










Services on Demand
Journal

Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO
Related links
-
 Similars in
SciELO
Similars in
SciELO
Share

 Permalink
PermalinkAnales de la Facultad de Medicina
Print version ISSN 1025-5583
An. Fac. med. vol.76 no.spe Lima 2015
http://dx.doi.org/10.15381/anales.v76i1.10969
ARTÍCULOS ORIGINALES
Índice de dispersión poblacional distrital (IDP) para la estimación de necesidades de recursos humanos en salud del primer nivel de atención
District population dispersion index (IDP) for estimating human resources needs at primary health care level
Carmela Álvarez1, María Z. Cuzco Ruiz2, Felipe Peralta Quispe2
1 Instituto de Investigación Estadístico, Social y Económico.
2 Dirección de Gestión del Trabajo de la Dirección General de Gestión del Desarrollo de Recursos Humanos – Ministerio de Salud del Perú.
Resúmen
Introducción: El Ministerio de Salud de Perú (MINSA) viene implementando políticas y estrategias orientadas a garantizar el acceso a atención con equidad, oportunidad y calidad; para lo cual se requiere contar con recursos humanos (RHUS) suficientes y adecuadamente distribuidos en los diferentes niveles de atención. Así, es fundamental estimar la brecha de RHUS especialmente en el primer nivel de atención, incorporando en particular como criterio, la dispersión poblacional presente en el país. Objetivos: Diseñar, validar y aplicar un índice de dispersión poblacional distrital (IDP) que caracterice la dispersión distrital y aporte en la estimación de brecha de RHUS en el primer nivel de atención. Diseño: Estudio observacional y analítico, análisis multivariado. Lugar: Dirección General de Gestión del Desarrollo de Recursos Humanos MINSA, Perú. Participantes: Se consideró como unidad de análisis la totalidad de los distritos del Perú. Intervenciones: Análisis factorial exploratorio que considera variables demográficas, sociales, económicas y de acceso a los servicios de salud, obtenidas de los Censos de Población y Vivienda (2005 y 2007) y la Encuesta Nacional Continua (2006). Principales medidas de resultado: Índice de dispersión poblacional distrital. Resultados: El IDP fue estructurado y validado con la relación oficial de municipios rurales y la percepción de los operadores sanitarios de los Gobiernos Regionales del país. De las 1 831 municipalidades evaluadas, se clasificó los 1 277 distritos considerados rurales de acuerdo a la clasificación de Presidencia de Consejo de Ministros (PCM) como dispersos por la metodología; se identificó un 82% de concordancia. Conclusiones: El IDP diseñado y validado aporta en la estimación de brechas de RHUS para los servicios asistenciales del primer nivel de atención en el Perú.
Palabras clave: Políticas, estrategias, equidad, recursos humanos.
Abstract
Introduction: The Ministry of Health of Peru (MINSA) is implementing policies and strategies to ensure equitable access to care, timeliness and quality. Sufficient human resources (RHUS) properly distributed in the different levels of care is needed to accomplish this. Thus, it is essential to adequately estimate the gap of RHUS, especially at primary care level. Objectives: To develop, validate and implement a district population dispersion index (IDP) characterizing the district, and to provide dispersion in estimating RHUS gap at primary care level. Design: Observational and analytical study. Location: Directorate General Management Human Resources Development MINSA, Peru. Participants: All districts of Peru were considered for analysis. Interventions: An exploratory factor analysis was performed. It considered demographic, social and economic access to health services, obtained from the Population and Housing Censuses (2005 and 2007) and the National Continuing Survey (2006) variables. The IDP was structured and validated against the official list of villages and the perception of health officers of regional governments. Main outcome measures: IDP. Results: Out of 1 831 municipalities evaluated, we classified 1 277 districts as rural, according to the classification of the Presidency of the Council of Ministers (PCM). They were considered as scattered by the methodology. Concordance was 82%. Conclusions: The IDP is a useful indicator to estimate the gaps of RHUS for health services at primary care level in Peru.
Keywords: Policies, strategies, equity, human resources.
