










Servicios Personalizados
Revista

Articulo
 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares en
SciELO
Similares en
SciELO
Compartir

 Permalink
PermalinkJournal of Economics, Finance and Administrative Science
versión impresa ISSN 2077-1886
Journal of Economics, Finance and Administrative Science v.15 n.28 Lima jun. 2010
Falibilidad del método rough set en la conformación de modelos índice de riesgo dinámico en la predicción del fracaso empresarial
Fallibility of the Rough Set Method in the formulation of a failure prediction index model of dynamic risk
Rubén Mosqueda1
1. Doctor en Ciencias Económicas y Empresariales. Profesor Investigador de tiempo completo en el Tecnológico de Monterrey, Campus Irapuato. Miembro del Sistema Nacional de Investigadores del CONACYT, México.
Resumen
La quiebra empresarial es uno de los problemas que más preocupan a la teoría financiera. Son muchos los esfuerzos y escasos los avances logrados; persiste el problema de diseño experimental en los modelos que se han planteado, fundamentalmente por dos causas: desconocimiento sobre el proceso de quiebra que sigue cada empresa y por el uso exclusivo de la información contable para conformar dichos modelos. En un avance natural aparece el Modelo RPV como un intento por suplir las deficiencias hasta ese momento. El modelo logra mejorías significativas al incluir también información cualitativa; sin embargo, se advierte que la teoría Earning Power, en la que se fundamenta, podría traer problemas de especificación y de estructura cuando se aplique a otra muestra de empresas. Los resultados empíricos no sólo comprobaron estas sospechas, sino que permitió robustecer el modelo asignando los coeficientes de respuesta de las variables explicativas más ajustados al riesgo.
Palabras clave: Quiebra empresarial, Teoría Rough Set, modelos predictivos, GRACH, Teoría Earning Power.
Abstract
Bankruptcy is one of the most important entrepreneurial problems studied by the Financial Theory. Despite this great effort, there is not a significant progress in order to predict the economic failure. In this way, the evidence suggests that this problem, related to the experimental design, is still present because of two main reasons: ignorance about bankruptcy process and the use of the accounting information as the unique input to construct the predictive models. In order to solve those problems, the RPV Model included both qualitative and accounting information with excellent results. So, the Earning Power Theory –upon which the RPV is based– could cause problems of specification and structure in the model. Empirical results not only verify those suspicions, but they made a stronger model possible by introducing to the equation ERC values adjusted to the risk.
Keywords: Bankruptcy, Rough Set Theory, Predictive Models, GRACH, Earning Power Theory.
INTRODUCCIÓN
En el éxito empresarial, es importante la eficacia administrativa, de igual forma las empresas deben corresponder al dinamismo del mercado que se traduce en oportunidades, pero también en riesgos para las organizaciones. Entonces, el reto para el administrador consiste en adaptar a la empresa ante los imponderables, tanto del mercado como organizativos, que dificultan dichas tareas. Para ello el control preventivo es fundamental.
Fue a partir del modelo de Z-score que la teoría financiera pondera la importancia de contar con modelos financieros prospectivos que ayudasen a los administradores en sus tareas. Desde entonces, se han desarrollado un sinnúmero de modelos predictivos con cierta capacidad para adelantarse al fracaso empresarial, y su claro efecto: la quiebra. La evidencia sugiere que los modelos se muestran incapaces para replicar el éxito predictivo fuera de las empresas de control. En buena medida, esta incapacidad podría deberse al empleo exclusivo de la información contable para construir dichos modelos predictivos. Así, el diseño de modelos más complejos e integrales, que consideran no solo la información contable sino información que refleje el estilo y forma administrativo, ha contribuido al avance y a la comprensión del fenómeno de quiebra empresarial.
Uno de tales constructos es el Modelo RPV (Mosqueda, 2008). Este modelo mostró un grado de precisión predictiva muy superior a los modelos desarrollados hasta ese momento. Parte de su éxito descansa en el uso de la técnica Rough Set para escoger los factores que inciden en el fracaso empresarial. No obstante, se han observado ciertas inconsistencias metodológicas que invita a perfeccionarlo. En este sentido, el objetivo de este documento es validar la teoría Earning Power, a partir de la predictibilidad del Modelo RPV, y detectar posibles problemas de especificación y de estructura del modelo. Para ello, será necesario hacer un estudio exploratorio-evolutivo de la teoría de quiebra más relevante y, de esta suerte, encontrar explicaciones sobre las posibles fallas.
Para lograr este propósito, el trabajo se ha dividido en ocho apartados. En el primero de ellos se realiza un análisis sobre el concepto de fracaso empresarial y su relación con la quiebra. En la segunda sección desarrollamos la evolución que ha tenido el tema. El tercer apartado analiza los problemas que han hecho que los modelos predictivos fracasen. Luego, en el cuarto apartado se realiza un análisis crítico sobre los modelos basados en la información contable, principal fuente para construirlos. En la quinta sección analizamos el modelo RPV y en la sexta efectuamos un estudio empírico del modelo ante un nuevo colectivo de empresas. En el séptimo segmento se ejecuta una prueba estadística para comprobar la robustez del modelo RPV modificado y, finalmente, las conclusiones del tema se señalan en el octavo apartado.
Particularidades sobre el fracaso y la quiebra empresarial
Si bien el fenómeno de quiebra empresarial no resulta nuevo dentro del estudio financiero1, debemos advertir que dicho fenómeno presenta distintos niveles de complejidad cuyo reconocimiento dependerá de la normativa, pero también influyen el estilo y la eficacia en la gestión para que se dé. La práctica parece demostrar que la gestión eficiente dota de mejores posibilidades de supervivencia a las empresas. A pesar de la basta literatura desarrollada, es difícil encontrar una concepción teórica homogénea y única del fracaso2. Si nuestra intención es entender la complejidad del fenómeno de quiebra, es necesario asociarlo con el fracaso empresarial. Sin embargo, lo que es verdad es que no se ha alcanzado a entender el fenómeno en su toda su magnitud y eso se traduce en un escaso consenso sobre lo que se entiende como fracaso empresarial o la forma en cómo se mide.
Algunos tratadistas apelan a una disminución en las condiciones de rentabilidad como elemento que evidencia el fracaso, en tanto otros se refieren a la incapacidad para hacer frente a los compromisos adquiridos con sus acreedores; algunos autores simplemente se centran en el comportamiento en las ventas. Para Beaver (1966), la empresa es una reserva de activos líquidos en la que hay flujos de entrada y de salida de tesorería, sustentando su enfoque en que la reserva sirve, por definición, como un colchón que permite salvar diferencias temporales entre estas entradas y salidas.
Aduciendo a las limitaciones de la anterior definición, Altman, Marco y Varetto (1994) estiman que el fracaso empresarial comienza como un fenómeno propiciado por un evento catastrófico en la organización, aunque reconoce que puede manifestarse como el resultado final de un lento proceso de declinación. Por su parte, McRobert y Hoffman (1997) asumen que el fracaso empresarial es un proceso que se inicia por defectos en el sistema administrativo que desembocan en decisiones desacertadas, en deterioro financiero y en un colapso de toda la empresa. Perfeccionando las propuesta clásicas, Abad, Arquero y Jiménez (2003) plantean la hipótesis de que el fracaso financiero se produce cuando el deudor es incapaz de atender a sus compromisos, ya que cualquier acreedor estaría dispuesto a aplazar el cobro de una deuda (o a conceder un préstamo) si se le compensa suficientemente y se le garantiza el reembolso. Por lo tanto, las expectativas favorables no solo aumentarían la capacidad de endeudamiento, también atraerían a los inversionistas. Más reciente, Mosqueda (2008) concibe el fracaso como el momento, conforme a un umbral, en que se detecta el incumplimiento de los objetivos financieros y estratégicos marcados por la gerencia que, en su conjunto, posibilitan el riesgo de quiebra de los negocios. De todos estos enfoques se deduce que una de las consecuencias más importantes del fracaso empresarial es la quiebra del negocio, entendiendo como quiebra empresarial los problemas serios de liquidez-solvencia que no pueden ser resueltos y causan el cierre efectivo del negocio.
