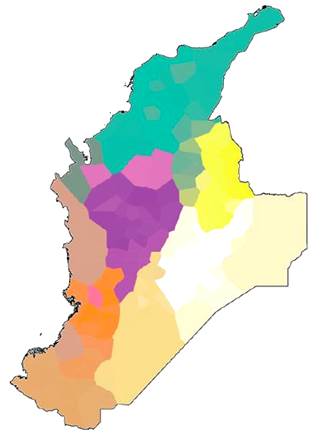
Figura 3 Mapa obtenido mediante agrupamiento difuso de la matriz de distancias lingüísticas (ALEC, 200 mapas léxicos, IRI)
La segunda agrupación está conformada por localidades de Norte de Santander y Santander. La tercera compuesta por Cundinamarca y Boyacá con continuidad hacia la cuarta zona compuesta por los Llanos orientales donde los colores se hacen más oscuros al haber mayor diferencia lingüística. La quinta zona es lo que hemos denominado a lo largo del texto como el Tolima Grande (Tolima, Huila y Caquetá). La sexta zona conformada por Nariño y Putumayo. La séptima zona desde el bajo Cauca hasta el Valle del Cauca y límites con el eje cafetero. Por último, la octava zona agrupa la zona costera del Cauca y parte del Chocó.
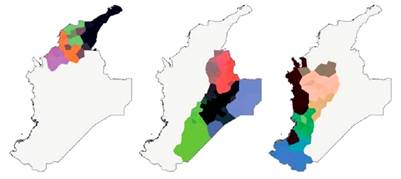
Figura 4 Tres divisiones mediante agrupamiento difuso de la matriz de distancias lingüísticas (ALEC, 200 mapas léxicos, IRI)
En la Figura 4 observamos la redistribución de la matriz de diferencia lingüística mediante agrupamiento difuso en tres grupos. Primero, observamos que se mantiene el Caribe norte y aparecen subdivididas cada una de las isoglosas dentro de la zona a niveles que concuerdan con transiciones departamentales: Guajira-Cesar, Atlántico-Magdalena, Bolívar-Sucre y Córdoba.
En segunda medida, el centro-occidente y centro-oriente del país se dividen en dos. La zona centro-oriente agrupando las hablas de los Santanderes, Llanos Orientales, la zona Cundiboyacense y el Tolima Grande. La zona centro-occidente reuniendo la zona del Darién, el continuo Antioquia-Eje Cafetero, Chocó y costas del Cauca, Cauca, Valle del Cauca y Nariño-Putumayo. Gracias a la redistribución también se observan subdivisiones al interior de zonas identificadas como el norte de Antioquia y el Eje Cafetero, mayor contraste entre la zona interior del Cauca con el Valle del Cauca y se observa de mejor manera la distribución de los Llanos Orientales, compuestos por Arauca, Casanare y Meta, pero con un remanente de las hablas cundiboyacenses en el medio.
Las tres zonas y sus transiciones se pueden observar también al realizar el escalamiento multidimensional de la información (Figura 5). En la parte superior se encuentran las localidades del norte del país con dos transiciones, una hacia el oriente que pasa por Santander hacia el centro-oriente, y otra al occidente por el Chocó y noroccidente antioqueño hacia el centro-occidente. El escalamiento multidimensional en el plano horizontal deja ver también la transición que hay desde el suroccidente del país hacia el centro pasando por el Tolima Grande (Popayán, Neiva, San Agustín). Se observa mayor distinción del Cauca y Valle del Cauca, el primero cercano a la zona central y el segundo más hacia las hablas antioqueñas, es decir, tendiendo al occidente en vez del centro. Las hablas del continuo Antioquía - Eje Cafetero se encuentran en el extremo opuesto de los Santanderes.