INTRODUCCIÓN
El Perú viene desarrollando importantes esfuerzos en el marco de la reforma de su sistema de salud, por garantizar el acceso de la población en su conjunto a una atención de salud con equidad, oportunidad y calidad. Sin embargo, el principal reto que afronta el Ministerio de Salud, en materia de dotación de recursos humanos en salud (RHUS) en el primer nivel de atención, es garantizar su disponibilidad especialmente en zonas de mayor dificultad de accesibilidad (1-3).
En este contexto, la planificación de RHUS asume el reto de estructurar un proceso sistemático que permita disponer, en el momento y en el lugar requerido, de las personas necesarias y con las competencias adecuadas, para ofrecer con calidad las prestaciones de salud y, de ese modo, cumplir los objetivos sanitarios (4).
Se han descrito diferentes métodos de cálculo para determinar el número de recursos humanos en salud (RHUS) necesarios y la brecha correspondiente de los mismos. Dreesch y col. describen al respecto cinco enfoques metodológicos utilizados para determinar las necesidades de recursos humanos en salud (5,6). En el caso de las necesidades en el primer nivel de atención, uno de los métodos empleados es el que se basa en el criterio de densidad poblacional; sin embargo, los valores obtenidos con este indicador, al dejar de considerar la dispersión de la población, no expresan precisamente las necesidades de personal de salud en las zonas con mayor dificultad en el acceso, lo que constituye una seria limitación especialmente en nuestro país caracterizado por una compleja realidad geo-socio-sanitaria. Es por ello que resulta necesario desarrollar una metodología que permita a los planificadores locales realizar el ajuste de la dotación en aquellas zonas consideradas por los operadores sanitarios como dispersa.
Se define como población dispersa a aquella que se caracteriza porque la distribución de sus viviendas es separada entre sí. Ello es típico en zonas de agricultura intensiva, con parcelas de pequeño tamaño que se intercalan entre las casas. Esta condición está asociada con los recursos naturales (disponibilidad de agua, relieve, tierras agrícolas, entre otras), con factores humanos (historia, nivel de vida, tecnología, entre otras) y, fundamentalmente, con la densidad poblacional. Estas características tienen importantes implicancias sobre la calidad de vida de los pobladores, con repercusión sobre el acceso a servicios básicos (energía eléctrica, agua potable y alcantarillado), educación, salud, entre otros; condiciones que subsecuentemente tienen impacto en la provisión de la oferta de servicios de salud diferenciándola y afectando en la dotación y permanencia de los RHUS (7,8). No existen evidencias en nuestro país y en la literatura internacional relacionadas al modelamiento de algún indicador que ajuste la dotación para la estimación de la necesidad de recursos humanos en salud en el primer nivel de atención en las zonas dispersas.
Dentro de los modelos estadísticos utilizados para identificar las variables más explicativas o correlacionadas en relación a un concepto a medir, se encuentra los análisis multivariados, estrategia de reducción de datos que es usada para explicar la variabilidad entre las variables observadas en términos de un número menor de variables subyacentes no observadas llamadas factores o dominios. Las variables observadas se modelan como combinaciones lineales de factores más expresiones de error. Por tal razón, el uso de este tipo de análisis estadístico resulta pertinente para integrar las variables demográficas, sociales, económicas y de acceso a los servicios de salud, que permite clasificar a los distritos de todo el país en dos categorías, dispersos y no dispersos, y a su vez tenga la suficiente consistencia estadística y alta concordancia con la percepción de dispersión por parte de los operadores sanitarios.
El presente estudio se desarrolla como parte de la responsabilidad técnica del equipo de Planificación Estratégica de la Dirección de Gestión del Trabajo en Salud de la Dirección General de Gestión del Desarrollo de Recursos Humanos en Salud (DGGDRH) del MINSA, de regular y planificar estratégicamente la dotación de recursos humanos de salud en función de las necesidades del país, en forma concertada con las instituciones y actores sociales a nivel nacional y regional. Por tal motivo, mediante R.M. N° 1762014 se aprobó la Guía Técnica para la Metodología de Cálculo de las Brechas de Recursos Humanos en Salud para los Servicios Asistenciales del Primer Nivel de Atención, siendo el Índice de dispersión poblacional distrital (IDP) unos de sus parámetros referenciales. El presente estudio sistematiza el proceso de formulación, validación y aplicación de la metodología del índice de dispersión poblacional distrital para la estimación de la necesidad de RHUS en el primer nivel de atención en el Perú.
