











 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink
El conocimiento ortográfico de los sujetos permite el procesamiento automático de las palabras en la lectura y la escritura, procesamiento que constituye, a su vez, la base para la comprensión y la producción de textos de calidad. Por dicha razón, resulta de suma importancia el estudio del desarrollo del conocimiento ortográfico en niños que aprenden a leer y escribir en diferentes sistemas ortográficos (Ferroni, 2012).
En efecto, se ha señalado que los sistemas ortográficos se distribuyen en un continuo de opacidad-transparencia de acuerdo a la relación que poseen con el principio alfabético. En los sistemas ortográficamente transparentes, como el español, el italiano o el finés, la relación entre los sonidos del habla y su representación gráfica resulta considerablemente estable, mientras que en las ortografías más opacas como el inglés o el francés, las relaciones entre la fonología y la ortografía resultan muy irregulares (Defior, Jiménez-Fernández & Serrano, 2009; Diuk, Borzone, Sánchez Abchi & Ferroni, 2009).
Las investigaciones que se ocuparon del desarrollo de la lectura y la escritura en diversos sistemas ortográficos han señalado que las características de cada sistema generan estrategias iniciales de lectura y escritura disímiles (Frost, 2005; Katz & Frost, 1992, 2001; Ziegler & Goswami, 2005).
En esta línea se ha señalado que, en los sistemas ortográficamente transparentes en los cuales las relaciones entre fonemas y grafemas son altamente consistentes, los sujetos desarrollarían tempranamente estrategias de escritura basadas en el procesamiento fonológico y la conversión de fonemas a grafemas (Diuk et al., 2009; Signorini, Borozne & Diuk, 2001).
En cambio, en las ortografías más opacas en las cuales la conversión de fonemas a grafemas no resulta una estrategia productiva, los sujetos deben desarrollar tempranamente estrategias léxicas y sub-léxicas de escritura y lectura (Seymour, Aro & Erskine, 2003).
El conocimiento léxico se encuentra constituido por el almacén de representaciones ortográficas de las palabras que poseen los sujetos. Las representaciones ortográficas de las palabras contienen información acerca de las letras que la componen y su ubicación dentro de la misma (Perfetti, 1992). Estas representaciones se adquieren a partir del mecanismo de recodificación fonológica, mediante el cual es posible descifrar y pronunciar correctamente las palabras impresas (Thorne et al., 2013).
Por otro lado, diversos estudios han arrojado evidencia del almacenamiento de unidades sub-léxicas tales como sílabas, morfemas, o cadenas de letras que aparecen juntas con frecuencia en cada sistema ortográfico (Dehane, 2009; Dehane, Cohen, Sigman & Vinckier, 2005).
En efecto, estudios realizados en francés, un sistema ortográfico más opaco que el español, señalan que, a partir de su contacto con material escrito los sujetos adquieren de manera implícita e inconsciente, las regularidades de su sistema ortográfico (Pacton, Fayol & Perruchet, 2005) y acceden a las mismas para resolver la escritura de palabras ortográficamente complejas. Por ejemplo, en francés, la cadena sonora /et/ se traduce más frecuentemente como ette después de <V> que después de <F>. Para analizar si los participantes eran sensibles a esta regularidad del sistema ortográfico del francés, Pacton, Fayol y Perruchet (2005) dictaron palabras y pseudopalabras que contenían la cadena sonora /et/ a niños de 8 a 11 años y adultos y notaron que los participantes respetaban la regularidad al escribir palabras y pseudopalabras.
Ahora bien, estos estudios fueron llevados a cabo en lenguas de ortografía opacas por lo que resultaría interesante observar si en una lengua de ortografía transparente como el español en la cual la relación fonología-ortografía resulta mucho más estable, los niños son sensibles a las regularidades del sistema ortográfico.
Algunos estudios realizados con niños que leían en español, una lengua ortográficamente transparente, sugieren que efectivamente los sujetos son sensibles a la frecuencia de las sílabas del sistema ortográfico. Vera, Jiménez-Fernández y Defior (2013), utilizando la tarea de juicio de similitud de palabras, observaron que niños de 2do, 4to y 6to grado de Educación Primaria señalaron como más reales pseudopalabras que contenían grupos consonánticos de alta frecuencia (por ejemplo, prefate en lugar de drufate).
