









 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink
INTRODUCCIÓN
Los estudios de asociación genética consisten en la investigación de una relación causa-efecto entre una enfermedad, predisposición a una enfermedad, u otra característica fenotípica definida con uno o más polimorfismos genéticos 1 .La farmacogenómica utiliza la tecnología genómica (transcriptómica, proteómica y epigenómica) para estudiar la relación entre los efectos de los medicamentos y los genes relevantes 2. La farmacogenética focaliza su atención sobre el efecto de los polimorfismos de uno o cientos de genes que están relacionados con la farmacocinética (Vgr metabolismo, transportadores), farmacodinamia (receptores) y genes modificadores de enfermedad que han sido asociados como efecto de los fármacos. En la última década los estudios en general de asociación genética y especialmente las investigaciones farmacogenéticas de casos y controles se han elevado de manera constante, proporcionando aportes importantes al conocimiento sobre el tema. Sin embargo, una parte de los estudios publicados tienen problemas de replicabilidad, es decir, sus resultados catalogados como positivos al inicio, no han podido ser reproducidos por estudios ulteriores en poblaciones independientes. Un ejemplo ilustrativo son los estudios iniciales sobre la farmacogenética de la warfarina, los cuales en la evaluación de la calidad metodológica presentaban problemas en la selección de genes candidato, tamaño de muestra, estratificación poblacional, análisis del Equilibrio de Hardy-Weinberg, entre otros 3.
Entre los diseños que tienen más observaciones en su calidad metodológica están los estudios de casos y controles. Existen otros tipos de diseños entre los cuales están los ensayos controlados aleatorizados, donde los participantes se estratifican por genotipo y se asignan aleatoriamente a los grupos de tratamiento; la principal fortaleza de este diseño es que constituye una fuerte evidencia de una interacción fármaco-gen, es una evidencia de causalidad y es posible evaluar múltiples resultados; sin embargo tienen la limitación de su factibilidad porque requieren un tamaño de muestra grande, es de alto costo y es difícil evaluar eventos raros. También existen los estudios de cohorte prospectivos, en los cuales se realiza un seguimiento de los participantes a lo largo del tiempo y se compara el resultado de la enfermedad con los subgrupos de fármacos y genotipos, su ventaja es precisamente su carácter prospectivo y la posibilidad de evaluar múltiples resultados; y sus desventajas son la posibilidad de sesgo de selección (pérdida durante el seguimiento), sesgo de información (no diferencial), confusores y la dificultad de evaluar eventos raros 4.
El presente artículo tiene el objetivo de revisar los principales factores a tener en cuenta, para obtener una calidad metodológica adecuada en estudios farmacogenéticos de casos y controles, entre los cuales se analizarán la definición operacional del fenotipo, selección de los casos y controles, tamaño de la muestra, estratificación de la población, equilibrio de Hardy-Weinberg (EHW), sesgo de notificación selectiva de los desenlaces, análisis de datos, fenómeno de fenoconversión y las metodologías de identificación de variantes genéticas, fenómeno de depleción de los susceptibles y las guías de evaluación de calidad metodológica de estudios farmacogenéticos. Previamente se hará una breve revisión del diseño de casos y controles en el contexto farmacogenómico.
Estudios de casos y controles
Aplicado a estudios farmacogenéticos, las personas con reacciones adversas o pobre respuesta terapéutica (resultados o desenlaces) se denominan "casos", la frecuencia de genotipos en los "casos" son comparados con los "controles", que son definidos como personas que tienen una exposición comparable al fármaco, pero en quienes no se presentan los resultados o desenlaces 5,6. Este tipo de diseño permite medir los efectos de la interacción gen-fármaco, pero debe anotarse que no descarta completamente los efectos independientes del genotipo o respuesta del fármaco 4.