EL DESARROLLO DE LOS MODELOS PREDICTIVOS
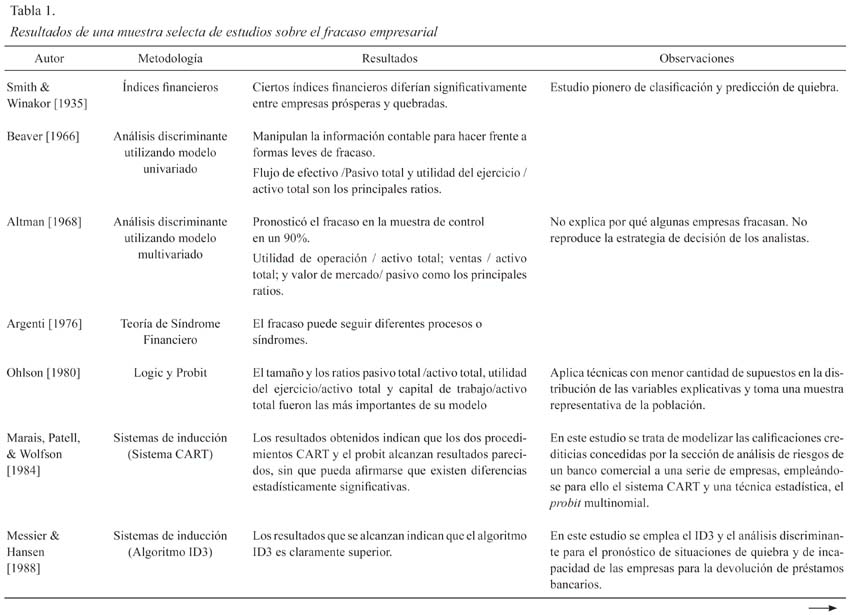
Motivados al encontrar que ciertos índices contable-financieros diferían significativamente entre empresas en quiebra y empresas prósperas, Smith y Winakor (1935) proponen un modelo simple que les permite clasificar a las empresas y predecir su quiebra. Sin embargo, los estudios hasta esa época fueron considerados poco formales (serios) y no fue sino hasta la década de los 60 en que se comienzan a utilizar modelos matemáticos y estadísticos más robustos. Este primer acercamiento científico serio conduce a los especialistas financieros a utilizar la información contable, que introducen en tests dicotómicos, para identificar aquellos ratios que mejor correspondían a la realidad de las empresas estudiadas3. De esta época destaca el Modelo Z-score de Altman (1968) que no solo le permite una interpretación más clara del efecto de cada variable en el modelo, sino que define puntos de corte, lo cual se traduce en un aumento de la eficiencia del esfuerzo de análisis, al reducir el tiempo dedicado a las empresas con una probabilidad de quiebra muy alta o muy baja, y así aumentar la eficiencia de la dirección para evaluar aquellas firmas que se encuentran en la zona gris4.
El predictor Z-score, conformado mediante mecanismos de análisis discriminante, combina varios de los ratios financieros más significativos dentro de una derivación estadística y desarrollada en una muestra de empresas industriales. Las variables del Z-score identificadas por Altman son las siguientes:

en donde K es el capital de trabajo; ATOT representa al activo total; UTRET son las utilidades retenidas; EBIT es la utilidad antes de intereses e impuestos; PTOT son los pasivos totales; Pit es el precio de la acción i en el momento t, y V son las ventas totales de la empresa analizada. El éxito de este modelo en pronosticar el fracaso (superior al 90% en la muestra de control, al 80% en una muestra de empresas de bajo rendimiento y al 70% dos años antes del fracaso) supuso una revolución en la investigación contable que, en aquellos momentos, se estaba planteando: la eliminación del análisis mediante ratios como técnica analítica para evaluar el rendimiento de las empresas.
A partir de este trabajo revolucionario se han desarrollado un sinnúmero de modelos predictivos del riesgo de quiebra, aunque estudios recientes sugieren que estos no son mejores que el modelo inicial de Altman. Durante los siguientes 40 años, el esfuerzo dirigido a la mejora del Z-score ha sido impresionante. El diseño experimental de Altman se aplicó a otros períodos, sectores y países, empleando técnicas estadísticas, variables, horizontes temporales y diseños muestrales idénticos o levemente diferentes. Sin embargo, una deficiencia de diseño experimental es que la mayoría de los trabajos que aplican esta técnica de análisis discriminante no cumplen con los supuestos que requiere la estimación de máxima verosimilitud.
Luego, durante la década de 1970, los estudios del fracaso empresarial se orientaron, en su mayoría a la técnica del Análisis Discriminante Múltiple (Libby, 1975; Wilcox, 1973). Sin embargo, debido a sus características operacionales, la mayoría de los autores que escribió sobre quiebra diseñaron modelos más complejos, pero al mismo tiempo más precisos, para determinar la probabilidad de quiebra de la empresa. Tales son los modelos Logit (Ohlson, 1980), el análisis Probit (Zmijewski, 1984) y, en la última década, las Redes Neuronales. Paradójicamente, Mosqueda (2008) recopila evidencias que sugieren que la capacidad explicativa de algunos de los modelos predictivos posteriores más utilizados no superan al modelo Z-score que sigue estando mejor especificado.
Así, el avance doctrinario de la predicción de la quiebra empresarial se ha centrado en la posibilidad de que la determinación de la solvencia futura de una empresa puede ser entendida como una operación de clasificación; es decir, una información inicial o conjunto de atributos asociados a una empresa, y extraídos en su mayor parte de los estados contables de la misma. Luego, entonces, lo que pretendería el analista financiero sería tomar la decisión de clasificar a esa empresa dentro de una categoría concreta de riesgo financiero, de entre varias posibles. Por lo tanto, la selección ha de estar basada en reglas prácticas o heurísticas, debiendo fijarse también un criterio de suficiencia para determinar cuándo las soluciones encontradas son satisfactorias. Todo ello concuerda plenamente con el paradigma de la racionalidad limitada, que gobierna los procesos de decisión en el ámbito económico.
Observamos, sin embargo, que estas técnicas presentan limitaciones pues parten de hipótesis más o menos restrictivas que, por su propia naturaleza, la información económica, y en especial los datos extraídos de los estados financieros de las empresas, no van a cumplir, perjudicando los resultados. Así nacen los modelos de inteligencia artificial cuyo antecedente lo encontramos en el test de Turing. Este test postula que una máquina presenta comportamiento inteligente si un observador es incapaz de distinguir entre las sucesivas respuestas proporcionadas por la máquina y un ser humano. La ventaja de estos modelos es que no parten de hipótesis preestablecidas y se enfrentan a los datos de una forma totalmente exploratoria, configurándose como procedimientos estrictamente no paramétricos. Tal es el caso de la Teoría Rough Set (Pawlak, 1991).
LA CRISIS DE LOS MODELOS PREDICTIVOS
A pesar de no contar con una teoría de la quiebra suficientemente robusta, los tratadistas financieros han trabajado en la elaboración de modelos y técnicas que permitan, más que entender el fenómeno, advertir al administrador sobre la cercanía al fracaso. Por otra parte, la desarticulación entre el avance mostrado por las técnicas cuantitativas y la teoría de la quiebra ha propiciado una crisis del diseño experimental típico en donde se advierte una incapacidad metodológica para definir modelos estables (los propuestos por cada investigador para cada período, sector o país son diferentes) y con tasas de éxito adecuadas en muestras de control (ver la Tabla 1)5. Como respuesta, se crean un sinfín de teorías tratando de explicar dichas inconsistencia y, así, robustecer la capacidad predictiva de los modelos. Resulta significativo que los modelos empíricos se comporten bien a la hora de clasificar, de describir, pero no de predecir; en tal sentido, mucho tuvo que ver el análisis heurístico que se implementó a través de la aplicación de técnicas estadísticas en ausencia de una teoría de la quiebra aceptable y, en especial, sobre datos extraídos de los estados financieros poco fiables, perjudicando los resultados6.
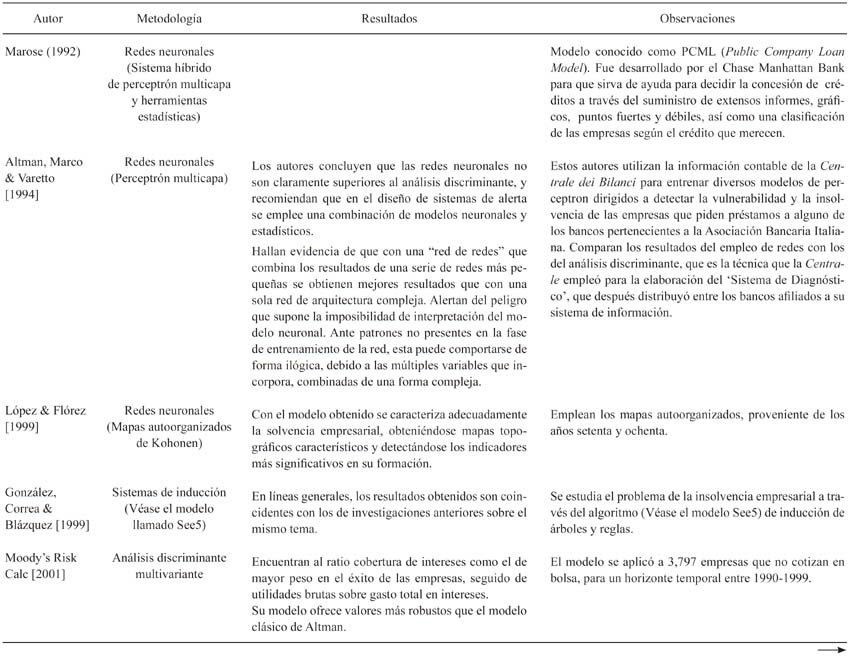

La evidencia documental indica que los modelos predictivos actuales no son estables en el tiempo, pues muestran resultados inconsistentes a lo largo del tiempo; esta circunstancia ha llevado a los tratadistas en indagar sobre los aspectos puntuales en los que fallan. Todo parece indicar que el esfuerzo debería centrarse en la calidad y el tipo de datos que alimenta al modelo. Sin embargo, lamentablemente la generalidad de los modelos se vale de la información contable. Algunos autores alegan que es preciso clasificar los procesos de fracaso empresarial porque existe la posibilidad de que algunas empresas, que están experimentando tensiones financieras o formas leves de fracaso, manipulen la información contable para aumentar la confianza del público (Wilcox, 1971). Otros afirman que las técnicas estadísticas sobreajustan los modelos predictivos para alcanzar el máximo éxito clasificatorio en la muestra, reduciendo su validez externa (Hair et al., 1999). En general, se argumenta que las empresas parecen seguir diferentes procesos que desembocan en el fracaso financiero y, por lo mismo, no es posible establecer sobre qué variables financieras ni valores en las mismas se determina la futura solvencia o insolvencia de una firma (Ball, Kothari, & Robin, 2000; Laitinen, 1993)7.