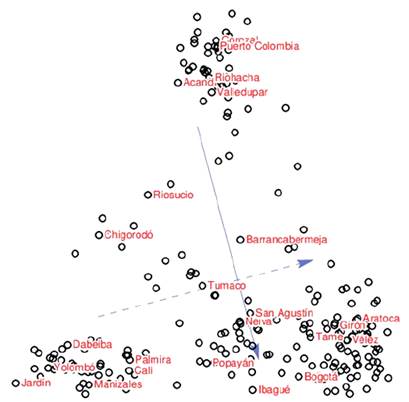
Figura 5 Gráfico de escalamiento multidimensional de la matriz de distancia lingüística (ALEC, 200 mapas léxicos, IRI)
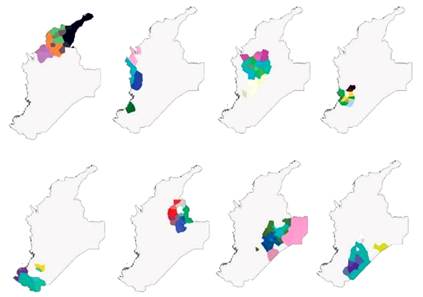
Ahora bien, al escalar a ocho divisiones (Figura 6), máximo de distribuciones observadas en la Figura 3, el Caribe norte colombiano y sus subdivisiones se mantienen. En cambio, las divisiones centro-oriente y centro-occidente marcan distintos relieves de la matriz de diferencias lingüísticas al dividirse en cuatro o tres zonas cada uno. Por la parte centro-occidente se agrupa la zona del Darién con el Chocó y las costas del Cauca. En este nivel son claras las diferencias en mayor detalle. Se contrastan la zona del Darién, la zona costera, el interior del Chocó y la costa del Cauca.
4. DISCUSIÓN
La variación lingüística que se observa en esta propuesta de clasificación dialectal del español de Colombia desde el nivel léxico (Tabla 3) puede ser argumentada desde diversos factores como la diversidad geográfica, hechos históricos, composición poblacional, patrones de movilidad, migraciones de la época, etc. Si bien tal argumentación merece un tratado completo, que esperamos que el presente trabajo suscite, de manera muy resumida explicaremos las posibles causas que producen los relieves dialectales observados en diálogo con las propuestas de clasificación anteriores a la nuestra. Hemos optado por apropiar la división en superdialectos, dialectos y subdialectos propuesta por Montes Giraldo (1995), teniendo en cuenta que la distribución de los resultados en sus posibilidades de agrupación presenta extensiones de gran tamaño que guardan correspondencia jerárquica con otras de menor nivel (regionales o departamentales). La diferencia con Montes Giraldo radica en que nuestros resultados no implican que las variedades propuestas compartan rasgos o normas pertenecientes a más de un nivel de la lengua, sino que se limitan a la dimensión léxica.
4.1. Superdialectos
La bipartición del español de Colombia propuesta por Montes Giraldo (1982) es un hecho sustentado principalmente en la presencia o ausencia de rasgos fonéticos que llevan a dividir el español de Colombia en andino y costeño, dicha bipartición no puede ser discutida desde nuestro nivel de análisis teniendo en cuenta que nos basamos únicamente en datos léxicos. Desde el análisis en el nivel léxico, Mora y otros (2004) afirman que sus resultados coinciden y por lo tanto la bipartición es correcta. Ávila y otros (2015) sostienen que la bipartición es válida, pero al observar el comportamiento de los datos léxicos retraen la isoglosa del superdialecto costeño únicamente a la zona Caribe y explican que la zona Pacífico se vincula a las hablas andinas antes que a las costeras. Nuestros resultados difieren partiendo de que no es nuestra tarea refutar o validar la isoglosa que sustenta la bipartición, sino actualizar las agrupaciones dialectales en el nivel léxico a la luz de los resultados encontrados. Al observar los resultados del agrupamiento de la matriz de diferencias lingüísticas y su escalamiento multidimensional (Figuras 4 y 5), observamos tres agrupaciones constantes que por su extensión pueden ser consideradas superdialectos. Al primer superdialecto, que agrupa los departamentos del norte del país, lo hemos denominado superdialecto costeño, y recoge a su vez la zona transicional del Pacífico hacia las hablas centro-occidentales y la zona santandereana costeña hacia las hablas centro-orientales. El segundo, superdialecto andino centro-occidental, se extiende desde Nariño y Putumayo hacia el norte, pasando por los departamentos de Cauca, Valle del Cauca, Chocó, Risaralda, Caldas, Quindío y Antioquia. El tercero, denominado superdialecto andino centro-oriental, está compuesto por Santander, Norte de Santander, Boyacá, Cundinamarca, Tolima, Huila, Caquetá, Arauca y Meta.