MÉTODOS
Construcción del índice de dispersión poblacional distrital (IDP)
Para el presente estudio se elaboró un indicador categórico, sustentado en variables demográficas, sociales, económicas y de acceso a servicios de salud, el cual permite clasificar binariamente (dispersos y no dispersos) a todos los distritos de Perú.
Se aplicó el análisis multivariado por medio del análisis factorial exploratorio -puesto que el estudio de la población dispersa en nuestro país es un fenómeno multidimensional- considerando los aspectos sociales, económicos, geográficos y de acceso a los establecimientos de salud. Esta estrategia de reducción de datos fue usada para explicar la correlación entre las variables observadas en términos de un número menor de variables subyacentes no observadas llamadas factores o dominios. Las variables observadas se modelaron como combinaciones lineales de factores más expresiones de error. La elección de esta aproximación se basó en que las variables y las relaciones entre ellas podrían conformar dimensiones en particular que expliquen la condición de dispersión estimada.
Es preciso mencionar que la unidad de análisis en el estudio fue el distrito. Se tuvo como elementos base los planos cartográficos, el Censo Nacional de Población y Vivienda del año 2007 (CPV 2007) (9) y la Encuesta Nacional Continua (ENCO 2006) (10); evaluándose 1 831 distritos.
En base de las combinación de las siguientes 14 variables resultantes de la revisión de la literatura internacional y de las que los operadores sanitarios consideraron que caracterizarían a un distrito disperso.
-
LocChi:
LocMed:
LocGra:
CamPob0705:
InDre:
InAgu:
InEle:
P_piso_sin_tierra:
PeaPrim:
PeaSec:
PeaTer:
PeaDes:
Tiempo_Salud:
P_Pob_Rural:
Altitud:
Densidad Poblacional:
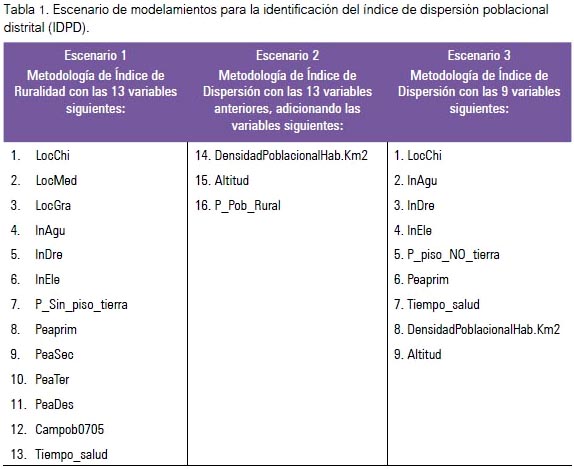
El equipo técnico de Planificación Estratégica de la Dirección de Gestión del Trabajo en Salud de la Dirección General de Gestión del Desarrollo de Recursos Humanos en Salud (DGGDRH) del MINSA propuso tres escenarios de calificación e identificación de dispersión a nivel distrital en todo el país, tal como se muestra en la tabla 1, utilizando las características y definiciones de las poblaciones rurales.
-
Escenario 1: Se consideraron 13 variables que caracterizan las áreas rurales del Perú.
-
Escenario 2: Se analizaron 16 variables, las cuales caracterizan las áreas de población dispersa en Perú. Estas están conformadas por las 13 del escenario 1 y tres más que miden circunstancias geográficas que condicionan la dispersión en nuestro país.
-
Escenario 3: Fueron nueve las variables que se sometieron a análisis a este nivel, las cuales caracterizan a las áreas de población dispersa en Perú y son las de mayor peso en la propuesta anterior.
Para que el análisis factorial tenga sentido deberían cumplirse dos condiciones básicas: parsimonia e interpretabilidad. Según el principio de parsimonia, los fenómenos deben explicarse con el menor número de elementos posibles. Por lo tanto, respecto al análisis factorial, el número de factores debe ser lo más reducido posible y estos deben ser susceptibles de interpretación sustantiva. Una buena solución factorial es aquella que es sencilla e interpretable.
