










Servicios Personalizados
Revista

Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO  uBio
uBio
Compartir

 Permalink
PermalinkRevista Peruana de Biología
versión On-line ISSN 1727-9933
Rev. peru biol. v.19 n.1 Lima abr. 2012
COMENTARIOS
Revisión de índices de distribución espacial usados en inventarios forestales y su aplicación en bosques tropicales
Review of spatial indices used in forest inventory and their application in tropical forests
Alicia Ledo*1, Sonia Condés1, Fernando Montes2
1 Escuela Técnica Superior de Ingenieros de Montes. Universidad Politécnica de Madrid. Ciudad Universitaria, sn. 28040 Madrid, Spain
2 CIFOR-INIA. Ctra. de La Coruña km 7.5, 28040 Madrid Spain
* alicialedo@gmail.com
Resumen
En este trabajo se hace una revisión de los diferentes índices utilizados para describir y caracterizar la estructura horizontal o patrón espacial en masas forestales con especial énfasis en aquellos que se han aplicado para el estudio de bosques tropicales. Estos índices se han clasificado en función del tipo de datos requerido para su cálculo. Diferentes aspectos del comportamiento estadístico y la aplicabilidad de aquellos índices más usados (los índices de Fisher y Morisita, el análisis de la varianza en escalas anidadas y la técnica SADIE de entre las técnicas que utilizan datos de densidades o coberturas en unidades de muestreo; los índices de Clark-Evans, Pielou y Byth-Ripley basados en medidas de distancias entre árboles; y las funciones L(d) y O-ring que requieren para su cálculo la posición de todos los arboles) se analizan en un caso de estudio a partir de datos de parcelas experimentales un bosque tropical andino.
Palabras clave: índices de diversidad, estructura forestal, patrón espacial, biodiversidad, bosques de niebla, Andes, Perú.
Abstract
This paper reviews the different indices used to describe and characterize the horizontal structure or spatial pattern in forest stands, with particular emphasis on those which have been applied to the study of tropical forests. These indices have been classified according to their data-inventory requirements. A number of aspects concerned with the statistical properties of the most commonly employed indices (Fisher and Morisita indices, LQV techniques and SADIE in the quadrats group; Clark-Evans, Pielou and Byth-Ripley in the nearest-neighbour group; The empirical L(d) and O-ring functions in the mapped data group) and their applicability to tropical stands, have been tested in experimental plots located in an Andean tropical forest.
Keywords: diversity index, forest structure, spatial pattern, biodiversity, cloud forest, Andes, Peru.
Introducción
El inventario forestal es una herramienta necesaria para el conocimiento del monte, y la planificación de cualquier recurso requiere en primer lugar de un conocimiento del mismo (Madrigal 2002). Tradicionalmente, los trabajos de inventario forestal se realizaban con fines orientados a la producción. Al surgir nuevas demandas de utilidades de los sistemas forestales por parte de la sociedad, se han ido incorporando nuevos objetivos a los inventarios, como la estimación y valoración de la biodiversidad, estimación de bienes ambientales y estado de conservación de los ecosistemas; de hecho, las medidas de biodiversidad ya aparecen en los principales inventarios europeos (Alberdi et al. 2005). El estudio de la estructura horizontal y vertical de las masas arboladas se incluye como una parte importante en el análisis de la biodiversidad (Staudhammer & LeMay 2001). La estructura horizontal en una masa forestal viene determinada por la distribución en el espacio de los árboles o patrón espacial. Para estudiar el patrón espacial en un monte, la técnica más habitual es comparar la distribución de pies presente con una distribución que se toma de referencia, normalmente la distribución aleatoria o de Poisson, pudiendo el patrón real desviarse de la distribución de referencia como consecuencia de una mayor agregación de los árboles o de una distribución regular de los mismos. Cada uno de estos patrones observados revela una historia forestal distinta, responde a unas causas (Legendre 1993) y también genera ciertas consecuencias (Halpern & Spies 1995). La importancia de la distribución espacial de los árboles también se pone de manifiesto al elegir la técnica selvícola apropiada para aplicar los diferentes métodos de ordenación (Vincent et al. 2003), pues la selvicultura influye en la organización de los árboles (Montes et al. 2004) y es importante saber cómo puede afectar la estructura de la masa al desarrollo de la misma (por ejemplo, cómo afecta la estructura de los pies maduros al regenerado, para poder así favorecer la regeneración natural ofreciendo las condiciones necesarias).
Para el estudio de la distribución espacial se han desarrollado muchos índices, que se han ido incorporando a los inventarios para caracterizar la biodiversidad. Estos índices se pueden clasificar (teniendo en cuenta el tipo de datos que utilizan para su cálculo o la metodología empleada) como métodos basados en la varianza, que utilizan datos en unidades de muestreo; métodos basados en cálculos de distancias, que requieren de la medida de distancias o ángulos, y técnicas del momento de segundo orden, que requieren para su cálculo datos de la posición de todos los árboles.
En bosques tropicales la realización de inventarios para cuantificar los recursos forestales es relativamente reciente y todavía no se ha generalizado su uso. En parte, debido a que las zonas tropicales se encuentran es su mayoría en países con recursos más escasos que no invierten tanto ni en sector forestal ni en investigación y control. Por otro lado, los bosques tropicales son de mayor complejidad estructural y con un mayor número de especies presentes que implican una mayor variabilidad y da lugar a masas más heterogéneas cuyo estudio es más complicado (Pélissier & Goreaud 2001). Muchos de estos bosques ven en la actualidad amenazada su persistencia, y aunque recientemente se han realizado inventarios exhaustivos en algunas zonas tropicales, esta información no es utilizada por gestores o ecologistas (Steege et al. 2006). Los procesos ecológicos que intervienen en la persistencia de los bosques tropicales y en el mantenimiento de su elevada diversidad son aún desconocidos.
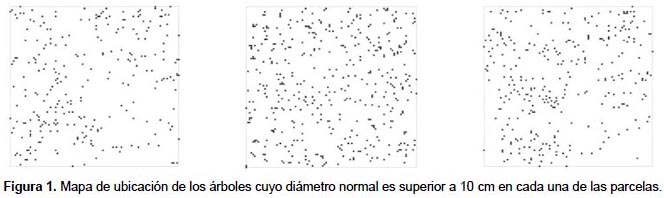
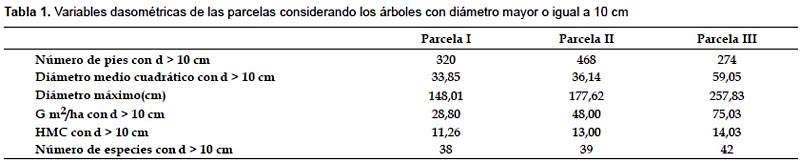
En este trabajo se presenta una revisión de las técnicas existentes para caracterizar el patrón espacial en inventarios forestales, ofreciendo ejemplos de aplicación en masas tropicales. La aplicabilidad y problemática de las técnicas más comúnmente empleadas se analiza en tres parcelas cuadradas de 1 ha cada una instaladas en un Bosque de Niebla Montano conocido como "Bosque de Neblina de Cuyas", situado en la vertiente pacífica de los Andes en el norte de Perú, provincia de Ayabaca, en la región de Piura. Las coordenadas UTM del área de estudio oscilan entre UTM 642700-644300 este y 9493300-9490499 sur, zona 17S. Datum WGS84, variando la altitud desde 2659 a 3012 m, la pendiente es por lo general mayor al 30%. En estas parcelas se han medido las posiciones de todos los árboles (Fig. 1) y se han calculado las principales variables de masa (Tabla 1). Los bosques de niebla son formaciones estructuralmente complejas, y son ecosistemas muy vulnerables que se encuentran en la actualidad muy amenazados a nivel global (Hamilton et al. 1994).
