











 English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink1. Introduction
Credit granting is an important element of financial transactions to provide liquidity for several economic activities ( Doumpos et al., 2018 ; Xia et al., 2021 ). The problem with granting credit is a decision made under uncertain conditions in the face of the risk of borrowers not meeting their obligations. Furthermore, credit granting is usually regarded as a dynamic scenario (Xia et al., 2021; Laborda and Ryoo, 2021 ). This makes it a complex decision-making issue, which may compromise the survival of an organisation. Thus, organisations are fundamentally responsible for assessing the risk of prospective borrowers before granting credit ( Roy and Shaw, 2022 ). This risk consists of the possibility that the creditor incurs losses due to the non-fulfilment of obligations brought about by the borrower (Doumpos et al., 2018; Li et al., 2021 ). If the creditor can estimate the probability of a loss, then decision-making will be more reliable ( Marqués et al., 2013 ; Roy and Shaw, 2021a). These issues have become relevant topics in risk management for minimising financial losses for those who grant credit. Efficient credit risk management is a decisive factor for credit institutions, non-financial businesses and consumers ( Andriosopoulos et al., 2019 ; Sariannidis et al., 2020 ; Roy and Shaw, 2022). Most companies offer credit to customers (Doumpos et al., 2018; Ashofteh and Bravo, 2021 ). Examples include banks, retailers, insurance companies, and micro and small businesses ( Chen et al., 2016 ; Li and Chen, 2020). The main components of credit risk modelling are i) Probability of Default (PD), ii) Exposure at Default and iii) Loss Given Default. For a theoretical background on these topics, refer to Andriosopoulos et al., 2019 ), Breeden (2021 ), Salcedo (2021 a), Salcedo (2021b) and Kozodoi et al. (2022 ).
The management and classification of the risk of a borrower or credit operation are made by employing Credit Scoring Models (CSMs). The CSMs aim to estimate the default risk by classifying the credit borrowers based on sociodemographic characteristics that allow them to be categorised as ‘good’ or ‘bad’ payers (refer to Louzada et al., 2016 ), Li and Chen (2020 ), Gunnarsson et al. (2021 ), Xia et al., 2021 ; Kozodoi et al. (2022). To establish superior CSMs, industry and academia mainly utilise the following two tools: algorithms and data sources ( Trivedi, 2020 ; Breeden (2021 ; Xia et al., 2021). Over the last few decades, researchers have focused on developing improved CSMs. Emphasis has been placed on prediction methods including artificial intelligence algorithms and performance measures incorporated into CSMs ( Lessmann et al., 2015 ; Chen et al., 2016). Most of these studies have used extensive databases with abundant variables to test the performance of CSMs. Furthermore, CSMs access these available data sources to extract, analyse and convert borrowers’ information into risk measurement values ( Řezáč, 2015 ; Kozodoi et al. (2022). The indicator that quantifies the probability that a borrower to sustain a ‘good’ risk is the Credit Score (CS). Letters, numbers or specific labels representing borrowers’ idiosyncratic rate or quality may symbolise a CS (Li et al., 2021). Thus, customers whose CS responds with a high probability of being a ‘good’ payer would be accepted, and the others rejected by CSMs.
Recent studies have focused on improving the accuracy of CSMs for predicting payment default risk (refer to Lessmann et al., 2015; Louzada et al., 2016 ; Andriosopoulos et al., 2019 ; Kozodoi et al. (2022 ). Important advances have been obtained, and practically all credit management areas (receipt, response, recovery, collection or risk measurement) use CSMs ( Řezáč, 2015; Dastile and Celik, 2021 ). However, the literature has not yet presented a broader analysis of the CSM modelling process. Most approaches aim exclusively for the accuracy and results of optimisation methods and do not cover the entire context of building CSMs. Many studies have disregarded the real-world specificities (problem characteristics and customer databases) in applying CSMs. This study aims to present a literature review of the most recent optimisation methods applied to CSMs. This literature review included only papers published between January 2008 and May 2022. The delimitation of this study is based on the exponential growth of publications, as presented by Louzada et al. (2016). The scope of this study lies in providing theoretical lines which synthesise the state of the art and cooperate with more promising studies for the better development of CSMs. This paper is structured as follows: Section 2 provides a brief theoretical basis for credit operations, credit scoring and the main quantitative models used in CSMs; Section 3 presents the literature review; Section 4 demonstrates the research methodology; Section 5 provides the results obtained; Section 6 discusses the findings, and the paper ends with conclusions and future directions regarding CSMs.
