










Services on Demand
Journal

Article
 Portuguese (pdf)
Portuguese (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO
Related links
-
 Similars in
SciELO
Similars in
SciELO
Share

 Permalink
PermalinkLiberabit
Print version ISSN 1729-4827
liber. vol.22 no.2 Lima Jul./Dec. 2016
ARTÍCULOS
Efeito do tamanho da amostra na análise de evocações para representações sociais
Effect of the size of the sample in the analysis of evocations for social representations
João Wachelke*, Rafael Wolter** e Fabíola Rodrigues Matos***
*** Universidade Federal de Uberlândia, Brasil.* * Universo/Universidade do Estado do Rio de Janeiro, Brasil.
*joao.wachelke@ufu.br **rafaelpeclywolter@gmail.com ***fabiolarmatos@yahoo.com.br
RESUMO
A análise prototípica das evocações é uma das principais técnicas que permite a exploração da estrutura das representações sociais a partir de dados verbais. O presente trabalho visa avaliar o efeito de variações no tamanho da amostra nas configurações dos resultados da análise prototípica a partir de evocações livres. Foram sorteadas subamostras de um banco de dados com 469 participantes com tamanhos amostrais progressivamente menores (200, 100, 50 e 25 casos), e comparadas as configurações de resultados dos primeiros quadrantes relativamente à amostra de referência. Os resultados apontam que as amostras de 200 e 100 casos têm padrões próximos da amostra total em termos de concordância com a composição do primeiro quadrante. Além disso, amostras com 50 e 25 participantes não são recomendáveis, por terem alta variabilidade e baixa coincidência com a amostra maior.
Palavras-chave: Representações sociais, evocações livres, tamanho da amostra, análise prototípica, métodos quali-quantitativos.
ABSTRACT
The prototypical analysis of evocations is one of the main techniques that allows the exploration of the structure of social representations from verbal data. The present study aims to evaluate the effect of variations in the size of the sample in the configurations of the results of the prototypic analysis from free evocations. Subsampleswere randomly selected from a database with 469 participants with progressively smaller sample sizes (200, 100, 50 and 25 cases), and compared the results settings of the first quadrants with respect to the reference sample. The results show that the samples of 200 and 100 cases have patterns close to the total sample in terms of agreement with the composition of the first quadrant. In addition, samples with 50 and 25 participants are not recommended because they have high variability and low coincidence with the larger sample.
Keywords: Social representations, free evocations, sample size, prototypical analysis, qualitative and quantitative methods.
Introdução
A análise prototípica (Vergès, 1992), também chamada de análise das evocações ou técnica do quadro das quatro casas é uma das técnicas mais utilizadas para exploração da estrutura das representações sociais. A teoria das representações sociais (Moscovici, 1976) propõe que as representações sociais são formas de conhecimento compartilhado por grupos acerca de objetos da vida cotidiana. Por sua vez, a análise prototípica baseia-se na formulação clássica da teoria do núcleo central (Flament e Rouquette, 2003; Sá, 1996). Essa teoria, que complementa a teoria das representações sociais concebe cada representação social como uma estrutura com dois sistemas de elementos, isto é, crenças, ideias, ou opiniões: central e periférico. O sistema ou núcleo central é formado pelo conjunto de alguns poucos elementos que definem a representação social para o grupo e são resistentes a mudanças. Por exemplo, em pesquisas orientadas por essa perspectiva, «medo» tende a ser apontado como um elemento central, isto é, uma ideia-chave consensual, da representação social atual de estudantes de ensino médio (Natividade e Camargo, 2011) e de profissionais de saúde (Oliveira, 2013) sobre a temática ou objeto social AIDS. Isso quer dizer que, para esses grupos, medo é uma característica julgada essencial, indispensável, inegociável para que estudantes de ensino médio e profissionais de saúde organizem suas crenças e comunicações a respeito desse assunto. Simplificando um pouco, podemos dizer que os elementos centrais são os elementos mais importantes, para o grupo, de uma representação social. Por outro lado, o sistema periférico compreende ideias mais pulverizadas, particulares e flexíveis que tratam de aspectos menos compartilhados, permitindo percepções específicas de subgrupos e indivíduos acerca do tema da representação.