CRÍTICA A LOS MODELOS BASADOS EN LA INFORMACIÓN CONTABLE
Una característica común en la mayor parte de los estudios del fracaso empresarial es que se valen exclusivamente de la información contable, transpolada a razones financieras, para predecir el futuro del negocio. Aún y cuando la información cualitativa no está exenta de brindar información parcial, al igual que la información contable, los teóricos coinciden en que la mezcla de estos dos tipos de información en los modelos predictivos robustece sus predicciones. Así, a pesar de que la importancia de los ratios en el estudio del fracaso empresarial no puede ser negada, su uso ha sido por demás criticado, fundamentalmente por las siguientes dos cuestiones: (a) los constructos, que se elaboran con ratios financieros que no tiene una teoría que justifique su uso y, a su vez, los modelos y los resultados que de estos se derivan, serían simplemente un ejercicio estadístico; (b) estos modelos son incapaces de pronosticar la quiebra de las empresas de aquellas que presentan una alta clasificación crediticia debido a que omiten uno o varios elementos importantes, tales como la relación entre riesgo-rendimiento de manera adecuada. Estas dos circunstancias dan pie a los siguientes razonamientos:
-
Restricción. Dado que la obligación por presentar públicamente la información contable y su elaboración depende de criterios basados en tipo/tamaño de empresa, los modelos de predicción del fracaso empresarial que utilizan ratios están restringidos y, en consecuencia, por los datos de este tipo de compañías que conocen el criterio.
-
Imagen fiel. Cuando la elaboración de los modelos predictivos se basa en los ratios financieros, los investigadores asumen implícitamente que la información contable anual les proporciona la imagen fiel y verdadera sobre la situación financiera de la empresa. Debemos reconocer que existe información contable viciada que no puede proporcionar la imagen real del negocio. Rosner (2003) encontró evidencia de que las empresas fracasadas manejan ganancias al alza para dar una imagen positiva sobre su situación financiera, especialmente cuando se encuentran al borde del fracaso.
-
Parcialidad. Desde el momento en que los investigadores introducen solo ratios financieros a sus modelos predictivos, ellos asumen que los indicadores relevantes, ya sea de fracaso o éxito, quedan captados por la información contable. La experiencia muestra que no toda la información relevante queda incluida en los Estados Financieros; luego, si los estados contables no brindan toda la información requerida, se generan problemas de valores perdidos. Argenti (1976) asegura que a pesar [de] que los ratios financieros pueden mostrarnos que algo anda mal dudo que alguien pudiera atreverse a predecir el colapso o fracaso con la sola evidencia de estos ratios. (p. 62). Por su parte, Maltz, Shenhar y Reilly (2003) demostraron empíricamente que el uso de medidas financieras como indicadores únicos de desempeño de la organización es limitado.
Por ello, cada vez un mayor número de autores opta por incluir indicadores no contables o cualitativos en los modelos predictivos del fracaso empresarial. La evidencia encontrada por estos estudios nos sugiere que la información no financiera y cualitativa puede resultar particularmente apropiada cuando se estudia el fracaso empresarial de las pequeñas empresas, pues, a priori, la veracidad en la información contable en este tipo de empresas es menor. Además de las variables no contables y cualitativas, las características de la empresa –como el tipo de industria y el tamaño– han probado ser una variable muy importante en la predicción del fracaso empresarial. Laitinen (1993), por ejemplo, encontró evidencia de que las empresas pequeñas son más susceptibles al fracaso empresarial. -
Representatividad. Parece no haber consenso sobre cuál es el tipo de ratios más representativo cuando se da el fracaso empresarial. A pesar de que diversos estudios han comparado las habilidades predictivas de los ratios financieros basados en partidas de devengo (Casey y Bartczak, 1984) contra los basados en flujos de caja (Gentry, Newbold, & Whitford, 1987), no existe consenso sobre cuáles son los que mejor capacidad predictiva tienen. Una solución adoptada ante esta dicotomía sería la incorporación de ratios de valor añadido. En un estudio de 1991, Declerc, Heins y Van Wymeersch demostraron que cuando se incorporan indicadores financieros más complejos a los modelos predictivos, como los ratios de valor añadido, se incrementa notablemente la capacidad predictiva.
EL MODELO RPV Y LA METODOLOGÍA ROUGH SET
Este apartado de dedica a analizar las características básicas y los resultados obtenidos por el modelo denominado Ratio Ponderado de Valoración (RPV), propuesto por Mosqueda (2008), para predecir la quiebra en las micro y pequeñas empresas. La novedad que aporta este modelo, a diferencia de los desarrollados hasta este momento, es que incorpora tanto información contable como información cualitativa; elabora su índice a través de la combinación (superposición) de las principales variables que inciden sobre la situación económica de la empresa en un período determinado con un costo de oportunidad en el mercado en condiciones de equilibrio. La propuesta para calcular el desempeño de la empresa queda expresada en la siguiente ecuación:
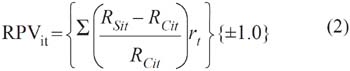
En este caso, RSit es la variable (ratio, indicador) estándar; RCit es la variable (ratio, indicador) simple8; rit es la ponderación para cada ratio representativo y sería el proxy de los coeficientes de respuesta del resultado (ERC)9. Como se observa, es preciso tomar en cuenta el signo, ±1.0, de la variación según la naturaleza de RCit. De acuerdo con este modelo, la maximización se alcanza cuando el resultado es mayor a cero, Max(RPV)>0, y se interpreta como un rendimiento por encima del que otra empresa o proyecto similar obtendría en el mercado. Una particularidad de las tareas para encontrar las variables (RCit) es que Mosqueda (2008) aplicó la metodología Rough Set sobre una muestra de control de 230 pequeñas y microempresas mexicanas.
Los descubrimientos obtenidos por el RPV original sugieren que el fracaso empresarial se debe a los siguientes indicadores10: la Presión Financiera (PEF), a la habilidad para detectar las Oportunidades de Negocio (ONE), al Sistema de Gestión Financiera (AFI), a la Dotación en Equipo y Tecnología (DET), a la Rentabilidad de la Inversión (ROI) y algún Indicador Específico propio a cada Sector (IES)11. De estos indicadores destacan el Ratio Presión Financiera y las Oportunidades del negocio como los más relevantes. Luego, la función econométrica que se puede derivar quedaría:
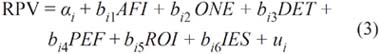
Debido a que el RPV es un modelo índice de riesgo dinámico cuyo propósito es encontrar el riesgo de quiebra de las empresas desde un punto de optimización económico, un RPVit>0 indicaría que la empresa no tendría problemas de quiebra; pero, esta restricción, no determina la optimización de los resultados. Por ello es que el resultado se le contrasta contra el rendimiento óptimo del mercado (como lo puede ser la tasa libre de riesgo) y, así, determinar el excedente económico real. Es decir:
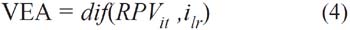
en donde VEA es el valor económico añadido, RPVit es el desempeño económico de la empresa i en el momento t, encontrado por el modelo RPV; ilr es la tasa libre de riesgo (tasa CETE para el caso de México) que estaría representada por αi en la función econométrica12.
La teoría Rough Set
La teoría Rough Set fue originalmente desarrollada en los años ochenta a partir de los fundamentos teóricos de Pawlak (1991), y actualmente expandida en el trabajo de Greco, Matarazzo y Slowinski (1998) como herramienta formal para tratar con la incertidumbre o la vaguedad inherente a un proceso de decisión. Aunque hoy en día hay extensiones de esta teoría, nos estamos refiriendo al enfoque clásico que es un tanto distinto de la teoría estadística de la probabilidad como de la teoría de lógica difusa (fuzzy set).