Índices de aplicación en unidades de muestreo
Las unidades de muestreo son sub-regiones discretas del espacio consideradas como muestras representativas de la población total. En los inventarios forestales son generalmente parcelas donde se mide la densidad de alguna variable o se hace un simple conteo de elementos, como puede ser la estimación de la cobertura o el conteo del regenerado. Analizar el valor de varianza de la variable medida en las parcelas indicará la presencia de uno u otro patrón espacial.
Algunos de los índices incluidos en este grupo no tienen ningún requerimiento respecto a la forma o tamaño de las unidades, otros requieren que las parcelas sean de la misma forma y tamaño y en último caso, requieren que las parcelas sean cuadradas y contiguas. Los índices de este grupo se recogen en la Tabla 2.

Unidades de muestreo no necesariamente contiguas.- El primer índice de este grupo fue el propuesto por Fisher y sus colaboradores (1922) este cociente es también conocido como índice de Cox (1971) o de Strand (1953), y permite analizar el patrón espacial a partir del ratio entre la media y la varianza de la variable entre parcelas. Otros índices dentro de este grupo son los índices de agregación de David y Moore (1954), de Douglas (1975) y de Lloyd (1967) y el índice de dispersión de Southwood (1978), aunque el más utilizado es el de Morisita (1959) (Tabla 2). Como se puede observar en la Figura 2a, el índice de Fisher presenta una mayor variación que el índice de Morisita. De hecho, para alcanzar la misma precisión con ambos índices, con el índice de Fisher se deben incluir más parcelas que con el de Morisita (Fig. 2b). La parcela 1, en la que el índice de Morisita muestra mayores errores, presenta una menor densidad, lo que parece indicar que el índice de Morisita da resultados más fiables en masas densas, mientras que el índice de Fisher presenta un comportamiento más estable en aquellas parcelas con una disposición más regular de los pies (Figs. 1 y 2b). Una de las características de este tipo de índices es su dependencia del tamaño de la unidad de muestreo. En la Figura 3 se muestra el valor de ambos índices en función de la dimensión del lado de la unidad de muestreo, apreciándose la gran variación del valor del índice según el tamaño de parcela elegido.
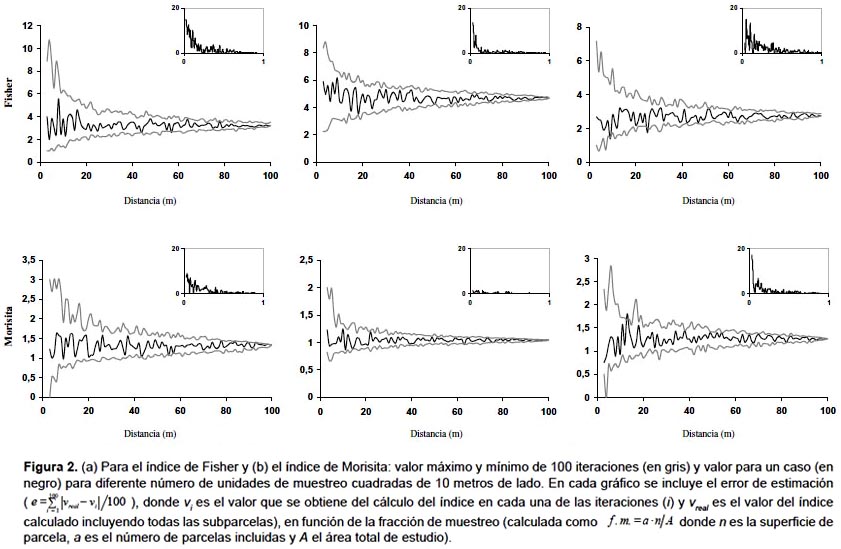
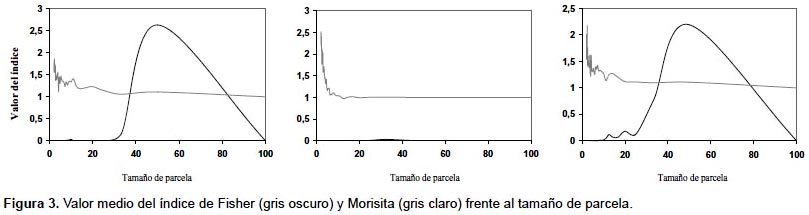
La capacidad de estos índices para detectar el patrón espacial depende de la escala a la que se presenta el patrón espacial y del tamaño de la unidad de muestreo. En las tres parcelas analizadas, el índice de Morisita refleja un patrón muy agregado cuando se tienen unidades de muestreo muy pequeñas, presentando un valor relativamente estable que muestra una ligera tendencia a la agregación para unidades de muestreo de mayor tamaño (Fig. 3). El índice de Fisher, por el contrario, no refleja el patrón agregado con unidades de muestreo de pequeño tamaño o cuando el número de árboles es muy grande, como en la parcela II.
El índice de Morisita se ha utilizado en el estudio del patrón de árboles en un bosque en la India, considerado en parcelas primero de 1 ha y luego de 0,25 ha todos los pies con diámetro normal mayor a 10 cm (Parthasarathy & Karthikeyan 1997); también para estudiar la disposición espacial de las especies de sotobosque y su relación con los huecos en un bosque en Costa Rica, haciendo transectos donde se miden todos los árboles con altura menor a 60 cm (Richards & Williamson 1975) y para caracterizar la estructura forestal en un bosque de Chile, con parcelas 50 x 60 m subdivididas en subparcelas cuadradas contiguos de 3 x 3 m donde registran todos los árboles con una altura mayor a 2 m (Veblen 1979).
Unidades de muestreo contiguas y cuadradas.- Cuando se dispone de información de densidad o cobertura en unidades de muestreo cuadradas contiguas (quadrats) pueden emplearse técnicas para caracterizar el patrón espacial a partir del valor que toma la varianza en función del tamaño de la unidad de muestreo, incrementando sucesivamente el tamaño de la unidad de muestreo anidando las unidades iniciales en unidades de mayor tamaño (Greig-Smith 1952). El tamaño de cuadrícula en que la varianza es mayor indica la escala característica del proceso que se está analizando. Keshaw (1960) usó este método, al que bautizó como blocked quadrat covariance, estudiando el patrón de pares de especies, proponiendo representar la varianza en función del tamaño del bloque. Hill (1973) publicó los primeros métodos denominados term local quadrat variance (TLQV), en los que se calcula la varianza entre unidades de muestreo contiguas. Estas técnicas se han ido consolidando para analizar el patrón espacial en trabajos posteriores (Besag & Diggle 1977; Galiano 1983; Mead 1974; Renshaw & Ford 1984). Un estudio detallado de todo este conjunto de índices y su desarrollo aparece en el libro de Dale (1999). El trabajo de Roxburgh y Chesson (1998) presentó una modificación, en él se analiza la interacción entre el patrón espacial dos especies, y también tienen potencialidad para estudiar variables presencia/ausencia e integrar análisis multiespecies (Dale 1999).
En la Figura 4 se muestran las funciones 4 term local quadrat variance (4TLQV) y 9 term local quadrat variance (9TLQV) para las parcelas representadas en la Figura 1. Se puede ver en la Figura 3 que en las tres parcelas ambas funciones presentan un máximo de varianza poco después de los 10 metros, que estaría señalando la distancia de agregación de los árboles en las parcelas.