2. Theoretical background
2.1 Credit operations
Credit operations express the delivery of goods or present value with the expectation of receiving a certain amount in the future ( Marqués et al., 2013 ; Trivedi, 2020 ). Such operations generate interest ( Bravo et al., 2013 ; Ashofteh and Bravo, 2021 ). These interests are charged for a predetermined period to minimise payment defaults ( Doumpos et al., 2018 ; Li and Chen, 2020 ; Trivedi, 2020). Given the criticality of risk assessment, a CSM’s purpose is to classify potential borrowers as ‘good’ or ‘bad’ (Marqués et al., 2013; Li and Chen, 2020). That is, those whose payment is expected on time and those whose payment is expected not to be complied with (Li and Chen, 2020). Traditionally, the models used for credit granting have been based on expert judgement. Expert judgement is primarily used when borrowers’ historical data are missing or for special types of credit assessments ( Andriosopoulos et al., 2019 ; Gunnarsson et al. (2021 ). A common practice considers the 3, 4 or 5 C’s qualitative model: character, capacity, capital, collateral and conditions (Marqués et al., 2013). Nevertheless, as customer bases grew exponentially, financial institutions began to combine or replace credit granting decisions based on judgements with statistical models (Chen et al., 2016; Gunnarsson et al. (2021). In this respect, the Basel II Accord, which established a minimum capital requirement for financial institutions, was a watershed in the CS. These institutions resort to approaches based on internal classification, culminating in constant attempts to build CSMs (Chen et al., 2016; Gunnarsson et al. (2021). These CSMs make CS a primary tool for financial institutions to assess credit risk and make decisions on cash management and resource allocation (Marqués et al., 2013; Gunnarsson et al. (2021).
2.2 Credit scoring
In general, the CS is used to assess the risk of payment default when granting credit. CS includes an estimation based on the probability model of a borrower showing behaviour considered undesirable for the future ( Lessmann et al., 2015; Gunnarsson et al. (2021 ). Thereby CSMs deal with a generic market-originated denomination and aim to quantify risk using formulas to calculate the referred CS ( Marqués et al., 2013 ; Louzada et al., 2016 ; Andriosopoulos et al., 2019 ). Most CSMs aspire to identify the characteristics that influence behaviours that lead to either payment or default in a way that a customer might be classified as a ‘good’ or ‘bad’ payer (Louzada et al., 2016). Thus, those customers whose CSMs present a high probability of being ‘good’ payers are accepted, and those with low probability are declined ( Finlay, 2009 ; Breeden (2021 ; Carta et al., 2021 ). Furthermore, the latest CSMs have been employed for issues such as profitability, the use of Big Data (BD), Deep Learning (DL), equity in analysis, and sustainability (refer to Bastani et al., 2019 ; Kozodoi et al., 2019 ; Ashofteh and Bravo, 2021 ; Dastile and Celik, 2021 ; Djeundje et al., 2021 ; Kang et al., 2021 and Kozodoi et al. (2022).
2.3 Main quantitative models
In quantitative models, each data instance is described by various characteristics representing the level of risk of a loan or borrower ( Laborda and Ryoo, 2021 ; Xia et al., 2021 ). This score might be associated with risk classification and the PD estimation ( Marqués et al., 2013 ; Andriosopoulos et al., 2019 ). The traditional statistical methods include Discriminant Analysis (DA), Logistic Regression (LR), Classification Tree (CT) and Multiple Discriminant Analysis. These methods are linear in form and have the advantage of being easily applied and interpreted (Andriosopoulos et al., 2019 ; Marqués et al., 2013). To establish a CS, the Operational Research models, such as Linear Programming, Quadratic Programming and Multiple-Criteria Decision-Making are also used in CSMs (Marqués et al., 2013; Roy and Shaw, 2021 roy). Evolutionary Computation, Artificial Intelligence, Data Mining and Machine-Learning techniques describe credit risk with greater precision ( Breeden (2021 ; Xia et al., 2021; Kozodoi et al. (2022 ). The most prominent are Fuzzy Logic, Markov Chain, Bayesian Networks, Genetic Algorithm (GA), Naive Bayes (NB), k-Nearest Neighbors (k-NN), Artificial Neural Networks (ANN), Support Vector Machine (SVM) and Case-based Reasoning (CBR). The disadvantages are that these techniques require a great computational endeavour and finance, and business analysts seldom know them (Marqués et al., 2013; Breeden (2021).