A análise prototípica é uma estratégia de apresentação de resultados referentes a propriedades coletivas de dados de evocações livres. Solicita-se a uma amostra de membros de um grupo que forneçam um número de respostas (geralmente 3 ou 5) a um estímulo indutor geralmente verbal. Por exemplo, para o objeto AIDS, a tarefa poderia ser: «escreva as cinco primeiras palavras que lhe vem em mente quando pensa em AIDS». A análise prototípica é a organização das respostas com base em dois critérios, para sugerir se um elemento tende a ser central ou periférico. O primeiro é a frequência de cada resposta; o segundo é a ordem média de evocação, ou posição média em que a resposta aparece dentre as respostas de cada participante, sendo o escore 1 atribuído à palavra dita primeiro, 2 à palavra dita em segundo lugar, e assim por diante. Vergès (1992) define que respostas com alta frequência e baixa ordem média de evocação sinalizam elementos com alta probabilidade de serem centrais. Há também outras combinações importantes: respostas com baixas frequências mas também evocadas nas primeiras posições podem indicar subgrupos na população, uma chamada «zona de contraste»; e respostas com alta frequência mas alta ordem de evocação podem indicar o que se chama de «alta periferia», palavras com uma certa saliência. Há autores que inclusive defendem a possibilidade de identificar elementos centrais na alta periferia (p. ex., Pecora e Sá, 2008).
A estipulação de critérios para definir o que é um valor alto ou baixo para essas duas propriedades permite ampla variedade de opções, como por exemplo um valor de referência correspondente à média da amostra, uma proporção fixa, e assim por diante (ver Wachelke e Wolter, 2011). De todo modo, pode-se dizer que nas pesquisas descritivas que empregam a análise prototípica o principal interesse reside, geralmente, na identificação dos elementos da chamada «zona do núcleo central», com alta frequência e baixa ordem de evocação.
Não é nossa intenção aqui entrar em todos os pormenores técnicos dos critérios e procedimentos vinculados à análise prototípica, visto que esses aspectos já foram apresentados e discutidos detalhadamente (ver Wachelke e Wolter, 2011). Nosso interesse recai sobre a adequação de um único aspecto técnico da análise: a partir de que tamanho da amostra a análise prototípica fornece resultados válidos? Nesse sentido, Wachelke e Wolter (2011) apontam que não há critérios precisos para definir um tamanho de amostra adequado. São comuns os estudos com grandes amostras. Podem ser citados exemplos com grupos com mais de 500 participantes (Oliveira, Fischer, Teixeira, Sá e Gomes, 2010) ou 200 (Sá, 1998). No outro extremo, há relato de pesquisas com 25 participantes (Wolter, Gurrieri e Sorribas, 2009).
Wachelke e Wolter (2011) argumentam que de modo geral seria desejável ter amostras maiores, já que
(...) quanto mais numeroso o grupo de participantes, mais estáveis serão os resultados, afinal uma amostra maior tende a gerar resultados menos suscetíveis de influência pela presença de casos extremos e aproximar-se da realidade observada na população de que é extraída; ou seja, permite estimativas mais confiáveis das ocorrências do fenômeno na população. (p. 523)
Até que ponto o tamanho da amostra pode gerar diferenças de resultados devido a artefatos metodológicos? A eventual constatação de diferenças de resultados de um mesmo grupo (população) com amostras de tamanhos diferentes é algo preocupante, pois indicaria que diagnósticos de caracterização de crenças de grupos podem gerar leituras equivocadas de uma efetiva ausência de diferenças empíricas. O presente trabalho visa avaliar o efeito de variações no tamanho da amostra nas configurações dos resultados da análise prototípica. Conforme Wachelke e Wolter (2011), a expectativa seria que amostras maiores tenham resultados mais próximos dos resultados da população, e amostras menores mostrem-se mais distantes e estáveis. É o que se pretende verificar.
Método
Foi realizado um estudo de simulação de resultados da análise prototípica inspirando-se no procedimento de reamostragem denominado bootstrap. Trata-se de considerar a amostra de pesquisa como uma população, implicando a realização de análises a partir de subamostras sorteadas da amostra total, com reposição (Efron e Tibshirani, 1993). No presente caso, foi realizado um estudo a partir do banco de dados de uma pesquisa relatada em Wachelke et al. (2008) contendo respostas para caracterizar as representações sociais de brasileiros sobre a velhice. A partir do banco de dados, o total de participantes (N = 469) foi considerado como uma população e foram realizadas análises prototípicas com subamostras de tamanhos amostrais maiores e menores, de modo a comparar os resultados obtidos e avaliar o efeito da variação de tamanho em sua conformação.
