











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
1. Introducción
Las técnicas de minería de textos se definen como parte de la minería de datos que tiene como objetivo extraer conocimientos de datos textuales no estructurados (Gil, 2021). Los datos textuales no estructurados se refieren a la información almacenada en formato de textos que no siguen un patrón de organización predeterminado. Uno de los tipos más comunes de datos no estructurados es el que se genera y recopila en una variedad de formas, incluidos los documentos guardados en word, los artículos publicados en los diarios nacionales y/o locales, los mensajes de correo electrónico, las publicaciones de blogs, los sitios de redes sociales y otros. Los datos estructurados se refieren a la información que se encuentran en la mayoría de las bases de datos bibliográficas que ya tienen una estructura definida como autor, título, fuente, paginación, etc. Estos datos estructurados son archivos de textos que se suelen organizar y mostrar en filas y columnas, también pueden ser ordenados y procesados fácilmente por las herramientas de minería de datos.
En el panorama actual del llamado big data, en el que una gran cantidad de datos se generan diariamente, la aplicación de las técnicas de extracción automática de conocimientos se vuelven esenciales a partir de esos textos. Para la extracción automática de conocimiento en la minería de textos se utilizan algoritmos de aprendizaje automático (del inglés, machine learning) que se aplican a los textos no estructurados y que deben pasar por una serie de transformaciones orientados a la obtención de una representación estructurada. Normalmente, esta representación estructurada de los textos se configuran como vectores espaciales, formando una matriz de documentos por términos. En esta matriz, cada fila representa un documento y cada columna representa un término presente en la colección de documentos. Las palabras se utilizan comúnmente como atributos, dando lugar a una representación denominada bolsa-de-palabras. Este formato es simple y permite el uso directo del aprendizaje automático, porque asume que los términos son independientes y no se consideran las relaciones entre los términos (Sinoara et al., 2021). Percibida de esta manera la minería de textos sería el proceso de analizar grandes cantidades de datos textuales a través de los avances logrados en el procesamiento del lenguaje natural que permitan el descubrimiento y extracción de algún aspecto pertinente dentro de una colección de textos no estructurados (Kumar, Kar & Ilavarasan, 2021). Una descripción de las etapas que lleva realizar la minería de textos puede ser consultada en Gaikwad et al. (2014) así como en Lanzarini et al. (2019).
La minería de textos no es un proceso de búsqueda de información, pues en ese tipo de búsqueda el usuario ya sabe lo que quiere, es decir, busca encontrar lo que quiere y/o necesita y lo encuentra. Ese es el proceso de recuperación de la información requerida y es el mecanismo utilizado en el análisis de textos estructurados. Ya en el análisis de textos no-estructurados, la minería de textos ayuda al usuario a descubrir informaciones desconocidas y a veces ni siquiera sospechadas por el propio usuario. Para ser más claros, la minería de textos, surgió de la necesidad de descubrir automáticamente información (patrones y anomalías) en los textos. El uso de esta tecnología permite recuperar información, extraer datos, resumir documentos, descubrir patrones, asociaciones y reglas, y realizar análisis cualitativos o cuantitativos sobre documentos de textos (Aranha y Passos, 2006; Gil, 2021; Urbizagástegui, 2021). El proceso de extracción de conocimiento implica entonces la evaluación e interpretación de los patrones o modelos obtenidos en la etapa de minería de datos, pues el lenguaje natural que las personas utilizan cotidianamente refleja de alguna manera las situaciones sociales y las relaciones interpersonales que se entablan con los demás agentes sociales; como la percepción y la visión de las contiendas cotidianas en la escena política y social de un país.
Por los motivos apuntados anteriormente, el presente artículo tiene como objetivo aplicar las técnicas de minería de textos para analizar los editoriales del periódico peruano La República publicados desde el 5 de mayo hasta el día 6 de junio de 2021, fechas en las que se llevaron a cabo las campañas políticas de la segunda vuelta electoral para ocupar la presidencia del Perú. Se pretende obtener información relevante orientada a entender el uso de las terminologías comunicadas a través del lenguaje escrito en ese periódico. La importancia de realizar este tipo de estudio radica en el potencial que tiene las técnicas de minería de textos para filtrar la visión que tienen los sujetos que construyen y comunican los embates antagónicos de la realidad social nacional. De ese modo, este estudio se centra en la búsqueda de la lógica del conocimiento práctico cuya forma de expresión empleada es el lenguaje objetivado, en este caso, en los editoriales publicados y comunicados por el periódico La República.
