










Services on Demand
Journal

Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO
Related links
-
 Similars in
SciELO
Similars in
SciELO
Share

 Permalink
PermalinkBiblios
On-line version ISSN 1562-4730
Biblios no.74 Pittsburgh Jan./Mar. 2019
http://dx.doi.org/10.5195/biblios.2019.366
CASE REPORT
A implantação e implementação de uma hemeroteca digital em Ciência da Informação: algumas considerações sobre o Harvester in Library and Information Science – HILIS
The insertion and implementation of a scientific Library in Information Science: Some considerations about the Harvester in Library and Information Science – HILIS
Adriana Bruna Silva Albuquerque
Pedro Ivo Silveira Andretta
Universidade Federal de Rondônia – UNIR, Brasil
Resumo
Objetivo. Abordar a implantação e implementação de uma hemeroteca digital de periódicos de acesso livre da área de Ciência da Informação e transversais, de cobertura global, utilizando o software Open Harvester System e as possibilidades OAI-PMH. Para tanto, foram esboçados conceitos sobre o Acesso livre, Open Archive Initiative – Protocol for Metadata Harvesting, Public Knowledge Project e seus softwares Open Journal Systems e Open Harvester System. Metodologia. Como aportes metodológicos, procurando descrever e justificar as etapas de seleção de provedores de dados (periódicos) e da configuração do servidor de serviço (hemeroteca digital), denominado "Harvester in Library and Information Science (HiLIS)", valemo-nos do ponto de vista qualitativo, exploratório, pesquisa ação e bibliográfica. Resultado. Os resultados obtidos propiciaram a sistemática e a política de desenvolvimento da coleção, a caracterização do HiLIS, e sua configuração quanto a entrada de dados, agrupamento de elementos de metadados Dublin Core, MARC, MODS e ETD-MS, as características da coleção e as modalidades de recuperação de informação. Conclusão. Assim, em nossas considerações finais, esboçamos algumas melhorias a serem implementadas e apontamos estudos futuros de ordem métrica para o conhecimento produzido na Ciência da Informação.
Palavras-chave
Ciência da Informação; Desenvolvimento de coleções; Hemeroteca digital; Metadados – correspondências; Open Harvester System; Periódicos de acesso livre.
Abstract
Objetive. This study aims to discuss the insertion and implementation of a Open Access digital scientific journal library for Information Science and related fields, with global coverage, using the Open Harvester System and OAI-PMH possibilities. For such concepts were planned concepts about the Acesso livre, Open Archive Initiative - Protocol for Metadata Harvesting, Public Knowledge Project and its software Open Journal Systems and Open Harvester System. Methodology. As methodological contribution the qualitative, exploratory, action research and bibliographic points-of-view were used, attempting to describe and justify the data providers (journals) and service server configuration (digital scientific library) selection, named "Harvester in Library and Information Science (HiLIS)". Results. As results were presented the systematics and politics of collection development, the characterization of HiLIS and its configuration regarding data input, grouping of Dublin Core, MARC, MODS and ETD-MS element metadata, and the collection’s characteristics and the information recovery modes. Conclusion. The final considerations discuss some improvements to be implemented and future measurement studies for the knowledge produced in Information Science.
Keywords
Collections development; Digital scientific library; Information Science; Metadata – Letters; Open access journals; Open Harvester System.
1 Introdução
Os avanços proporcionados pelo Acesso Livre – ou Acesso Aberto – para a comunicação científica são conhecidos pelo meio científico há algum tempo. Tais avanços propiciaram a dinamização das práticas de publicação e circulação das produções acadêmico-científicas, a exemplo da consolidação de sistemas eletrônicos para o desenvolvimento e manutenção de periódicos e repositórios, bem como iniciativas de estabilização de protocolos para intercâmbio de registros. Ademais, surgiram grandes bases de dados que permitem ao usuário manipular e acessar ao mesmo tempo o conteúdo de diferentes fontes.
Neste cenário, o sistema Harvester foi desenvolvido para coletar, armazenar, recuperar e pesquisar dados referências de periódicos e de diversas outras fontes, de modo a auxiliar a difusão dos conteúdos científicos e reduzir o tempo de levantamento bibliográfico, aumentando o acesso e o compartilhamento de ideias. São exemplos de sistemas desse tipo o GeoColeta1, o REA Paraná2, o Kollektin3, o U.N.C. Library4 e o AsiaJOL5.
Na área da Ciência da Informação, e particularmente no Brasil, os sistemas Harvester são bastante difundidos, a exemplo de bases de dados bem conhecidas, como a Base Referencial de Artigos de Periódicos em Ciência da Informação (BRAPCI)6 e o Repertório da Produção Periódica Brasileira de Ciência da Informação (RPPBCI)7, que indexam artigos de publicações nacionais. Apesar do grande número de sistemas existentes, carecemos ainda de uma base de dados que seja capaz de sumarizar a produção de acesso livre global, especificamente na área de Ciência da Informação.
Em consonância a essa necessidade, a pesquisa que segue tem como objetivo apresentar os procedimentos de implantação e implementação de uma hemeroteca digital8, valendo-se da tecnologia Harvester para coleta e difusão dos registros de periódicos de acesso livre global em Ciência da Informação, a saber, o Harvester in Library and Information Science (HiLIS) (http://www.biblioteconomia.unir.br/hilis/ ).
Nesse contexto, destacamos que nossa pesquisa se justifica e tem sua importância por ao menos dois pontos: seu escopo e seu valor instrumental. A primeira justificativa relaciona-se diretamente a melhorias na área de Arquivologia, Biblioteconomia e Documentação; já a segunda é, em justa medida, do interesse dos bibliotecários, por promover o uso de uma ferramenta própria para a coleta, a organização, a recuperação e o acesso à informação bibliográfica. É importante ressaltar que não é nossa intenção criar uma base de dados que substitua as já existentes, as quais servem a seu propósito com excelência, e sim propor uma base que complemente as opções de busca por artigos científicos, além de apresentar um roteiro de ações para que os bibliotecários promovam iniciativas similares em outras frentes científicas.
No decorrer deste artigo, exporemos brevemente os conceitos de Open Access, Open Archives/OAI-PMH, SEER/ OJS e Harvester/Open Harvester System. Apresentaremos também um trabalho prático-analítico em que discorremos sobre os procedimentos para a seleção dos periódicos que compõem o HiLIS, além da descrição do sistema, sua configuração de entrada de dados, arquivos, coleções e modalidades de recuperação de informação. Por fim, teceremos algumas considerações para a melhoria do sistema e suas formas de utilização.
2 Acesso livre / Open Access
Em meados dos anos 1980, com o aumento de títulos publicados e os altos custos de assinaturas de periódicos de editoras comerciais, o acesso à informação de publicações científicas tornava-se difícil (NEUBERT; RODRIGUES; GOULART, 2012). A crise dos periódicos impunha limitações quanto ao acesso e, por conseguinte, à visibilidade das pesquisas científicas, fatores que não podiam ser minimizados pelos autores-pesquisadores, impossibilitados de disponibilizar gratuitamente seus trabalhos em virtude da concessão de direitos autorais às editoras.
Em decorrência dessa crise, a comunicação científica presenciou o surgimento do movimento Acesso Livre, ou Acesso Aberto. Essa iniciativa visava possibilitar mundialmente o livre acesso às publicações científicas, evitando quaisquer barreiras de custo, de modo a favorecer a disseminação da informação entre cientistas e pesquisadores. Esse movimento teve como propósito remover as restrições de licenças de uso e atribuir ao próprio autor a responsabilidade pelo controle da integridade de sua obra, para que ele fosse devidamente reconhecido e citado.