Participantes
Como descrito em Wachelke et al. (2008), participaram do estudo 469 pessoas (55% do sexo feminino), com média de idade de 30.5 anos e desvio padrão de 12 anos (idades de 15 a 59 anos). Os participantes residiam em todas as regiões do país, sendo que o estado com mais participantes foi São Paulo (23% do total).
Instrumento
Os participantes responderam um questionário online com questões de caracterização e uma de evocações. Foi-lhes pedido que escrevessem as cinco primeiras palavras ou expressões inspiradas pela palavra velhice.
Procedimento
À época do estudo de Wachelke et al. (2008), foi realizado um levantamento de dados em comunidades de cidades da rede social Orkut, com convite livre para participar de uma pesquisa sobre velhice e envelhecimento, por meio da divulgação do link com instruções e formulários do questionário. As respostas não foram categorizadas, passaram apenas por uma lematização, o agrupamento de respostas com mesmo radical que pertençam à mesma classe gramatical, conforme Wachelke e Wolter (2011).
Foi realizada a análise prototípica com os dados da amostra total de 469 participantes, e depois foram sorteadas 40 subamostras, 10 para cada tamanho amostral: 25, 50, 100, e 200, e para cada caso foi realizada a análise. O programa de computador Evocation 2000 foi utilizado como auxílio. Para comparabilidade dos resultados das análises com diferentes tamanhos, optou-se pelos seguintes critérios de construção dos quadrantes: consideração do número mais próximo de 50% do total de evocações para determinar o critério mínimo de frequência para inclusão nos quadrantes, e separação de aproximadamente 20% do total de evocações do corpus na zona de alta frequência, para distinguir palavras mais citadas de menos citadas. Quanto à ordem de evocação, optou-se por considerar respostas com ordem média de evocação 3 ou inferior como tendo baixas ordens de evocação (respondidas primeiro).
A comparação dos resultados das subamostras de diferentes tamanhos amostrais foi descritiva. Foram calculados alguns índices sintetizando as 10 subamostras com o mesmo tamanho de amostra, bem como realizada a análise padrão para a amostra total. As seguintes informações para cada conjunto de subamostras foram calculadas: proporção de ocorrência de alguns elementos no primeiro quadrante, para comparação com a amostra total; e índice de comunidade médio dos elementos do primeiro quadrante de cada subamostra em intersecção com o primeiro quadrante obtido com a amostra total. Assim, a análise realizada centra-se na comparação da composição do primeiro quadrante da amostra total com as demais subamostras.
Resultados
A análise referente à amostra total considerou expressões, após lematização, com frequência 9 ou mais (correspondente a 1.9% do total de participantes, e incluindo 49.8% do total de evocações), e teve frequência 39 (separando 19.9% do total de evocações na zona de alta frequência) como critério de ponto de corte de alta frequência. Os seguintes elementos tiveram frequência 39 ou mais e ordem média de evocação inferior 3, compondo assim o primeiro quadrante (frequência e ordem média de evocação entre parênteses): doenças (106; 2.57), solidão (85; 2.85), rugas (56; 2.34), experiência (49; 2.61), sabedoria (47; 2.72), aposentadoria (39; 2.62) e dependência (39; 2.82).
A Tabela 1 apresenta os resultados referentes às intersecções da composição dos primeiros quadrantes resultantes da amostra total e dos conjuntos de subamostras. A parte superior da tabela apresenta as proporções referentes às subamostras quanto ao pertencimento de cada um dos elementos mencionados (com alta frequência e baixa ordem de evocação na amostra total) no primeiro quadrante resultante dessas análises com amostras menores. Se estabelecermos que 0.7 ou mais de proporção de pertença ao primeiro quadrante é um nível aceitável de correspondência com a presença no primeiro quadrante de um elemento na amostra total, há seis elementos do conjunto de subamostras N = 200 e quatro elementos do conjunto N = 100 coincidindo com o primeiro quadrante da amostra total. Para os tamanhos amostrais de 50 e 25, a quantidade de elementos concordantes com o primeiro quadrante da amostra total cai para um e nenhum respectivamente.