Por su parte, Carrillo y Alegría (2014) en otro estudio con niños españoles encontraron evidencia de la sensibilidad de niños de 2do a 6to grado a la frecuencia de las sílabas. Estos autores dictaron a un grupo de niños palabras y pseudopalabras con las sílabas /ba/, /be/, /bi/, /bo/ y /bu/, en cada una de sus formas ortográficas posibles (<BA>, <BE>, <BI>, <BO> y <BU> y <VA>, <VE>, <VI>, <VO> y <VU>). El caso de estas sílabas resulta particularmente útil en español ya que el sonido /b/ presenta una relación inconsistente con los dos grafemas que lo representan (<B> y <V>). A pesar de que en términos generales el grafema <B> es más frecuente, el uso de una u otra letra, se ve afectado por la vocal que le sigue: el grafema <V> es más frecuente delante de <E> e <I> y el grafema <B> es más frecuente delante de <A>, <O> y <U>. Se considera que el uso de las sílabas <VE> y <VI> (sílabas de mayor frecuencia que incluyen al grafema de menor frecuencia del par, es decir, <V>) es evidencia de la sensibilidad de los niños hacia la frecuencia de las sílabas.
Carrillo y Alegría (2014) obtuvieron evidencia de que, en español, los niños desarrollan tempranamente sensibilidad hacia la frecuencia de las sílabas dado que los niños tendieron a utilizar la sílaba de mayor frecuencia en la escritura de palabras y pseudopalabras.
El objetivo de este trabajo es, entonces, analizar, si los datos obtenidos en los estudios realizados en España se replican en niños argentinos. Efectivamente, se ha señalado que en países como Chile o Argentina los diseños curriculares educativos poseen pocas referencias estrictas en relación a la enseñanza de la ortografía, hecho que ha dado como resultado bajos niveles de desarrollo de conocimiento ortográfico (ambos países se encuentran por encima de la media en errores de ortografía en una prueba administrada a América Latina y El Caribe) (Unesco, 2010).
Dados estos datos, resulta interesante observar si el desarrollo de algunos aspectos relacionados con el conocimiento ortográfico en Argentina es similar al que se da en otros países con el mismo sistema ortográfico.
Asimismo, resultaría interesante analizar si es la frecuencia absoluta de cada sílaba, es decir, el número de ocurrencias de las sílabas target en cualquier posición léxica, el factor que más influye en el posible almacenamiento de unidades sub-léxicas o si, por el contrario, es la magnitud de la diferencia de frecuencia entre sílabas de un par con el mismo sonido (por ejemplo, <VA> y <BA>), es decir, el tamaño de la diferencia entre el número de ocurrencias de una u otra cadena de letras con el mismo sonido, el hecho más relevante.
En efecto, en un trabajo anterior realizado con niños argentinos que leen en español, Ferroni y Diuk (2013) observaron que la magnitud de la diferencia en la frecuencia de los ítems de cada par de grafemas homófonos (con el mismo sonido, por ejemplo <B> y <V>) es un factor relevante en el aprendizaje de cadenas ortográficamente complejas. En efecto, las autoras, intentando replicar el paradigma de Share (1999) de aprendizaje ortográfico, hicieron leer a niños de 3er grado textos breves con pseudopalabras ortográficamente complejas en español. Luego de dos días, las autoras les pedían a los niños que escribieran dichas pseudopalabras al dictado. Ferroni y Diuk (2013) observaron que los niños podían almacenar la forma ortográfica de palabras con grafemas cuya frecuencia era similar respecto del grafema con el mismo sonido (los niños obtuvieron un desempeño satisfactorio tanto en Lluedelote 73% como en Yuedelote 60% donde la diferencia de frecuencia entre <Y> o <LL> es baja: <LL> es 1,2 veces más frecuente que <Y>) pero en aquellos pares de pseudohomófonos en los cuales las diferencias en la frecuencia entre grafemas era más importante (/s/ como <C> o <S>, <S> es 2,69 veces más frecuente que <C>), los sujetos podían recordar la pseudopalabra con el grafema más frecuente (Silfosa, 100%) mientras que en muy pocos casos se conseguía retener la forma que incluía el grafema con menor frecuencia de aparición (Cilfosa, 30%). En consecuencia, las autoras propusieron que la magnitud de la diferencia en la frecuencia de aparición cada par de grafemas homófonos posee cierto nivel de impacto en el aprendizaje de nuevas palabras.
Resultaría interesante entonces, analizar si en efecto, los niños hablantes de español almacenan unidades sub-léxicas de escritura y si la variable de la magnitud de la frecuencia entre letras de un par con el mismo sonido incide y en qué nivel en este proceso.