Definición del fenotipo: Fenotipos, endofenotipos y biomarcadores
Definido operacionalmente el fenotipo consiste en la utilización de métodos epidemiológicos, biológicos, moleculares o computacionales para seleccionar sistemáticamente las características de un trastorno que podría ser el resultado de distintas influencias genéticas 7. En estudios farmacogenéticos el fenotipo son las características observables y/o susceptibles de ser medidos (efectos sobre la farmacocinética o farmacodinamia), que pueden ser considerados como efecto del genotipo del individuo al cual se ha administrado un fármaco en investigación. El término endofenotipo configura un componente mensurable del fenotipo, no visto a simple vista, que se encuentra a lo largo (es decir, dentro) de la ruta entre la enfermedad (es decir, fenotipo observable) y el genotipo distal 8,9. El término endofenotipo se utiliza en la investigación genética de las enfermedades psiquiátricas, bajo la perspectiva que lo que observamos a simple vista es la enfermedad psiquiátrica, es decir el "exofenotipo", en cuya etiología estaría implicada un componente genético, moldeado por el ambiente 10. Los biomarcadores son características que se pueden medir objetivamente y se evalúa como un indicador de procesos biológicos normales, procesos patogénicos o respuestas farmacológicas a una intervención terapéutica. Tanto los fenotipos, endofenotipos y biomarcadores son utilizados en estudios farmacogenéticos como puntos finales o resultados (outcomes) con los cuales se establecerán la relación de la influencia genética sobre una respuesta farmacológica 11. Las técnicas proteómicas en el futuro serán la fuente de muchos biomarcadores, que se utilizarán como puntos finales o resultados para estudios farmacogenéticos.
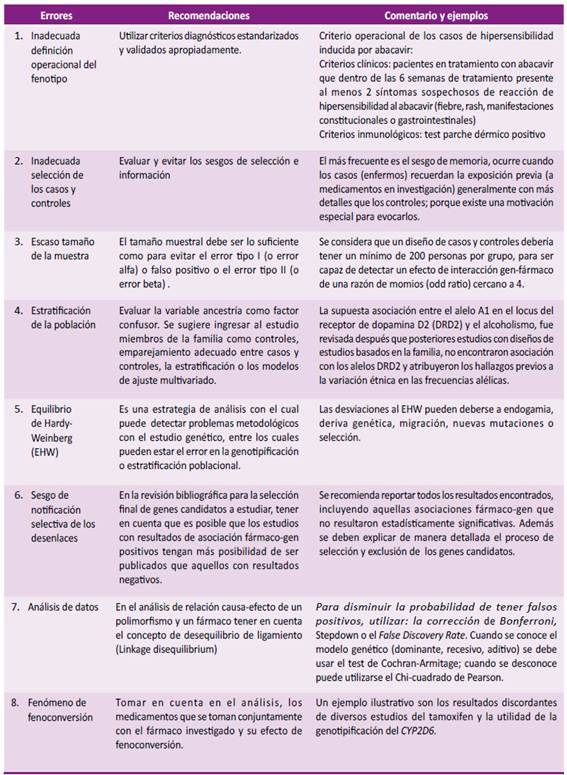
Para mejorar la replicabilidad de los estudios farmacogenéticos es importante trabajar con fenotipos precisos12. Por ejemplo, para el estudio de la genómica de las enfermedades neurodegenerativas se recomienda incluir casos con criterios diagnósticos estandarizados y validadas apropiadamente, estudios de cohortes prospectiva y casos con diagnóstico histopatológico, si fuera posible. 12 Un buen ejemplo de fenotipificación adecuada, son los estudios de la susceptibilidad a la reacción de hipersensibilidad inducida por abacavir. En estos estudios los casos son definidos operacionalmente como aquellos identificados por criterios clínicos e inmunológicos (test parche dérmico positivo), es decir, son incluidos aquellos pacientes en tratamiento con abacavir que dentro de las 6 semanas de tratamiento presenten al menos 2 síntomas sospechosos de reacción de hipersensibilidad al abacavir (fiebre, rash, manifestaciones constitucionales o gastrointestinales) además de haber resultado positivo al test parche dérmico específicos para esta reacción adversa 13. Ver Tabla 1.