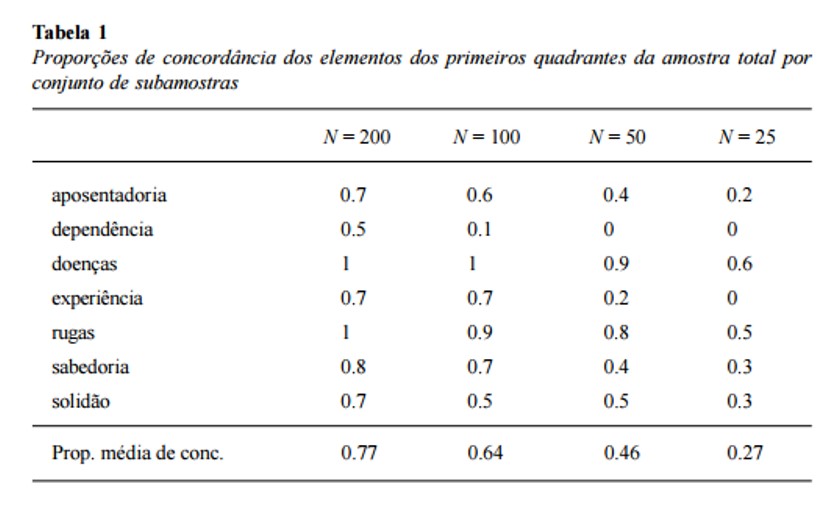
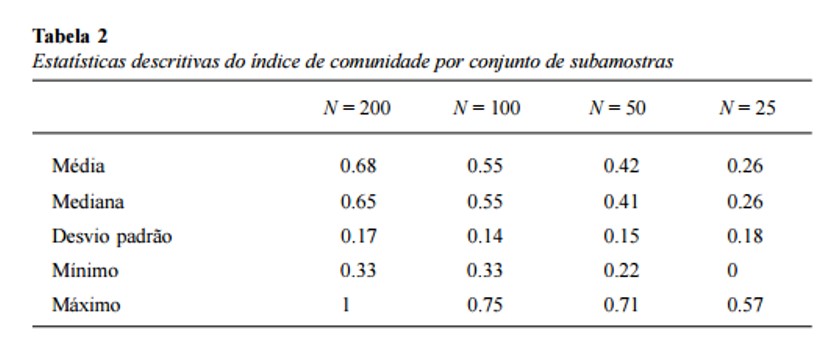
Outra maneira de observar essa correspondência é calculando uma proporção média de concordância com a situação de cada elemento presente no primeiro quadrante da amostra total, somando-se as proporções de cada conjunto de subamostras e dividindo-as por 7, que é o número de elementos considerados. A Tabela 1 mostra tendência de diminuição dessa concordância à medida que o tamanho amostral diminui, variando de 0.77 (N = 200) a 0.27 (N = 25). Uma outra maneira de obter informação semelhante consiste no cálculo do índice de comunidade de corpora de evocações (Wolter e Wachelke, 2013). Esse índice corresponde à divisão do total de evocações presente em dois corpora pelo total de elementos evocados, e permite então avaliar a proporção de elementos comuns aos dois conjuntos de dados, variando de 0 (nenhuma intersecção) a 1 (coincidência total). No presente caso, um índice de comunidade foi calculado sempre considerando o primeiro quadrante da análise total e o primeiro quadrante de cada uma das dez análises de subamostras de cada tamanho amostral. Na Tabela 2 são apresentadas as estatísticas descritivas referentes a cada subamostra. Novamente, observa-se redução progressiva de comunidade entre os corpora à medida que diminui o tamanho amostral, com os conjuntos de subamostras de tamanho 50 e 25 com índices inferiores a 0.50.
Discussão
Os resultados do primeiro quadrante da amostra total indicam uma representação social da velhice compartilhada pela amostra de brasileiros que é marcada por perdas e ganhos. Trata-se de um padrão recorrente na literatura (p. ex., Veloz, Nascimento-Schulze e Camargo, 1999; Wachelke et al., 2008): um período da vida em que há desafios e problemas como o enfrentamento de doenças, solidão e dependência de outras pessoas, bem como sinais físicos como rugas, mas ao mesmo tempo marcado pela aquisição de experiência e sabedoria e mudanças importantes no mundo do trabalho, como a aposentadoria. No entanto, o objetivo principal do estudo não foi o de descrever em detalhe a estrutura de uma representação social, mas o de investigar a extensão dos desvios de padrões de resultados obtidos com subamostras da amostra inicial maior.