Método
Para la recolección y análisis de los datos del presente trabajo de investigación se utilizó un enfoque cuantitativo. Se trata de un diseño no experimental-transeccional con un alcance correlacional ya que pretende evaluar el grado de asociación entre las variables (Sampieri, Fernández Collado & Lucio, 2010).
La hipótesis de trabajo es que los niños que leen y escriben en español son sensibles a la frecuencia de aparición de las sílabas en su sistema ortográfico, por lo tanto, al tener que escribir palabras de baja frecuencia con ortografía inconsistente (con dos o más posibilidades y sin que haya regla ortográfica que indique cuál es la indicada en cada caso) y cuya representación ortográfica probablemente no posean, utilizarán la opción de sílaba más frecuente.
Participantes
El estudio fue realizado con 259 niños (116 niños y 143 niñas) que cursaban 4to, 5to, 6to y 7mo grado en una escuela privada de la Ciudad de Buenos Aires. La edad cronológica promedio de los participantes fue de 10 años y 8 meses (M= 130.77 meses, DE= 14.23). Todos los niños fueron hispanohablantes nativos. Con anterioridad al comienzo de las sesiones de evaluación, las familias de los niños firmaron un consentimiento informado en el que expresaban su conformidad en relación con el proyecto de investigación. Los niños participantes manifestaron su asentimiento de forma verbal y en todo momento se atendió a que no se produjera ningún tipo de malestar que justificara la exclusión de algún niño de las sesiones de aprendizaje.
Medición
Siguiendo a Carrilllo y Alegría (2014), se administró una prueba de escritura de 26 palabras ortográficamente complejas (con dos o más posibles escrituras sin que exista regla que indique cuál es la correcta) de muy baja frecuencia que incluían las cadenas sonoras /be/, /bi/, /siar/ y /sia/ en sus dos posibles formas ortográficas (<BE>/<VE>, <BI>/<VI>, <CIAR>/<SIAR> y CIA>/<SIA>). Algunas de las palabras dictadas fueron besugo para la cadena <BE>; veterano para la cadena <VE>; bikini para la cadena <BI>; vicuña para la cadena <VI>; distanciar para la cadena <CIAR>; anestesiar para la cadena <SIAR>; desperdicia para la cadena < CIA> y amnesia para la cadena <SIA>. Las palabras fueron seleccionadas del Diccionario de frecuencias del castellano escrito de niños de 6 a 12 años, (Martínez Martín & García Pérez, 2004). No se incluyeron pseudopalabras en el presente estudio con el fin de evitar la adopción de una estrategia de escritura simplista por parte de los niños que se viera reflejada en la elección sistemática del grafema <B> o del grafema <V>, por un lado y en la elección sistemática del grafema <S> o del grafema <C> para escribir todos los ítems (Carrillo & Alegría, 2014). Sin embargo, para intentar llevar al mínimo la posibilidad de acceder a conocimiento léxico se seleccionaron palabras de baja frecuencia. Se obtuvo un valor de alfa de Cronbach de .71 en esta prueba.
Procedimiento
La prueba de escritura de palabras fue administrada de manera grupal en las aulas del colegio al que asistían los niños. Para ello, la autora del presente estudio se presentaba en las aulas y les dictaba las palabras de la prueba de escritura a los niños. Antes del dictado, se les explicaba a los niños la consigna de trabajo y se les pedía que permanecieran en silencio para poder escuchar bien las palabras que se decían. Las palabras se repetían dos veces y se esperaba a que todos los niños hubieran escrito la última palabra dictada para continuar con la siguiente. Las palabras dictadas fueron las mismas para los cuatro grados. La prueba fue administrada durante el mes de julio a todos los grupos.
Análisis de datos
Utilizando el paquete estadístico SPSS (Statistical Package for the Social Sciences), en primer lugar se analizaron las distribuciones de los puntajes obtenidos para identificar aquellas que se alejaban de la distribución normal asintótica (prueba de Kolmogorov-Smirnov).
Asimismo, con el fin de analizar el desempeño de los niños en la escritura en el dictado de palabras, se calcularon los estadísticos descriptivos para conocer las medias de escritura y los desvíos estándar.
Con el fin de comparar las medias en la escritura de palabras con sílabas homófonas (de igual sonido, pero con escritura distinta), se realizó una comparación de medidas relacionadas (U de Wilcoxon) entre el desempeño en escritura con la sílaba más frecuente y la sílaba menos frecuente. Con esta misma prueba, se comparó el desempeño de escritura de palabras con la sílaba de mayor frecuencia entre los niños de diferentes grados.