Desde este punto de vista, ubicamos al modelo Rough Set como un método perteneciente a los Sistemas de Inducción de Reglas y Árboles de Decisión (o métodos de criterio múltiple), cuyo enfoque, a su vez, se encuadra dentro de las aplicaciones de la Inteligencia Artificial.
El modelo utiliza la experiencia de una forma objetiva, a través del estudio de la experiencia histórica de una manera cuantitativa, para así explicitar reglas que, resumiendo y objetivando la experiencia acumulada, ayuden en las decisiones futuras. Los rough sets, que la comunidad científica ha decantado en denominar conjuntos aproximados en español, podrían entenderse como vago, impreciso; por tanto, y de manera intuitiva, un rough set es un conjunto de objetos que, en general, no pueden ser caracterizados de manera precisa en cuanto a la información disponible y de valores de un conjunto de atributos.
Evidentemente, debido a estas características, la teoría Rough Set desarrollada resulta muy útil para descubrir las dependencias entre los atributos de las observaciones, evaluar el nivel de significación y para el tratamiento de datos o información inconsistente. En tal sentido, la teoría de los rough sets representa el cúmulo del conocimiento dentro de una tabla de decisión, que es una técnica particular a un sistema de información. Las filas de la tabla corresponden a los objetos y las columnas a los atributos. Para cada objeto, en función de sus atributos específicos, existe un valor conocido llamado descriptor. Cada fila de la tabla contiene descriptores que representan información sobre una observación de la población. Generalmente, la información relativa a todo el conjunto de atributos se divide en dos subconjuntos: a) atributos de condición (criterios, características, síntomas, etc.), y b) atributos de decisión (clasificaciones, asignaciones, decisiones, etc.)
Analizar que las observaciones u objetos pueden ser indiscernibles, en cuanto a los descriptores, es el punto de partida de la filosofía de los rough sets. Al conjunto de todos estos objetos indiscernibles se le denomina conjunto elemental que, a su vez, conforma lo que se denomina el gránulo base del conocimiento de la población. La identificación plena de cualquier conjunto de objetos con un conjunto elemental se define como precisa; mientras lo opuesto se define como imprecisa, vaga o aproximada. En este sentido, un rough set representa la línea límite de casos; en otras palabras, son los objetos que no pueden ser clasificados con certeza como miembros de un conjunto o de su complemento. Por tanto, un rough set puede representarse por un par de conjuntos denominados de aproximación inferior y superior. La aproximación superior representa a todos los objetos que pertenecen con certeza al conjunto, y la aproximación inferior contiene los objetos que posiblemente pertenecen al conjunto.
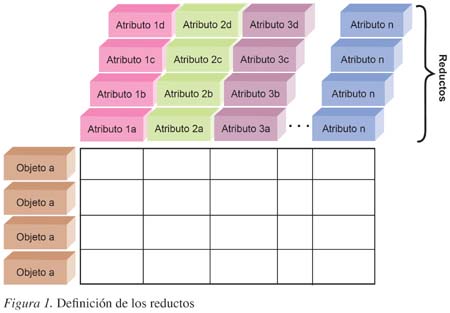
El desarrollo matemático se orienta también a descubrir dependencias entre los atributos que conforman los rough sets. Ello es de vital importancia para el análisis del conocimiento así como para la determinación de información redundante, de manera que se identifiquen aquellos atributos más relevantes y de mayor capacidad descriptiva para definir la aproximación al conjunto y reducir su número. Este subconjunto mínimo de atributos recibe la denominación de reducto y la intersección de todos los reductos núcleo; esto constituye la colección de atributos de condición más relevantes (ver Figura 1). Por otro lado, la identificación de los atributos reducto de una tabla de decisión permite derivar reglas de clasificación o decisión del tipo If then.... que relacionan descripciones de clases de atributos de condición con atributos de decisión. En el contexto de la Inteligencia Artificial, la teoría de los rough sets conforma un esquema formal de reglas deterministas y no deterministas procedentes de una representación del conocimiento en forma de tabla de decisión; este esquema da lugar a la configuración un nuevo paradigma de representación simbólica del conocimiento con derivación inductiva de reglas: aprendizaje inductivo.
En este sentido, se podría decir que hay tres categorías generales de imprecisión en el análisis científico. La primera categoría ocurre cuando un acontecimiento es aleatorio por naturaleza, y la imprecisión asociada con este tipo de acontecimientos puede describirse por la teoría estadística de la probabilidad. La segunda surge del hecho de que los objetos pueden no pertenecer exclusivamente a una única categoría, sino a varias categorías aunque con diferentes grados; en este caso la imprecisión toma forma de pertenencia difusa a un conjunto y es el objeto de la lógica difusa. La tercera categoría es la teoría Rough Set que es útil cuando las clases en las que han de catalogarse los objetos son imprecisas, pero, sin embargo, pueden aproximarse mediante conjuntos precisos. Estas diferencias muestran una de las principales ventajas de la teoría Rough Set: no se necesita ninguna información adicional acerca de los datos, tales como una distribución de probabilidad en estadística, o el grado o probabilidad de pertenencia en la teoría de lógica difusa.
Así pues, la teoría Rough Set se vale de la noción de atributo, en vez de criterio. Ello se debe a que el dominio (escala) de un criterio requiere estar ordenado de acuerdo con las preferencias, sean estas crecientes o decrecientes; no obstante, el dominio de un atributo no necesita ser ordenado. Por lo mismo, esta teoría supone que una situación de decisión puede ser representada por una tabla de información, formada por una cuádrupla:

y dado que la ecuación (5) está definida como una tabla de información, y , además que x e y Є U, entonces, las variables x e y son indiscernibles para el conjunto de atributos P definidos en S, si y solo si, f (x,q) = f (y,q), para todo q Є P.
Así, bajo esta teoría, se asume que la representación del conocimiento de los objetos se da en forma de tabla de información. En las filas de la tabla se indican los objetos (acciones, alternativas, candidatos, pacientes, empresas, etc.), mientras que las columnas corresponden a los atributos. Las entradas en la tabla son los valores del atributo; es decir, la entrada en columna q y en fila x tiene el valor f(x, q). Por tanto, para cada par (objeto, atributo) se conoce un valor denominado descriptor. Cada fila de la tabla contiene descriptores que representan información correspondiente a un objeto. La relación de no-diferenciación ocurriría si en dos objetos los descriptores tomasen el mismo valor para todos los atributos.
Un sistema de información reducido permite la obtención de reglas de decisión. De hecho, esta es la cuestión más importante del enfoque Rough Set. Suponemos que el conjunto de datos contiene información de un conjunto de objetos descritos por un conjunto de atributos. Estos, a su vez, se dividen en dos subconjuntos de atributos de condición y atributos de decisión, que denotamos por C y D. El problema consiste en encontrar reglas que determinen si un objeto pertenece a un subconjunto particular denominado clase de decisión. La definición de esta clase es conocida porque, por ejemplo, lo ha definido el experto o un usuario. Una regla de decisión puede expresarse como una sentencia lógica que relaciona la descripción de condiciones y las clases de decisión. Toma la siguiente forma: SI <se cumplen condiciones> ENTONCES <el objeto pertenece a una clase de decisión dada>
Con todo, los resultados obtenidos por el enfoque Rough Set se expresan de forma similar al lenguaje natural humano. Los procedimientos para generar reglas de decisión a partir de una tabla de decisión operan sobre los principios del aprendizaje inductivo. Los algoritmos de inducción de reglas utilizan alguna de las siguientes estrategias: generación de un conjunto mínimo de reglas que cubran todos los objetos de la tabla; generación de un conjunto exhaustivo de reglas consistentes en todas las reglas posibles de una tabla, o, generación de un conjunto de reglas de decisión fuertes que cubran relativamente muchos objetos, pero no necesariamente todos los objetos de la tabla.
ESTUDIO EMPÍRICO
Hemos centrado este estudio en las empresas mexicanas porque es el mercado de donde disponemos información. Sin embargo, esto no es ocioso si observamos que la gestión de las pequeñas y microempresas mexicanas no funciona, por desgracia, dentro de los paradigmas de eficiencia empresarial. Sistemas administrativos obsoletos, falta de preparación gerencial y contabilidad orientada solo al cumplimiento de la norma tributaria son algunos de los factores que los aquejan. Ohlson (1980) y Blazy (2000) encontraron evidencia de que el tamaño es un factor determinante, sus descubrimientos sugieren que las pequeñas y microempresas son más vulnerables al fracaso empresarial. Esta evidencia se corrobora con un reporte de la CEPAL (2009) que muestra que en América Latina el 80% de las pequeñas y microempresas no sobreviven más allá de 3 años porque, fundamentalmente, el administrador no está preparado y porque no cuentan con un sistema contable fiable que permita una adecuada toma de decisiones. Ante estas circunstancias, pareciera ser que los modelos predictivos tradicionales no encajan con la realidad, pues se nutren fundamentalmente de variables continuas poco fiables.