En general, los resultados concuerdan en marcar una línea divisoria entre las hablas del centro-occidente y las del centro-oriente, razón por la que se proponen los dos superdialectos andinos. Tal distribución es compatible con las proyecciones viales trazadas por el gobierno colombiano en la Ley 12 de 1949 con las que se buscaba construir carreteras modernas sobre los caminos que tradicionalmente comunicaban al país. Por una parte, se propuso una troncal occidental desde Tumaco a Cartagena, pasando por Pasto, Popayán, Cali, Manizales y Medellín; por otra parte, la troncal oriental desde Florencia, Caquetá pasando por Garzón, Neiva, Cabrera, Bogotá, Tunja, Barbosa, Bucaramanga, La Ceiba, Abrego, Ocaña, hasta llegar al departamento del Cesar.
De lo anterior es posible plantear, a modo de hipótesis, que las rutas históricas de tránsito en Colombia, que inician su modernización en 1949, corresponden con rutas de difusión lingüística que atraviesan el país verticalmente en dos troncales, una oriental y otra occidental. Sin embargo, es menester revisar también las vías transversales, por ejemplo, desde 1945 Cali tiene conexión terrestre hasta Buenaventura, lo que acerca la localidad a las hablas del centro-occidente del país. Esta hipótesis puede ser perfeccionada a futuro en un trabajo que revise, desde la llegada de los españoles, cómo se fueron construyendo los denominados caminos reales y su posterior desarrollo en vías nacionales y la manera en que esto motivó la difusión de variantes léxicas. Se ha comprobado la correlación entre las distintas vías de acceso (caminos de herradura, carreteras transitables, carreteras principales y vías férreas) y la variación lingüística media, utilizando datos del ALEC. Esto se ha hecho a través del Índice de Autocorrelación Espacial, descubriendo que esta variable extralingüística presenta la mayor dependencia espacial bivariante en relación con la distancia lingüística. Este hallazgo fue ratificado por el tratamiento de esta interacción en el marco del modelo geográfico mixto autorregresivo de regresión espacial, reafirmando la relación entre la variación lingüística y los fenómenos geográficos citados (Fernández, Bonilla y Rocha en prensa).
Si bien Montes Giraldo (1982) y Mora y otros (2004) distinguen a nivel dialectal el andino oriental y occidental, nuestra propuesta los eleva a nivel superdialectal, teniendo en cuenta cada una de las transiciones vistas de manera vertical, la distribución de la matriz de diferencias lingüísticas evidenciada en el escalamiento multidimensional y el gran tamaño de las isoglosas.
4.2 Dialectos y dialectos transicionales
En el nivel dialectal nuestra propuesta redistribuye cada uno de los dialectos de acuerdo con los relieves observados en los resultados. En la presente propuesta se presentan ocho dialectos en el nivel léxico, a diferencia de las propuestas de Montes Giraldo (1982) y Mora y otros (2004) que proponen cuatro y cinco dialectos respectivamente.
En primera medida, nuestros resultados no indican cercanía lingüística, a nivel léxico, del dialecto costeño Caribe con los departamentos de los Llanos Orientales, el Valle del Cauca y el Tolima como indican Mora y otros (2004) o los denominados costeñismos parciales que propone Montes Giraldo (1982). Lo que se observa, en el escalamiento multidimensional, es que la transición se da desde las hablas del Caribe hacia el oriente y centro del país, pero la diferencia lingüística es suficientemente alta para distinguirlos y nunca hay agrupación.
Desde el dialecto costeño Caribe, hacia la parte superior de la Tabla 3, encontramos los dialectos andino centro-oriental alto, medio y bajo. El andino centro-oriental alto se cruza con el costeño Caribe por la relación transicional con localidades del departamento de Santander que hacen parte de la cuenca del Magdalena.