No se debe olvidar que “El editorial es el género periodístico que refleja más claramente la línea ideológica del periódico y así la hace pública” (Linares et al., 2014, p. 144); y que además es:
Un espacio de debate mediatizado [que] se encuentra en las páginas editoriales de los periódicos nacionales […]. En esta sección, la prensa escrita sostiene posiciones ideológicas e intenta influir en la agenda política. El editorial de un diario puede ser considerado como un género, ya que da cuenta de una manera particular de representar el mundo (discurso) y de configurar las identidades sociales (estilo). Específicamente, se trata de un texto sin firma a través del cual un medio de comunicación manifiesta su postura frente a temáticas de interés público, constituyendo un objeto de análisis de enorme valor para identificar las relaciones dialécticas que permiten el movimiento de significados y los procesos de mediación social”. (Cárdenas et al., 2017, p. 21).
Citando diversas fuentes López (2016) sostiene que un editorial es un artículo que expresa la opinión de un periódico; explica que los editoriales presentan las opiniones de los periódicos como organizaciones colectivas y las opiniones de sus editores. Por lo tanto, puede generalizarse la idea de que los medios periodísticos suelen expresar una línea o tendencia editorial imparcial; sin embargo, como mencionan Núñez y Vázquez (2008)
La obligación de imparcialidad es relativa al tratamiento de la información, pero no es incompatible con la expresión de la opinión y, con ello, con la definición de una tendencia o línea editorial. La línea editorial o tendencia requiere una actitud uniforme en la toma de posición sobre los temas principales o de fondo. Hay que distinguir, pues, entre las distintas tendencias que el periódico puede adoptar o expresar a partir de los principios que se aplican al tratamiento de los temas de fondo, la elección política en el debate democrático y el comentario del acontecer. (p. 265).
Teniendo en cuenta que el impacto en la sociedad y la trascendencia práctica del oficio del periodismo en las sociedades democráticas está directamente ligado a las figuras de “libertad de opinión” y “el derecho a obtener una información veraz”, se exige que los conceptos se separen nítidamente, al menos, desde un punto de vista teórico” (Núñez, 2007). Sin embargo, el propósito de una editorial sería muy variado, ya que:
se define un punto de vista, se crea una opinión en el público sobre un suceso determinado, se analiza y se interpreta una noticia, se relaciona un suceso concreto con otros y se establecen juicios de valor que crean actitudes en una comunidad. (Moreno, 2003, p. 231).
Los medios de comunicación se han convertido pues, en un medio eficaz para influir en la ideología de las personas al dirigir la elección de las palabras y su presentación en el contenido. En el caso de la política, los medios de comunicación, especialmente los editores de los editoriales crean argumentos persuasivos que favorecen su postura política, plantean y defienden una tesis que transmite su postura sobre un tema controvertido y que suele estar relacionado con el interés público (Al Khatib et al., 2016). La idea de que el periodismo no opera como un simple vehículo de información está siendo explorado con mayor énfasis en la literatura de las ciencias de la comunicación; esta idea sugiere que el contenido ofrecido a las masas de lectores está influenciado por las preferencias políticas y el marketing, especialmente cuando se trata de los editoriales de los periódicos locales (Eberwein et al., 2015).
Concordando con estas argumentaciones las preguntas de investigación que orientan este trabajo son las siguientes: ¿Cómo los editoriales de La República construyeron y difundieron los embates políticos en las últimas elecciones presidenciales?, ¿Fueron estos términos neutrales e imparciales?, ¿Puede la minería de textos ayudarnos a entender estos embates políticos?
Para responder a esas interrogantes y los objetivos propuestos, este documento está organizado de la manera siguiente: después de una breve introducción y establecimiento de los objetivos del artículo, se ofrece un marco teórico de la minería de textos aplicados a los estudios relacionados con los editoriales de un periódico o áreas cercanas a este asunto. Luego se describe la metodología, es decir, las unidades de análisis, la forma de recolección de los datos y la forma de medición de los mismos. Se presentan los resultados obtenidos y se exponen las conclusiones. Finalmente se lista la bibliografía que se empleó para la redacción de esta investigación.
2. Marco referencial
Las representaciones sociales son interpretaciones del mundo social que se elaboran colectivamente lo que es fundamental para que las personas pueden interactuar en el espacio social. Todos los aspectos que envuelven la vida de un sujeto, incluyendo el momento histórico-social en el que el sujeto está inmerso son formadores de las representaciones sociales que este mismo individuo se formulará respecto de los fenómenos sociales que forman parte de su contexto. Estas representaciones sociales se crean vía el proceso de anclaje y objetivación que sirven para darle familiaridad a lo desconocido; con lo cual, las representaciones sociales intervienen en una situación concreta en el que se sitúan los individuos y los grupos mediante la comunicación que se estabecen entre ellos, por intermedio del marco conceptual proporcionado por su bagaje cultural, los códigos, valores e ideologías relacionadas con posiciones sociales ya establecidas. Las representaciones sociales son entonces producidos y formados en situaciones específicas (Moscovici, 1976, 2001, 2008). Este anclaje y objetivación se comunica a los demás vía el lenguaje oral o escrito, en el caso de los editoriales del diario La República de forma escrita, que es el objeto de análisis de este trabajo.