Así, en el presente apartado mediremos el grado de precisión del modelo RPV, en el que se aplica para ello un colectivo de 5 empresas que satisfagan los siguientes criterios de exclusión:
-
Empresas micro y pequeñas definidas por el número de trabajadores.
-
Empresa sana o fracasada sobre la que se pueda identificar con claridad el año de quiebra.
-
Que el año de quiebra sea 2008 ya que la ventana de estudio comprende del 2006 al 2008.
-
Que las empresas cuenten con información contable siempre y cuando dicha información superase el baremo de aceptabilidad definido en la encuesta que se aplicó originalmente en el estudio de Mosqueda (2008).
RESULTADOS
De la Tabla 2 se destacan varios puntos. Notamos que, tras aplicar el Modelo RPV original, esto es, con los coeficientes de respuesta definidos por Mosqueda (2008) a una muestra de empresas por fuera, se presenta un sesgo de error clasificatorio del 40%. En todo caso, la empresa del sector agroindustrial sería la más eficiente (con un RVP de 2.517), en tanto que las empresas comerciales serían las peor libradas. En la práctica, estos resultados concuerdan con los indicadores industriales del Instituto Nacional de Estadística y Geografía (2008), que señalan que las empresas agroindustriales son las que menos han sentido la actual crisis económica, no así las firmas comerciales.
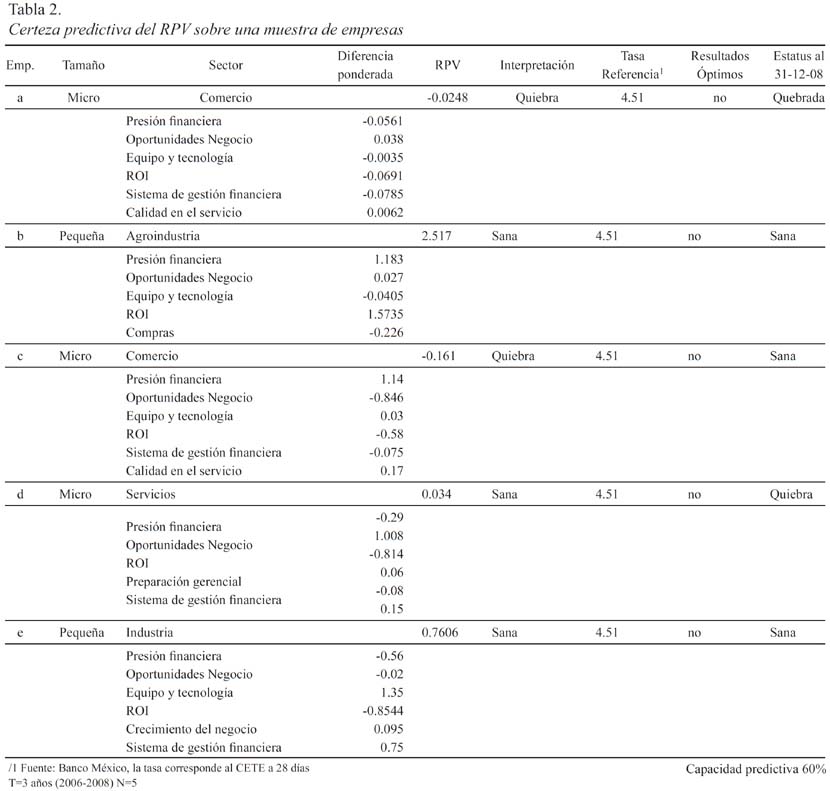
Por otro lado, y aun cuando la muestra a que se aplicó el modelo es reducida, el escaso poder predictivo del RPV (al pasar del 90% en la muestra de control frente al 60% que se obtiene en este estudio), no hace más que corroborar un problema de especificación y/o de cambios estructurales en el modelo. Por ello es que proponemos los algunos puntos en los acápites siguientes para robustecerlo.
Consideraciones críticas sobre los supuestos del Modelo RPV
El escaso poder predictivo, mostrado anteriormente por el RPV cuando se aplica a muestras distintas a la muestra de control, se puede explicar por alguna de las siguientes circunstancias: a) Ante un cambio estructural en el modelo, como pueden ser las nuevas condiciones del entorno que han provocado un cambio estacional en el modelo que precisaría su actualización; b) que los coeficientes de respuesta asignados a las variables (rit) no sean los adecuados; y, c) que el modelo estuviera mal especificado al haber incorporado variables poco representativas. Veamos algunos detalles:
La determinación de los pesos relativos de las variables quizás sea la principal debilidad del RPV. Se asume que los pesos relativos históricos (rit) son un buen proxy de los coeficientes de respuesta bit de la función econométrica que deberían cuantificarse por algún método de prospección estadística. Sospechamos que esta circunstancia es la que origina un problema de heteroscedasticidad13 e invalida la aplicación del modelo a otros entornos.
Por otra parte tenemos el problema de especificación dado que se conformó a partir de una batería de ratios financieros clásicos. Hay evidencia que sugiere que los ratios complejos capturan mejor la situación financiera de una empresa y, por ende, el efecto que tiene el sistema administrativo sobre el desempeño (Mora, 1994; Mosqueda, 2004). Esta inclusión a priori subsanaría el sesgo producido por medir la calidad administrativa con una batería de preguntas arbitraria y parcial14.
En nuestro caso, por cuestiones de espacio, nos centraremos en las cuestiones de pesos relativos de los coeficientes de respuesta (ERC) que en el Modelo RPV de Mosqueda (2008) se introducen como bit. Para ello, primero se calcularán ERC de las variables independientes. El cálculo de los ERC se hace retomando la muestra de control (Mosqueda, 2008) y que sirvió para calcular los bit, luego, se detectarán los posibles problemas de heteroscedasticidad que pudieran persistir en el Modelo RVP, para ello se utilizará el test G-Q.
PERFECCIONAMIENTO DEL MODELO
Los resultados de la regresión multivariante de la función econométrica (4) para cada sector se recogen en la Tabla 3, sobre el que se desprenden los comentarios siguientes:
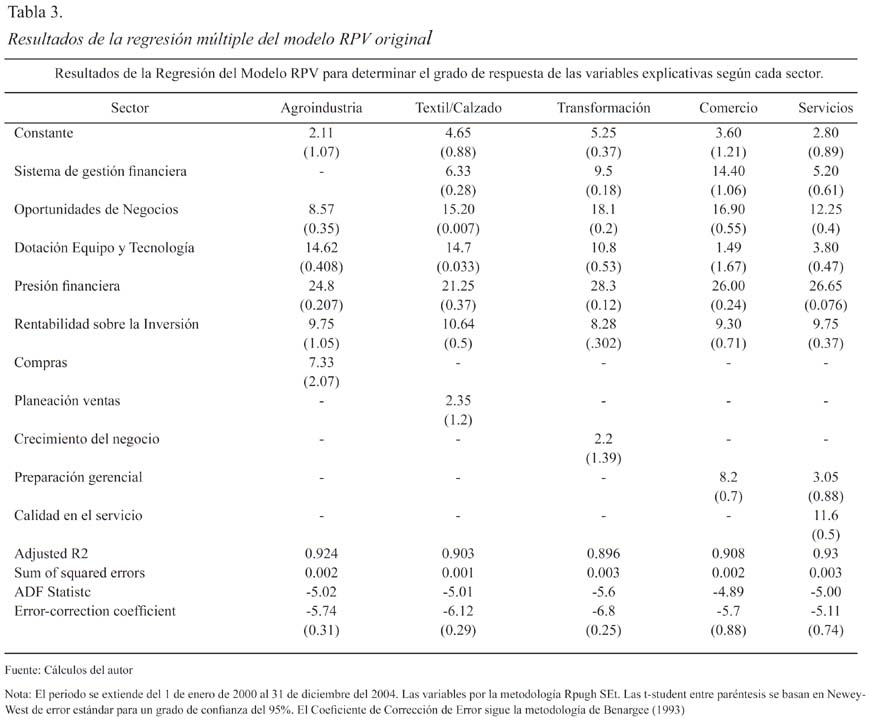
Según muestra la Constante15, se reconoce la asimetría en el costo crediticio para cada sector. Así, la agroindustria no solo sería el sector que estaría en posibilidades de pagar la tasa más baja (2.11), sino que se puede inferir la necesidad de contar con subvenciones. Por el contrario, la industria de la transformación estaría dispuesta a pagar la tasa más alta de las encontradas para estos sectores (5.25).