O Acesso Livre à produção científica pode ser conduzido por meio de duas vias: a dourada ou a verde. Um ativista do movimento, Stevan Harnad, em entrevista à Encontros Bibli (HARNAD, 2007, p. xii), afirma que a via dourada "é apropriada para as revistas mantidas por meio de assinaturas, seja para tornar o seu conteúdo livremente acessível em linha, ou converter o seu modelo de recuperação dos custos"; já pela via verde, caberia aos "autores auto-arquivarem seus artigos, publicados em revistas científicas, nos RI [repositórios institucionais] de ALi [acesso livre], da sua respectiva instituição". Complementando essa percepção acerca da via verde, consideramos atualmente que "o depósito deve ser realizado em ambiente interoperável e aberto, nos repositórios institucionais ou temáticos" (CHALHUBI; BENCHIMOLII; GUERRA, 2012, p. 160).
Com o amadurecimento da compreensão das possibilidades do Acesso Livre, surgiu o interesse por padrões de interoperabilidade e protocolos para a colheita, compartilhamento e reuso de metadados. Neste cenário, aparece a Open Archives Initiative e o Protocol for Metadata Harvesting/ OAI-PMH.
3 Open Archives Initiative - Protocol for Metadata Harvesting (OAI-PMH)
A Open Archives Initiative9 (OAI) é uma organização criada no ano de 1999, centrada na Cornell University nos Estados Unidos e patrocinada pelas instituições Andrew W. Mellon Foundation, Coalition for Networked Information, Digital Library Federation, Natural Science Foundation e Alfred P. Sloan Foundation. Essa organização desenvolve e promove padrões de interoperabilidade para repositórios visando facilitar a disseminação eficiente de conteúdos e a comunicação científica, e é responsável também pela elaboração e popularização do Protocol For Metadata Harvesting (PMH).
O OAI-PMH oferece interoperabilidade e extensibilidade, que possibilitam o compartilhamento de metadados dos repositórios para aplicações externas que tenham interesse na coleta de dados. Nesses termos, Oliveira e Carvalho (2009), recordam que o procotolo OAI-PMH consiste na abertura dos metadados, e não necessariamente na abertura dos textos completos presentes nos repositórios. Dessa forma, nem todo repositório que implementa o procotolo OAI-PMH é de acesso aberto, assim como o inverso também é válido, isto é, há repositórios de acesso aberto que não implementam o protocolo OAI-PMH.
O OAI-PMH fornece um quadro em que a interoperabilidade é dividida em duas classes de participantes, conhecidos como provedores de dados e provedores de serviços. Os provedores de dados auxiliam na administração do sistema que suporta o protocolo de comunicação OAI-PMH. Já os provedores de serviços utilizam os metadados colhidos por meio do protocolo de comunicação, como se pode observar nas figuras a seguir:
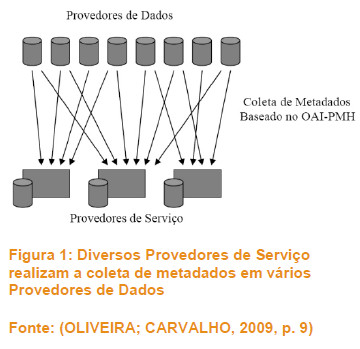

Os provedores de serviços, por meio de um sistema Harvester, realizam o harvesting, isto é, recolhem e utilizam metadados de diversos repositórios e provedores de dados que estejam em conformidade com o padrão OAI-PMH, de modo a prover condições de pesquisa aos usuários em uma única interface de busca. Madalli (2015) reitera que "a colheita de metadados depende principalmente da utilização das normas por provedores de dados. No entanto, por várias razões gestores de repositórios, ao preencher as coleções, muitas vezes não seguem padrões globais de metadados" (MADALLI, 2015, p. 93, tradução nossa). Um padrão reconhecido e adotado pela OAI-PMH é o Dublin Core, que, por sua simplicidade e eficiência, é direcionado para a descrição de registros nos softwares da família Public Knowledge Project (PKP).
4 Public Knowledge Project (PKP)
O Public Knowledge Project10 (PKP) é uma organização fundada em 1998, por John Willinsky, da University of British Columbia, que atualmente funciona pela cooperação entre diferentes instituições, a saber: Stanford University, Simon Fraser University Library, Ontario Council of University Libraries, University of British Columbia Libraries e a University of Pittsburgh Libraries. A organização visa garantir o acesso livre a pesquisas científicas por meio do desenvolvimento de softwares open source, tais como: Open Conference Systems (OCS), Open Journal Systems (OJS), Open Harvester Systems (OHS) e Open Monograph Press (OMP).
A seguir apresentaremos os softwares open source OJS e OHS, que foram estudados para viabilizar o empreendimento teórico necessário à implantação do HiLIS.
4.1 Open Journal Systems (OJS) / Sistema Eletrônico de Editoração de Revista (SEER)
O Open Journal Systems (OJS) é um software de código aberto de gerenciamento e publicação eletrônica de revistas/periódicos, desenvolvido pelo Public Knowledge Project (PKP) e lançado no ano de 2001. Sobre o software, Márdero Arellano, Santos e Fonseca (2005) comentam que "esta ferramenta contempla ações primordiais à automação das atividades de editoração de periódicos científicos, permitindo completa autonomia na tomada de decisões sobre o fluxo editorial, a publicação e o acesso por parte do editor" (MÁRDERO ARELLANO; SANTOS; FONSECA, 2005, p. 76).
O OJS, que é adotado mundialmente, automatiza os procedimentos de produção das edições periódicas, assim como provê condições para a livre circulação, a visibilidade, a indexação e o compartilhamento dos textos e registros bibliográficos. No Brasil, em 2003, o Instituto Brasileiro de Informação em Ciência e Tecnologia (IBICT) traduziu o sistema para o português, denominando-o Sistema Eletrônico de Editoração de Revistas (SEER)11.
O OJS/SEER é atualmente o sistema de publicação de periódicos científicos mais utilizado, tanto por sua simplicidade e tradição quanto pela facilidade de adesão ao protocolo OAI-PMH, que permite a sistemas habilitados para o harvesting, tal como o OHS, coletar os metadados e divulgar os registros em suas respectivas plataformas.
4.2 Open Harvester Systems (OHS)
O Open Harvester Systems é uma colheitadeira de metadados de código aberto e agregador desenvolvido pelo Public Knowledge Project (PKP), lançado no ano de 2002. Este software utiliza o protocolo OAI-PMH, que, segundo Oliveira e Carvalho (2009), "permite a coleta de diversos padrões de metadados (MODS, MARCXML e algumas variações do Dublin Core)" (OLIVEIRA; CARVALHO, 2009, p.24) dos registros bibliográficos de diferentes tipos de fontes e, assim, garante que repositórios de conteúdo semelhante possam ser interoperáveis.
O Harvester PKP foi originalmente desenvolvido para colher metadados dos periódicos que utilizam a plataforma do SEER/OJS e que já atendiam ao protocolo OAI-PMH. Atualmente, este sistema é um mecanismo ágil para recuperar, armazenar, indexar e pesquisar registros bibliográficos de diversos repositórios, desde que estes utilizem o mesmo padrão de comunicação (protocolo OAI-PMH) para possibilitar a coleta de dados.
A seguir, abordaremos os procedimentos metodológicos empreendidos para a implantação e implementação do HiLIS.