El análisis de textos utiliza técnicas del área del procesamiento del lenguaje natural, aplicadas a la minería de textos, que es una rama de la inteligencia artificial centrada en el diseño de métodos y algoritmos que toman como entrada y/o producen como salida datos en la forma de lenguaje humano. La exploración del procesamiento del lenguaje natural comienza aproximadamente por la década de 1950 con la llamada prueba de Turing que enuncia que si una máquina llegara a ser capaz de engañar a los seres humanos, haciéndose pasar por humana, con la misma facilidad con que un ser humano puede engañar a otro, entonces esa máquina tendría que ser considerarla como inteligente (Turing, 1950). Lo que se sugiere con esta afirmación es que debe existir alguna ligación entre las múltiples disciplinas para poder afrontar la tarea de comprender los procesos de comunicación humana y poder replicarlos en una computadora, pues el lenguaje natural se distingue de otros lenguajes artificiales por la riqueza de su vocabulario, así como por sus construcciones gramaticales y la multiplicidad de interpretaciones del sentido final del texto. Esta técnica de minería de textos está siendo explorada en muchos campos académicos y científicos.
Por ejemplo, Pollak et al. (2011), pensaron que una comparación de diferentes artículos periodísticos mostraría las discrepancias entre la cobertura noticiosa local (keniana) y la internacional (occidental), que puede explicarse en parte en términos de ideología. Para probar esta hipótesis, utilizaron la minería de textos para estudiar el uso del lenguaje en los informes periodísticos sobre las elecciones de Kenia de diciembre de 2007 y la consiguiente crisis postelectoral. Tomaron sus datos de los editoriales de los periódicos kenianos Daily Nation y The Standard en contraposición a los periódicos británicos y estadounidenses The Independent, The Times, The New York Times y The Washington Post. La minería de textos encontró que la principal diferencia entre la prensa occidental y la local radicaba en el encuadre. En los periódicos británicos y estadounidenses, fueron creados un marco tribal mientras que los diarios de Kenia optaron por un marco sociopolítico. Los medios occidentales cuando explicaron los conflictos en Kenia vieron estos conflictos principalmente como una animosidad tribal o luchas por el poder entre tribus. Sin duda, muchos de los conflictos posteriores a las elecciones generales de 2007 tuvieron un aspecto étnico, pero siempre los conflictos sociales son más complejos.
Yuan (2016) intentó detectar y cuantificar los sesgos de los diarios en China. Para ese efecto, extrajo una matriz de términos versus documentos de los artículos sobre el XVIII Congreso del Partido Comunista Chino realizado en noviembre de 2012, de 21 periódicos chinos de siete provincias, así como de el Diario del Pueblo. Para esta matriz, utilizó la agrupación jerárquica para dividir los periódicos en dos grupos. Usando el dendrograma y las diferencias entre los grupos, pudo construir un índice para indicar la dirección y la magnitud del sesgo de los medios. En la muestra, los periódicos de Zhejiang y Guangdong constituyen un grupo y el resto constituyen otro grupo. La principal diferencia de los medios chinos se refleja en dos dimensiones: central/local y política/económica.
Nava y Marques (2019) realizaron un estudio longitudinal sobre la forma en que se construyó y representó la imagen pública de Lula Da Silva en los editoriales del diario O Estado de São Paulo durante las cinco campañas presidenciales en las que participó representando al Partido de los Trabajadores (años 1989, 1994, 1998, 2002 y 2006), para verificar si esta imagen cambió o se mantuvo igual a lo largo de las campañas. Los resultados del estudio evidencian que los términos más asociados y recurrentes a Lula resaltan características negativas, siendo relacionado a Brizola y a la extrema izquierda en la campaña de 1989 o asociado como un opositor menor a su competidor Fernando Enrique Cardoso en las elecciones de 1994, sin embargo, en 1998 ambos vuelven a enfrentarse siendo el foco de atención las propuestas económicas dada la coyuntura de crisis en el país. El estudio concluye que estos editoriales del diario O Estado de São Paulo se mostraban adversas a la candidatura de Lula Da Silva durante todas las campañas presidenciales, este posicionamiento casi no tuvo variaciones.
Para Bykov (2020), la “democracia y los derechos humanos” no configuran (temas/conceptos) clave en las políticas públicas de Rusia ya que los discursos presidenciales suelen centrarse en tres ejes comunes: Rusia, estado y Poder. En esta investigación el autor busca describir la evolución de la agenda política de una Rusia postsoviética y para ello analiza, a través de la minería de texto, los discursos políticos realizados por Boris Yeltsin (1994), Vladimir Putin (2000 y 2018) y Dimitry Medvedev (2008) a la Asamblea Federal de Rusia. Se sugiere que esta técnica puede ser aplicada para el estudio de textos políticos y automatizar investigaciones de lingüística política.
En una investigación sobre los editoriales de los periódicos en Japón realizada por Kaneko et al. (2021), se concluye que el análisis de texto asistido por computadora basado en el aprendizaje automático no supervisado, puede ser una técnica útil y en crecimiento para investigar diversos temas que usualmente aparecen en los medios de comunicación pero que se muestran ideológicamente divididos.