Por otro lado, se puede ver que los ERC varían sustancialmente respecto de los rij encontrados para el modelo original RPV. Sin embargo, se debe destacar que persiste el ratio Presión financiera como el indicador más importante. Salvo para el sector agrícola, el indicador Oportunidades de Negocios es la segunda variable en importancia; así, se reconoce el papel fundamental que tiene la planeación estratégica en la supervivencia de las empresas.
La Dotación tecnológica es un indicador relevante para todos los sectores, pero particularmente en el sector agrícola al ubicarse en segundo sitio. Este resultado vendría a explicar la necesidad por tecnificar la producción agrícola. Por otra parte, destaca la necesidad por contar con un Sistema de Gestión Financiera eficaz en el sector comercio.
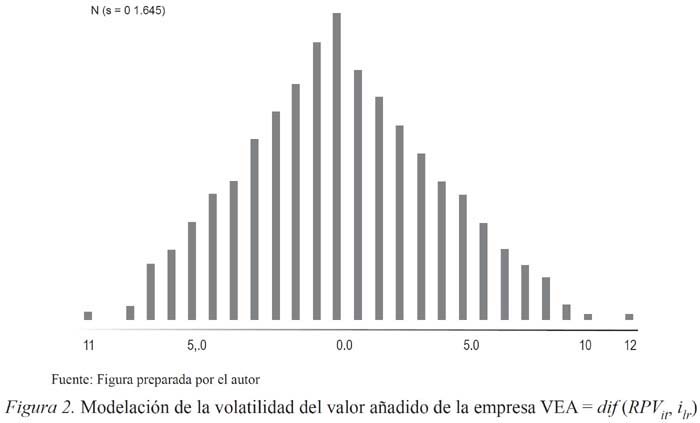
Tanto por los altos niveles mostrados en la capacidad explicativa (R2 ajustado ≥ 0.89) como por los tests ADF (que permiten aceptar la hipótesis sobre qué se basa el modelo RPV de fracaso), se puede inferir que todas las funciones especificadas por sector para el RPV se encuentran bien especificadas. Sin embargo, conforme la metodología que desarrollaron Benarjee, Dolado y Mestre (1993), notamos que los Coeficientes de Corrección del Error se ubican en cierta frontera de volatilidad que pudiera hacer cuestionables dichas bondades. Al respecto, existen las siguientes dos teorías: una que establece que estas sospechas corroborarían la presencia de una heteroscedasticidad condicionada autorregresiva (mejor conocida como ARCH)16; la otra, encabezada por Bollerselv (1986), que trata de modelar la asimetría de esta volatilidad condicionada de manera más precisa (GARCH). Al respecto, es preciso señalar que dicha volatilidad quedaría recogida en los cambios en VEA (denotado por la ecuación 4) que es el valor objetivo de los negocios exitosos. En lo particular los resultados de distribución estadística sugieren que se está en presencia de un modelo simétrico y, por tanto, es posible aplicar el modelo simétrico de Bollerselv (ver Figura 2).
Una versión estándar del modelo GARCH propuesto por Bollerselv tendría la siguiente representación:
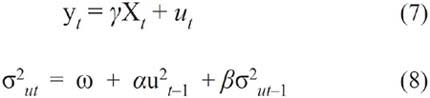
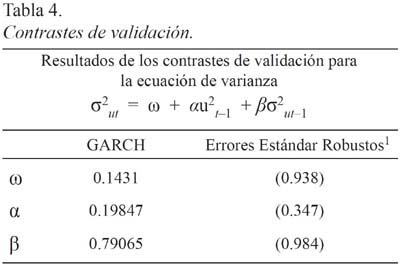
donde la expresión (5) muestra la media condicional de la variable yt en función de las variables exógenas o predeterminadas (xt) y del error del modelo (ut). Por su parte, la expresión (8) explicaría la varianza condicional de los residuos de yt en función de tres clases de variables: (a) una media (ω); (b) el término ARCH (u2t-1), medido por el cuadrado de los residuos de la expresión (5) rezagados un período, que refleja las novedades respecto de la volatilidad del período previo; y (c) el término de residuos GARCH (σ2ut-1), que mide la varianza condicional rezagada un período. Los contrastes de validación respecto de los parámetros estimados y su diagnóstico se muestran en la Tabla 4. Para tales efectos, se ha planteado la hipótesis de contraste en la que existen problemas de heteroscedasticidad dados ciertos niveles de volatilidad.
En los resultados de la Tabla 4 se nota que el coeficiente de estimación de la volatilidad, a un grado de confianza del 95 por ciento de significación, tiene un término constante del 0.14341 que se asocia con la variable dummy, y que recoge el efecto GARCH de persistencia de la volatilidad con un resultado del 0.79065. Por otra parte, el estadístico αu2t−1 es aproximadamente de 0.572, lo que evidencia la carencia de problemas de heteroscedasticidad y, por ende, reafirma la insesgadez de los Coeficientes de Corrección del Error.
VALIDACIÓN DEL MODELO RPV POR EL MÉTODO LACHENBRUNCH JACKKNIFE
Hasta este punto, los resultados obtenidos corroboran problemas de especificación en el modelo RPV original. Esto, en consecuencia, explica la disminución en su predictibilidad. Así, dejamos este epígrafe para validar la robustez del nuevo Modelo RPV según sus ERC obtenidos por regresión lineal multivariante.
Para lograr este propósito se utiliza la técnica Lachenbrunch Jackknife (TLJ en delante) que permite validar qué tan preciso clasifica un modelo por fuera de muestra17. Antes de continuar cabe destacar que en el propio trabajo de Mosqueda (2008) se aplicó esta técnica y se obtuvieron niveles de precisión cercanos al 63%, lo cual confirmaría que, de alguna forma, la TLJ ya advertía sobre los problemas de especificidad del modelo RPV original, señalados en el presente documento.
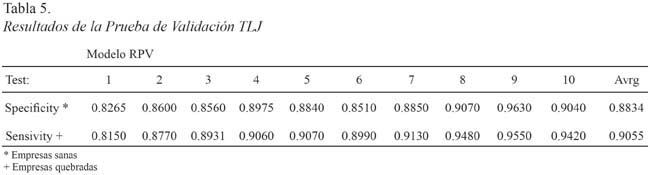
Para realizar la prueba de validación se escogieron tres empresas excluidas de la muestra original que cumplieran con los criterios de exclusión, esto nos permitió validar la capacidad de pronóstico del modelo de una forma artificial al clasificar a las empresas por fuera de la estimación. La Tabla 5 presenta el poder de clasificación a partir de diez pruebas de TLJ (tomando Y* = 0.1833)18.
Como se observa en la Tabla 5, el poder de clasificación de la muestra excluida aumenta respecto al resultado obtenido en el RPV original (Tabla 2), pasando de un 60% a un 88.34% en la proporción de empresas prósperas correctamente clasificadas (specificity) y de un 90.55% para detectar la proporción de empresas fracasadas correctamente clasificadas (sensitivity). De esta suerte, la estabilidad en los resultados del pronóstico y en los coeficientes estimados expresa en la muestra cuán robustas son ambas estimaciones a las variaciones. En efecto, queda claro que la correcta ponderación en la combinación de variables cualitativas-cuantitativas proporciona una realidad más ajustada de las empresas, pero también permite conformar un Modelo RPV con mayor capacidad predictiva.
CONCLUSIONES
Se advierte que la hipótesis acerca de la crisis del diseño experimental sigue presente en la mayor parte de los modelos predictivos, fundamentalmente en su especificación (variables relevantes) y estructura (afectada en el tiempo). Una solución que se han dado a estos problemas es la incorporación de técnicas matemáticas más robustas como la técnica Rough Set. El modelo RPV utiliza esta técnica para detectar las principales variables explicativas del fracaso empresarial para un colectivo de pequeñas y microempresas con resultados atractivos. Sin embargo, se aprecia que la predicción del modelo descansa en la teoría earning power, la cual asume que el pasado se repite en el futuro; así, los coeficientes de respuesta fueron calculados por medio de la metodología de contribuciones relativas de propuesto por la firma consultora Moodys.
Una conclusión del presente trabajo es que esta metodología originó los problemas de especificación, disminuyendo la capacidad predictiva del modelo. Para demostrarlo se aplicó el modelo RPV a un colectivo de empresas en un espacio-tiempo distinto a la muestra de control. Los resultados corroboraron el problema de diseño. A partir de ello se utilizaron técnicas de regresión lineal para determinar el comportamiento futuro de los ERC hasta obtener valores más ajustados. En efecto, los nuevos valores fueron validados por medio de la TLJ obteniendo una mejoría en el comportamiento del modelo por fuera (pasando de un 90% frente al 60% que se obtuvo en la prueba de control).
En este sentido, el presente artículo estaría demostrando que la teoría Earning Power falla en el momento de predecir el futuro y, por tanto, requiere de indicadores más ajustados. No obstante, también cabría la posibilidad de que la conformación de las aproximaciones que demanda la teoría Rough Set precise de probabilidad o del valor de la posibilidad. Sobre este último punto sobresale una importante línea de investigación. Finalmente, se reafirma, dadas las distintas funciones RPV para cada sector, que las empresas siguen un proceso de quiebra distinto, acaso condicionado por los elementos del ambiente que se dan en cada sector.