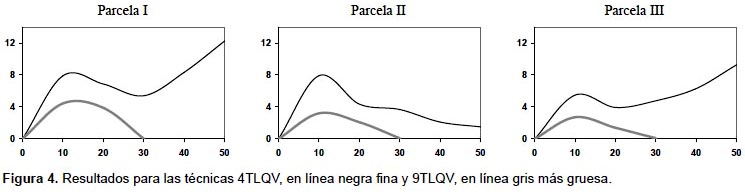
Dentro de esta categoría está también la técnica Sadie (Spatial Analisis by distancie indices) desarrollada por Perry (1998), técnica que asume una hipótesis nula simulada de regularidad, y mide el patrón de agregación como el "esfuerzo" (distancia) que tendrían que hacer los elementos de cada unidad de muestreo para que al desplazarse a las unidades contiguas se llegara a una distribución aleatoria en todo el área. Se calcula un índice de agregación Iδ que indica las zonas con mayores grados de agregación (valores mayores a 1) y las áreas regulares (valores menores a 1). Es frecuente hacer una interpretación visual del mapa resultante para detectar las diferentes zonas en cuanto a la agregación de las plantas (Fig. 5). El uso los índices de este apartado es más común en el estudio de coberturas, abundancias o variabilidad de los datos que en inventarios forestales clásicos y no se encuentran en estudios en bosques tropicales salvo algunos casos, como en el estudio de varianzas anidadas para ver las escalas a las que ocurren las diferentes estructuras espaciales en una selva en Malasia, caracterizando la estructura en parcelas de 5 x 5 m; 10 x 10 m y 20 x 20 m y estudiando los resultados obtenidos para los diferentes tamaños de parcela (Bellehumeur et al. 1997).

Unidades de muestreo no necesariamente de misma forma o tamaño ni contiguas.- Dentro de este grupo de índices en los que se compara la varianza entre las diferentes unidades de muestreo, se encuentran el índice de Moran (1950) y el de Geary (1954) (Tabla 2). Se han empleado en el estudio de riqueza de especies en la Amazonía ecuatoriana, tanto sobre imágenes (Sandler et al. 1997) como sobre datos de campo (Müller-Starck & Schubert 2002); en el estudio de las diferentes coberturas del suelo en un bosque en Senegal (Gourbiere & Debouzie 1995) y en el estudio de la distribución espacial del regenerado en un bosque en la Guayana Francesa (Julliot 1997).
Dentro de este grupo también se encuentran técnicas para medir la correlación espacial de una variable: el análisis espectral bidimensional, el wavelet analsisys, la dimensión fractal, los variogramas, , correlogramas, series de Fourier, LISA (local index of spatial association), triangulaciones, modelos espaciales autoregresivo, incluso otros estadísticos más sencillos como aplicación de ajustes a modelos de probabilidad o simplemente un test de la χ2 usado exitosamente por Greig-Smith (1964). Información detallada sobre todas estas técnicas se encuentra en Creesie (1993) y Ripley (1981). La aplicación de estos índices es frecuente en el estudio de vegetación del suelo o coberturas, solo ocasionalmente se han utilizado para analizar el patrón de los árboles.
Índices basados en medidas de distancias
Estos índices requieren medir en campo la distancia o ángulo desde un árbol aleatorio al árbol o árboles más cercanos, o desde un punto aleatorio al árbol más cercano o ambas medidas simultáneamente, por lo que se suelen denominar métodos del vecino más cercano. Los índices más comúnmente utilizados dentro de este grupo se recogen en la Tabla 3.
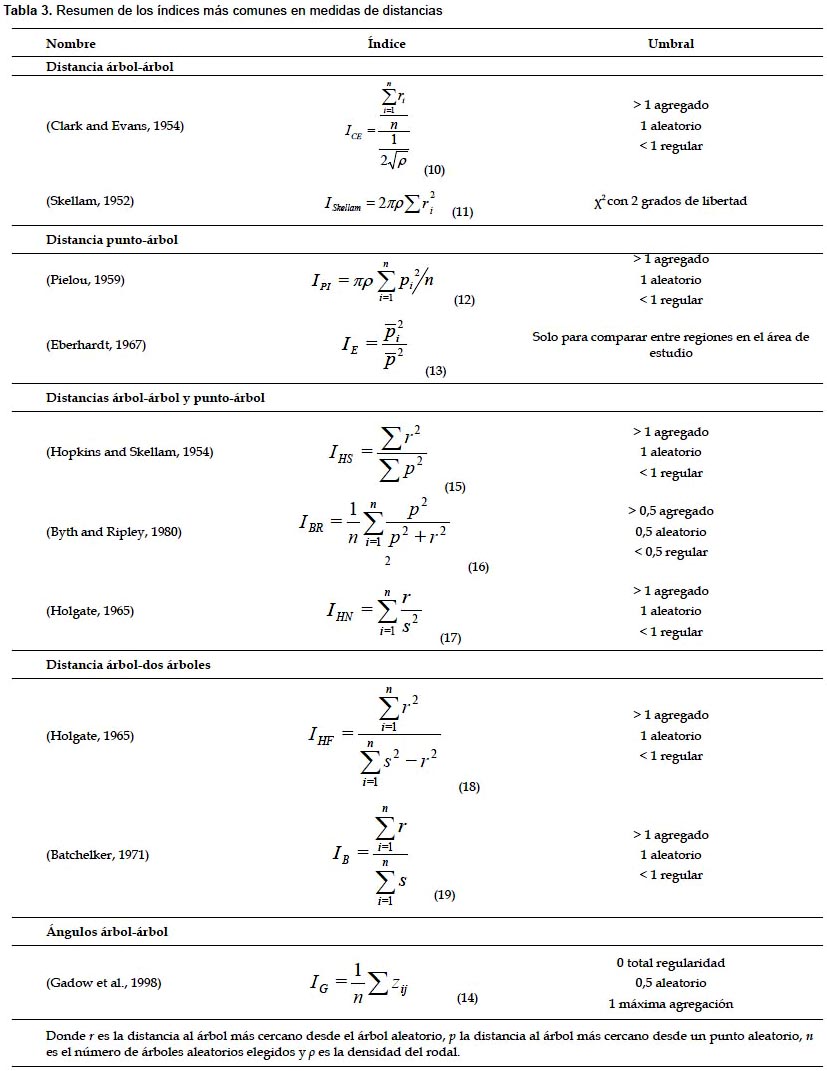
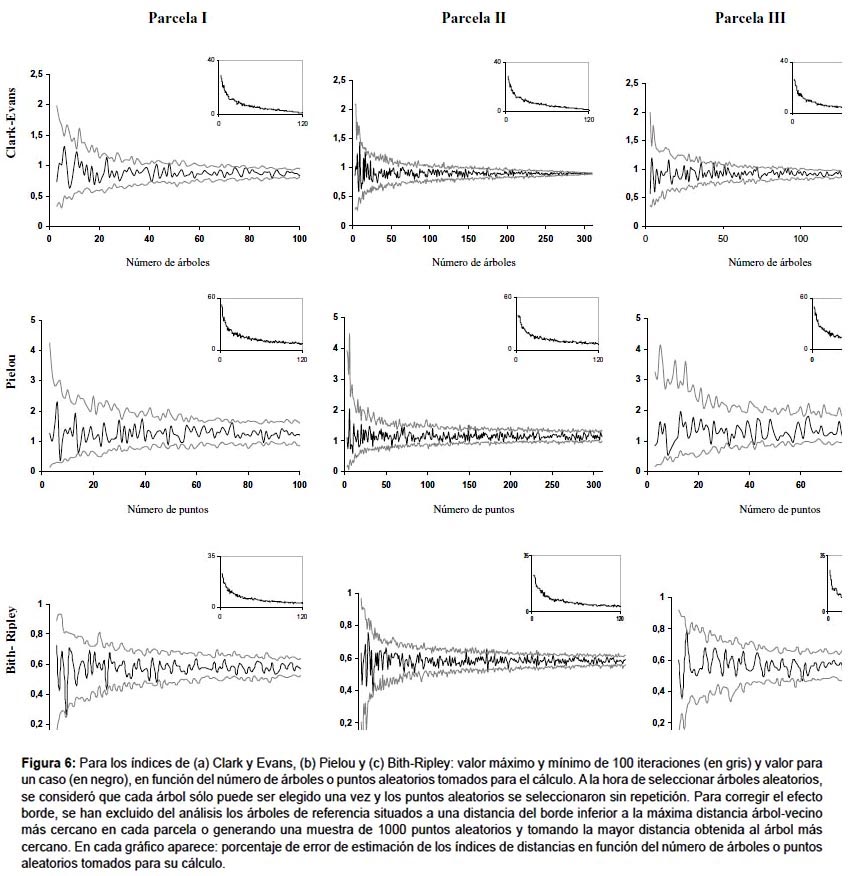
Distancia árbol-árbol entre un árbol aleatorio y su vecino más próximo.- El índice más extendido dentro este grupo es el índice de Clark y Evans (1954). Este índice compara datos de densidad de población (estimada o conocida) con la muestra de los datos de distancias de un árbol a su vecino más próximo. Otro índice parecido, pero menos robusto, es el de Skellam (1952) (Tabla 3). La precisión de estos índices depende del tamaño de muestra de distancias entre árboles vecinos tomada, como muestra la Figura 6. En este ejemplo, para obtener un error menor del 10% se necesitan un mínimo de 25 árboles en la zona de estudio para el índice de Clark y Evans (Fig. 6a).