Tabla 3 Propuesta de división dialectal del español de Colombia con base en análisis dialectométrico de 200 mapas léxicos del ALEC (Gabmap, método IRI, algoritmo de agrupación difusa, escalamiento multidimensional)
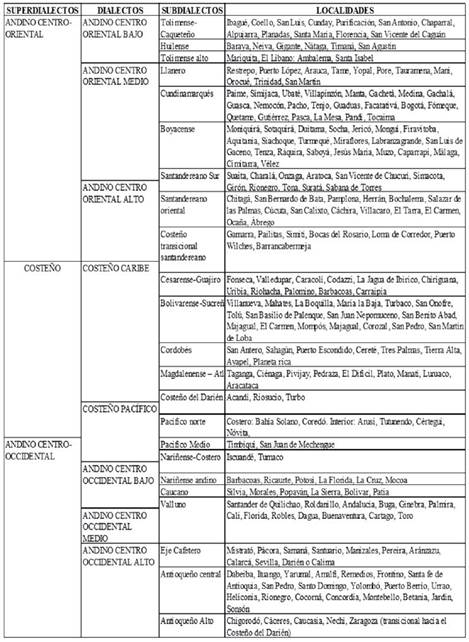
De allí que, entre los dos dialectos, costeño Caribe y andino centro-oriental alto, se proponga a nivel subdialectal el costeño transicional santandereano. El dialecto andino centro-oriental alto también agrupa las hablas de Santander y Norte de Santander y tiene su transición hacia los departamentos de Boyacá, Cundinamarca, Meta, Casanare y Arauca, a lo que hemos agrupado como dialecto andino centro-oriental medio. Por último, se propone el dialecto andino centro-oriental bajo, que reúne los departamentos del Gran Tolima, en sintonía con lo encontrado por Mora y otros (2004), quienes incluyen las localidades del Caquetá dentro de la zona tolimense-huilense.
Desde el costeño Caribe hacia la parte inferior de la Tabla 3, encontramos el dialecto costeño Pacífico como parte de los superdialectos costeño y andino centro-occidental, teniendo en cuenta la zona transicional de las localidades que se encuentran al occidente de Antioquia y limitan el tapón del Darién. El dialecto costeño Pacífico también incluye localidades del Chocó y las costas del Cauca y Nariño. Por tal razón, se propone como zona transicional con el andino centro-occidental bajo específicamente con el subdialecto nariñense costero. La discontinuidad areal puede deberse a que en principio era una zona continua que incluía el Valle del Cauca, pero por la migración del interior hacia Buenaventura se producen cambios que llevaron a la distinción y fraccionamiento del continuo dialectal. El andino centro-occidental bajo también incluye el interior de Nariño y Putumayo y se extiende hacia el norte a algunas localidades del Cauca.
El andino centro-occidental medio está conformado en su mayoría por el Valle del Cauca. Montes Giraldo (1982) afirma que son pocos los datos del ALEC que nos permiten trazar isoglosas definitorias de esta zona y que podría hablarse de una zona caucana con mitad del sur del Valle del Cauca y una zona caucana independiente; por su parte, Mora y otros (2004) optaron por la agrupación a nivel subdialectal caucano-valluno. En nuestros resultados, el relieve del Valle del Cauca se distingue en las visualizaciones y el escalamiento multidimensional deja ver cierta independencia de la región con transición hacia el sur del país. Por último, el dialecto andino centro-occidental alto está compuesto por los departamentos del Eje Cafetero y Antioquia; este relieve es constante en todas las visualizaciones y tiene transición hacia el dialecto costeño Caribe. Como se puede observar, las diferencias lingüísticas en el nivel léxico son suficientemente significativas para separar como dialectos las zonas que tradicionalmente habían sido agrupadas como dialecto andino occidental.
Ávila y otros (2015) proponen que, en vez de separar los dialectos andinos en oriental y occidental, como postulan Montes Giraldo (1982) y Mora y otros (2004), es “más prudente hablar de una porción norte (hablas antioqueño-caldenses y santandereanas) y una porción sur (hablas caucano-vallunas, andinas, tolimenses-huilenses, cundiboyacenses y llaneras)”. De acuerdo con la visualización del eje horizontal en el escalamiento multidimensional (Figura 5), esta propuesta no es viable porque los límites entre la zona antioqueña y santandereana se dan por la influencia del dialecto costeño Caribe y la diferencia lingüística a nivel léxico es tan alta que aparecen en lugares opuestos.
4.3. Subdialectos
A nivel subdialectal proponemos la subdivisión del dialecto costeño Caribe en agrupaciones departamentales (Cesar y Guajira, Bolívar y Sucre, Magdalena y Atlántico), con excepción de Córdoba, que muestra en los mapas mayor diferenciación del resto. Montes Giraldo (1982) y Mora y otros (2004) dividen el costeño Caribe a nivel departamental y las isoglosas subdialectales que proponen no dejan ver la transición o continuidad dialectal de las zonas.