5 Procedimentos metodológicos
Para implantarmos e implementarmos o sistema HiLIS, realizamos uma série de estudos bibliográficos, a partir dos quais apresentamos anteriormente apenas alguns conceitos fundamentais. Ademais, este estudo pode ser caracterizado da seguinte forma: pelo ponto de vista de sua abordagem, como qualitativo; pelo de seu objetivo, como exploratório; e por seus procedimentos técnicos, como bibliográfico; além de utilizar também o método de pesquisa-ação. Nestes termos, temos:
• O ponto de vista da abordagem do problema desta pesquisa é considerado qualitativo porque, conforme as considerações de Lüdke e André (1986), "a pesquisa qualitativa supõe o contato direto e prolongado do pesquisador com o ambiente e a situação que está sendo investigada" (LÜDKE; ANDRÉ, 1986, p.11). Neste caso, observamos e trabalhamos com o OHS em uma instalação local e, posteriormente, em rede, para compreender o comportamento do sistema em relação a ajustes de configuração, entrada de dados, categorização e agrupamento de metadados e entradas de arquivos.
• O ponto de vista do objetivo desta pesquisa é considerado como exploratório na medida em que, de acordo com o que afirmam Cruz e Ribeiro (2004), ela "objetiva oferecer informações sobre o objeto de pesquisa e orientar a formulação de hipóteses" (CRUZ; RIBEIRO, 2004, p. 17), o que se recomenda quando o assunto pesquisado não dispõe de muitos estudos publicados. Apesar de a tecnologia Harvester não ser nova, e o uso do harvesting já ter sido apropriado pela comunidade científica dedicada à Ciência da Informação em alguns projetos, pouco se tem tratado sobre o desenvolvimento de um projeto de implantação e implementação desta tecnologia e do processo de colheita propriamente dito, inclusive em âmbito internacional. Dentre raros estudos acerca dessa temática, destacamos Fernando e Hettiarachchi (2013) e Madalli (2015). Além disso, houve um engajamento exploratório no sentido de levantar os periódicos da área da Ciência da Informação, ou de áreas transversais, que são de acesso livre e utilizam o protocolo OAI-PMH.
• O ponto de vista dos procedimentos técnicos desta pesquisa é bibliográfico, pois, segundo Muller (2013), configura-se como tal a pesquisa que "utiliza material já publicado, constituído basicamente de livros, artigos de periódicos e, atualmente, de informações disponibilizadas na Internet" (MULLER, 2013, p.108), método de que nos valemos nas buscas de correspondências entre metadados. Quanto aos procedimentos técnicos, esta também é uma pesquisa-ação, como caracteriza Thiollent (2012) as pesquisas em que há "realmente uma ação por parte das pessoas ou grupos implicados no problema sob observação" (THIOLLENT, 2012, p.21). Desse modo, tal abordagem se realizou neste trabalho, considerando as tomadas de decisões que empreendemos para a seleção dos títulos a serem indexados, os ajustes nas configurações do sistema e a elaboração de uma política de desenvolvimento de coleções.
Iniciamos os estudos conceituais para o desenvolvimento desta pesquisa em meados de 2015, enquanto os testes do OHS ocorreram em abril de 2016, utilizando uma instalação local AMPdoc12. Entre maio e junho do mesmo ano, demos início e concluímos a configuração do sistema em rede, além de realizar a carga, ou ainda, a alimentação do sistema com os registros. Em julho de 2016, com a hemeroteca já implementada, alguns acadêmicos do curso de Biblioteconomia da Universidade Federal de Rondônia (UNIR) realizaram buscas de artigos para uso em atividades em sala de aula, valendo-se do sistema, de modo a sugerir alguns ajustes em seu layout e apresentação.
Um procedimento que julgamos extremamente importante para um projeto de implantação de um sistema Harvester é a seleção de fontes de informação, isto é, de provedores de dados. A seguir apresentamos as etapas para a seleção dos provedores de dados empregados no HiLIS.
6 Etapas para seleção de Provedores de Dados
Para nortear a seleção dos provedores de dados que seriam requisitados e trabalhados pelo HiLIS para a coleta de metadados, elaboramos uma Política de Desenvolvimento de Coleção, apresentada no Anexo A. Conforme disposto na Política, a seleção de coleções do HiLIS se fixou exclusivamente em periódicos acadêmico-científicos da área da Ciência da Informação, ou de áreas transversais, de acesso livre, que utilizavam o OJS e o Protocolo OAI-PHM.
As etapas de seleção foram divididas em duas:
• Etapa 1: Identificação de periódicos da área de Ciência da Informação, ou transversais;
• Etapa 2: Identificação, entre os periódicos listados na Etapa 1, dos que são de Acesso Livre e utilizam o protocolo OAI-PMH.
Na primeira etapa, os periódicos foram levantados e planilhados junto a algumas fontes "canônicas", tais como: Base de Dados Referenciais de Artigos de Periódicos em Ciência da Informação (BRAPCI), Directory of Open Access Journals (DOAJ), Scientific Electronic Library Online (SciELO), Sistema Regional de Información en Línea para Revistas Científicas de América Latina, el Caribe, España y Portugal (Latindex) e Library and Information Science Abstracts (LISA). Em cada uma dessas bases de dados filtramos os periódicos por termos específicos da área de Ciência da Informação, localizando periódicos de arquivologia, biblioteconomia e museologia e áreas transversais, tal como detalhamos a seguir:
• BRAPCI: todos os periódicos identificados foram inicialmente selecionados;
• DOAJ: a princípio, selecionamos todos os periódicos listados nas categorias Bibliography, Library Science e Information Resources, na seção "Browse Subjects";
• SciELO: selecionamos, inicialmente, todos os periódicos da área das Ciências Sociais Aplicadas que tratassem de Ciência da Informação, Biblioteconomia, Arquivologia, Museologia, Investigação e Comunicação
• Latindex: não havia uma categorização para os periódicos indexados. Nesse caso, selecionamos, a princípio, os periódicos da seção "Nombre de la revista" que tematizassem Biblioteconomia, Informação, Documentação, Arquivologia, Museologia, buscando também suas designações em línguas estrangeiras por meio de expressões truncadas;
• LISA: a lista de periódicos indexados não é apresentada do mesmo modo que as anteriores. Para identificar a cobertura da base de dados, fizemos uma série de pesquisas com diversos termos próprios da área no campo de busca, e prospectamos os títulos das publicações. Inicialmente, selecionamos todos os periódicos dos artigos encontrados nessas buscas.
Na segunda etapa, acessamos os links coletados de modo a verificar se esses títulos faziam uso do OJS e do protocolo OAI/PHM. Para tanto, dois procedimentos foram adotados: o primeiro, que se mostrou menos eficiente, foi acessar as páginas intituladas "about", "sobre", "acerca de" ou equivalentes, conforme a origem do periódico; o segundo, que se mostrou mais eficiente, foi apagar a expressão "index" ao final do URL do periódico e adicionar a combinação "/oai", como apresentamos a seguir.

As etapas mencionadas demandaram muito tempo, e em seu decorrer somaram-se outros periódicos que não estavam indexados nas fontes "canônicas", mas foram lembrados e encaminhados por colaboradores, ou simplesmente encontrados por meio de pesquisas no buscador do Google. Além disso, uma postagem do Blog do Santarem intitulada Revistas – Ciência da Informação (com Qualis CSA)13, de autoria do Prof. Dr. José Eduardo Santarem Segundo, permitiu a identificação de outros títulos.
A seguir apresentamos os resultados dessa seleção de periódicos.