El índice de Clark y Evans se ha aplicado en el estudio del patrón de árboles muertos en Costa Rica, calculando la distribución espacial de los árboles muertos en 3 parcelas de diferente edad de la masa de 12 ha cada una (Lieberman et al. 1985), en el estudio de diversidad y estructura de la selva de Tutulia en tres parcelas permanentes de 1,2 ha (Webb & Fa'aumu 2004) o para estudiar el patrón espacial de los huecos, aplicando el índice considerando el centro de cada hueco como un punto, en una parcela de 9 ha (Ward & Parker 1989). Dentro de este grupo también se han propuesto índices que utilizan las distancias desde un árbol aleatorio dentro de la parcela a los dos árboles más próximos. Los más destacables son los dos índices propuestos por Holgate (1965) y el índice de Batchelker (1971). Estos índices presentan el inconveniente de requerir un inventario aún más complejo, y han tenido una difusión y aplicación escasas.
Distancia punto-árbol desde un punto aleatorio de la parcela al árbol más próximo.- El más extendido es el índice de Pielou (1959) (Tabla 2), que examina la presencia de regularidad o agregados comparando con una distribución normal de media 1 y varianza 1/n.
Este índice, a pesar de haber sido el más utilizado para estudiar la estructura horizontal en masas forestales, es menos estable asintóticamente que el de Clark y Evans (Fig. 6), siendo necesarios 70-90 árboles para obtener errores por debajo del 10% en el ejemplo analizado (Fig. 6b). El índice de Pielou se ha aplicado para analizar la estructura de la masa en un bosque en la India, con 90 parcelas de 0,1 ha (Reddy et al. 2008), o estudio de la diferente estructura entre estratos de vegetación en un bosque subtropical en Japón (Hagihara et al. 2008).
Otro índice que utiliza la distancia de puntos al azar al árbol más próximo, de uso mucho menos extendido que el de Pielou, es el índice de Eberhardt (1967), presenta el problema de que su valor es relativo y por tanto no comparable entre diferentes bosques.
Cociente entre distancias árbol-árbol y punto-árbol.- El índice desarrollado por Hopkins y Skellam (1954) postula que si la distribución es aleatoria, la distancia entre puntos al azar y el árbol más cercano, debe ser igual a la distancia entre árboles. Este índice fue modificado por Byth y Ripley (1980) y aunque no es de extendida aplicación en áreas tropicales, es un índice con buenas propiedades para estudiar la distribución espacial de los árboles (Condés & Martínez-Millán 1998), de hecho, en las tres parcelas analizadas este fue el índice, dentro de los que utilizan medidas de distancias, que presentó un comportamiento más estable (Fig. 6), siendo preciso tomar 20 árboles con sus puntos para alcanzar un nivel de error inferior al 10% (Fig. 6c).
Ángulo árbol-árbol entre un árbol aleatorio y su vecino más próximo.- En este grupo está el índice de uniformidad de ángulos propuesto por Gadow y colaboradores (1998), que permite caracterizar el patrón espacial midiendo únicamente los rumbos de un árbol aleatorio a sus vecinos más próximos, y comparando los ángulos reales con el ángulo de referencia que se obtendría en una distribución regular, en caso de considerar cuatro vecinos Gadow propone un ángulo de referencia de 72 grados. Su uso no es muy extendido, pero se ha utilizado en el análisis de la estructura en un bosque subtropical de Mongolia (Lima et al. 2006) y para evaluar estructura espacial en sabanas (Graz 2006).
Índices que requieren conocer las posiciones de todos los árboles
Este grupo de técnicas utilizan estadísticos de segundo orden que describen la estructura de la correlación espacial del patrón de puntos (Wiegand & Moloney 2004) basados en la distribución de distancias entre pares de puntos (Ripley 1981) y aumentando la distancia de análisis. Son muy útiles para estudiar la estructura horizontal a diferentes escalas. En las últimas décadas el uso de estas técnicas se está incrementando (Wiegand & Moloney 2004) y es común su utilización para caracterizar el patrón espacial en masas tropicales, como en la red CTFS (http://www.ctfs.si.edu/group/About/) donde se está haciendo el seguimiento de parcelas de 25-50 ha en diferentes bosques del planeta. En general, el empleo de estas técnicas requiere que el patrón espacial sea homogéneo e isotrópico en la escala de estudio (Ripley 1981).
Técnicas basadas en el momento de segundo orden.-
Funciones acumulativas. Sin duda la más conocida es la función K(d) de Ripley (Ripley 1977), que evalúa el número medio de árboles alrededor de cada uno de los diferentes árboles en función de la distancia, permitiendo caracterizar el patrón espacial a diferentes escalas:
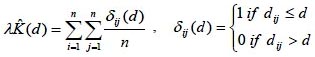
siendo dij la distancia entre dos árboles. En la práctica la función se calcula para un cierto número discreto de distancias d. El efecto borde se puede corregir reemplazando δij(d) por el inverso de la fracción de circunferencia con centro en el punto i y radio dij contenida en la parcela (Ripley 1977). Ecuaciones explícitas para esta corrección del efecto borde en diferentes casos se pueden encontrar en Creesie (1993) y en Goreaud y Pélissier (1999. Se recomienda además que la distancia máxima de análisis no supere la mitad del lado más corto de la parcela (Ripley 1981).
En la práctica la función se calcula para un cierto número discreto de distancias d. La función K(d) se suele utilizar como función test, generándose un número suficientemente elevado de simulaciones (generalmente 99 o más) de un modelo nulo, que suele consistir en una distribución completamente aleatoria (H0 ≈ SCR-complete spatial randomness) y se compara la función empírica con los cuantiles (normalmente 2,5% y 97,5%) del modelo nulo. Cuando la función empírica alcanza valores superiores al modelo nulo a una determinada distancia, implica la existencia de un patrón espacial en agregados significativo a esa distancia y si por el contrario aparece por abajo, implica la existencia de un patrón espacial regular a esas distancias.