Por su parte, el subdialecto costeño transicional santandereano demuestra que la línea occidental del departamento de Santander a lo largo del río Magdalena presenta rasgos léxicos característicos de habla de las zonas costeñas. Estas localidades han sido puertos importantes y mantienen su conexión fluvial con el norte del país, lo que justifica su relación con las hablas ribereñas del Caribe colombiano.
Ahora bien, hacia el pacífico proponemos el subdialecto costeño del Darién teniendo en cuenta que es una zona de encuentro de los dialectos costeño Caribe, costeño Pacífico y andino centro-occidental alto. Desde el siglo XVII esta región fue habitada por esclavos procedentes de África Central que eran administrados por zonas del distrito antioqueño (Colmenares 1984). German de Granda (1988) explica que la población esclava que trabajaba en las minas provenía de los bantú, chamba, mande y otros grupos del interior de África, lo que muestra una composición poblacional específica que desarrolla una variedad diferenciada del español por el contacto. Por otra parte, las localidades costeras del Pacífico alto (Acandí, Riosucio, Coredó, Bahía Solano y Arusí) no contaban en la época, ni actualmente, con acceso por vía terrestre al resto del país y únicamente se puede ingresar por vía aérea o marítima, lo que confirma una separación del resto de Colombia y, por lo tanto, mayor diferencia lingüística.
En la Tabla 3 observamos que varias localidades del norte del Valle del Cauca hacen parte del subdialecto del eje cafetero y no del valluno, esto se debe a que el norte del departamento se compuso a partir de la migración antioqueña de finales del siglo XIX y principios del XX. Tras la migración los antioqueños fundaron poblaciones en las áreas de ladera de las cordilleras, específicamente poblados como “Versalles (1887), Sevilla (1903), Caicedonia (1905), Darién (1913), Restrepo (1913) y Trujillo (1924)” (Ramírez 2011: 64). En contraparte, la zona sur y central del Valle del Cauca, que denominamos “valluna”, se ha consolidado en mayor parte por grupos de descendencia afroamericana y valluna raizal, lo que se evidencia en la distinción subdialectal.
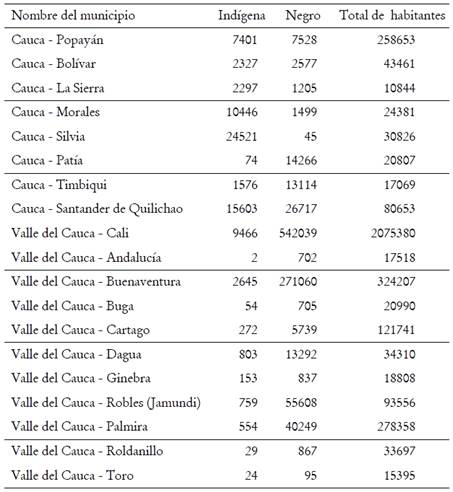
De manera similar, los subdialectos caucano y valluno se distinguen por factores de composición poblacional. Por una parte, mayor influencia indígena en el departamento del Cauca, teniendo en cuenta la presencia de resguardos y población indígena Yanacona, Misak, Páez, Totoró, Nasa, etc., y, en el caso del Valle del Cauca al sur de la zona de influencia antioqueña, preponderancia de población afrocolombiana. Saber exactamente los porcentajes de composición poblacional de la época es una tarea difícil. Al revisar los censos de población realizados durante la época de recolección de datos del ALEC, observamos que en el censo de 1964 en el Cauca se especifica que la población indígena fue contada dentro del general de habitantes (Departamento Administrativo Nacional de Estadística [DANE] 1964). En el censo de 1973 hay distinción étnica en el conteo, pero únicamente en las áreas “donde la población indígena era predominante”, para lo que “se utilizó un formulario especialmente diseñado para captar las características de los grupos indígenas existentes en el territorio” (DANE 1973: XVI). En el caso del Valle del Cauca, el censo de 1964 no menciona ni ofrece datos algunos sobre población indígena y en el de 1973 los campos “viviendas en áreas indígenas” y “población en áreas indígenas” aparecen vacíos (DANE 1973: 2-3).