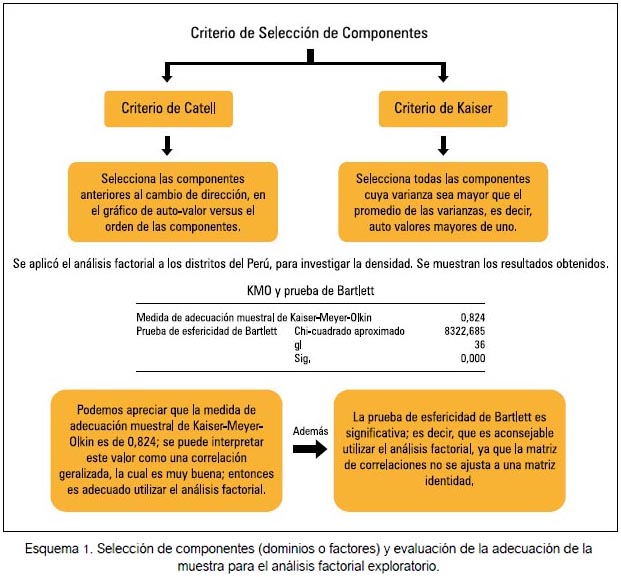
Luego de evaluar la adecuación del tamaño de muestra con la prueba de esfericidad de Barlett y las pruebas de Kaiser-Meyer-Olkin, se procedió a la extracción de factores siguiendo las pautas de Catell y Kaiser. Posteriormente, la extracción se realizó por medio de un análisis de componentes principales, eligiéndose cinco factores que explicaban el 88% de la variabilidad; así, los resultados obtenidos fueron estandarizados. Tras ello, se realizó un análisis por clúster (conjunto de técnicas multivariantes que agrupan objetos o individuos basándose en las características comunes que estos poseen), que permitió categorizar a los distritos en dispersos y no dispersos.
Validación del índice de dispersión poblacional distrital (IDP)
Para efectos de la validación del IDP, se evaluó la concordancia entre la cantidad de distritos dispersos a nivel nacional según nuestros resultados con la clasificación distrital (rural y urbana) de la Ley Nº 27972 de la Ley Orgánica de Municipalidades modificada mediante DS Nº 090-2011 de la Presidencia del Consejo de Ministros, donde se estipula 1 303 distritos rurales de un total de 1 831. Así mismo, se validó con la percepción de dispersión que definen el operador sanitario, para lo cual se utilizó un instrumento diseñado para tal fin, aplicándose con representantes de las Direcciones Regionales de Salud de Pasco, Huánuco, Amazonas, Ayacucho, Cajamarca, Huancavelica, Huánuco, Pasco, San Martín, Ucayali y Apurímac, en diferentes talleres.
RESULTADOS
Estructuración del IDP
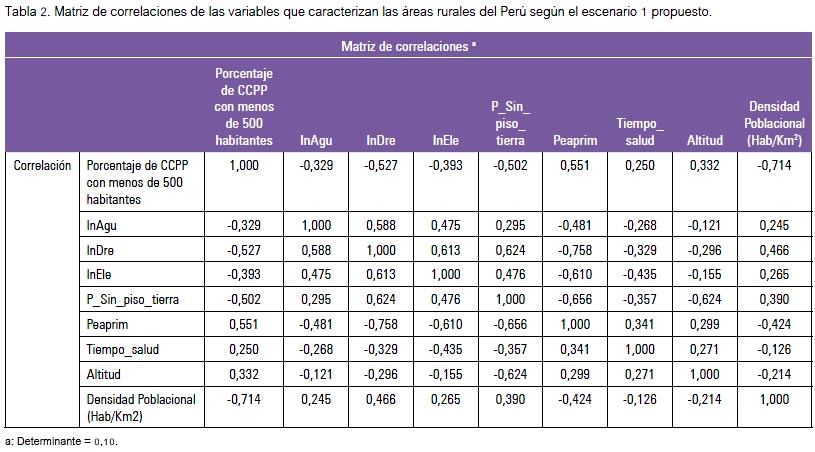
Las variables independientes o explicativas fueron dispuestas en una matriz de correlación. Así, se formó una tabla de doble entrada donde se presenta la lista de variables tanto en orden horizontal como en vertical, mostrando el coeficiente de correlación en la intersección correspondiente a las variables. A este nivel, el modelo mide y muestra la interdependencia en relaciones asociadas entre cada pareja de variables y todas al mismo tiempo. Asimismo, se evaluó si la matriz fue determinante.