La modificación de la función K(d) propuesta por Besag conocida como L(d) (Besag en la discusión de Ripley, 1977) es más comúnmente utilizada porque estabiliza la varianza y porque su interpretación visual es más fácil:
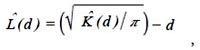
En la Figura 7a se puede ver la función empírica para las parcelas de la Fig. 1. Como se puede observar, la parcela 1 presenta un patrón en agregados desde los 2 a los 42 m., no mostrando desviaciones significativas de una distribución aleatoria en el resto de distancias analizadas, la parcela 2 solo presenta agregación significativa a escalas cortas, hasta 5 m., tendiendo a la regularidad a distancias mayores a 35 m. La parcela 3 tiene un patrón en agregados hasta distancias de 35 m, no presentando diferencias significativas respecto a la distribución al azar para distancias mayores.
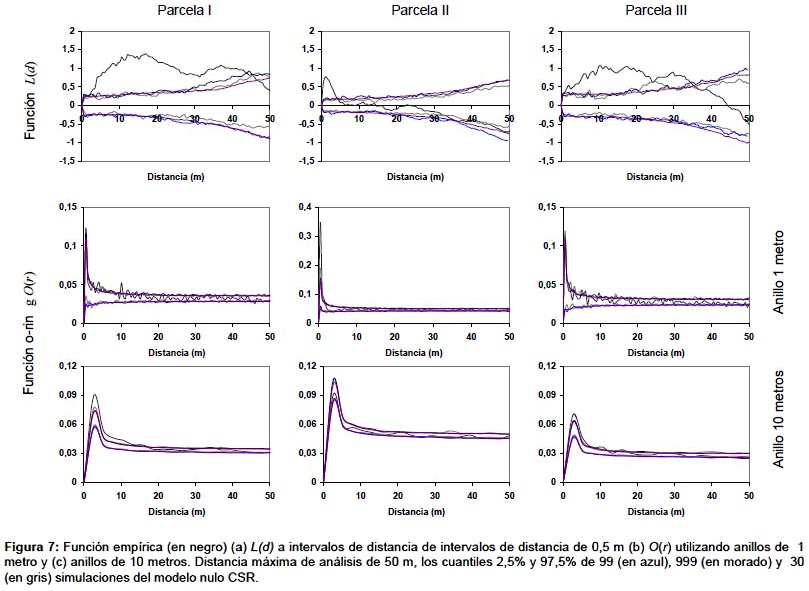
Como se puede observar en la Fig. 7a, los cuantiles del modelo nulo calculados a partir de un número mayor de iteraciones son más estables, sin embargo los intervalos en los que se detectan desviaciones significativas respecto del modelo nulo no cambian sustancialmente al comparar la función empírica con los cuantiles obtenidos con 99 iteraciones o con 999 iteraciones, por lo que el análisis con 99 iteraciones se podría considerar adecuado en este caso. Algunos trabajos parecen indicar que en parcelas con un número de árboles pequeño sería necesario un número mayor de iteraciones (Loosmore & Ford 2006), no obstante, aumentar el número de iteraciones supone un aumento en el tiempo de cálculo que puede llegar a ser prohibitivo cuando hay un número grande de individuos en las parcelas. En la mayoría de los casos los cuantiles obtenidos con 30 iteraciones son muy fluctuantes, aunque, dependiendo del número de individuos, como se observa en la Fig. 7a, los intervalos en los que se detectan desviaciones significativas del modelo nulo pueden no diferir sustancialmente del análisis con 99 o más iteraciones.
Este método tiene además algunas variantes interesantes, como la función bivariante K12 (Lotwich & Silverman 1982) que permite analizar el patrón de atracción y repulsión entre dos clases de puntos, y las funciones de correlación de la marca, que evalúan la correlación de una variable relacionada con cada punto, como puede ser el diámetro, en función de la distancia (Stoyan & Stoyan 1994) o la función Krx(d) (Montes & Cañellas 2007) para relacionar el patrón de puntos con una variable continua.
Estas técnicas comenzaron a aplicarse en el estudio de bosques tropicales para analizar el patrón espacial en selvas tropicales en Costa Rica (Clark & Clark 1992), se han empleado también para estudiar y modelizar una selva tropical en Brasil, midiendo durante tres años consecutivos parcelas rectangulares de 0,5 ha donde se registran las posiciones y diámetros de todos los pies con un diámetro mayor a 10 cm (Batista & Maguire 1998); para estudiar el patrón espacial en diferente áreas de un bosque en la India, con tres parcelas de 1 ha, considerando todos los pies con diámetro mayor o igual a 30 cm (Pélissier 1998). También se han empleado técnicas del momento de segundo orden para analizar el patrón espacial en la Laurisilva canaria (Arévalo & Fernandez-Palacios 2003); en el estudio de la dependencia entre los huecos que aparecen en la masa y la riqueza de especies en un bosque montano en Argentina (Grau 2002) y en los trabajos de patrón espacial y dinámica forestal en la Guayana Francesa (Picard et al. 2009).
Otras funciones similares en cuanto a fundamento e interpretación son la función de Getis y Franklin (1987) y las funciones G y F propuestas por Diggle (1983). Son de escasa utilización, pero un estudio completo con aplicación a una sabana africana aparece en Gignoux et al. (1999). Hardy y Sonké (2004) utilizan también funciones acumulativas para estudiar la distribución de especies en una selva en Camerún y Plotkin y colaboradores (2002) utilizan este tipo de funciones para un análisis de los patrones de agregación de los árboles en un bosque en Malasia.
Funciones no acumulativas
Estas funciones son conocidas como pair correlation function (Stoyan & Penttinen 2000), y a diferencia de las funciones acumulativas su valor para cada distancia di depende únicamente de los puntos que distan una distancia di, aunque en la práctica se evalúa la función en una corona circular de radio menor di-δ y radio mayor di+δ. Las más conocidas son la función g(r) (Stoyan & Stoyan 1994), que es análoga a la función K(d), y la denominada función O-ring (Wiegand & Moloney 2004) que mide el número de puntos en función de la distancia:
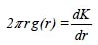
Muchos autores utilizan este tipo de funciones porque son más sensibles para detectar la existencia de un patrón espacial a una determinada distancia (Ward et al. 1996), aunque las funciones acumulativas presentan mejores propiedades estadísticas (Stoyan & Penttinen 2000). Esta diferencia se pone de relieve en la comparación de las funciones O-ring con las correspondientes funciones L(d) (Fig. 7), como se puede observar en las parcelas I y III las funciones O-ring únicamente muestran agregación para determinadas distancias y el tamaño del anillo elegido será decisivo a la hora de determinar el patrón según qué distancias (Fig.7b,c). Condit et al. (2000) propuso una función no acumulativa para el análisis del patrón espacial de vecindad de los árboles en bosques tropicales, en uno de los trabajos de referencia dentro de este ámbito. También se han utilizado para ver el patrón de algunas especies en un bosque en Sri-Lanka (Wiegand et al. 2007).
Triangulación o teselación.- Se ha propuesto estudiar el patrón espacial haciendo una triangulación a partir de los árboles posicionados, con la triangulación Delaunay (1934), la teselación Dirichlet (en Ripley 1981) o los Voronoï polygons area (Thiessen, 1911).
Aplicación de estas técnicas se encuentran en el estudio de la competencia en la selva de Uganda (Lawes et al. 2008) y en la modelización de la estructura forestal en la Guayana francesa (Mercier & Baujard 1997).
Índices del vecino más cercano refinado
Son una extensión de los índices basados en medidas de distancias expuestos en el apartado anterior, pero en lugar de considerar la distancia de cada árbol a su vecino, van incrementando el número de árboles vecinos de cada árbol. Son, por tanto, índices acumulativos. Una explicación más detallada y con ejemplos se puede encontrar en Li y Zhang (2007) o en Ripley (1981). Una corrección del efecto borde aparece en Rozas y Camarero (2005), y un estudio completo en Stoyan (2006). Son muy poco usados en el mundo forestal.