Os resultados indicam que há uma diferença considerável no padrão de classificação de elementos como provavelmente centrais ou periféricos conforme o tamanho amostral do banco de dados associado à análise prototípica. Foi observado um nível de divergências majoritário no que diz respeito aos dois menores tamanhos amostrais considerados (50 e 25), o que implica a necessidade de muita cautela na realização de análises prototípicas com amostras reduzidas. Com amostras de 100 e 200 não foram repetidas exatamente as mesmas composições de primeiro quadrante observadas na amostra definida como total, mas houve maior número de concordâncias dos resultados, indicando que, mesmo na impossibilidade de identificar um «padrão de ouro» ou ponto claro em que há validade dos resultados, a aproximação foi satisfatória.
É comum a realização de análises prototípicas com ampla variação amostral em estudos diferentes, e não é discutido na literatura da área o impacto do uso dessa estratégia com bancos de dados de tamanhos discrepantes. Considera-se que o objetivo de verificar até que ponto há uma mesma indicação de padrões a partir de tamanhos amostrais diferentes foi atingido, e nesse sentido reforçam-se com comprovação empírica as recomendações antes especulativas de Wachelke e Wolter (2011) de que há necessidade de certo volume de dados para gerar uma análise prototípica mais estável. Noutras palavras, com cerca de 100 participantes, pelo menos em configurações semelhantes às avaliadas no presente estudo, provavelmente os resultados não diferirão tanto de outros obtidos com amostras maiores. Com menos que isso, não é possível ter tanta segurança, e com amostras de 25 ou menos basicamente há grande probabilidade de se obterem configurações casuais, o que recomenda a não utilização da análise prototípica com pequenas amostras.
Cabe esclarecer, evidentemente, que o estudo realizado tem as suas limitações. Primeiramente, poder-se-ia questionar a respeito da do modo como se utilizou a técnica do bootstrap. Geralmente trata-se de procedimento associado a testes estatísticos, no cálculo de parâmetros, e com números de amostras bem maiores. No presente caso, assumidamente houve uma inspiração nessa lógica no processo de reamostragem, isto é, entende-se que o princípio subjacente à técnica permitiria a construção de um procedimento para avaliar o efeito de variações na obtenção da amostra em relação a uma população de amostras, que no caso foi a amostral total de participantes. Portanto, optou-se por sua utilização, e haja vista a coerência dos resultados, julga-se que essa adaptação tenha sido satisfatória. Outro aspecto que poderia ser questionado diz respeito à quantidade de subamostras de cada conjunto de tamanho amostral. O estudo foi realizado com apenas dez subamostras por tamanho amostral, e a princípio não haveria limites para realizá-lo com números maiores. Porém, dado que não foi utilizada estatística inferencial, optando-se somente pela estatística descritiva, e também pela consistência dos resultados obtidos, indicando a direção de menor convergência à medida que o tamanho da amostra afasta-se do tamanho da amostra total, é possível avaliar que o estudo cumpre suas funções com o delineamento executado. É contudo evidente que esforços para verificar o potencial de replicabilidade desses resultados com outros objetos e grupos, bem como outras operacionalizações para reamostragem, podem ser frutíferos para avaliar a generalidade dos padrões encontrados, em sintonia com a atual revalorização da importância dos estudos de replicação em psicologia social.
Além disso, pode chamar atenção a escolha de optar por uma comparação com uma amostra total de referência, com 469 participantes, ou seja, a equivalência dessa amostra a uma população, sendo que na verdade essa mesma amostra também é um retrato aproximado do que se estima ser a realidade empírica das representações de brasileiros sobre a velhice. Aliás, se for realizada uma avaliação mais radical, o próprio estudo de Wachelke et al. (2008) permite apenas aproximar uma população de brasileiros com um certo perfil – as pessoas com acesso à internet pertencentes a certos tipos de comunidades numa rede social no momento da pesquisa. Além disso, é pertinente considerar também que a concordância dos resultados dos tamanhos amostrais de 100 e 200 com a amostra de referência não é perfeita porque essa mesma amostra contém erro amostral, enquanto que os dados provenientes da reamostragem permitiriam atenuar esse viés, especialmente em casos em que são empregadas quantidades significativamente maiores de reamostras (como 500 ou 1000, por exemplo) 1. Nesse sentido, a reamostragem poderia ser um recurso ainda mais útil e valioso se incorporada às pesquisas em representações sociais.