Para efectos del presente estudio, se asumió que el tamaño de la muestra es tal que la muestra es representativa, presentando las mismas características de la población. De esta manera, las conclusiones que puedan extraerse a partir del análisis del coeficiente de correlación serán válidas con inferencia poblacional. Esto es aplicable para el tiempo de desplazamiento del hogar al establecimiento de salud más cercano, puesto que el resto de las nueve variables es información proveniente del Censo de Población y Vivienda del 2007 (CPV -2007).
El coeficiente de correlación es un valor entre -1 a 1, siendo los valores cercanos a cero los que denotan menor correlación (inclusive ausencia de ella) y aquellos más cercanos al valor absoluto 1 indica que la correlación es muy fuerte. En la tabla 2 se observa la matriz de correlaciones efectuada para el escenario 1, donde la correlación más alta está entre Pea Primaria (porcentaje de la población económicamente activa ocupada en el sector primario) y tenencia de drenaje en la vivienda, que es de -0,758, que muestra una relación lineal negativa fuerte.
La prueba de Kaiser-Meyer-Olkin y la prueba de esfericidad de Barlett confirmaron que podría realizarse el análisis factorial exploratorio, puesto que existe una correlación generalizada y no se ajusta a una matriz de identidad.
Como se expresó previamente, fueron dos los métodos utilizados para la selección de factores. El criterio de Kaiser, el cual selecciona todos los componentes cuya varianza sea mayor que el promedio de las varianzas, es decir, auto valores mayores de uno (esquema 2), y el criterio de Catell, utilizando el gráfico de sedimentación. Por ambas vías, se estima que la estructura factorial tendría cinco dominios.
En el esquema 1 se muestra los criterios de selección de componentes (dominios o factores) y la evaluación de la adecuación de la muestra para el análisis factorial exploratorio.
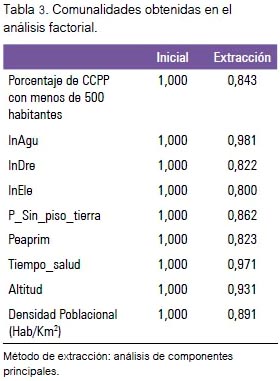
En la tabla 3 se presenta las comunalidades (proporción de la varianza explicada por los factores comunes en una variable). Se observa que son satisfactorias, especialmente la tenencia de agua en la vivienda, el tiempo de desplazamiento del hogar al establecimiento de salud más cercano, la altitud, densidad poblacional y vivienda con piso diferente de tierra. Además, la totalidad de las variables tiene valores superiores a 0,5.
Matriz de componentes
En la tabla 4 se presenta la matriz factorial, indicándose la relación de cada variable con el correspondiente componente. Los elementos de esta matriz son las puntuaciones factoriales, que a la vez pueden considerarse como los coeficientes de correlación lineal de Pearson del factor y la variable. Se observa que el primer factor tiene una alta correlación con casi todas las variables, con puntuaciones superiores a 0,4 en todos los casos. Por su parte, el segundo factor también tiene una correlación moderada con casi todas; pero la puntuación de altitud es mayor en este componente que en el primero.