Resultados
En primer lugar, se analizaron las distribuciones de las puntuaciones obtenidas en la escritura de las sílabas y las puntuaciones de la escritura convencional de las palabras. Este análisis mostró que todas las medidas se alejaron significativamente de la distribución normal asintótica (Z de Kolmogorov-Smirnov = 1.955; p = .001, para la escritura de la sílaba <VE>, Z de Kolmogorov-Smirnov = 2.055; p = .001, para la escritura de la sílaba <VI>, Z de Kolmogorov-Smirnov = 3.197; p = .001, para la escritura de la sílaba <CIAR>, Z de Kolmogorov-Smirnov = 4.203; p = .001, para la escritura de la sílaba <CIA>, Z de Kolmogorov-Smirnov = 3.737; p = .001, para la escritura de palabras con la sílaba <VE>, Z de Kolmogorov-Smirnov = 3.550; p =.001, para la escritura de palabras con la sílaba <VI>, Z de Kolmogorov-Smirnov = 5.393; p = .001, para la escritura de palabras con la sílaba <CIAR> y Z de Kolmogorov-Smirnov = 6.063; p = .001, para la escritura de palabras con la sílaba <CIA>). Por tal razón se utilizaron pruebas estadísticas no paramétricas para analizar los datos (U de Wilcoxon). Por otro lado, se calcularon los estadísticos descriptivos de las medidas de escritura de cada una de las sílabas (ver Tabla 1).
Tabla 1: Estadísticos descriptivos de las medidas de escritura de las sílabas más frecuentes con el grafema menos frecuente y los puntajes por escritura correcta e incorrecta con cada una de las sílabas (en porcentajes)
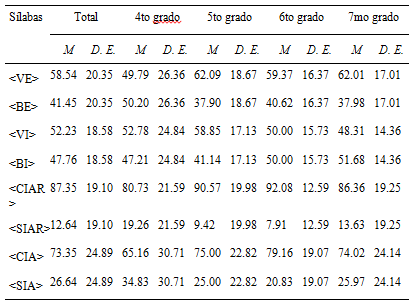
La comparación de medias respecto de la escritura de la sílaba más frecuente (U de Wilcoxon) reveló que en todos los pares de sílabas analizados, los niños escribieron en mayor medida la sílaba más frecuente del par de sílabas con el mismo sonido, siendo la diferencia estadísticamente significativa (<VE-BE> Z = -.199, p = .045, <VI-BI> Z = -163, p = .038, <CIAR- SIAR> Z = -5.90, p = .001, <CIA- SIA> Z = -4.25, p = .001).
Con el fin de analizar si es la frecuencia absoluta de cada sílaba o si, por el contrario, es la magnitud de la diferencia en la frecuencia de cada par de sílabas homófonas (con el mismo sonido) el factor que incide en mayor medida en el uso de una u otra sílaba, se calcularon las magnitudes de las diferencias en las frecuencias de los pares de sílabas con el mismo sonido. En un análisis de tipo cualitativo, los resultados mostraron que la sílaba <VI> es 1.02 veces más frecuente que <BI>, la sílaba <VE> es 2.06 veces más frecuente que <BE>, la sílaba <CIA> es 7.09 veces más frecuente que <SIA> y la sílaba <CIAR> 242 veces más frecuente que <SIAR>.
El número de ocurrencias (frecuencia token) de palabras que contienen las sílabas target en cualquier posición y la magnitud de la diferencia en la frecuencia de cada par con el mismo sonido se muestra en la Tabla 2.
Tabla 2: Número de ocurrencias (frecuencia token) de palabras que contienen las sílabas target en cualquier posición y magnitud de la diferencia en la frecuencia de cada par con el mismo sonido
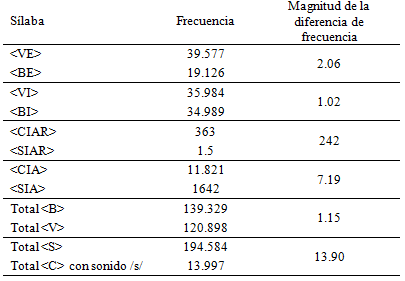
Además del análisis cualitativo, otra comparación de medias (U de Wilcoxon) entre sílabas homófonas (idéntico sonido) pero con diferente escritura y frecuencia de aparición (<VE>, <VI>, <CIAR> y <CIA> versus <BE>, <BI>, <SIAR> y <SIA>) mostró que la diferencia entre sílabas frecuentes y no frecuentes es estadísticamente significativa (Z = 8.25, p = .028).