De todo modo, no presente trabalho, o procedimento foi escolhido e utilizado de forma simples meramente para apontar que, mesmo sem levar em consideração a capacidade de generalização estatística de resultados de uma amostra para uma população, prática padrão em levantamentos verdadeiramente probabilísticos, a flutuação e divergência em tamanhos amostrais já causa diferenças que não podem ser ignoradas. Não conhecemos estudos com a análise prototípica que utilizem um processo de amostragem aleatória e com tamanhos de amostra suficientemente grandes para permitir um grau razoável de generalização dos resultados para as populações, os grupos reais a que se referem os estudos. A análise prototípica é uma técnica exploratória usada com amostras de conveniência, mas que permite alguma diversidade. A finalidade exploratória dessa técnica certamente desaconselharia a realização de um projeto tão amplo que viabilize generalização estatística, até mesmo porque é possível apenas um trabalho inicial de levantamento de propriedades gerais dos elementos que necessita de ulterior confirmação, como indicam diversas referências clássicas na área, como Sá (1996). Nesse sentido, haveria baixa relação custo-benefício de executar um projeto com a magnitude necessária para tal generalização.
O recurso de optar por uma amostra maior como um ponto de referência serviu como ilustração da instabilidade da apresentação dos resultados da análise de evocações mesmo com os mesmos critérios para construção dos quadrantes em todas as condições. À medida que temos amostras maiores, cresce por um lado a diversidade de respostas possíveis e aumenta o espaço para diferenciação de alguns elementos. A construção de quadrantes pelos mesmos critérios pode resultar em configurações diferentes conforme mudam os tamanhos amostrais; isso é coerente com a consideração da análise prototípica como uma simples técnica de apresentação e organização de resultados, como apontam Wachelke e Wolter (2011). A análise prototípica não deve ser pensada como uma técnica de análise estatística inferencial que necessita de uma amostra com tamanho mínimo para sua realização efetiva, mas sim como uma estratégia que pode ser utilizada para organizar dados com mais ou menos sucesso, conforme sua finalidade. No entanto, ressalta-se que pode haver grande divergência desses resultados devido a características de cada amostra pesquisada.
Assim, entende-se que deve ser considerada com seriedade a afirmativa de que a análise prototípica permite uma primeira exploração do conteúdo de uma representação social sem dispensar uma caracterização mais sólida do estatuto central ou periférico de um elemento. Esse tipo de verificação, conforme a teoria clássica do núcleo central, deve ser determinada preferencialmente com técnicas confirmatórias como a técnica do questionamento ou mise en cause, a técnica dos esquemas cognitivos de base, questionários de caracterização ou procedimentos que permitam avaliar outras propriedades além da mera frequência de evocações – alguns exemplos incluem a indução por cenário ambíguo, o uso de tarefas de escolha por bloco associado a análises de similitude, e o uso de questões complementares para avaliar propriedades de evocações (para informações aprofundadas sobre essas e outras técnicas de estudo da centralidade em representações sociais, ver Abric, 2003).
Finalmente, entende-se que a análise prototípica fornece auxílio para que o pesquisador tenha bases para refinar seu entendimento sobre o funcionamento estrutural de uma representação social. Nesse sentido, trata-se de uma técnica que dá subsídios para avaliar o consenso de uma amostra acerca do conteúdo associado a uma temática de representação social. No entanto, é uma técnica com benefícios e limitações bem definidas, não uma receita mágica capaz de oferecer um diagnóstico de qualquer representação social para qualquer grupo, apesar de uma aparência de objetividade fornecida por indicadores numéricos. Além disso, trata-se de técnica subordinada a decisões fundamentais que contextualizam a sua utilização – por exemplo, até que ponto uma amostra de uma pesquisa de representações sociais corresponde a um representante válido de um grupo social real? O que caracteriza de fato o pensamento compartilhado, o consenso do grupo a respeito de um objeto social? São aspectos que engendram discussões amplas (para considerações a respeito, ver Wachelke, 2012; Wagner, 1994, 1995) e de suma importância para entender a extensão em que técnicas como a análise prototípica podem ser úteis, visto que a mera aplicação irrefletida dessa estratégia não resolve ou supera eventuais contradições na operacionalização de aspectos teóricos das representações sociais em pesquisas.