En el Perú, una descripción de las características discursivas de la línea editorial del diario Correo durante la segunda vuelta de las elecciones presidenciales del 2011, a partir del análisis de la sección central de 20 ediciones del diario, fue realizada por Suarez (2013). La observación del género de opinión en las páginas editoriales de los diarios La República y Diario Uno en la campaña política presidencial, del 1 al 15 de abril del 2016, fue desarrollada por Argumedo (2016). El tratamiento informativo sobre la vacancia de Pedro Pablo Kuczynski en marzo del 2018 fue estudiado por Quispe (2019). También, un análisis morfológico y de contenido de 30 noticias de las ediciones digitales del diario Expreso y La República con relación al tratamiento periodístico sobre la disolución del Congreso en 2019 fue elaborado por Tineo (2020).
Como se puede apreciar en la literatura revisada, y hasta donde es de conocimiento de los autores del presente artículo, la minería de textos no ha sido tomada como herramienta para analizar los editoriales del diario La República.
3. Metodología
Este estudio se basa en la teoría de las representaciones sociales y se centra en la búsqueda de la lógica del conocimiento práctico, cuya forma de expresión es el lenguaje objetivado en los editoriales publicados y comunicados por el diario La República. Para la recolección de los datos, se copió cada editorial publicada en cada uno de los días del diario La República desde el 5 de mayo hasta el 6 de junio de 2021, día de las elecciones en segunda vuelta, y se guardaron en el folder creado con el nombre Republica. En total se copiaron y guardaron 33 editoriales, los cuales sirvieron como subsidios para el análisis de las palabras como representaciones sociales de conocimiento comunicados a los lectores del diario en mención. Luego se procedió a la preparación de los datos para que los algoritmos de la minería de textos no separen los nombres propios, por ejemplo, para que reconozcan nombres como Pedro Castillo y no Pedro por un lado y Castillo por el otro. Igualmente, Keiko Fujimori y no Keiko por un lado y Fujimori por otro lado. También para los nombres propios de todas las personas mencionadas en los editoriales, así como los nombres de los partidos políticos nacionales, las instituciones y las organizaciones.
El software utilizado para análisis fue la versión 4.0.5 de R y 1.4.1 de RStudio, siendo elegidos porque son softwares que contienen recursos para el análisis de minería de textos y porque son gratuitos. Además, cuentan con un amplio abanico de funciones y se puede mejorar con el uso de nuevos paquetes, es decir, son programas potentes para el análisis de textos.
Los editoriales del periódico normalmente no se encuentran en un formato adecuado para la extracción de conocimiento, es necesario aplicar métodos de extracción e integración, transformación, limpieza, selección y reducción del volumen de estos datos, antes de la etapa de minería de textos. La integración significa obtener datos de los diversos editoriales (son 33 editoriales) y luego unificarlos, formando una única fuente de datos. La transformación es la idoneidad de los datos para su uso en algoritmos de extracción de datos. Luego viene la limpieza de la información que consistió en eliminar cualquier elemento que no sea texto (puntuaciones, fechas, números, etc.), eliminar espacios en blanco innecesarios y convertir todos los textos a minúsculas. Además, se eliminaron palabras que no aportan significado a los textos desde el punto de vista analítico (artículos, adverbios, etc.), así como algunas otras palabras que no aportan significados en este contexto en particular los llamados stopwords.
Todo este proceso fue realizado utilizando diversos paquetes de R (ver anexo) como tm y readtext. Para la remoción de los stopwords se utilizó el paquete SnowballC. Para la visualización de las frecuencias de los términos identificados se utilizaron los paquetes ggplot2. Estos mismos paquetes se utilizaron para visualizar las asociaciones o correlaciones entre los términos elegidos como interesantes. Ya para trazar las asociaciones entre las palabras se utilizaron los paquetes graph y grid. Para crear la nube de palabras se utilizaron los siguientes paquetes: RColorBrewer, wordcloud y wordcloud2. Los paquetes fpc y cluster se utilizaron para crear el dendrograma, validar y estimar las agrupaciones y finalmente realizar la agrupación de clústeres en torno a los términos más frecuentes. Este paquete contiene además funciones para el análisis de conglomerados y la medición de los datos; por eso se usó en este trabajo para hacer un gráfico cusplot más ajustado a los datos. Finalmente, para trazar otros gráficos como barras, redes de las palabras más representativas utilizadas en los editoriales de La República se utilizaron los paquetes igraph, textplot y glasso. El proceso de organización, limpieza de los datos, así como el tratamiento de los textos están resumidos en la Figura 1.