Por último, con el fin de analizar el aprendizaje implícito de las regularidades durante los diferentes años, se compararon las medias de escritura con la sílaba de mayor frecuencia obtenidas entre grados. Los resultados señalaron que existieron diferencias significativas entre 4to y 5to grado a favor de la escritura con la sílaba de mayor frecuencia (Z = -3.59, p = .001), pero no entre los demás niveles (Z = -1.268, p = .205 entre 5to y 6to grado y Z = -.957 p = .338 entre 6to y 7to grado).
Discusión
El objetivo del presente trabajo fue el de analizar si niños de 4to a 7mo grado de la escuela primaria son sensibles a la frecuencia de un grupo de sílabas del sistema ortográfico español, un sistema ortográfico transparente.
Para ello, se les dictó a 259 niños argentinos de 4to a 7mo grado palabras con las cadenas sonoras /be/, /bi/, /siar/ y /sia/ en sus dos formas ortográficas posibles (<VE> o <BE>, <VI> o <BI>, <CIAR> o <SIAR> y <CIA> o <SIA>).
La particularidad de estas sílabas reside en el hecho de que, en español, una de las sílabas de cada par homófono (con el mismo sonido) es la sílaba más frecuente con el grafema menos frecuente (<VE>, <VI>, <CIAR> y <CIA>) mientras que la otra versión escrita de la sílaba (<BE>, <BI>, <SIAR> y <SIA>) es la sílaba de menor frecuencia que incluye el grafema más frecuente. El uso prioritario del primer grupo (sílaba más frecuente con el grafema menos frecuente) daría cuenta de que los niños son sensibles a la frecuencia de las sílabas y utilizan dicho conocimiento para escribir, mientras que el uso mayoritario de las sílabas del segundo grupo (sílaba menos frecuente que incluye el grafema más frecuente) constituiría evidencia del uso de procesamiento fonológico.
Los resultados obtenidos en el presente trabajo sugieren que los niños son altamente sensibles a la frecuencia de las sílabas del sistema ortográfico. En efecto, en todos los pares de sílabas incluidos en el análisis se obtuvieron diferencias significativas a favor de la escritura de la sílaba más frecuente.
En relación a este resultado, se ha señalado que al igual que en los sistemas opacos, en ortografías transparentes, una vez que los sujetos han adquirido cierto nivel de automatización en el conocimiento de las correspondencias entre fonemas y grafemas, comienzan a atender a unidades más largas que el grafema durante la lectura hecho que permite su almacenamiento (Huemer, Aro, Landerl & Lyytinen, 2010). Esta idea se encuentra en línea con la hipótesis de la recodificación fonológica como mecanismo de aprendizaje ortográfico la cual estipula que la lectura permite realizar diferentes asociaciones entre la escritura y los sonidos durante la lectura (Share, 1995; 1999; 2004; 2008; 2011).
Los resultados obtenidos en el presente estudio coinciden con los obtenidos en estudios realizados con niños españoles (Carrillo & Alegría, 2014; Vera, Jiménez-Fernández & Defior, 2013) en los cuáles se observó que los niños eran sensibles a la frecuencia de las sílabas del español ya a partir de 2do grado.
En el presente estudio, en contraposición a los realizados por Carrillo y Alegría (2014) y Vera, Jiménez-Fernández y Defior (2013) no se incluyó a niños del primer ciclo de primaria, hecho que constituye una limitación metodológica que no permite delimitar en qué momento del desarrollo del proceso de alfabetización los niños comienzan a desarrollar la sensibilidad a la frecuencia de las sílabas. Este asunto deberá ser atendido en estudios posteriores.
Sin embargo y respecto de la edad de los sujetos, en la comparación por grados, los resultados obtenidos señalaron un incremento significativo de la sensibilidad hacia la frecuencia de las sílabas entre 4to y 5to grado, diferencia que deja de existir entre grados superiores. Este dato sugeriría queque en ese alrededor de 5to grado se establecería un momento “techo” en el que se llega al máximo del almacenamiento de las unidades sub-léxicas incluidas en el presente estudio.
Por otro lado, el presente trabajo se propuso analizar si es la frecuencia absoluta de cada sílaba el factor que más influye en el almacenamiento de unidades sub-léxicas o si, por el contrario, es la magnitud de la diferencia de frecuencia entre sílabas de un par con el mismo sonido (por ejemplo, <VA> y <BA>), la variable con más incidencia.