Selección de casos y controles
Los estudios de casos y controles pueden presentar sesgos de selección e información. El sesgo de selección se produce cuando hay una inclusión o exclusión inadecuada de los casos o controles. Los casos como los controles deberían tener el mismo potencial para desarrollar el desenlace o resultado en investigación (fenotipos). En estos estudios, si los controles provienen de grupos de personas que son atendidas en un hospital, es posible un sesgo de selección, porque se estarían seleccionando personas cuyas frecuencias alélicas corresponden a una enfermedad subyacente, el cual podría distorsionar la asociación exposición-enfermedad o interacción fármaco-fenotipo 4. El sesgo de información ocurre cuando existen diferencias en la obtención de los datos de los casos y los controles. Los sesgos de información más frecuentes son el de memoria y la mala clasificación. El sesgo de memoria (recall bias) ocurre cuando los casos (enfermos o el fenotipo) recuerdan la exposición previa generalmente con más detalles que los controles; por ejemplo, los pacientes (casos) expuestos a fármacos en el pasado, recuerdan con más detalles que los controles, porque en estos últimos, no existe una motivación especial para evocarlos. El sesgo de inadecuada clasificación esta descrita como la variación en la calidad de la obtención de los datos de los casos y controles, denominándose diferencial (Differential misclassification), cuando se sobre o subestima el riesgo; por otro, se llama de no-diferencia cuando únicamente se subestima el riesgo.
Tamaño de la muestra
En los estudios de casos y controles el tamaño ideal de la muestra depende de cuatro factores, entre los cuales están la frecuencia relativa esperada de la exposición de interés entre los controles (personas sin la enfermedad o sin el fenotipo farmacológico), fuerza de asociación esperada entre el factor de riesgo de interés y la enfermedad, nivel de significancia deseado (error alfa a ser aceptado, generalmente es de 5 %) y el error beta a tolerar (generalmente no mayor de 10 %) 14. El objetivo de tener un tamaño muestral adecuado es prevenir dos tipos de errores. El error tipo I (o error alfa) o falso positivo, es decir, en estudios farmacogenéticos concluir que existe una asociación entre el fenotipo farmacológico y el gen investigado, cuando en realidad no lo hay; el error tipo II (o error beta) falso negativo, que consiste en que el estudio no encuentra una asociación, cuando en verdad si existe 14.
En estudios farmacogenéticos con diseño de casos y controles, el tamaño de la muestra debe ser lo suficientemente grande para verificar si existe una real interacción gen-fármaco. Se considera que un diseño de casos y controles debería tener un mínimo de 200 personas por grupo, para ser capaz de detectar un efecto de interacción gen-fármaco de una razón de momios (odds ratio) cercano a 4. Se requiere un mínimo de 400 casos y 800 controles para determinar una razón de momios entre 2 y 4 15. Para los cálculos de la muestra, debe tomarse en cuenta la prevalencia de los portadores de alelo mutante entre los controles; al respecto se ha calculado que si esta prevalencia está por debajo de 0.2 se requiere no menos de 755 controles en el estudio para una razón de momios de 2.0 3.
Estratificación de la población
El sesgo de estratificación de la población es la distorsión en el valor de una asociación observada entre la variante genética G y la enfermedad D (en estudios farmacogenéticos sería un fenotipo, susceptibilidad a una reacción adversa o fallo en respuesta terapéutica) que puede ocurrir cuando G está asociada con algún factor real de riesgo E que varía según la etnicidad 16. Un clásico ejemplo es el estudio sobre la asociación entre el haplotipo Gm y la diabetes tipo 2 entre los casos y controles nativos americanos 17. Knowler y col en su estudio en tribus Pima y Papago inicialmente encontraron una asociación entre el haplotipo G y diabetes mellitus 2 en la población de nativos americanos, sin embargo, al realizar un análisis más exhaustivo se observó que el alelo mutante era más frecuente en la población con ancestro nativo americano, mientras que la diabetes mellitus 2 era menos prevalente en individuos sin la ancestría nativa. Por lo tanto, el estudio evidenciaba la asociación inversa entre la asociación entre el ancestría y Gm; y la asociación inversa entre la herencia caucásica y el riesgo de diabetes mellitus tipo 2 18. Cuando los resultados se ajustaron por la ancestría, la asociación inversa desapareció. Se ha observado que una de las principales razones por las cuales muchos estudios de asociación gen-enfermedad no han sido replicados en sus resultados, es por la confusa estratificación poblacional 19.