Referencias
Abad, C, Arquero, J. L, Jiménez, S. M. (2003). Procesos de fracaso empresarial. Identificación y contrastación empírica. Actas del III Workshop de Investigación Empírica en Contabilidad Financiera. Alicante, España: Universidad de Alicante. [ Links ]
Altman, E. I. (1968). Financial Ratios, Discriminant Analysis and the Prediction of Corporate Bankruptcy. The Journal of Finance, XXIII(4), 589-609. [ Links ]
Altman, E. I., Marco, G., & Varetto, F. (1994). Corporate Distress Diagnosis: Comparisons Using Linear Discriminant Analysis and Neural Networks (the Italian Experience). Journal of Banking and Finance, 18, 505-529. [ Links ]
Argenti, J. (1976). Corporate collapse. The causes and symptoms. Londres: McGraw-Hill. [ Links ]
Apellániz, P., & Labrador, M. (1995). El impacto de la regulación contable en la manipulación del beneficio. Estudio empírico de los efectos del PGC de 1990. Revista Española de Financiación y Contabilidad, 82,13-40. [ Links ]
Ball, R.; Kothari, S. P., & Robin, A. (2000). The Effect of International Institutional Factors on Properties of Accounting Earnings. Journal of Accounting and Economics, 29(February), 1-51. [ Links ]
Beaver, W. H. (1966). Financial ratios as predictors of failure. Journal of Accounting Research, 5(Supplement), 71-127. [ Links ]
Benarjee, A., Dolado, J. J., & Mestre, R. (1993). On Some Simple Tests for Cointegration: The Cost of Simplicity (Documento de Trabajo 9302). Madrid, España: Banco de España. [ Links ]
Blazy, R. (2000). La faillite, éléments danalyse économique. Avec Préface de Pierre Morin. Paris: Economica. [ Links ]
Bollerselv, T. (1986). Generalized Autoregressive Conditional Heteroskedasticity. Journal of Econometrics, 31, 307-327. [ Links ]
Casey, C., & Bartczak, N. (1984). Cash Flow: Its Not the Bottom Line. Harvard Business Review, 4(July-August), 60-66. [ Links ]
Cepal. (2009). La reacción de los gobiernos de América Latina y el Caribe frente a la crisis internacional. Reporte Naciones Unidas. Disponible en <http://competitividad.org.do/wp-content/uploads/2009/02/la-reaccion-de-los-gobiernos-de-america-latina-y-el-caribe-frente-a-la-crisis-financiera.pdf>. Recuperado el 15 de marzo del año 2009. [ Links ]
Declerc, M., Heins, B., & Van Wymeersch, Ch. (1991, April 10-12). The Use of Value Added Ratios in Statistical Failure Prediction Models: Some Evidence on Belgian Annual Accounts. Documento presentado en el 1991 Annual Congress of the European Accounting Association. Maastricht, The Netherlands. [ Links ]
Engle, R. (1982). Autoregressive Conditional Heteroscedasticity with Estimates of the Variance of United Kingdome Inflation. Econometrica, 50(4), 907-1006. [ Links ]
García, J. M., & Mora, A. (2003). On the Persistent Understatement of Shareholders Equity around Europe. Revista Española de Financiación y Contabilidad, 115(Edición especial), 44-68. [ Links ]
Greco, S., Matarazzo, B., & Slowinski, R. (1998). A New Rough Set Approach to Evaluation of Bankruptcy Risk. En C. Zopounidis (Ed.), New Operational Tools in the Management of Financial Risks (pp. 121-136). Dordrecht, Holanda: Kluwer Academic Publishers. [ Links ]
Gentry, J. A., Newbold, P., & Whitford, D. T. (1987). Funds Flow Components, Financial Ratios and Bankruptcy. Journal of Business Finance & Accounting, 14(4), 595-606. [ Links ]
Gianni, R., Acora, P., Aguirre, N., Leiton, P., & Muñoz, J. (2002). Modelos de clasificación y Predicción de Quiebra de Empresas: Una aplicación a empresas chilena. Forum Empresarial, 7(1), 33-50. [ Links ]
Guillén, J. (2009). A Lesson to Learn from Developed Countries: The Case of State Branching Deregulation in the Us. Estudios de Economía, 36(1), 67-95. [ Links ]
González, A. L., Correa, A., & Blázquez, J. A. (1999). Perfil del fracaso empresarial para una muestra de pequeñas y medianas empresas. Comunicación presentada al X Congreso AECA, Zaragoza, España. [ Links ]
Hair, J. F., Anderson, R., Tatham, R. L. & Black, W. C. (1999) Multivariate Analysis. New York: Prentice Hall. [ Links ]
Instituto Nacional de Estadística y Geografía (2008). Información estadística y económica. México D.F. Disponible en <http://www.inegi.org.mx/inegi/default.aspx?s=est&c=125>. Recuperado el 1 agosto de 2008.
Laitinen, E. (1993). Financial Predictors for Different Phases of the Failure Process. Omega: The International Journal of Management Science, 21(2), 215-228. [ Links ]
Libby, R. (1975). Accounting Ratios and the Prediction of Failures: Some Behavioral Evidence. Journal of Accounting Research, 13(1), 150-161. [ Links ]
López, E., & Flórez, R. (1999). El análisis de solvencia empresarial utilizando redes neuronales autoasociativas: el modelo Koh-León. Proceedings of the VI International Meeting on Advances in Computational Management, Reus, Tarragona, España. [ Links ]
Maltz, A. C., Shenhar, A. J., & Reilly, R. R. (2003). Beyond the Balanced Scorecard: Refining the Search for Organizational Success Measures. Long Range Planning, 36, 187-204. [ Links ]
Marais, M. L., Patell, J. M., & Wolfson, M. A. (1984). The Experimental Design of Classification Models: An Application of Recursive Partitioning and Bootstrap. Journal of Accounting Research, 22(Supplement), 87-118. [ Links ]
Marose, R. A. (1992). A Financial Neural Network Application: Neural Networks in Finance and Investing. Chicago: Probus Publishing, [ Links ]
McRobert, A., & Hoffman, R. (1997). Corporate Collapse: An Early Warning Systemfor Lenders, Investors and Suppliers. Roseville NSW, Australia: McGraw Hill. [ Links ]
Messier, W. F., & Hansen, J. V. (1988). Inducing Rules for Expert System Development: An Example Using Default and Bankruptcy Data. Management Science, 34(12),1403-1415. [ Links ]
Mora, A. (1994). Los modelos de predicción del fracaso empresarial: una aplicación empírica del logit. Revista Española de Financiación y Contabilidad, 78(enero-marzo) 203-233. [ Links ]
Mora, A. (2004). La adopción de la normativa contable internacional en España: principales efectos sobre el resultado y el patrimonio empresarial. Revista valenciana de economía y hacienda, ISSN 1577-4163, 11, 61-82 [ Links ]
Mosqueda, R. (2004). Evidencia empírica de las medianas empresas mexicanas sobre la capacidad predictiva de los modelos de fracaso empresarial (Documento de trabajo VIII). Conferencia Internacional de las Ciencias Económicas y Empresariales, Camagüey, Cuba. [ Links ]
Mosqueda, R. (2008). Indicadores del fracaso empresarial en las empresas mexicanas. México D. F.: Instituto Mexicano de Ejecutivos de Finanzas. [ Links ]
Moodys (2001). Moodys Risk Calc. Disponible en <http://www.moodys.com/cust/default.asp>. Recuperado el 15 de noviembre, 2004. [ Links ]
Neophytou, E, Charitou, A, & Charalambous, C. (2004). Predicting Corporate Failure: Empirical Evidence for the UK. European Accounting Review, 13(3), 465-497. [ Links ]
Ohlson, J. (1980). Financial Ratios and the Probabilistic Prediction of Bankruptcy. Journal of Accounting Research, 18(1) 109-131. [ Links ]
Pawlak, Z. (1991). Rough Sets. Theoretical Aspects of Reasoning about Data. Londres: Kluwer Academic Publishers. [ Links ]
Rosner, R. L. (2003). Earnings Manipulation in Failing Firms. Contemporary Accounting Research, 20(2), 361-408. [ Links ]
Sastre, L. (2002). Tourism Revenues and Residential Foreign Investment in Spain: A Simultaneous Model. Applied Economics, 34, 1399-1410. [ Links ]
Sheth, J., & Sisodna, J. (2005). ¿Por qué fracasan las buenas compañías?. Bettermanagement, 19(Marzo), 10-16. [ Links ]
Simon, H. A. (1960). The New Science of Management Decision. New York: Harper & Row. [ Links ]
Skeel, D. A. (1998). An Evolutionary Theory of Corporate Law and Corporate Bankruptcy, Vandelbirt Law Review, 51, 1325–1365. [ Links ]
Smith, R., & Winakor, A. (1935) Changes in the Financial Structure of Unsuccessful Industrial Corporations. Bulletin No. 51, University of Illinois, Bureau of Business Research, Urbana. [ Links ]
Stern, J. & Stewart, B. (2001). All about EVA. The Real Key to Creating Wealth. EVAluation: Stern Stewart & Co. Reseach, 1, 1-16. [ Links ]
Tiparat S. & Nittayagasetwat, A. (1999). An Investigation of Thai Listed Firms Financial Distress Using Macro and Micro Variables. Multinational Finance Journal, 3(2), 103-125. [ Links ]
Wilcox, J. W. (1971). A Simple Theory of Financial Ratios as Predictors of Failure. Journal of Accounting Research, 9(2), 389-395. [ Links ]
Wilcox, J. W. (1973). A Prediction of Business Failure Using Accounting Data. Journal of Accounting Research: Empirical Research in Accounting Selected Studies, 11(Supplement), 163-179. [ Links ]
Wooldrige, J. (2006). Introducción a la Econometría. Un enfoque moderno. (2da. Ed.). Madrid, España: Thomson. [ Links ]
Zmijewski, M. E. (1984). Methodological Issues Related to the Estimation of Financial Distress Prediction Models. Journal of Accounting Research, 22(Supplement), 59-86. [ Links ]
Notas de pie
1 Skeel (1998), por ejemplo, realiza un recuento interesante sobre los estudios de finales del siglo XIX y a principios del siglo XX. El autor encuentra que aquellos trabajos se centraban solo en el estudio epistemológico del fracaso empresarial. En la actualidad, los modelos del fracaso empresarial se perfilan para resolver tres cuestiones básicas: a) diseñar, fundamentalmente a partir de información contable e indicadores macroeconómicos, modelos matemáticos capaces de tipificar y predecir el fracaso y agrupar a las empresas en categoría dicotómica: empresas fracasadas y empresas prósperas; b) tipificar el proceso de quiebra, aludiendo al comportamiento de indicadores de eficiencia financiera; y c) entender el proceso de fracaso empresarial a partir de las recomendaciones y actuaciones del analista financiero.