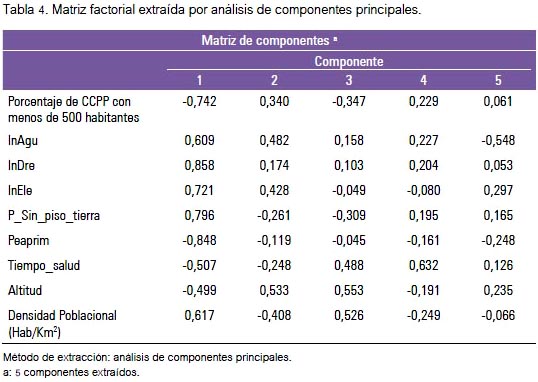
Tras la observación, se puede deducir que el primer componente tiene mayor explicación con las variables: Porcentaje de la población en viviendas particulares que disponen de algún tipo de drenaje o desagüe (0,858), Porcentaje de la PEA ocupada en el sector primario (-0,848), Porcentaje de la población en viviendas particulares que tienen cualquier material en sus pisos diferente a tierra (0,796), Cambio en la población 2007-2005 (-0,742), Porcentaje de la población en viviendas particulares que disponen de electricidad (0,721). Aunque, la explicación por las otras variables también son buenas. Por su parte, en el caso del segundo componente estaría explicada por la Altitud (0,533) y Porcentaje de la población en viviendas particulares que disponen de agua por red pública o pilón (0,482).
Análisis de componentes principales
La extracción se realizó aplicando el análisis de componentes principales (ACP). La varianza total explicada según los cinco componentes extraídos ascendió a 88%. El indicador multivariable que explica el grado de dispersión poblacional en cada unidad de análisis puede ser calculado multiplicando los valores de cada uno de los factores extraídos mediante ACP por sus respectivos autovalores. Específicamente en este estudio, para los primeros cinco dominios fueron: 4,418; 1,157; 1,076; 0,713 y 0,560.
De esta manera, se generó el indicador de dispersión poblacional Indiglobal en cada unidad de análisis (distrito), con los cinco componentes principales, mediante la expresión:
Indiglobal = ((FAC1_2 * 4.418) + (FAC2_2 * 1.157) + (FAC3_2 * 1.076) + (FAC4_2 * 0.713) + (FAC5_2 * 0.560))
Donde: FAC = Los valores de cada uno de los factores extraídos por unidad de análisis.
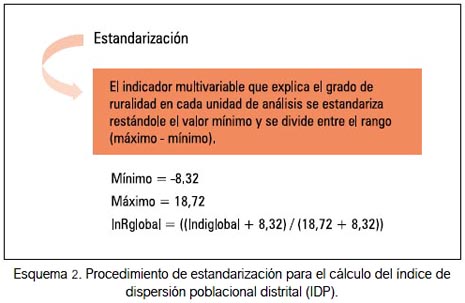
Estandarización
Los valores obtenidos para la variable Indiglobal fueron estandarizados (valores entre 0 y 1). Para ello se utilizó la fórmula, en la cual se resta el valor mínimo y se divide entre el rango (máximo – mínimo), obteniéndose con ello el índice de dispersión poblacional distrital (IDPD), tal como se especifica en el esquema 2.
No obstante, una vez elaborado el orden establecido por el indicador multivariable es necesario someterlo a pruebas a fin de comprobar que el indicador realmente refleje el fenómeno que estamos investigando. En ese sentido, una de las alternativas al cálculo del indicador multivariable es el empleo del análisis clúster para clasificar en estratos las unidades de análisis.
Análisis por clúster para la discriminación del índice de dispersión poblacional distrital (IDP)
El análisis clúster es un conjunto de técnicas multivariantes que persiguen agrupar objetos o individuos basándose en las características comunes que estos poseen, donde los grupos resultantes deben mostrar mucha homogeneidad entre los elementos del grupo y un alto grado de heterogeneidad entre los diferentes grupos. El grupo como tal, para efectos del estudio se le denominó clúster simplemente. El análisis por clúster permitirá categorizar a los distritos en dispersos y no dispersos.
En el análisis por clúster, existen dos grandes tipos de técnica: los métodos jerárquicos y los métodos no jerárquicos. En el caso de los primeros, el análisis parte desde el número de individuos, posteriormente estos van uniéndose entre sí en función de la mayor o menor proximidad, formando así clúster.
Estos a su vez se van uniendo hasta llegar a un único grupo. Tras ello se tiene dos posibilidades de desarrollo: la determinación de la medida de distancia o proximidad a usar, o el método que determinará el modo de unión sucesiva de los distintos grupos entre sí. En este último tipo se encuentra la vinculación inter-grupos, vinculación intragrupos, vecino más próximo o distancia mínima, vecino más lejano o distancia máxima y el método Ward.