6.1 Resultados da seleção de periódicos
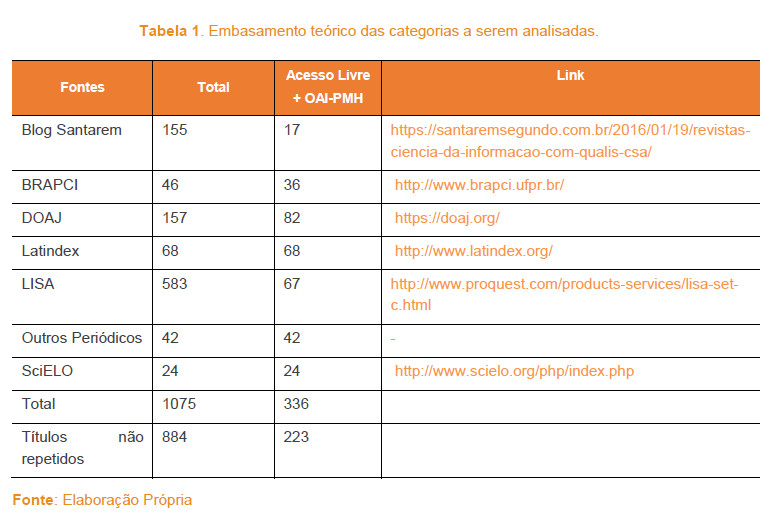
As etapas anteriores resultaram na geração de uma planilha com diversas folhas para cada fonte de informação. Essa ação foi necessária para que pudéssemos compreender quantos periódicos de cada fonte atendiam às exigências para serem selecionadas. No total, visitamos 1075 periódicos, sendo que muitos constavam em mais de uma fonte. Desse total, 223 atendiam aos critérios de coleta no HiLIS, tal como apresentamos a seguir, na Tabela 1.
Os títulos de periódicos não repetidos que atenderam aos critérios de seleção foram separados em uma folha individual na planilha, para serem reunidos pelo HiLIS após sua configuração. A configuração do harvester é apresentada a seguir.
7 Harvester in Library and Information Science (Hilis)
O HiLIS, conforme já mencionado, vale-se da plataforma OHS, e foi instalado em rede junto aos servidores da UNIR14. O nome do provedor de serviço, Harvester in Library and Information Science – HiLIS, destaca de maneira simples o tipo de fonte de informação e a cobertura da base de dados e, mais precisamente, da hemeroteca digital. Conforme as caracterizações de Rowley (2012), o HiLIS se apresenta como uma base de dados referencial, e é particularmente uma base de dados bibliográficos.
Vilan Filho e Burnier (1996) destacam que as bases de dados bibliográficas devem ter um objetivo claro. Nesses termos, elaboramos, em conjunto com a Política em Anexo, o objetivo e a missão do HiLIS, tal como segue.
• OBJETIVO
O Objetivo do portal é facilitar a pesquisa e o acesso à produção científica para acadêmicos e profissionais, em especial, das áreas de Arquivologia, Biblioteconomia, Ciência da Informação, Documentação, Gestão do Conhecimento, Gestão da Informação e Museologia. Para tanto, reúne registros das publicações em periódicos de acesso livre, no campo da Ciência da Informação e áreas relacionadas, que utilizam o protocolo Open Archives Initiative Protocol for Metadata Harvesting - OAI-PMH.
• MISSÃO
O portal tem como missão possibilitar a pesquisa e o acesso a publicações de periódicos nacionais e internacionais de acesso livre em Ciência da Informação e áreas afins, para promover o desenvolvimento e a inovação da área.


Em seguida, abordaremos alguns cuidados que julgamos essenciais na configuração do OHS.
7.1 Configurações para entrada de dados, agrupamento de metadados e categorizações (Browse)
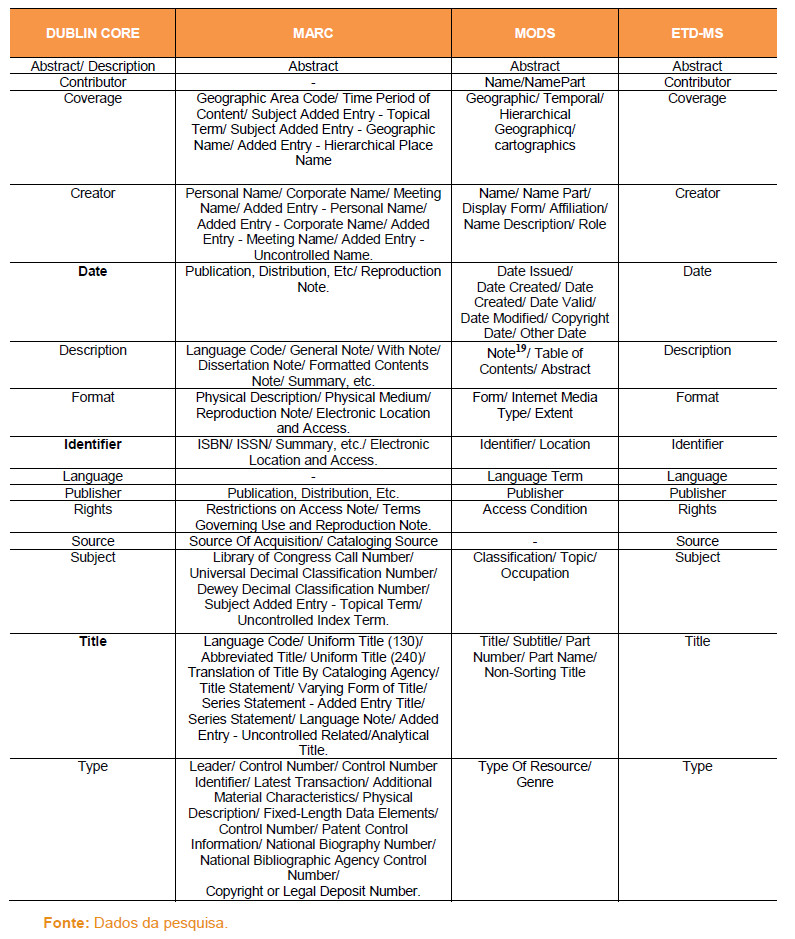
Antes de iniciarmos a entrada de arquivos, ou ficheiros, no OHS, foi preciso ajustar as configurações de entrada de dados. Essa configuração demanda estabelecer correspondências entre os diferentes conjuntos de metadados para os quais o sistema está habilitado, conforme o padrão a receber, quais sejam: Dublin Core, MARC, MODS e ETD-MS. Tais correspondências visam organizar os registros na busca Browse, por meio do Sort Orders, e agrupar os metadados para pesquisas simples ou avançadas, por meio do Crosswalks.
Na página Crosswalks foram discriminadas as correspondências entre os diferentes formatos de metadados. Para essa tarefa, apoiamo-nos nos estudos empreendidos por Alves e Souza (2007), pela Library of Congress (2012) e no site The J. Paul Getty Trust15, o que resultou na elaboração do Apêndice A - Correspondência de metadados entre os formatos Dublin Core, MARC, MODS e ETD-MS utilizado no Harvester in Library and Information Science (HiLIS).
Na página Sort Orders, algumas correspondências entre os diferentes formatos de metadados para casos específicos se repetiram, com o objetivo de estabelecer cinco categorias de busca Browse, a saber: Title, Date, Publisher, Subject e Author. Uma vez estabelecidas as configurações, pudemos iniciar a entrada de arquivos.
7.2 Entrada de Arquivos
A entrada de registros de metadados no sistema OHS se divide em duas etapas: a Add Archive e a Manage. Nesse processo, retomamos a listagem de periódicos selecionados para compor a coleção do HiLIS.