Discusión
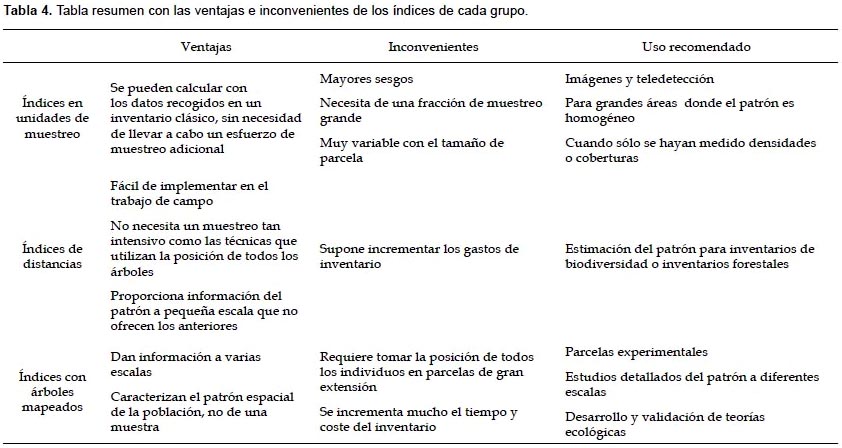
Comparación de las diferentes técnicas de análisis de la estructura horizontal.- Dentro de las ventajas del grupo de índices que se estiman en unidades de muestreo, destaca el que se puedan calcular con datos de un muestreo convencional sin necesidad de ampliar los recursos invertidos en el inventario. Por el contrario, la información que proporciona el cálculo de estos índices depende en gran medida del tamaño de parcela considerado, y no se pueden extrapolar los resultados a otras escalas. Además, para resultados fiables se necesita que la zona de estudio sea relativamente homogénea y una fracción de muestreo considerable, por eso son usados en teledetección o análisis de imágenes (donde la fracción de muestreo es la totalidad). Dentro de este grupo el índice más recomendable para aplicar en masas similares a la estudiada es el índice de Morisita, por su mayor estabilidad y por requerir un menor esfuerzo de muestreo. La técnica SADIE muestra las zonas de agregación, no es un índice que esté midiendo el patrón general.
El grupo de los índices que requieren de distancias medidas en campo son muy útiles para obtener una descripción de la estructura horizontal a escala de vecindad (del Río et al. 2003) o para comparar diferentes zonas o rodales dentro del bosque. Las mediciones que requieren son sencillas de implementar en el inventario. Dan un valor a pequeña escala que no proporcionan los índices basados en unidades de muestreo, pero también requieren de un esfuerzo de muestreo mayor, lo que implica consumir más recursos en el inventario. Otro problema que se encuentra al aplicar estos índices en masas complejas como la estudiada es que si se incluyen todos los pies presentes en la masa, sin excluir los diámetros menores, el valor de índice está fuertemente influido por el elevado número de pies que hay en los estratos inferiores, y no proporciona información acerca de la distribución de los pies mayores. Como se puede observar en la Figura 5, en la parcela II (donde hay un mayor número de árboles y la distribución de puntos es más uniforme porque no presenta zonas con grandes huecos y zonas con agregados tan marcados como las parcelas I y III), este tipo de índices muestran un comportamiento más estable y menores errores, lo que indica que el índice dará resultados más fiables en masas con una distribución más regular que en masas más heterogéneas. Los mejores resultados se han obtenido con el índice de Byth-Ripley, por lo que dentro de este grupo se aconseja es uso de este índice en este tipo de masas; aunque hay que tener en cuenta que para calcular este índice es preciso medir distancias árbol-árbol y distancias punto-árbol, lo que supone un mayor esfuerzo en la toma de datos que el de Clark y Evans, y éste segundo ofreció también buenos resultados. El índice de Pielou resultó el menos eficiente en las parcelas estudias.
La ventaja de aplicar las técnicas de patrones de puntos es que describen el patrón espacial diferentes escalas, proporcionando una información muy interesante para el estudio de la estructura del ecosistema. Analizando el patrón espacial de las diferentes especies o de los individuos en un determinado estado de desarrollo se puede inferir sobre los procesos ecológicos que han originado ese patrón. Como inconveniente a estas funciones está que para su aplicación se requiere un fuerte esfuerzo de muestreo, pues hay que tomar la posición de todos los árboles, y un mayor esfuerzo de cálculo, requieren paquetes estadísticos específicos para hacer los análisis. Las funciones no acumulativas muestran la presencia de agregación o regularidad en rangos de distancias menos amplios que las funciones acumulativas debido a que aíslan el patrón espacial a una determinada distancia, y no incluyen los pies situados a distancias inferiores, sin embargo pueden ser muy útiles para detectar la presencia de un determinado patrón espacial en un rango de distancias concreto. El ejemplo presentado muestra que el uso de 99 iteraciones en el cálculo de las bandas de los cuantiles 97,5% y 2,5% del modelo nulo es suficiente cuando se incluye un elevado número de árboles en el análisis. Los avances en las técnicas de cálculo automático han favorecido una tendencia a la generalización del uso de estas técnicas para el análisis del patrón espacial. Sin embargo, sigue siendo una gran limitación la necesidad de tomar la posición de los árboles en parcelas de gran extensión, ya que este tipo de inventario que puede ser realizado en parcelas experimentales con fines de investigación, no es tan factible para ajustarse a un presupuesto de un inventario de monte convencional.
En la Tabla 4 se resumen los inconvenientes, ventajas y aplicaciones de los diferentes tipos de índices.
Problemas específicos en bosques tropicales.- Los bosques tropicales suelen presentar en muchos casos cierta tendencia a la regularidad a escalas grandes, sin embargo según se va reduciendo la escala se suele encontrar una fuerte tendencia a formar agregados, como en el caso de estudio presentado en este trabajo (Ledo et al. 2009). Esta agregación a pequeña escala se ha descrito en muchos otros trabajos en zonas tropicales (Condit et al. 2000; Lawes et al. 2008; Picard et al. 2009). La escala de análisis o los criterios (como estrato, diámetro, tipo funcional) para definir la población que se analiza van a influir en el patrón espacial de manera especial en masas tropicales (Pélissier 1998), al igual que el diámetro de corte considerado para incluir en el análisis, pues la elevada densidad de pies de los estratos inferiores influirá de manera decisiva en el patrón resultante además de hacer más difícil el replanteo de las parcelas de inventario o la medición de rumbos y distancias. El mayor número de especies presentes y la complejidad de los procesos ecológicos que tienen lugar en el bosque hacen que aparezcan diferentes niveles de organización a diferentes escalas, que pueden variar según zonas o tipos de bosques. Estos niveles de organización pueden ser caracterizados gracias el análisis del patrón espacial, pero suponen una fuente de variabilidad adicional. Por otra parte, en la mayoría de las teorías ecológicas propuestas para explicar la diversidad existente en zonas tropicales, como en la teoría de Janzen-Connell (Connell 1971; Janzen 1970) o en la Teoría Neutral (Hubbell 2001), la distribución espacial de los individuos de las diferentes especies juega un papel esencial.
¿Qué técnica utilizar? .- Para estudios de coberturas o imágenes, grandes áreas, o cuando hay limitaciones que impiden llevar a cabo mediciones adicionales de distancias o posiciones de los pies en el inventario, para evaluar el patrón espacial en el conjunto del área de estudio se pueden utilizar los índices en unidades de muestreo. Dentro de este grupo, y según los resultados de este estudio, el más interesante es el índice de Morisita.