Referências
Abric, J.-C. (Dir.) (2003). Méthodes détude des représentations sociales. Ramonville-Saint Agne: Érès.
Efron, B. & Tibshirani, R. (1993). An introduction to the bootstrap. New York: Chapman & Hall.
Flament, C. & Rouquette, M. L. (2003). Anatomie des idées ordinaires. Paris: Armand Colin
Moscovici, S. (1976). La psychanalyse: son image et son public. Paris: PUF - Presses Universitaires de France.
Natividade, J. C. & Camargo, B. V. (2011). Representações sociais, conhecimento científico e fontes de informação sobre AIDS. Paidéia, 21(49), 165-174.
Oliveira, D. C. (2013). Construção e transformação das representações sociais da AIDS e implicações para os cuidados de saúde. Revista Latino-Americana de Enfermagem, 21(Especial), 276-286.
Oliveira, D. C., Fischer, F. M., Teixeira, M. C. T. V., Sá, C. P., & Gomes, A. M. T. (2010). Representações sociais do trabalho: uma análise comparativa entre jovens trabalhadores e não trabalhadores. Ciência e Saúde Coletiva, 15(3), 763- 773.
Pecora, A. R. & Sá, C. P. (2008). Memórias e representações sociais da cidade de Cuiabá, ao longo de três gerações. Psicologia: Reflexão e Crítica, 21(2), 319-325.
Sá, C. P. (1996). Núcleo central das representações sociais. Petrópolis: Vozes.
Sá, C. P. (1998). A representação social da economia brasileira antes e depois do «Plano Real». Em A. S. P. Moreira & D. C. Oliveira (Eds.), Estudos interdisciplinares de representação social (pp. 49-69). Goiânia: AB.
Veloz, M. C. T., Nascimento-Schulze, C. M., & Camargo, B. V. (1999). Representações sociais do envelhecimento. Psicologia: Reflexão e Crítica, 12(2), 479-501.
Vergès, P. (1992). Lévocation de largent: une méthode pour la définition du noyau central de la représentation. Bulletin de Psychologie, 45(405), 203-209.
Wachelke, J. F. R. (2012). Representations and social knowledge: an integrative effort through a normative structural perspective. New Ideas in Psychology, 30(2), 259-269.
Wachelke, J. F. R., Camargo, B. V., Hazan, J. V., Soares, D. R., Oliveira, L. T. P., & Reynaud, P. D. (2008). Princípios organizadores da representação social sobre envelhecimento: dados coletados via internet. Estudos de Psicologia (Natal), 13(2), 107-116.
Wachelke, J. F. R. & Wolter, R. (2011). Critérios de construção e relato da análise prototípica para representações sociais. Psicologia: Teoria e Pesquisa, 27(4), 521-526.
Wagner, W. (1994). Fields of research and socio-genesis of social representations: a discussion of criteria and diagnostics. Social Science Information, 33(2), 199-228.
Wagner, W. (1995). Social representations, group affiliation, and projection: knowing the limits of validity. European Journal of Social Psychology, 25(2), 125-139.
Wolter, R. P., Gurrieri, C., & Sorribas, E. (2009). Empirical illustration of the hierarchical organisation of social thought: a domino effect? Interamerican Journal of Psychology, 43(1), 1-11.
Wolter, R. P. & Wachelke, J. (2013). Índices complementares para o estudo de uma representação social a partir de evocações livres: raridade, diversidade e comunidade. Psicologia: Teoria e Prática, 15(2), 119-129.
1 Devemos essa constatação à observação pertinente de um dos pareceristas que avaliou o artigo, a quem somos gratos.
*, *** Universidade Federal de Uberlândia, Brasil.
**Universo/Universidade do Estado do Rio de Janeiro, Brasil.
*joao.wachelke@ufu.br
**rafaelpeclywolter@gmail.com
***fabiolarmatos@yahoo.com.br
Recebido: 02 de fevereiro de 2016
Aceitado: 25 de julho de 2016

{kind=link}
{kind=link}