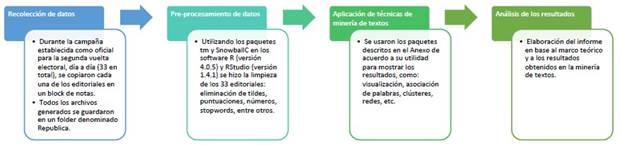
4. Análisis de los resultados
En los 33 editoriales de La República se encontraron 3089 palabras diferentes. Para mostrar aquellas palabras cuya frecuencia de aparición fueron mayor a 10 veces, se construyó la Figura 2. Se aprecia que “candidato” (1.8%), “electoral” (1.6%) y “país” (1.6%) son las palabras más utilizadas en el periodo de estudio.
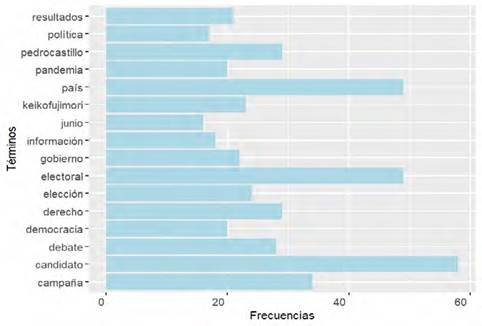
Igualmente las palabras “keikofujimori”, “pedrocastillo”, “resultados”, “elección”, “democracia”, etc., tienen coherencia con la coyuntura política del momento y muestran la representación mental que el editorialista de La República tenía sobre los embates políticos del periodo en estudio. Sin embargo, no es posible olvidar que en la práctica social, esas representaciones mentales están orientadas a la producción de efectos sociales; a producir y reproducir lo que aparentemente designan como una realidad objetiva pero son apenas representaciones mentales de actos de percepción y apreciación en la que el editorialista invierte sus intereses y estrategias de manipulación simbólica que funcionan como signos, emblemas o estigmas pero también como poderes políticos.
La extracción de asociaciones de palabras (ver la Figura 3 y 4) se basa en las relaciones gramaticales entre las palabras presentes en los textos que hace uso de las dependencias temáticas para expresar e identificar informaciones referenciales entre argumentos sintácticos. Sirve para medir las relaciones entre las palabras presentes en los 33 editoriales de La República develando patrones de percepción inherentes a las estructuras semánticas que emergen de la relación entre las principales unidades léxicas extraídas. De esa manera se conforman descriptores con alto grado de asociación entre sí, representado las inquietudes centrales de la percepción del editorialista acerca de la coyuntura política vivida en el momento.
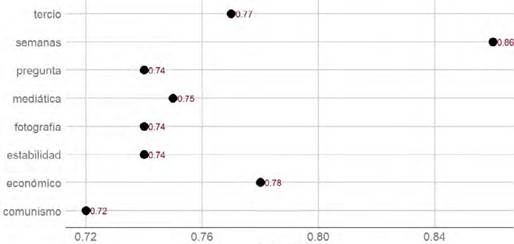
Estas asociaciones de palabras pueden mostrar una asociación positiva, negativa o neutral. Para mostrar con qué palabras se asocia al candidato Pedro Castillo se construyó la Figura 3. A un nivel de correlación de Pearson positiva mayor a 0.7, se le asocia al candidato con la palabra “semanas” (r = 0.86), refiriéndose a las pocas, escasas semanas que quedan para el día de las elecciones y a las semanas previas para ese día. La palabra “tercio” (r = 0.77) se refiere a que casi un tercio de los votantes oscila entre no acudir a votar, votar en blanco o votar nulo, pero que al mismo tiempo si acuden a votar un tercio de la población lo haría porque no quieren que el fujimorismo vuelva al poder; es el llamado antivoto que persigue al fujimorismo.
Las palabras “mediática” (r = 0.75), “pregunta” (r = 0.74) y “fotografía” (r = 0.74) son asociados a Pedro Castillo debido a que las encuestas de opinión solían preguntar por los motivos que un desconocido, que utilizaba un lápiz como símbolo de campaña y que al inicio no aparecía en los primeros lugares, logró llegar a la segunda vuelta frente a una rival con una fuerte operación mediática, con bombardeo masivo en paneles y redes sociales; esta derrota paulatina conforma una fotografía del momento. Sin embargo, lo más destacable de estas asociaciones giran en torno a las palabras “económico” (r = 0.78), lo cual era una de las preocupaciones centrales respecto a su candidatura, ya que el candidato se relacionaba con el “comunismo” (r = 0.72), lo cual traería como consecuencia una falta de “estabilidad” (r = 074) en diversos planos.