En estudios farmacogenéticos hay dos ejemplo ilustrativos. El primero es la supuesta asociación entre la ototoxicidad de los aminoglucósidos y una variante de la secuencia molecular del ARNr 12S, un gen codificado por las mitocondrias, un estudio inicial encontró que una familia italiana era más susceptible a esta reacción adversa 20. Sin embargo, posteriores estudios encontraron que la secuencia del ARNr 12S humano es similar a la del gen ARNr 12S bacteriano y, por lo tanto, convierte efectivamente al ARNr 12S humano en el objetivo (bacteriano) para la acción de los fármacos aminoglucósidos, presumiblemente imitando la estructura del sitio de unión bacteriano del fármaco 21. Es decir, la presencia de la mutación del ARNr 12S per se no tiene un efecto primario independiente del tratamiento farmacológico 22. El segundo ejemplo es la supuesta asociación entre el alelo A1 en el locus del receptor de dopamina D2 (DRD2) y el alcoholismo que sugirió un estudio 23. Posteriores estudios con diseños de estudios basados en la familia, no encontraron asociación con los alelos DRD2 y atribuyeron los hallazgos previos a la variación étnica en las frecuencias alélicas 24,25.
Las estrategias que se recomiendan para evitar el factor confusor de estratificación de población, son el uso de miembros de la familia como controles, emparejamiento adecuado entre casos y controles, y la estratificación o los modelos de ajuste multivariado 26. La aplicación del diseño basado en los familiares, no resulta práctico aplicarlo en estudios farmacogenéticos, porque es muy improbable que otros miembros de una misma familia estén recibiendo el fármaco en estudio 3. La estrategia más factible es tomar en cuenta en el ajuste multivariado de los resultados, el factor etnicidad/raza. En la característica de etnicidad/raza se recomienda asignar a los individuos en categorías lo más específicas posible (Vgr. En USA, ancestría Pima o Papago; en Perú grupo étnico quechua, aymara, etc.), esto quiere decir que debe evitarse asignar la etnicidad a categorías muy amplias y convencionales como caucásica, afroamericana, hispana, asiática, etc. Por otro lado, es de suma importancia anotar la presencia de personas de familias de origen étnico mixto 26.
Las estrategias descritas funcionan bien cuando la etnicidad/ raza de los individuos estudiados es fácilmente identificable o son obvias, lo cual no siempre ocurre. Cuando la estratificación de población es más sutil o los grupos étnicos no son difíciles de reconocer, se recomienda utilizar algunos métodos para detectar a lo que se denomina "estratificación criptica"; entre estos métodos están el uso de marcadores no relacionados a gen en estudio, "control genómico" y la "asociación estructurada". El método uso de marcadores no relacionados al gen en estudio, consiste en realizar la genotipificación adicional del SNP (single nucleotide polymorphism , SNPs), en otras áreas del genoma y evaluar la asociación entre estos y los resultados obtenidos 3,27. El método de control genómico 28 se utiliza para el ajuste de estratificación de población en el análisis univariado de resultados binarios; por consiguiente, pueden ser útiles en estudios de asociación gen-enfermedad con resultados binarios. Sin embargo, hay que tomar en cuenta que en estudios farmacogenéticos con resultados no binarios, el método de control genómico tiene utilidad limitada 3. El método de asociación estructurada, consiste en la aplicación de un modelo de agrupamiento usando datos de genotipo multilocus con el objetivo de inferir la estructura y asignación (probabilística) de individuos a poblaciones 28.
Equilibrio de Hardy-Weinberg (EHW)
En la investigación médica la distribución más frecuente de una variable continua se denomina normal o gaussiana; de manera similar, en genética existe una probabilidad de distribución de los alelos de interés en la población, a esa distribución se denomina equilibrio de Hardy-Weinberg (EHW) 29. Las desviaciones al EHW pueden deberse a endogamia, deriva genética, migración, nuevas mutaciones o selección. La razón principal a tomarse en cuenta el concepto del EHW en la metodología de asociación genética, es que constituye una forma de detectar problemas metodológicos con el estudio genético, entre los cuales pueden estar el error en la genotipificación o estratificación poblacional. Esta es la razón por la cual los estudios farmacogenéticos deben realizar, el test de adherencia al EHW de cada SNP investigado; los test sugeridos son el test de chi cuadrado de Pearson, el test más exacto para EHW 30.