El método Ward busca minimizar la varianza intra-grupos. Para ello parte del número de grupos, formando todos ellos por un único punto (todos los individuos), con lo que la suma de las varianzas intra-grupo es cero. Ulteriormente, se unirán dos grupos para conformar uno nuevo –concretamente aquellos dos puntos que minimicen el incremento en la suma de las varianzas intra-grupo-; el proceso continúa del mismo modo sucesivamente.
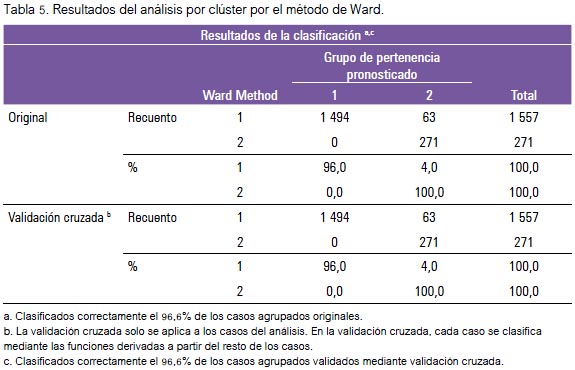
En la tabla 5 se observa los resultados del análisis por clúster. Puede verse que se ha generado dos tipos de distritos, asignándose finalmente 1 557 distritos al grupo 1 y un total de 271 distritos al grupo 2. Este resultado es producto de la asignación más óptima, garantizando que los grupos son homogéneos dentro de sí y heterogéneos entre ellos.
Validación del IDP
Se encontró una alta concordancia (82%) entre los distritos dispersos encontrados en el estudio y la clasificación distrital de rural de la Presidencia del Consejo de Ministros; así mismo, se identificó la concordancia con la percepción de dispersión definida por los distintos representantes de las microrredes en talleres descentralizados desarrollados en las Direcciones Regionales de Salud de Pasco (27 de noviembre de 2012) y Huánuco (29 de noviembre de 2012). En estas reuniones se identificó una concordancia promedio del 97% con la percepción de dispersión en 79 distritos adscritos en estas DIRESAS, identificándose una alta concordancia con la clasificación propuesta.
Con la validación política derivada de su correlación con la clasificación de ruralidad establecida por el Listado de Municipalidades Rurales propuesto por la PCM y su validación sanitaria derivada de su correlación con la percepción de dispersión de los representantes de las microrredes, se sugirió su uso como ajuste de la dotación de recursos humanos en distritos dispersos en la Guía Técnica para la Metodología de Cálculo de las Brechas de Recursos Humanos en Salud para los Servicios Asistenciales del Primer Nivel de Atención aprobada, mediante R.M. N° 176-2014/MINSA.
Clasificación de distritos según IDP
De las 1 831 municipalidades evaluadas, fueron clasificados los 1 277 distritos considerados rurales por la clasificación de PCM, como dispersos por la metodología, identificándose un 82% de concordancia.
Los distritos más dispersos se hallaron en los Departamentos de Huancavelica (89,4%), Huánuco (86,8%), y Amazonas (86,7%) y los distritos menos dispersos, en los Departamentos de Callao (0%), Lambayeque (21,1%) y Tumbes (30,8%).
DISCUSIÓN
El Ministerio de Salud del Perú, en el marco de la cobertura universal en materia de salud, se encuentra en la búsqueda del fortalecimiento de la atención primaria y mejora del acceso a los servicios de salud; para ello resulta fundamental elaborar el requerimiento de recursos humanos en salud respecto a los servicios a implementar en los diferentes establecimientos de salud.
El índice de ruralidad a nivel distrital constituye un criterio primordial para la dotación de recursos humanos en salud. Dicha ruralidad se mide en base al IDP. Así, la dispersión es un factor que debe ser considerado en la caracterización de una determinada población en materia de salud pública, puesto que tiene efecto sobre varios factores que pueden influir en el acceso a servicios de salud.