En efecto, en un trabajo anterior, Ferroni y Diuk (2013) observaron que la magnitud de la diferencia en la frecuencia de aparición de los ítems de cada par de grafemas homófonos era un factor relevante en el aprendizaje de cadenas ortográficamente complejas. Las autoras observaron que un grupo de niños de 3er grado podían almacenar la forma ortográfica de palabras con un grafema cuya frecuencia era similar respecto del grafema con el mimo sonido (los niños obtuvieron un desempeño satisfactorio tanto en Lluedelote (73%) que en Yuedelote (60%) donde la diferencia de frecuencia entre <Y> o <LL> es baja: <LL> es 1,2 veces más frecuente que <Y>) pero que esto no era posible en aquellos pares de pseudohomófonos en los cuales las diferencias en la frecuencia entre grafemas era más importante (/s/ como <C> o <S>, <S> es 2,69 veces más frecuente que <C>). En los casos en que la magnitud entre las frecuencias era más amplia, los cuales los niños retenían sólo la forma más frecuente.
En el presente trabajo, a pesar de haber obtenido diferencias significativas en todos los pares de sílabas a favor de la sílaba más frecuente, se observó que la diferencia de uso de la sílaba más frecuente del par era mucho más amplia en los pares en los cuales existe una amplia diferencia en la frecuencia entre sílabas. Por el contrario, en los pares con poca diferencia de frecuencia, la diferencia a favor del uso de la sílaba más frecuente se achicaba considerablemente. De hecho, el orden de los pares de sílabas coincide si se ordenan a partir de la magnitud de la diferencia de la frecuencia entre pares homófonos o a partir de la diferencia de uso entre la sílaba más y menos frecuente (par <CIAR>/ <SIAR> magnitud de la diferencia de la frecuencia: 242 puntos, diferencia en el uso de la sílaba más frecuente: 74.71 puntos; par <CIA>/ <SIA> magnitud de la diferencia de la frecuencia: 7.19 puntos, diferencia en el uso de la sílaba más frecuente: 46.71 puntos; par <VE>/ <BE> magnitud de la diferencia de la frecuencia: 2.06 puntos, diferencia en el uso de la sílaba más frecuente: 17.09 puntos; par <CIAR>/ <SIAR> magnitud de la diferencia de la frecuencia: 1.02 puntos, diferencia en el uso de la sílaba más frecuente: 4.47 puntos). En efecto, el análisis estadístico mostró que, a pesar de ser baja, existe una correlación positiva entre la magnitud de la diferencia en la frecuencia entre pares homófonos y la diferencia en el puntaje que denota el uso de la sílaba más frecuente en comparación a la silaba menos frecuente (p= 397). Este resultado sugiere que la magnitud de diferencia en la frecuencia entre pares de sílabas con el mismo sonido así como entre pares de letras con el mismo sonido se relaciona con la medida de almacenamiento de los sujetos de dichas unidades. A pesar de que niños utilizaron significativamente en mayor medida las sílabas <VI> y <CIAR> que sus pares con el mismo sonido y diferente escritura (<BI> y <SIAR>) utilizaron en mayor medida las sílabas cuya frecuencia dista más de sus pares con el mismo sonido.
A modo de conclusión y como implicancia pedagógica, los resultados obtenidos en el presente estudio sugieren que el almacenamiento y uso de ciertas sílabas del sistema ortográfico español se relacionan directamente con su nivel de frecuencia y con la magnitud de frecuencia que se da en cada par de sílabas con el mismo sonido. Este hecho poseería entonces cierto nivel de incidencia en el desarrollo de la lectura y la escritura ya que sugiere que, cuando no poseen la representación ortográfica de una palabra, los niños tienden a utilizar la sílaba más frecuente para resolver las inconsistencias de la escritura. Por lo tanto, las instituciones educativas deberían prestar especial atención en diseñar propuestas que exploten la sensibilidad ortográfica de los niños hacia distintas unidades ortográficas para mejorar la escritura convencional y la velocidad en el reconocimiento de palabras que permite la fluidez lectora.
Por otro lado, se señala la importancia de trabajar especialmente la escritura convencional de palabras que contengan las sílabas y los grafemas de menor frecuencia en el sistema ortográfico para garantizar que los niños aprendan la escritura convencional de dichas palabras ya que utilizar la sílaba o el grafema más frecuente no es garantía de respetar la escritura convencional de todas las palabras del idioma.