Em Add Archive preenchem-se os campos: Title, URL, Type, OAI base URL, Index Method e Metadata Format de cada Provedor de Dados, para cada periódico selecionado.
Em Manage Archive são indicados todos os Provedores de dados da coleção, para que se escolham, individualmente, quais conjuntos de dados serão importados. Esses conjuntos compõem as seções dos periódicos, tais como: Editorial; Artigos de revisão; Relatos de experiência etc. Todos os conjuntos de dados dos periódicos foram importados para compor o HiLIS e, assim, observamos que o tempo para concluir a importação varia positivamente em proporção à quantidade de registros, sendo por vezes necessário repetir o procedimento mais de uma vez.
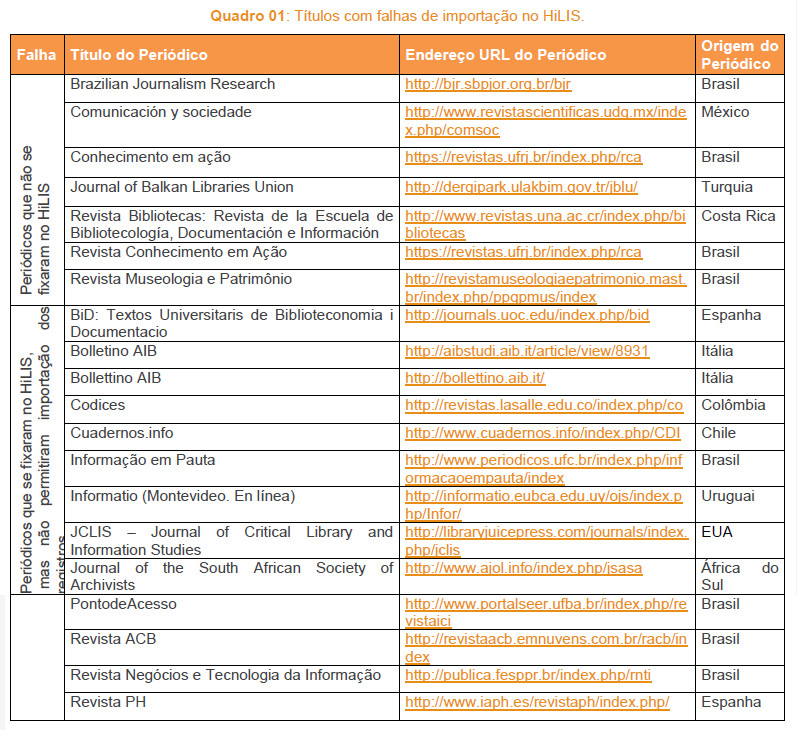
No processo de entrada de arquivos na importação de metadados verificamos erros de duas ordens, tal como apresentamos no Quadro 1:
• Periódicos que se fixaram no HiLIS, mas não permitiram importação dos registros;
• Periódicos que não se fixaram no HiLIS.
Além dessas falhas, percebemos que seis periódicos tinham títulos diferentes, porém apresentavam os mesmos endereços eletrônicos, o que ocasionou a geração de duplicata de endereços URL. Desse modo, dos 223 periódicos selecionados, o HiLIS conseguiu assimilar 197, provendo acesso a 76.464 registros bibliográficos.
Uma vez importados os registros, realizado o harvesting, observamos que foi possível identificar, com certa precisão, algumas características da coleção em termos de idioma e origem.
7.3 Características da coleção
As características da coleção foram tratadas em duas frentes, de acordo com a origem geográfica dos periódicos e, em seguida, seu idioma. Essas características, além de dizerem respeito à coleção do HiLIS, refletem em alguma medida um panorama da própria produção de conhecimento de acesso livre na Ciência da Informação em âmbito mundial.
Ao sumarizar as informações relativas à origem dos periódicos indexados no HiLIS, pudemos constatar que 34% dos periódicos são brasileiros, 10,6% espanhóis e 8,6% estadunidenses. O destaque brasileiro pode ser justificado pelo fato de os periódicos acadêmico-científicos da área, ou transversais, serem mantidos por instituições universitárias públicas ou por associações de classe profissionais sem fins lucrativos, os quais contam com corpo editorial e avaliadores voluntários, ou seja, que não cobram pelo processo editorial (exame por pares e edição) nem pelo acesso aos conteúdos. Além disso, esses periódicos em Ciência da Informação seguem um modelo de negócios voltado para as Ciências Sociais e Humanas, bem como para as Artes e Humanidades, tal como apresentado por Gumieiro e Costa (2012).
A partir das informações sobre a origem, sumarizamos as informações relativas ao idioma16 e pudemos constatar que no HiLIS são mais frequentes periódicos em português, espanhol e inglês, de tal modo que uma consulta empregando expressões nesses três idiomas poderia cobrir cerca de 80% dos registros alocados. Para verificar essa estimativa, agrupamos os países de acordo com o idioma, e assim tivemos:
• Português, utilizado no Brasil e em Portugal, configura 35% dos periódicos;
• Espanhol, utilizado na Argentina, Chile, Colômbia, Costa Rica, Cuba, Equador, Espanha, México, Peru e Venezuela, soma 28,4% dos periódicos. A seguir, apresentamos as tabelas com detalhamentos.
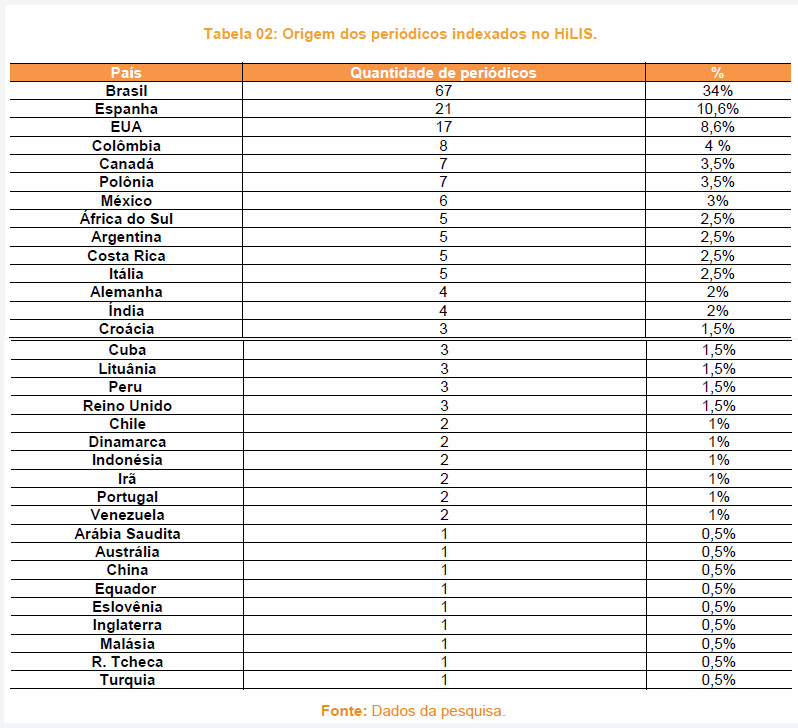
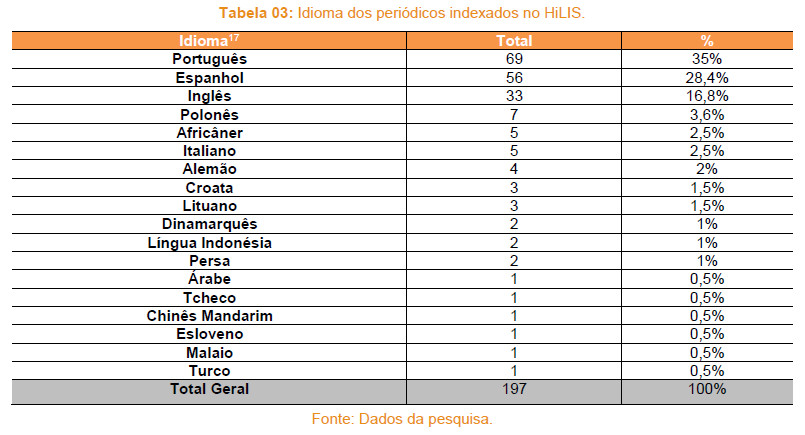
É importante destacar que esses dados consideram o idioma do periódico em relação a sua origem geográfica. Dessa forma, não assumimos, por exemplo, que 35% dos artigos publicados em acesso livre da área ou transversais à Ciência da Informação sejam em português, uma vez que é comum o aceite de trabalhos submetidos em mais de um idioma. Compreender a seleção, a origem e o idioma dos periódicos indexados no Harvester possibilita ao usuário elaborar melhores estratégias de busca, uma vez que se pode considerar a precisão ou revocação das consultas.