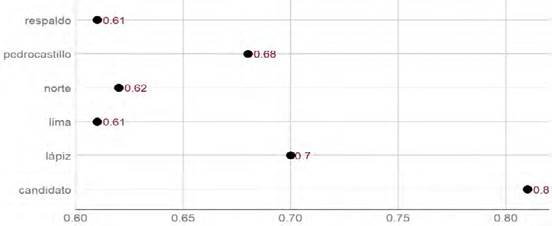
Para el caso de la candidata Keiko Fujimori (Figura 4), las asociaciones se determinaron a nivel de correlación de Pearson positiva mayor a 0.6, resultando que las palabras con mayor nivel de asociación son “candidato” (r = 0.8), seguida de “lápiz” (r = 0.7) y muy cerca también “pedrocastillo” (r = 0.68); es decir, La República muestra a Keiko Fujimori como “candidato” y la relaciona con su contendor Pedro Castillo cuyo símbolo era el “lápiz”. La palabra “respaldo” se refiere a las organizaciones políticas que anunciaron el apoyo a la candidatura del fujimorismo; a las encuestas de opinión donde los sectores socioeconómicos D y E (medio bajo y bajo) respaldan mayoritariamente la candidatura del fujimorismo; se sostiene que los candidatos tendrán que convencer a aquellos que ya decidieron su voto, pero que aún pueden cambiar de opinión para que los respalden. Las palabras “norte” (r = 0.62) y “Lima” (r = 0.61) se refiere a las macrozonas donde la candidata Keiko Fujimori obtiene mayor respaldo: en el norte del país y en el norte de Lima.
Se puede observar una diferencia entre las palabras que se asocian a uno y otro candidato. Mientras que para Pedro Castillo se presentan temas específicos del quehacer político y social, a la candidata Keiko Fujimori se le asocia con su contendor y el respaldo que recibe en determinadas regiones del país, mostrando así un tratamiento diferenciado y venal.
Es preciso señalar que en el caso de Pedro Castillo se tomó (convenientemente para el estudio) una correlación de Pearson 0.7 ya que en este nivel la correlación mostraba asociaciones con una cantidad de términos adecuados para el análisis. Si se tomaba una correlación mayor a 0.6 las asociaciones aumentaban a un elevado número de términos poco útiles para el análisis. Para el caso de Keiko Fujimori, cuando se usó un nivel de 0.7 la cantidad de términos asociados mostraba apenas un término, por eso fue más conveniente para el análisis usar una correlación mayor a 0.6. Es por esta razón, que no visualizamos en la Figura 3 la correlación entre ambos candidatos a pesar que esta se evidencia en la Figura 4.
Se denomina red semántica al esquema que permite representar la estructura de la red de palabras mediante un gráfico donde se representan los nodos y lazos de las palabras mostrando además la significación de los conceptos relacionados. Los conceptos, expresados a través de la palabra, surgen en un contexto social histórico en la forma de representaciones mentales de significados siendo parte del sujeto que la emite como un ser que está en la historia y en un espacio social cambiante. Ese espacio social es el lugar donde las relaciones sociales se articulan con saberes, visiones, percepciones, sueños o ficciones del emitente. Es en este espacio complejo donde se realiza el poder que el lenguaje representado ejerce sobre los agentes en comunicación y se busca la transformación en algo que otorga nuevas posibilidades de saberes, visiones, percepciones de tal manera que este modela una especie de compromiso con la acción transformadora de la sociedad.
La Figura 5 muestra la red de palabras de los editoriales de La República y sus vinculaciones, siendo el valor 0,24 para determinar las redes de relaciones de las palabras más utilizadas. El grosor de las líneas que unen a las palabras indica una mayor o menor relación. El centro de las preocupaciones de los editoriales del diario La República giran en torno a Keiko Fujimori y Pedro Castillo como candidatos, lo que expresa la coyuntura política del momento.
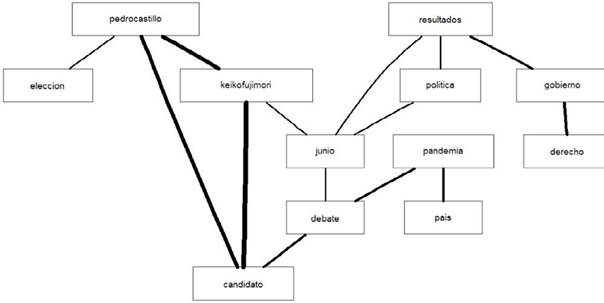
Por otro lado, se observa una relación fuerte entre ambos candidatos, así como entre las palabras “resultados” y “gobierno”. En menor medida, se aprecia una relación entre las palabras “candidato”, “debate”, “pandemia” y “país”, lo cual tiene bastante significancia ya que es uno de los temas presentes en el discurso. También podemos apreciar una relación fuerte entre “candidato”, “debate” y “pandemia”, “país” y “pandemia”, lo cual tiene bastante significancia ya que era uno de los temas presentes en los debates entre los candidatos. Obsérvese que la palabra “elección” sólo está relacionada con “pedrocastillo”. La palabra “junio” funciona como puente en esta red, es una palabra clave en la red, porque opera como mecanismo de comunicación con todas las otras palabras de la red. Junio es también el mes de las elecciones, por eso su importancia en la red.