Datos más recientes como los del censo de población de 2005 (Tabla 4) muestran que en las localidades encuestadas en el Cauca hay convivencia de población indígena y negra, con preponderancia indígena en Morales y Silvia. En el mismo orden se observa mayoría de población afrodescendiente en las localidades de Santander de Quilichao del Cauca y en Buenaventura, Dagua, Palmira y Roldanillo en el Valle del Cauca, lo que confirmaría la hipótesis de que la distinción subdialectal se debe a factores de composición poblacional. Patía llama la atención teniendo en cuenta que en el escalamiento multidimensional es cercana al subdialecto valluno a pesar de estar en zona indígena en límites con Nariño, esto se debe también a que dicha población es en mayoría afrodescendiente.
Por último, se comprueba la relación a nivel subdialectal entre Nariño y Putumayo en lo que hemos denominado nariñense andino. Arboleda (2000) explica que estos departamentos hacen parte de lo que se conoce como área andina del español, teniendo en cuenta la influencia de la lengua quechua y su adopción en la evangelización de los territorios del sur del país que limitan con Ecuador. En el mismo orden, Arboleda (2000) sostiene que esta relación andina se da por la relación política que durante la colonia tuvo Nariño con Quito y por el aislamiento de estos territorios con el centro de Colombia.
Tabla 4 Pertenencia étnica por municipio en localidades encuestadas de Cauca y Valle del Cauca (DANE 2005)
5. CONCLUSIONES
En vez de presentar una a una las variantes léxicas y mostrar su distribución espacial para el establecimiento de isoglosas, como hacen Mora y otros (2004), nuestra clasificación es realizada a partir de la visualización de los resultados de agrupación de una matriz de diferencias lingüísticas producida de manera automática por algoritmos estadísticos, obteniendo una mayor consistencia en los resultados para la selección e identificación de límites dialectales estrictamente en el nivel léxico y sin la sumatoria o acumulación de rasgos de diferentes niveles de la lengua. En este orden, no es posible mostrar las variantes específicas y su peso distributivo para la clasificación de un territorio, sino que nos basamos en el análisis de los relieves estadísticamente significativos que se marcan al momento de agrupar la matriz de diferencias lingüísticas mediante algoritmos de agrupación jerárquica y difusa.
En resumen, presentamos una propuesta de división dialectal del español de Colombia desde el nivel léxico (Figura 7), que divide el país en tres superdialectos, a saber, costeño, andino centro-oriental y andino centro-occidental. El superdialecto costeño se divide a su vez, al igual que en las propuestas de Montes Giraldo (1982) y Mora y otros (2004), en dos dialectos, Caribe y Pacífico, pero especificando la transición dialectal que hay hacia las hablas orientales y occidentales del país. Cada uno de los superdialectos andinos se ha dividido en alto, medio y bajo partiendo de la hipótesis de división territorial dada desde la conformación de las vías terrestres del país troncales oriental y occidental. Por último, con base en la redistribución de la matriz de diferencias lingüísticas obtenida mediante agrupamiento difuso, proponemos un total de veintitrés subdialectos y las transiciones dialectales que existen entre ellos
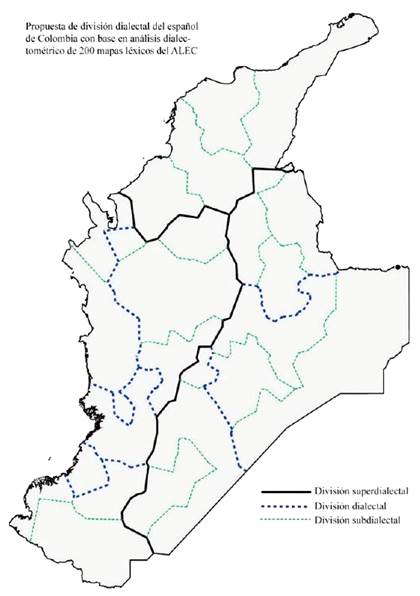
Figura 7 Propuesta de división dialectal del español de Colombia con base en el análisis dialectométrico de 200 mapas léxicos del ALEC
Cabe destacar que en nuestra propuesta hace falta la clasificación de las hablas correspondientes a más de la mitad de la Orinoquía, la Amazonía y la región Insular de Colombia. La dificultad para realizar dicha caracterización está dada por la falta de datos. De allí que sea menester el completar los trabajos del ALEC en dichas regiones y, a su vez, iniciar con la actualización de los datos en las regiones ya exploradas.