As possibilidades de consultas ao HiLIS dizem respeito às modalidades de recuperação da informação, sobre as quais trataremos a seguir.
7.4 Modalidades de recuperação de informação
As modalidades de recuperação de informação do HiLIS seguem as proposições de Fernando e Hettiarachchi (2013) e a estrutura própria do OHS. Desse modo, o utilizador do sistema tem acesso às modalidades de recuperação de informação por meio das pesquisas simples e avançada via Search, e da navegação via Browse.
Na aba Search, o utilizador pode realizar a busca por registros utilizando o campo All e elaborar uma estratégia de pesquisa valendo-se dos operadores booleanos, e dos recursos de truncagem e expressão exata. Também nessa aba, é possível aplicar filtros para delimitar o periódico ou especificar os campos dos metadados que serão considerados para a recuperação da informação.
Na aba Browse, o utilizador pode navegar pelos diferentes periódicos individualmente ou, ainda, pelos registros de todos os periódicos, utilizando as categorias Title, Date, Author, Publisher e Subject. A navegação é possível em virtude da configuração Sort Orders e se vale dos arranjos de correspondências de metadados.
Nos resultados da recuperação, tanto pela modalidade Search quanto pela Browse, há duas opções de acesso ao item: View Record e View Original. A primeira opção exibe os metadados do registro no próprio provedor de serviço, ou seja, no próprio HiLIS, o que é útil para a prospecção de dados a partir de aplicativos ou plug-ins macros acoplados nos navegadores web. Já a segunda opção direciona o utilizador para a página do item no provedor de dados, isto é, o periódico. Nesse caso, é preciso considerar que nem sempre os periódicos utilizam links persistentes, de modo que, com o passar do tempo, o endereço referenciado, pode ficar desatualizado.
8 Considerações finais
No presente trabalho, abordamos algumas considerações sobre a implantação e implementação de uma hemeroteca digital de periódicos de acesso livre da área de Ciência da Informação e áreas transversais, num âmbito global, utilizando o Open Harvester System e as possibilidades ofertadas pelo protocolo OAI-PMH. Para alcançar nossos objetivos, empreendemos nas páginas anteriores alguns apontamentos conceituais sobre o movimento Acesso Livre, o Open Archive Initiative – Protocol for Metadata Harvesting, o Public Knowledge Project e seus softwares, Open Journal Systems e Open Harvester System. Conforme entendemos, o Harvester é uma aplicação informática que atua como uma colheitadeira de metadados, enquanto o Harvesting é o processo de colheita que utiliza o protocolo de comunicação OAI-PMH, os quais estão encapsulados em padrões de metadados. Após isso, declaramos em nossos procedimentos metodológicos a natureza do estudo e, em seguida, abordamos as etapas de seleção de provedores de dados e a configuração dos recursos do servidor de serviço denominado Harvester in Library and Information Science (HiLIS).
A seleção dos periódicos que compuseram a coleção da hemeroteca foi norteada por uma política de desenvolvimento de coleção que delimitou a escolha exclusiva de periódicos de acesso livre habilitados para a importação de registros via OAI-PMH. Para isso, fizemos o levantamento de periódicos que atendessem às exigências disponíveis em fontes como a Base de Dados Referenciais de Artigos de Periódicos em Ciência da Informação (BRAPCI), o Directory of Open Access Journals (DOAJ), a Scientific Electronic Library Online (SciELO), o Sistema Regional de Información en Línea para Revistas Científicas de América Latina, el Caribe, España y Portugal (Latindex), a Library and Information Science Abstracts (LISA), entre outros.
A configuração e a caracterização do Harvester foram iniciadas após a seleção desses periódicos. Essa configuração abordou aspectos da entrada de dados, agrupamento de metadados e categorizações, de modo que foi necessário estabelecer correspondências entre os elementos Dublin Core, MARC, MODS e ETD-MS. Concluídas as correspondências, demos início à entrada de arquivos, isto é, o processo de harvesting, ou de coleta, dos registros dos periódicos. Nesse processo, notamos algumas falhas de prospecção, de modo que, dos 223 títulos selecionados, 198 foram carregados pelo sistema.
Com os títulos carregados na hemeroteca, foi possível identificar o Brasil como o país que mantém mais títulos de periódicos em acesso livre em Ciência da Informação e suas áreas transversais, sendo que uma consulta feita com expressões em português, espanhol e inglês, ao mesmo tempo, podem trazer a maior parte dos registros. Ainda com relação à caracterização do HiLIS, abordamos no decorrer do estudo seu objetivo, missão e modalidades de recuperação de informação.
A hemeroteca digital implementada foi testada por acadêmicos do curso de Biblioteconomia da Universidade Federal de Rondônia, que trouxeram opiniões sobre o conteúdo, a funcionalidade e a recuperação de informações. A partir daí, os próximos passos para melhorar o serviço são: a tradução do sistema para o português e o espanhol, o acréscimo de descrições e ilustrações dos ficheiros, bem como a resolução de eventuais problemas relativos aos metadados coletados. Estudos futuros poderão utilizar o HiLIS para prospecção de dados e ponderações métricas sobre o conhecimento de acesso livre produzido na Ciência da Informação, verificando, por exemplo, a articulação de redes de autores e temas nas produções dos diferentes países. É possível ainda que o presente estudo seja utilizado como base para implementar novas plataformas18, considerando também as atuais pesquisas de Andretta et al (2017) sobre as etapas para elaboração de hemerotecas digitais.
Agradecimentos
Aos professores, Wánderson Cássio Oliveira Araújo, Marcos Leandro Freitas Hübner e Joliza Chagas Fernandes, pelo acompanhamento e sugestões no decorrer desta pesquisa, as linguistas Pâmela da Silva Rosin e Clarissa Neves Conti, pela revisão dos originais.
Bibliografia
ALVES, M. D. R.; SOUZA, M. I. F. Estudo de correspondência de elementos metadados: Dublin Core e Marc 21. Revista Digital de Biblioteconomia & Ciência da Informação, Campinas, v. 4, n. 2, p. 20-38, 2007. Disponível em: < http://www.brapci.ufpr.br/brapci/v/7463 >. Acesso em: 27 mai. 2016.