Se configuró el programa para que muestre una nube de palabras, con un máximo de 30 palabras que estén presentes en el corpus con una frecuencia mínima de 3 veces, la variación en el tamaño y el color de las palabras indican su mayor frecuencia. Se observa que las palabras “candidato” y “elección” son las que más se repiten en los editoriales, mientras que “educación”, “peruanos”, “expresión”, “político”, “voto”, “vuelta” y “presidencial” aparecen con el mismo color y en menor tamaño, es decir, son las que se presentan con menor frecuencia. R también nos permite hacer bigramas y trigramas de acuerdo a las necesidades del investigador y mostrarlas en barras o nube de palabras como se muestra en la Figura 6. Para realizar la nube de palabras de bigramas, es decir, grupos de dos palabras, se configuró el corpus con una frecuencia de 15 y que muestre un máximo de 36 grupos de palabras. Resaltan, “proceso electoral” y “segunda vuelta”, seguido de “campaña electoral” y “candidato pedrocastillo”. Ello tiene una gran concordancia con la coyuntura del periodo en estudio.
El dendrograma es una representación gráfica de estructura arborescente de dependencia que muestra las distancias y las similitudes entre elementos. Agrupa en base a la similitud de sus características a dos individuos en un grupo, también llamado clúster. Los diversos clúster se van formando hasta formar uno solo que contiene la totalidad de los mismos. Así mismo, muestra la distancia entre los clúster. Los clústeres se representan mediante líneas horizontales, mientras que las líneas verticales (altura) representan las distancias, es decir, la altura en que se unen dos grupos es la distancia entre ellos, por tanto, a mayor altura, mayor diferencia. También, si el investigador desea, se pueden formar determinados número de grupos, los cuales se muestran en forma rectangular. La Figura 7 muestra el dendrograma de tres agrupamientos jerárquicos de las palabras más utilizadas en los 33 editoriales de La República.
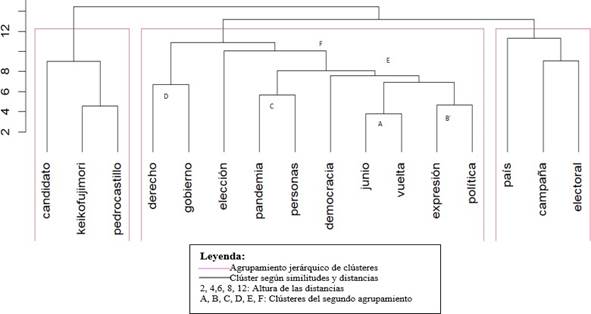
En el primer agrupamiento lo componen el clúster “keikofujimori” y “pedrocastillo” con “candidato”. El segundo agrupamiento, se observa en un primer nivel el clúster (A) formado por “junio” y “vuelta”. En un en un nivel inmediatamente superior, se unen “expresión” y política (clúster B) seguidos por “pandemia” y “personas” (clúster C) y finalmente, “derecho” y “gobierno” (clúster D). Un paso siguiente engloba el clúster A y B con “democracia” (clúster E). Siguiendo las agrupaciones, el clúster E junto con el C y la palabra “elección” forman el clúster F. Finalmente, el clúster D y F forman este segundo gran agrupamiento. El tercer agrupamiento está conformado por el clúster formado por las palabras “campaña” y “electoral” más la palabra “país”.
Al igual que en los otros gráficos, se aprecia una coherencia entre los términos agrupados con la coyuntura del periodo en estudio. En los grupos extremos presentan, por un lado a “keikofujimori” y “pedrocastillo” con la palabra “candidatos”, efectivamente los dos estaban en disputa; en el otro extremo, las palabras “campaña”, “electoral” y “país”, que representa como uno de los temas relevantes de aquel momento. El agrupamiento central, también se aprecia una coherencia como en el clúster A con las palabras “vuelta” y “junio”, ya que en este mes se realizó la segunda vuelta que definió al presidente. Igual, el caso de “pandemia” y “personas”, pues eran los temas de preocupación; así sucesivamente podemos observar las relaciones.
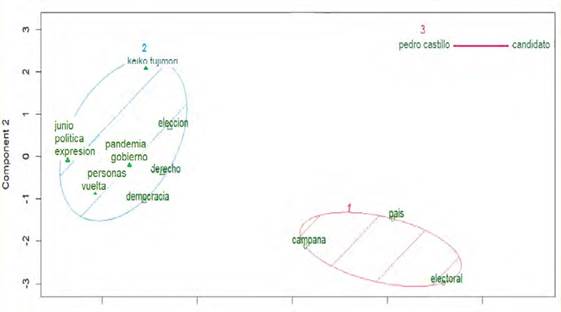
En la figura 8, se muestran los tres componentes identificados por el método de Ward. Estos representan el 95% de la variabilidad de los datos. Se aprecia que “pedrocastillo” y “candidato” son las palabras (variables) más representadas y con un alto rango por el tercer componente. Del mismo modo, “keikofujimori” es la palabra más representativa y con un alto rango por el segundo componente. Sin embargo, las otras palabras que conforman el segundo componente (“elección”, “derecho”, “gobierno”, “pandemia”, “personas”, “democracia”, etc.) así como, las palabras “país” “campaña” y “electoral” del primer componente, tienen baja proporción y representatividad en los editoriales del diario La República.