Sesgo de notificación selectiva de los desenlaces
(within-study selective reporting)
El sesgo de publicación ocurre cuando una investigación con resultados estadísticamente significativos tiene más probabilidades de ser enviada y publicada que el trabajo con resultados no significativos 30. El sesgo de publicación puede surgir dentro de un estudio individual. Por ejemplo, es posible que se midan varios resultados, pero solo se reporta en una publicación solo un subconjunto seleccionado de ellos 31,32. Un problema similar existe cuando los análisis de subgrupos con resultados significativos tienen más probabilidades de ser publicados. Se denomina sesgo de notificación selectiva de los desenlaces (within-study selective reporting) a la selección de un subgrupo de las variables originales registradas, basadas en los resultados, para su inclusión en la publicación de los estudios 26,28. Para evitar este tipo de sesgo se deben reportar todos los resultados encontrados, incluyendo aquellas asociaciones fármaco-gen que no resultaron estadísticamente significativas. Además, se deben explicar de manera detallada la forma en que se seleccionó los genes candidatos, las razones por las cuales fueron excluidas otras, especialmente si al inicio se consideró que se iban a incluirlas en el estudio y posteriormente se excluyeron. Estos datos son de gran utilidad para posteriores estudios.
Análisis de datos
En estudios farmacogenéticos, encontrar la correlación genotipo-respuesta farmacológica, es decir que un determinado SNP es la causa de un efecto o resultado sobre una respuesta farmacológica, no es tan sencillo. En realidad, los segmentos de genoma son heredados juntos como una unidad (Linkage disequilibrium), por lo tanto, la asociación de un SNP estudiado, con una respuesta farmacológica determinada, no necesariamente va a ser causal. Podría ser que otro SNP (no incluido en el estudio, pero cercano al investigado) por el fenómeno de desequilibrio de ligamiento fuera la verdadera variable causal 29.
Uno de los principales problemas que se debe afrontar en estudios farmacogenéticos, donde se analiza la asociación de numerosos SNPs con determinada respuesta farmacológica, es el de evitar incrementar la probabilidad de cometer error tipo I (falsos positivos), es decir, el control de la tasa global de errores (FWER o family-wise error rate)3. Para disminuir la probabilidad de tener falsos positivos, se recomienda utilizar una las siguientes estrategias estadísticas: la corrección de Bonferroni, Step down33o el False Discovery Rate. Cuando se conoce el modelo genético (dominante, recesivo, aditivo) se debe usar el test de Cochran-Armitage; si se desconoce es posible utilizar el Chi-cuadrado de Pearson 34.
Fenómeno de la fenoconversión
El fenómeno de fenoconversión consiste en que por factores extrínsecos no genéticos (Vgr. Polimedicacion por interacción farmacológica), los individuos catalogados previamente como metabolizadores rápidos, se convierten en metabolizadores lentos, por lo tanto, se modifica su respuesta clínica 35. El concepto de fenoconversión forma parte de otros más conocidos, como interacción fármaco-fármaco, interacción gen-fármaco e interacción fármaco-fármaco-gen. Una interacción fármaco-gen se produce cuando el tipo de gen del CYP450 de un paciente (por ejemplo, metabolizador lento CYP2D6) afecta la capacidad del paciente para depurar o metabolizar un fármaco. La interacción fármaco-fármaco-gen ocurre cuando el genotipo (Vgr. CYP450) de un paciente y un primer fármaco en el tratamiento del paciente (por ejemplo, un inhibidor de CYP2D6), afectan la capacidad para metabolizar un segundo fármaco administrado al mismo paciente 36; es decir, es la superposición entre interacción fármaco-fármaco y la interacción fármaco-fármaco-gen. La fenoconversión, por lo tanto, sería el resultado de una interacción fármaco-fármaco-gen.