ANDRETTA, P. I. S. et al. Etapas para elaboração de hemerotecas digitais utilizando o Open Harvester Systems: o caso do Harvester in Library and Information Science. In: ENCONTRO NACIONAL DE PESQUISA EM CIÊNCIA DA INFORMAÇÃO, 18, 2017, Marília. Anais… Brasilia: Associação Nacional de Pesquisa e Pós-Graduação em Ciência da informação – ANCIB, 2017. Disponível em: < http://enancib.marilia.unesp.br/index.php/xviiienancib/ENANCIB/paper/view/586/186 >. Acesso em 15 jan., 2018.
BUDAPEST OPEN ACCESS INITIATIVE. Read the original BOAI declaration. 2002. Disponível em: <http://www.budapestopenaccessinitiative.org/read> [ Links ].
CHALHUB, T.; BENCHIMOL, A.; GUERRA, C. Acesso livre via repositórios: politicas de instituições brasileiras. Encontros Bibli: Revista Eletrônica de Biblioteconomia e Ciência da Informação. Florianópolis, v. 17, n. Esp. 2, p. 159-173, 2012. Disponível em: <http://www.periodicos.ufsc.br/index.php/eb/article/view/1518-2924.2012v17nesp2p159>. Acesso em: 17 out. 2015 [ Links ]
CRUZ, C.; RIBEIRO, U. Metodologia científica: teoria e prática. 2. ed. Rio de Janeiro: Axcel Books, 2004. [ Links ]
CUNHA, M. B; CAVALCANTI, C. R. O. Dicionário de Biblioteconomia e Arquivologia. Brasília: Briquet de Lemos, 2008. [ Links ]
FERNANDO, I. D. K. L; HETTIARACHCHI, N. Installation and Customization Experience of Metadata Harvester System: Case from University of Ruhuna. Journal of the University Librarians Association of Sri Lanka, Colombo, v.17, n. 1, January 2013. Disponível em: <http://jula.sljol.info/articles/abstract/10.4038/jula.v17i1.6642/>. Acesso em: 10 mai. 2016. [ Links ]
GUMIEIRO, K. A.; COSTA, S. M. S. O uso de modelos de negócios por editoras de periódicos científicos eletrônicos de acesso aberto. Perspectivas em Ciência da Informação. Belo Horizonte, v. 17, n. 4, 2012. Disponível em: < http://portaldeperiodicos.eci.ufmg.br/index.php/pci/article/view/1489 >. Acesso em: 09 jan. 2016. [ Links ]
HARNAD, S. Entrevista com Stevan Harnad. Encontros Bibli: Revista Eletrônica de Biblioteconomia e Ciência da Informação. Florianópolis, n. Esp., p. x-xv, 1º sem. 2007. Disponível em: < https://periodicos.ufsc.br/index.php/eb/article/view/1518-2924.2007v12nesp1pvi >. Acesso em: 20 dez. 2015. [ Links ]
LIBRARY OF CONGRESS. MODS to Dublin Core Metadata Element Set Mapping Version 3. Metadata Object Description Schema (MODS). August, 2012. Disponível em: < http://www.loc.gov/standards/mods/mods-dcsimple.html >. Acesso em: 06 jan. 2016. [ Links ]
LÜDKE, M.; ANDRÉ, M. E. D. A. Pesquisa em educação: abordagens qualitativas. São Paulo: EPU, 1986. Disponível em: < http://docslide.com.br/education/livro-pesquisa-em-educacao-abordagens-qualitativas.html >. Acesso em: 24 jan. 2016. [ Links ]
MADALLI, D. P. Thematic harvesting of agricultural resources from generic repositories. Information Processing in Agriculture. Beijing Shi, v.2, n. 2, p. 93-100, September 2015, Disponível em: < http://www.sciencedirect.com/science/article/pii/S2214317315000293/pdfft?md5=aea4c553e633e6ae71fb3b87d00b34de&pid=1-s2.0-S2214317315000293-main.pdf >. Acesso em: 04 jan. 2016. [ Links ]
MÁRDERO ARELLANO, M. Á.; SANTOS, R.; FONSECA, R. SEER: disseminação de um sistema eletrônico para editoração de revistas científicas no Brasil. Arquivística.net. Rio de Janeiro, v. 1, n. 2, p. 75-82, jul./dez. 2005. Disponível em: <http://www.brapci.ufpr.br/documento.php?dd0=0000003949&dd1=d2fa6>. Acesso em: 10 jan. 2015. [ Links ]
MULLER, A. J. (Org.). Metodologia científica. Indaial: Uniasselvi, 2013. [ Links ]
NEUBERT, P. S.; RODRIGUES, R. S.; GOULART, L. H. Periódicos da Ciência da Informação em acesso aberto: uma análise dos títulos listados no DOAJ e indexados na Scopus. Liinc em revista, Rio de Janeiro, v. 8, n. 2, 2012. Disponível em: < http://dx.doi.org/10.18617/liinc.v8i2.497 >. Acesso: 19 nov. 2015. [ Links ]
OLIVEIRA, R. R.; CARVALHO, C. L. Implementação de Interoperabilidade entre Repositórios Digitais por meio do Protocolo OAI-PMH. Goiânia: Universidade Federal de Goiania. Instituto de Informática, 2009. (Relatório técnico 003-09). Disponível em < http://www.inf.ufg.br/sites/default/files/uploads/relatorios-tecnicos/RT-INF_003-09.pdf >. Acesso em: 30 jul. 2017. [ Links ]
PUBLIC KNOWLEDGE PROJECT. Harvester2: technical reference. p. 1-50, 2014. Disponível em: <https://pkp.sfu.ca/wp-content/uploads/2014/04/TechnicalReference.pdf>. Acesso em: 15 out. 2015. [ Links ]
ROWLEY, J. A biblioteca eletrônica. Tradução Antônio Agenor Briquet de Lemos. 2 ed. Brasília: Briquet de Lemos, 2012. [ Links ]
VILAN FILHO, J. L.; BURNIER, S.. Aspectos relevantes para a construção e uso de bases de dados bibliográficos. Revista de Biblioteconomia de Brasília. Brasília, v. 18, n. 2, p. 167-176, jul./dez. 1990. Disponível em < http://basessibi.c3sl.ufpr.br/brapci/index.php/article/download/17704 >. Acesso em: 30 jul. 2017. [ Links ]
THIOLLENT, M. Metodologia da pesquisa-ação. São Paulo: Cortez, 2012. [ Links ]
Dados dos autores
Adriana Bruna Silva Albuquerque
Bacharela em Biblioteconomia pela Universidade Federal de Rondônia. Atualmente atua na Biblioteca das Faculdades Integradas Aparício Carvalho.
adrianabrunaalbuquerque@gmail.com
Pedro Ivo Silveira Andretta
Professor Assistente do Departamento de Ciência da Informação da Universidade Federal de Rondônia. Mestre em Ciência, Tecnologia e Sociedade pela Universidade Federal de São Carlos e doutorando em Ciência da Informação pela Universidade de São Paulo.