Para inventarios descriptivos o estudios de biodiversidad, cuando el objetivo sea la comparación entre parcelas o zonas próximas o el objetivo sea caracterizar la distribución espacial a pequeña escala se pueden utilizar índices del vecino más cercano. Dentro de este grupo el índice de Byth y Ripley y el de Clark y Evans serían los más indicados para caracterizar el patrón en este tipo de bosques.
Para investigaciones exhaustivas o estudios del patrón a diferentes escalas, se recomienda el cálculo de la función L(d), siempre que se disponga de datos de la posición de los árboles en parcelas de tamaño suficiente para haya un número significativo de elementos incluidos en el análisis.
Agradecimientos
Este trabajo se ha llevado a cabo gracias a una Beca de Formación del Personal Investigador de la Universidad Politécnica de Madrid y a la financiación del viaje y estancia en Perú por el Consejo Social de la UPM. Los autores quisieran expresar también su agradecimiento a Wilder E. Caba Culquicondor por su ayuda en el trabajo de replanteo y medición de las parcelas.
Literatura citada
Alberdi I., Saura S., Martínez F.J., 2005. El estudio de la biodiversidad en el tercer Inventario Forestal Nacional. Cuadernos de la Sociedad Española de Ciencias Forestales 19:11-19.
Arévalo J.R. & Fernandez-Palacios J.M., 2003. Spatial patterns of trees and juveniles in a laurel forest of Tenerife, Canary Islands. Plant Ecology 165:1-10.
Batchelker C.L., 1971. Estimate of density from a sample of joint point and nearest neighbour distances. Ecology 52:353-355.
Batista J.L.F. & Maguire DA, 1998. Modeling the spatial structure of topical forests. Forest Ecology and Management 110:293-314.
Bellehumeur C., Legendre P., Marcotte D., 1997. Variance and spatial scales in a tropical rain forest: changing the size of sampling units. Plant Ecology 130:89-98.
Besag J.E. & Diggle P.J. 1977. Simple Monte Carlo Tests for Spatial Pattern. Applied statistics 26:327-333.
Byth K. & Ripley B.D., 1980. On sampling spatial patterns by distance methods. Biometrics 36:279-284.
Clark D.A., Clark D.B., 1992. Life history diversity of canopy and emergent trees in a neotropical rain forest. Ecological Monographs 62:315-344.
Clark P.J. & Evans F.C., 1954. Distance to nearest neighbour as a measure of spatial relationships in populations. Ecology 35:445-453.
Condés S., Martinez-Millan J. 1998. Comparación entre los índices de distribución espacial de árboles más usados en el ámbito forestal. Investigación Agraria: Sistemas y Recursos Forestales 7, 173-187.
Condit R., Ashton P.S., Baker P., Bunyavejchewin S., Gunatilleke S., Gunatilleke N., Hubbell S.P., Foster R.B., Itoh A., LaFrankie J.V., Lee H.S., Losos E., Manokaran N., Sukumar R., Yamakura T., 2000. Spatial Patterns in the Distribution of Tropical Tree Species Science 288:1414 - 1418.
Connell J.H., 1971. On the role of the natural enemies in preventing competitive exclusion in some marine animals and in rain forest trees., p. 298-312, In P. J. den Boer and G. Gradwell, eds. Dynamics of populations Centre for Agricultural Publishing and Documentation, Wageningen, the Netherlands.
Cox F., 1971. Dichtebestimmung und Strukturanalyse von Pflanzenpopulationen mit Hilfe der Abstandsmessungen. Mitt. Bundesforschungsanst. Forst- u. Holzw. 87.
Creesie N.A.C., 1993. Statistics for spatial data Wiley and Sons.
Dale M.R.T. 1999. Spatial Pattern Analysis in Plant Ecology Cambridge University Press.
David F.N., & Moore P.G., 1954. Notes on contagious distributions in plant populations. Annals of Botany 18:47-53.
del Río M., Montes F., Cañellas I., Montero G., 2003. Revisión: Índices de diversidad estructural en masas forestales. Investigación Agraria: Sistemas y Recursos Forestales 12:159-176.
Delaunay, B., 1934. Sur la sphere vide. Matematicheskikh i Estestvennykh Nauk. Bulletin of Academy of Sciences of the USSR 7:793-800.
Diggle P.J., 1983. Statistical Analysis of Spatial Point Patterns Academic Press, New York.
Douglas, J.B., 1975. Clustering and aggregation. Sankhya B 37.
Eberhardt L.L., 1967. Some developments in "distance sampling". Biometrics 23:207-216.
Fisher R.A., Thornton H.G., Mackenzie W.A., 1922. The accuracy of the plating method of estimating the density of bacterial populations. Annals of Applied Biology 9:325-359.
Gadow K.v., Hui G.Y., Albert M., 1998. DasWinkelmaûÐein Strukturparameter zur Beschreibung der Individualverteilung in WaldbestaÈnden. Centralbl. ges. . Forstwesen 115:1-9.
Galiano E.F., 1983. Detection of multiple-species patterns in plant populations. Vegetatio 53:129-138.
Gearly, R.C., 1954. The contiguity ratio and statistical mapping. The Incorporated Statistician 5:115-145.
Getis, A. & Franklin J., 1987. Second-order neighborhood analysis of mapped point patterns. . Ecology 68:473-477.
Gignoux J., Duby C., Barot S., 1999. Comparing the Performances of Diggle's Test of Spatial Ramdomness for Small Samples with and without Edge-Effect Correction: Application to Ecological Data. Biometrics 55:156-164.
Goreaud F. & Pélissier R., 1999. On explicit formulas of edge effect correction for Ripleys K-function. Journal of Vegetation Science 10:433-438.
Gourbiere F., Debouzie D., 1995. Spatial distribution and estimation of forest floor components in a 37-year-old Casuarina equisetifolia (Forst.) plantation in coast Senegal. Soil Biology and Biochemistry 27:297-304.
Grau H.R., 2002. Scale-dependent relationships between treefalls and species richness in a Neotropical Montante Forest. Ecology 83:2591-2601.
Graz F.P. 2006. Spatial diversity of dry savanna woodlands. Biodiversity and Conservation 15:1143–1157.
Greig-Smith P. 1952. The use of random and contiguous quadrats in the study of the structure of plant communities. Annals of Botany 16:293-316.
Greig-Smith P., 1964. Quantitative Plant Ecology. Butterworths, London.
Hagihara A., Feroz S.M., Yokota M., 2008. Canopy Multilayering and Woody Species Diversity of a Subtropical Evergreen Broadleaf Forest, Okinawa Island. Pacific Science 62:363-376.
Halpern C.B., Spies T.A., 1995. Plant Species Diversity in Natural and Managed Forests of the Pacific Northwest. Ecological Applications 5:913-934.
Hamilton L.S., Juvick J.O., Scalena F., 1994. Tropical montane Cloud forest Springer-Verlag, Nueva York.
Hardy O.J. & Sonké B., 2004. Spatial pattern analysis of tree species distribution in a tropical rain forest of Cameroon: assessing the role of limited dispersal and niche differentiation. Dynamics and Conservation of Genetic Diversity in Forest Ecology. 197:191-202.
Hill M.O., 1973. The intensity of spatial pattern in plant communities. Journal of Ecology 61:225-235.
Holgate P., 1965. Test of randomness based on distance methods. Biometrika 52:345-353.
Hopkins B. & Skellam J.G., 1954. A new method for determining the type of distribution of plant individuals. Annals of Botany 18:213-227.
Hubbell S.P., 2001. The Unified Neutral Theory of Biodiversity and Biogeography Princeton University Press.
Janzen D.H., 1970. Herbivores and the number of tree species in tropical forests. Amer. Naturalist 104:501–529.
Julliot C., 1997. Impact of Seed Dispersal by Red Howler Monkeys Alouatta Seniculus on the Seedling Population in the Journal of Ecology 85:431-440.