Un ejemplo de fenoconversión es el caso del tamoxifeno y la utilidad de la genotipificación del CYP2D6. Tamoxifeno se utiliza en el tratamiento de cáncer de mama con receptores positivos a estrógeno, su principal metabolito altamente activo es el endoxifen, el gen altamente polimórfico que interviene en este proceso es el CYP2D6. Por otro lado, se ha observado que existe una gran variabilidad en la eficacia y respuesta clínica al tratamiento con tamoxifeno. De allí surgió la idea que dicha variabilidad interindividual en la eficacia clínica podría radicar en el metabolismo del tamoxifeno regulada por el genotipo CYP2D6 37 y se iniciaron una serie de estudios con el objetivo de evaluar la utilidad de la genotipificación del CYP2D6 en el tratamiento del cáncer de mama con tamoxifeno. Sin embargo, los resultados de estos fueron discordantes. Finalmente, un estudio metanalítico que incluyó 25 estudios con un total de 13 629 pacientes, no encontró evidencia suficiente para recomendar la genotipificación del CYP2D6 como guía de tratamiento con tamoxifeno 38. Los hallazgos discordantes entre tamoxifen y el CYP2D6, han sido explicados por fenoconversión inducida por medicamentos que se tomaban conjuntamente con tamoxifeno como difenhidramina o inhibidores selectivos de serotonina, que tienen efecto inhibitorio de CYP2D6. Las estrategias para evitar este fenómeno es analizar el efecto de los medicamentos que se toman conjuntamente con el fármaco investigado y su efecto de fenoconversión 39-41.
Fenómeno de depleción de los susceptibles
Este fenómeno consiste en que el inicio de la exposición a un fármaco, se asocia con un aumento temprano de la tasa de incidencia de una reacción adversa medicamentosa aguda, seguido de una disminución de esta tasa de incidencia con una duración más prolongada de exposición al fármaco42. Este fenómeno se explica porque a nivel de población, los pacientes que permanecen con el fármaco son los que pueden tolerarlo, mientras que los susceptibles se seleccionan a sí mismos fuera de la población en riesgo 42. Este fenómeno se ha descrito en estudios de hemorragia gastrointestinal inducida por antinflamatorios no esteroideos y en tromboembolismo venoso inducido por anticonceptivos orales y terapia hormonal 43. El fenómeno de depleción de los susceptibles, es importante tener en cuenta en estudios farmacogenéticos de diuréticos tiazídicos y su relación con alteraciones en el intervalo QT (QT) en poblaciones multiétnicas, para interpretar y explicar su frecuencia relativa 44.
Guías de Evaluación de calidad metodológica de estudios farmacogenéticos
Actualmente se han publicado varias guías para la Evaluación de calidad metodológica de estudios de asociación genética, que bien pueden ser aplicados a la investigación farmacogenética. Entre las más importantes están STREGA (Strengthening the Reporting of Genetic Association Studies) 45, GRIPS (Strengthening the Reporting of Genetic Risk Prediction Studies) 46 y el Q-Genie (Quality of Genetic Studies) 47. Estos instrumentos son utilizados por las revistas médicas para la evaluación metodológica de estudios de asociación genética, los cuales son decisivos para la aceptación o no para su publicación; por lo tanto, también son útiles como guía para los proyectos de investigaciones farmacogenéticas.
En conclusión, los diseños más utilizados en estudios farmacogenéticos se clasifican en tres tipos: diseños basados en resultados o desenlaces (casos y controles, casos tratados únicamente y controles, y solo casos anidados dentro de un ensayo clínico controlado), diseño basado en cohortes (estudio de cohorte, estudio de cohorte de solo tratados, y el diseño basado en ensayo clínico con análisis de subgrupo dentro de dicho ensayo clínico) 48. En los estudios de casos y controles, para obtener una calidad metodológica adecuada y evitar los sesgos, es importante trabajar con fenotipos precisos, adecuada selección de los casos y controles y tamaño de la muestra; seleccionar una metodología adecuada para la identificación de variantes genéticas; y en el momento del análisis de resultados utilizar el Equilibrio de Hardy-Weinberg (EHW) e interpretar los resultados considerando la posibilidad de un fenómeno de fenoconversión.