En Perú, los aspectos geográficos, el poco desarrollo técnico de las actividades agropecuarias, la falta de servicios básicos, una producción local destinada fundamentalmente al autoconsumo, caracterizan a una población dispersa.
En el presente estudio se generó un índice de dispersión poblacional distrital (IDP) en base a una aproximación multivalente utilizando un análisis factorial y análisis por clúster, el cual tiene una alta una concordancia con la clasificación de ruralidad establecida por el Listado de Municipalidades Rurales propuesto por la PCM. Por otro lado, el indicador y la categorización final están contextualizados a Perú, no solo porque están de acuerdo a normativas intersectoriales, sino porque ha sido validado con operadores regionales de salud. Cabe mencionar que nuestros hallazgos son similares a los realizados, mediante el mismo análisis exploratorio, en otras realidades como México (11).
El IDP calculado cuenta con elementos importantes que le dan ventajas frente a otros índices desarrollados. En primera instancia hay que resaltar que la naturaleza multifactorial propia de la dispersión poblacional ha sido considerada desde su concepción, situación que lo coloca muy cercano a la realidad. Asimismo, este aspecto ha sido considerado en el análisis donde se ha utilizado técnicas multivariantes para explicar la explicación más parsimoniosa de los datos primarios por medio del análisis factorial y el agrupamiento natural de las unidades de análisis usando el análisis por clúster; esto último es una ventaja metodológica y estadística de alta relevancia.
La clasificación generada permitirá realizar el ajuste de la dotación de recursos humanos en distritos dispersos, y se ha utilizado para diseñar la clasificación de dispersión poblacional distrital del anexo N° 4 de la Guía Técnica para la Metodología de Cálculo de las Brechas de Recursos Humanos en Salud para los Servicios Asistenciales del Primer Nivel de Atención aprobada mediante R.M. N° 176-2014/MINSA.
REFERENCIAS BIBLIOGRÁFICAS
1. Carrasco V, lozano E, Velásquez E. Análisis actual y prospectivo de la oferta y demanda de médicos en el Perú 2005-2011. Acta méd peruana.2008;25(1):22-9.
2. Huicho L, Diez Canseco F, Lema C, Miranda J, Lescano A. Incentivos para atraer y retener personal de salud de zonas rurales del Perú: un estudio cualitativo. Cad Saúde Pública. 2012;28(4):729-39.
3. Ministerio de Salud del Perú. Lineamientos de Gestión del Ministro de Salud. Lima: MINSA; 2008.
4. Huamán L, Liendo L, Nuñez-Vergara M. Plansalud: Plan sectorial concertado y descentralizado para el desarrollo de capacidades en salud, Perú 2010 – 2014. Rev Med Perú Exp Salud Publica. 2011;28(2):362-71.
5. Métodos para estimativa e projecao das necessidades de recursos humanos em Sáude. Observatorio em Recursos Humanos em Sáude. Exposición de Cid Manso de Mello Vianna. Instituto de Medicina Social-UERJ.
6. Dreesch N, Dolea C, Dal Poz MR, Goubarev A, Adams O, Aregawi M, B ergstrom K, Fogstad H, et al. An approach to estimating human resource requirements to achieve the Millennium Development Goals. Health Policy Plan. 2005 Sep;20(5):267-76.
7. Dispersión poblacional y desarrollo: un análisis preliminar para los municipios de Chiapas EGAP ITESM Campus Estado de México. Carretera Lago de Guadalupe Km 3.5, Atizapán de Zaragoza, Estado de México, C.P.
8. Aliaga G, Durand M. Diagnóstico de la situación de salud en las comunidades alto andinas del Departamento de Ancash-Perú. Rev peru epidemiol. 2008;12(1):1-7.
9. Censos Nacionales 2007 – Perú: Resultados definitivos, INEI-UNFPA-PNUD Setiembre 2008.
10. Resultados de la Encuesta Nacional Continua - ENCO2006, INEI-UNFPA Setiembre 2007
11. Zamudio F, Corona A, López I. Un índice de ruralidad para México. Espiral. 2008;14(42):179-214.
Conflictos de interés:
El autor declara que no existen conflictos de interés.
Correspondencia:
Felipe Peralta
Correo electrónico: fperalta@minsa.gob.pe