Kershaw K.A. 1960. The detection of pattern and association. Journal of Ecology 48:233–242
Lawes M.J., Griffiths M.E., Midgley J.J., Boudreau S., Eeley H.A.C., Chapman C.A., 2008. Tree spacing and area of competitive influence do not scale with tree size in an African rain forest. Journal of Vegetation Science 19:729-738.
Ledo A., Montes F., Condés s., 2009. Forest, Wildlife and Wood Sciences for Society Development, pp. International Scientific Conference. IUFRO and EFI associated event, Pragra.
Legendre P., 1993. Spatial autocorrelation: Trouble or new paradigm? Ecology 74:1659-1673.
Li F. & Zhang L., 2007. Comparison of point pattern analysis methods for classifying the spatial distributions of spruce-fir stands in the north-east USA. Forestry 80:337-349.
Lieberman D., Lieberman M., Peralta R., Hartshorn G.S., 1985. Mortality Patterns and Stand Turnover Rates in a Wet Tropical Forest in Costa Rica Journal of Ecology 73:915-924
Lima A.B., Corral Rivas J.J., Von Gadow K., Muuss U. 2006. Assesment of forest structure and diversity using three different approaches. International Research on Food Security, Natural Resource Management and Rural Development. University of Bonn
Lloyd M., 1967. Mean crowding. Journal of Animal Ecology 36:1-30.
Loosmore N.B., Ford E.D., 2006. Statistical inference using the G or K point pattern spatial statistics. Ecology 87:1925-1931.
Lotwich H.W., Silverman B.W., 1982. Methods for analysing spatial processes of several types of points. Journal of the Royal Statistical Society. Series B 44:406-413.
Madrigal A., 2002. Ordenación de montes arbolados. Serie técnica ICONA. Madrid.
Mead R., 1974., A test for spatial pattern at several scales using data from a grid of contiguous quadrats. Biometrics 30:965-981.
Mercier F. & Baujard O., 1997. Voronoi diagrams to model forest dynamics in French Guiana. Proceedings of GeoComputation.
Montes F., Cañellas I., 2007. The spatial relationship between post-crop remaining trees and the establishment of saplings in Pinus sylvestris stands in Spain. Applied Vegetation Science 10:151-160.
Montes F. & Cañellas I., del Río M., Calama R., Montero G., 2004. The effects of thinning on the structural diversity of coppice forests. Annals of Forrest Science 61:771–779.
Moran P.A.P., 1950. Notes on continuous stochastic phenomena. Biometrika 37:17-23.
Morisita M., 1959. Measuring of the dispersion and analysis of distribution patterns. Memoires of the Faculty of Sciences, Kyushu University, Series E. Biology 2:215-235.
Müller-Starck G., Schubert R., 2002. Genetic Response Of Forest Systems To Changing Environmental Conditions. Forestry Sciences 70
Parthasarathy N. & Karthikeyan R., 1997. Plant biodiversity inventory and conservation of two tropical dry evergreen forests on the Coromandel coast, south India Biodiversity and Conservation 6:1063-1083
Pélissier R., 1998. Tree spatial patterns in three contrasting plots of a southern Indian tropical moist evergreen forest.. Journal of Tropical Ecology 14:1-16.
Pélissier R., & Goreaud F., 2001. A practical approach to the study of spatial structure in simple cases of heterogeneous vegetation. Journal of Vegetation Science 12:99-108.
Perry J.N., 1998. Measures of spatial pattern for counts. Ecology 79:1008-1017.
Picard N., Bar-Hen A., Mortier F., Chadoeuf J., 2009. Understanding the dynamics of an undisturbed tropical rain forest from the spatial pattern of trees. Journal of Ecology 97:97-108.
Pielou E.C., 1959. The use of point-to-plant distances in the study of the pattern of plant populations. Journal of Ecology 47:607-613.
Plotkin J.B., Chave J., Ashton P.S., 2002. Cluster Analysis of Spatial Patterns in Malaysian Tree Species. The American Naturalist 160:629–644.
Reddy C.S., Ugle P., Murthy M.S.R., Sudhakar S., 2008. Quantitative Structure and Composition of Tropical Forests of Mudumalai Wildlife Sanctuary, Western Ghats, India. Taiwania 53:150-156.
Renshaw E. & Ford E.D. 1984. The description of spatial pattern using two-dimensional spectral analysis. Vegetatio 56:75-85
Richards P. & Williamson G.B., 1975. Treefalls and Patterns of Understory Species in a Wet Lowland. Tropical Forest Ecology 56:1226-1229
Ripley B.D., 1977. Modelling spatial patterns (with discussion). Journal of Royal Statistical Society B 39:172-212.
RipleY B.D., 1981. Spatial Statistics. Wiley and Sons.
Roxburgh S.H., Chesson P., 1998. A new method for detecting species associations with spatially autocorrelated data. Ecology 76:2180-2192.
Rozas V. & Camarero J.J., 2005. Técnicas de análisis espacial de patrones de puntos aplicadas en ecología forestal. Invest Agrar: Sist Recur For 14:79-97.
Sandler B.C., Pearman P.B., Guerrero M., Levy K., 1997. Using a GIS to Assess Spatial Scale of Taxonomic Richness in Amazonian Ecuador. ESRI User Conference.
Skellam J.G., 1952. Studies in statistical ecology. I. Spatial pattern. biometrika 39:346-362.
Southwood T.R.E., 1978. Ecological Methods. Halsted Press, New York.
Staudhammer C.L., LeMaY V.M., 2001. Introduction and evaluation of possible indices of stand structural diversity. Canadian journal of forest research 31:1105–1115.
Steege H., Pitman N.C.A., Phillips O.L., Chave J., Sabatier D., Duque A., 2006. Continental-scale patterns of canopy tree composition and function across Amazonia. Nature 443:444-447.
Stoyan D., 2006. On estimators of the nearest neighbour distance distribution function for stationary point processes. Metrika 64:139-150.
Stoyan D. & Penttinen A., 2000. Recent applications of point process methods in forestry statistics. . Statistical Science 15:61–78.
Stoyan D. & Stoyan H., 1994. Fractals, Random Shapes and Point Fields. Wiley ed., New York.
Strand L., 1953. Mal for fordelingen av individer over et omrade. Det Norske Skogforsoksvesen 42:191-207.
Thiessen A.H., 1911. Precipitation averages for large areas. Monthly Weather Rev. 39:1082-1084.
Veblen T.T., 1979. Structure and Dynamics of Nothofagus Forest Near Timberline in South-Central Chile. Ecology 60:937-945.
Vincent K., Marc V.M., Lieven N., Guy G., Noël L., 2003. Spatial methods for quantifying forest stand structure development: A comparison between nearest-neighbor indices and variogram analysis. Forest science 49:36-49.
Ward J.S. & Parker G.R., 1989. Spatial Dispersion of Woody Regeneration in an Old-Growth Forest. Ecology 70:1279-1285
Ward J.S., Parker G.R., Ferrandino F.J., 1996. Long-term spatial dynamics in an old-growth deciduous forest. Forest Ecology and Management 83:189-202.
Webb E.L. & Fa'aumu S., 2004. Diversity and structure of tropical rain forest of Tutuila, American Samoa: effects of site age and substrate Plant Ecology 144:257-274.
Wiegand T., Gunatilleke C.V.S., Gunatilleke I.A.U.N., Okuda T. 2007. Analyzing the spatial structure of a sri lankan tree species with multiple scales of clustering. Ecology 88: 3088–3102
Wiegand T. & Moloney K.A., 2004. Rings, circles and null-models for point pattern analysis in ecology. Oikos 104:209-229.
Presentado: 17/01/2012
Aceptado: 21/08/2012
Publicado online: 01/10/2012