Recibido - Received: 2016-06-10
Aceitado - Accepted: 2018-01-11
Apêndice A
Correspondência de metadados entre os formatos Dublin Core, MARC, MODS e ETD-MS utilizado no Harvester in Library and Information Science – HiLIS
ANEXO A
Política de desenvolvimento de coleções do Harvester in Library and Information Science – HiLIS
1 POLÍTICA DE DESENVOLVIMENTO DE COLEÇÕES
A política de desenvolvimento de coleções da hemeroteca digital Harvester in Library and Information Science – HiLIS, do Departamento de Ciência da Informação da Universidade Federal de Rondônia, tem por finalidade definir atividades e critérios para seleção, aquisição, avaliação, desbaste e descarte dos materiais informacionais que compõem o seu acervo. Seus principais objetivos são:
a) disciplinar as ações da Comissão de Desenvolvimento de Coleções;
b) estabelecer diretrizes e critérios para seleção de fontes;
c) orientar o processo de avaliação e descarte da Coleção;
2 COMISSÃO DE DESENVOLVIMENTO DE COLEÇÕES
A Comissão de Desenvolvimento de Coleções deve atuar como órgão de suporte técnico e científico e deverá ser constituído por:
a) um docente do curso do Departamento de Ciência da Informação da Fundação Universidade Federal de Rondônia eleito como presidente;
b)dois docentes do curso de Biblioteconomia, internos ou externos à Fundação Universidade Federal de Rondônia;
c) um discente, como representante dos alunos de graduação do curso de Biblioteconomia, indicado pelo Departamento de Ciência da Informação - UNIR.
Os membros da Comissão serão nomeados por meio de Portaria.
2.1 Competências da Comissão de Desenvolvimento de Coleções
Os membros da comissão têm como principais atribuições:
a) articular-se com profissionais e acadêmicos da área de Ciência da Informação, coletando sugestões para atualização do acervo e melhorias no processo de desenvolvimento da coleção.
b) analisar as solicitações de seleção de periódicos para a coleção;
c) manter atualizada a coleção, estudando e solucionando falhas na coleta de metadados;
d) deliberar sobre o descarte de periódicos da coleção;
e) avaliar periodicamente a coleção;
2.2 Princípios da Comissão de Desenvolvimento de Coleções
Os trabalhos da Comissão de Desenvolvimento de Coleções devem ter os seguintes princípios:
a) comprometimento;
b) cooperação;
c) ética;
d) trabalho em equipe;
e) transparência.
3 FORMAÇÃO DO ACERVO
A hemeroteca digital Harvester in Library and Information Science – HiLIS não fará uso de recursos orçamentários e trabalhará com um sistema open source para coletar, reunir e facilitar o acesso a publicações de acesso livre, seguindo as doutrinas da Open Archives Initiative (OAI).
O acervo disponibilizado no HiLIS será constituído apenas por periódicos de acesso livre global na área de Ciência da Informação. Nesses periódicos serão importados os seguintes dados:
a) Editoriais;
b) Bibliografias;
c) Artigos originais;
d) Artigos de revisão;
e) Pesquisas em andamento;
f) Relatos de pesquisa;
g) Relatos de experiência;
h) Resumos de monografias, teses e dissertações;
i) Normas editoriais;
j) Normas para publicação;
k) Catálogos;
l) Dossiês;
m) Resenhas;
n) Notícias;
o) Relatos de estágio;
p) Entrevistas;
q) Manuais;
r) Índices.
3.1 Fontes de Seleção
Para a seleção dos periódicos serão utilizadas fontes como:
a) diretórios de periódicos;
b) bases de dados bibliográficos;
c) listagens de periódicos especializados fornecidos por especialistas.
d) indicação da Comissão de Desenvolvimento de Coleções do Sistema HiLIS.
3.2 Critérios de Seleção
Para a seleção de periódicos que comporão a Coleção do HiLIS, devem ser observados os seguintes critérios:
a) Adesão, total ou parcial, à área de Ciência da Informação;
b) Adesão às políticas de Acesso Livre;
3.3 Critérios de Aquisição
Para a adição de periódicos e sua manutenção junto a Coleção do HiLIS, devem ser observados os seguintes critérios:
a) Adesão ao Open Archives Initiative – Protocol for Metadata Harvesting OAI-PHM
b) Utilização do método de indexação ListRecords ou ListIdentifiers;
c) Utilização dos metadados Dublin Core ou Marc;
d) Recomenda-se a atualização dos índices de metadados dos periódicos da coleção a cada dois meses.
3.4 Critérios para Descarte
O descarte de periódicos da coleção se dará nas seguintes condições:
a) Por decisão da Comissão de Desenvolvimento de Coleções;
b) Por mudanças no periódico em relação à adesão às políticas de Acesso Livre ou a inabilitação do OAI-PMH;
c) Por mudanças no endereço web do periódico.
3.5 Abordagem de avaliação
A comissão deverá proceder à avaliação do acervo do HiLIS sempre que necessário, empregando métodos quantitativos e qualitativos, a fim de obter resultados a serem analisados para assegurar o alcance de seus objetivos
4 REVISÃO DA POLÍTICA DE DESENVOLVIMENTO DE COLEÇÕES
Recomenda-se a revisão anual, ou sempre que se fizer necessário, das políticas de desenvolvimento de coleções pela Comissão, com a finalidade de garantir sua adequação à comunidade acadêmica, profissional e científica.
1 GeoColeta. Disponível em: <http://igeonidd.nuvem.ufrgs.br/geocoleta/home/index.php/index >.
2 REA Parana. Disponível em: <http://igeonidd.nuvem.ufrgs.br/geocoleta/home/index.php/index >.
3 Kollektion. Disponível em: <http://philo.at/kollektion/index.php/index >.
4 U.N.C Library. Disponível em: <http://bibliotecas.unc.edu.ar/index.php/ >.
5 Asian Journals Online. Disponível em: <http://www.journal.acs.org.au/index.php/>.
6 Base Referencial de Artigos de Periódicos em Ciência da Informação. Disponível em: <http://www.brapci.ufpr.br/ >.
7 Repertório da Produção Periódica Brasileira de Ciência da Informação. Disponível em: <http://bdpife2.sibi.usp.br/metabuscaci/ >.
8 Compreendemos como hemeroteca uma "coleção de publicações periódicas", tal como dicionarizado por Cunha e Cavalti (2008).
9 Open Archives Initiative. Disponível em: <https://www.openarchives.org>.
10 Public Knowledge Project. Disponível em: <https://pkp.sfu.ca>.
11 Sistema Eletrônico de Editoração de Revistas. Disponível em: <http://seer.ibict.br/>.
12 AMPDoc. Disponível em: <http://mblazquez.es/ampdoc-2-0/>.
13 Blog Santarem. Disponível em: <https://santaremsegundo.com.br/2016/01/19/revistas-ciencia-da-informacao-com-qualis-csa/>.
14 A versão instalada do Open Harvester Systems foi a 2.3.2, de 16 de março de 2012.
15 The J. Paul Getty Trust. Disponível em: <http://www.getty.edu/research/publications/electronic_publications/intrometadata/crosswalks.html>.
16 Há países que têm mais de um idioma oficial, como é o caso da África do Sul, Canadá, Índia e Malásia. Nesses casos, empregamos apenas o idioma mais praticado no País. Essa escolha foi necessária, levando-se em conta a cooficialidade de idiomas, a exemplo da Espanha, em que é praticado oficialmente o Espanhol e cooficialmente os idiomas Catalão, Basco, Galego e Aranês, o que criaria uma dispersão nos conjuntos. Nosso objetivo, neste trabalho, era convencionar a unidade.
17 O idioma considerado como oficial do país de origem dos periódicos não necessariamente coincide com o idioma dos artigos, uma vez que alguns periódicos tendem a aceitar artigos em diversos idiomas, e, neste caso, o periódico em questão não foi computado em nossas estatísticas.
18 Sobre a utilização de novas plataformas como Provedores de serviço, damos atenção especial ao Omeka e à seção "Ferramentas" do Portal Open Archives <https://www.openarchives.org/pmh/tools/tools.php>.
19 Nota: dentre os registros utilizados para a composição dos metadados de descrição, este foi o único que não pode ser selecionado em razão da notificação de erro de duplicata.