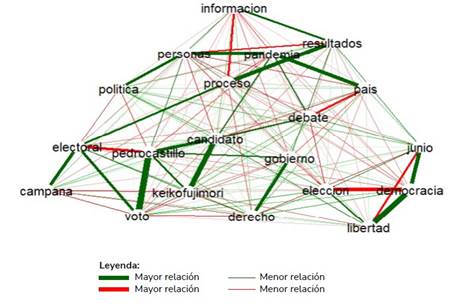
Uno de los temas centrales del análisis de textos es la identificación de los conceptos de interés y la identificación de las relaciones que se producen entre estos conceptos lingüísticos. En la Figura 9 se aprecia las diferentes relaciones entre las 20 palabras más representativas rescatadas de los editoriales. Se observa que la palabra “candidato” tiene una relación mayor con “keikofujimori” -se define por el grosor de la línea-, también se relaciona con “pedrocastillo”, lo cual se asemeja a lo obtenido en las asociaciones de palabras con el término “keikofujimori” (Figura 4), donde “candidato” tiene un mayor nivel de asociación, a su vez está con “debate”, conformando un espectro de preocupaciones de la escena política nacional vivida en el momento del proceso electoral. Otra relación fuerte se aprecia entre las palabras “gobierno” y “derecho” así como entre “proceso” y “resultados” y entre “democracia” con “libertad’’. Otro grupo se centra en los resultados del proceso, que está vinculado a las elecciones del mes de junio. Este gráfico nos demuestra que en los editoriales de La República, durante el periodo de estudio, el tema principal fue la segunda vuelta electoral para elegir nuevo presidente.
5. Discusión y conclusiones
En breve tiempo y con bajo costo -ya que se utilizó software libre Rstudio-, se analizaron los editoriales del diario La República publicados del 5 de mayo al 6 de junio de 2021, es decir, durante la campaña electoral hacia la segunda vuelta electoral para la elección presidencial. Los 33 editoriales en estudio produjeron 3089 términos con una dispersión del 95% y la palabra de mayor longitud tenía 28 letras. Mediante las diversas técnicas de minería de textos se ha podido obtener los términos utilizados y sus relaciones, lo cual es importante ya que “quien ignore los principios editoriales de la empresa informativa y no sepa qué persigue o pretende puede ser juguete en manos del informador, y el desconcierto o la ignorancia serán el resultado de unos principios editoriales no formulados con claridad” (Edo, 1994, p. 170). En los primeros resultados del análisis se observa que las palabras que aparecen con mayor frecuencia y que a su vez tienen mayor relación son “pedrocastillo”, “candidato” y “keikofujimori”. A Pedro Castillo se le presenta con temas específicos del quehacer político y social mientras que a la candidata Keiko Fujimori se le asocia con su contendor y se le confiere un tratamiento distinto. Los términos más utilizados están relacionados a la coyuntura electoral, como son “candidato” y “elección”, términos que más se repiten en los editoriales, así como “proceso electoral” y “segunda vuelta”, que de hecho coinciden plenamente con el momento político efervescente que se vivía en esos días.
Pedro Castillo aparece como candidato del partido político Perú Libre cuyo símbolo es el lápiz pero no sucede lo mismo con el partido Fuerza Popular y su candidata Keiko Fujimori. Esta mención puede deberse a la importancia que le dan los medios de comunicación al partido Perú Libre y a lo que representa como ideología de extrema izquierda. Esto se ve reflejado también en los resultados obtenidos de las asociaciones de la palabras donde se aprecia una relación entre “pedrocastillo” y las palabras “comunismo” a un nivel del 0.72%, “estabilidad” (0.74%) y “económico” (078%).
Considerando que, “los medios de comunicación masiva elaboran sus propias representaciones sociales sobre diversos temas, hechos o personas y es el sujeto o grupo al que se pertenece, expuestos a los medios de comunicación, los que pueden rechazarlas o incorporarlas” (Cuevas, 2011, p. 5) y teniendo en cuenta que a los medios de comunicación se les considera como el cuarto poder por su influencia en los asuntos sociales y políticos, se observa cómo en los editoriales del diario La República se presenta a “keikofujimori” como “candidata” con “respaldo”, mientras que a su contendor “pedrocastillo” se le relaciona más intensamente con las palabras “económico”, “comunismo” y “estabilidad” pero sugiriendo más bien inestabilidad económica. Es decir, se representan de diversa manera a cada uno de los candidatos, lo que pudo haber influenciado en la reacción de los votantes.
Las aparentes verdades políticas, especialmente en un momento crítico como son las elecciones políticas, lleva a olvidar que los productos lingüísticos son también representaciones mentales específicas de este espacio social particular que es el periodismo, y que esas representaciones lingüísticas que son los editoriales cumplen funciones políticas, conscientes o inconscientes, y evidencian sus preferencias. Este es el caso del diario La República.