2 En la obra de Argenti (1976) se puede consultar una revisión extensa sobre el significado de fracaso empresarial, así como los trabajos de Beaver (1966) y de Sheth y Sisodna (2005), trabajos en los que se esquematiza integralmente el fenómeno del fracaso empresarial.
3 La mayoría de los autores de las primeras décadas del siglo XX utilizan ratios financieros pertenecientes a uno de los cuatro grandes grupos: liquidez, actividad, rentabilidad y endeudamiento. Los índices de liquidez y endeudamiento son los que más contribuyen en la determinación de quiebra de empresas, salvo en el caso de Altman que substituye Liquidez por Rentabilidad.
4 Los puntos de corte para calificar la salud de la empresa caería en alguno de los siguientes puntos:
Z < 1.81 (alto riesgo de quiebra)
Z > 3.00 (bajo riesgo)
1.81 < Z < 3.00 (área gris)
5 Paradójicamente se dio este avance sin haberse resuelto uno de los problemas clásicos: El problema de clasificación. Recordemos que uno de los propósitos de los modelos de predicción de la quiebra empresarial consiste en clasificar a las firmas dentro de dos grupos: grupo de empresas fracasadas y grupo de empresas no fracasadas. Al respecto se han desarrollado dos tipos de errores cometidos al momento de clasificar a las empresas: error tipo I y error tipo II. Si una firma fracasada es catalogada incorrectamente como empresa no fracasada por el modelo, se está cometiendo el error tipo I y si, por el contrario, una empresa no fracasada es erróneamente clasificada dentro del grupo de empresas fracasadas, entonces, se está cayendo en un error tipo II. En la práctica cometer cualquiera de estos tipos de error trae serias consecuencias.
6 Para un estudio pormenorizado de la manipulación contable y el fracaso empresarial se puede consultar las obras de Apellániz y Labrador (1995) y de García y Mora (2003).
7 En este sentido, H. A. Simon (1960) ya había propuesto una solución ingeniosa al respecto, al diseñar una división de los procesos de decisión entre estructurados y no estructurados; pero, su propuesta resultó difícil de aplicar en la práctica.
8 La clasificación de las variables en estándar y simple obedece a criterios de Administración Financiera. Por estándar se entiende al indicador del mercado y por simple el resultado que se obtiene de la empresa analizada.
9 El peso específico de cada indicador (rij), que matemáticamente no podrá ser superior a 1.0, se conformó por medio de la metodología propuesta por la firma consultora Moodys, a saber:
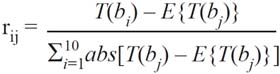
En donde T(bij) es el ratio (variable) respectivo; en tanto que E{T(bij)} refleja el valor promedio (esperado) del total de las variables; luego,
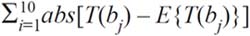
representa a la suma absoluta de las diferencias.
10 Para mayor información sobre estas variables se puede consultar a Mosqueda (2008). De dicho estudio, podemos decir, en términos generales, que las variables cualitativas se obtienen tras la aplicación de un cuestionario de competitividad, en tanto que las variables cuantitativas son ratios financieros que se calculan a partir de información contable.
11 Lamentablemente, el autor no hizo las regresiones respectivas para encontrar los coeficientes de respuesta estimados de las variables independientes. En su lugar, se tomó los valores históricos de las variables (rit) como predictores, confiando, según se aprecia, en la teoría de eaning power que establece que los valores históricos tienen el potencial suficiente para predecir el futuro.
12 Mosqueda (2004) encuentra que la ecuación (4), en cierta forma, retoma la idea de Hamilton, publicada en el año 1777, que luego perfeccionarían Stern y Stewart (2001) para elaborar su modelo EVA, respecto de la idea de valor económico residual, a diferencia de la metodología RPV que compara el desempeño económico generado por los indicadores más representativos de la empresa y no sólo por los retornos de capital propuesto por el modelo EVA.
13 Esta condición hace que el estimador de la varianza del término de perturbación, Ôu2 sea sesgado por distintas causas. En nuestro caso, asumimos que el sesgo no se debe tanto a la omisión de alguna variable explicativa relevante –el método Rough Set ha probado sobrada robustez discriminadora; puede consultarse los trabajos de Greco, Matarazzo y Slowinski (1998) y Mora (2004) –, sino por la existencia de cambios estructurales en el modelo (un cambio estacional en una serie temporal).
14 Mosqueda (2008) acepta esta circunstancia de parcialidad al decir que: Las variables cualitativas (estratégicas) que hemos estudiado representan sólo una lista descriptiva, y no limitativa, dichas variables dependerán del enfoque (estilo) administrativo que se crea más adecuado. En consecuencia, la supremacía de una u otra tendencia en el estilo de la dirección afectará al RPV (p. 144)
15 En el trabajo de Mosqueda (2008) se dedica todo un epígrafe para argumentar el por qué la Constante explica la asimetría en el costo crediticio. Sin embargo, se puede deducir que el criterio adoptado se debe a la orientación de Valor Económico Agregado por el que el resultado del RPV es interpretado.
16 Wooldrige (2006) ha dejado en claro que para que el estadístico F –con ût2 – sea válido se debe asumir que los errores ut s son homoscedásticos y no correlacionados, lo cual supone, implícitamente, excluir ciertas formas de heteroscedasticidad dinámica. Es por ello que en los últimos años los economistas han centrado su atención en el análisis de las variables dependientes retardadas asumiendo que se cumplen los supuestos de Gauss-Makov (retardos distribuidos finitos). En este sentido Engle (1982) propuso que se modelara la volatilidad condicionada cambiante en el tiempo mediante un proceso ARCH, el cual permite modelar la varianza de las series sobre la base de las perturbaciones aleatorias pasadas. Similares resultados a los presentados en el comportamiento de los CCErr (Tabla 3), obtuvo Sastre (2002), quien, sin embargo, después de corregir los problemas de acuerdo con el test G-Q no mejoró significativamente los problemas de especificación.
17 Este tipo de pruebas permite encontrar el inverso de los errores de especificación (tipo I y tipo II); desde esta perspectiva, la proporción de empresas fracasadas correctamente clasificadas se les denominaría con el término de sensitivity, mientras que la proporción de empresas prósperas correctamente clasificadas se conocería como specificity.
18 En la medida en que el valor de Y* sea más alto (bajo) el modelo clasificará a más empresas como fracasadas (sanas) y disminuirá el porcentaje correctamente clasificado de empresas prósperas (quebradas). El criterio que adoptamos obedece al éxito clasificatorio mostrado en los estudios de Neophytou Charitou & Charalambous (2004) o Tirapat y Nittayagasetwat (1999), que seleccionan el valor límite a partir de los errores tipo I y tipo II.