3. Literature review
The call for an analysis of credit granting came about as sales commerce under future payment compromises began ( Louzada et al., 2016 ). The statistical score which distinguishes ‘good’ and ‘bad’ applicants was possibly presented for the first time by Durand (1941 ). Durand (1941 ) approached the risk elements in customer payment instalment plans ( Gunnarsson et al. (2021 ). However, the first operational scoring model was only proposed after a reasonable amount of time by Altman (1968 ). This model is based on five indices selected from eight variables in corporate financial statements, with a linear combination of these indices that demonstrated a discriminant function Z. Next, Orgler (1970 ) developed a general model of CS for commercial loans that approached the issue of dependent and independent variables using Multivariate Regression (MR). Eisenbeis (1978) used DA techniques to analyse the methodological approaches and statistical problems associated with CSMs.
In the 1980s, Capon (1982 ) suggested a more critical view of the logical basis of systems and CSMs. This is because statistical issues may cause severe legal problems for creditors if they are not correctly implemented in CSMs. Subsequently, Leonard (1992 ) modelled the credit decision process using DA and LR. Leonard (1992) used loan requests from small businesses handled by a large Canadian bank. Nonetheless, since the 2000s, new types of approaches have emerged to better deal with CS. Baesens et al. (2003 ) used three rule-extraction techniques through an ANN (Neurorule, Trepan and Nefclass). These techniques were employed for credit risk assessment using three data sets, demonstrating a powerful management tool via ANN and decision tables. Sinha and Zhao (2008 ) compared the performance of seven classification methods: LR, ANN, k-NN, SVM, Data Mining, Decision Table and Decision Tree (DT). Antonakis and Sfakianakis (2009 ) scrutinised the efficiency of Bayes’ Theorem as a method for building classification rules in the triage of credit applicants. In this study, the researchers used two sets of real data to compare the rule with NB, LR, ANN, k-NN, CT and Linear Discriminant (LD). Finlay (2009 ) used a GA to generate a set of linear-scoring models oriented towards individual measures of organisational interest. Šušteršič et al. (2009 ) developed a CSM for consumers with limited data by implementing an ANN; for variable selection, GA and Principal Component Analysis (PCA) were used. Ince and Aktan (2009 ) researched the performance of CSMs which applied traditional approaches and artificial intelligence, such as DA, LR, ANN and Classification and Regression Trees (CART).
In 2010, research on CS grew exponentially. Finlay (2010 ) models continuous financial measures such as default, revenue and contribution to profit. Liu and Bo (2011 ) used a Simulated Annealing algorithm together with a GA to select the ideal attributes of an NB classifier in real databases. Vukovic et al. (2012 ) presented a system of four CBR models which use GA to select the functions of preference and define the value of the attributes. Bravo et al., 2013 ) presented a methodology for granting and monitoring credit to micro-entrepreneurs by applying LR and Knowledge Discovery in Databases (KDD). Kruppa et al. (2013 ) improved probability estimation using methods such as k-NN and Random Forests (RF) deployed along with LR in a data set from a company that produces appliances. Řezáč, 2015) proposes a new ESIS2 algorithm that estimates the information value and assesses the discriminatory power of the CSMs. Verbraken et al. (2014 ) adapted the Expected Maximum Profit (EMP) measure to find the compensation between expected losses and losses by default. Kozeny (2015 ) partially fills a gap in the usage of GA in CS, as these algorithms play a supporting role in other techniques, such as NN. Lessmann et al., 2015) updated Baesens et al. (2003) by comparing 41 classifiers in real-world databases. This study examined the extent to which alternative scoring card assessments differed between predictive indicators. Furthermore, Lessmann et al., 2015) compared other ensemble, hybrid system and single-model approaches. For a theoretical foundation regarding these modelling types, refer to Louzada et al. (2016) and Andriosopoulos et al. (2019 ).
By the second half of the 2010s, studies were not limited to predicting payment default probability. Serrano-Cinca and Gutiérrez-Nieto (2016 ) proposed a system of support for a profit-scoring decision oriented to a Person-to-Person (P2P) loan based on MR and using the Internal Rate of Return (IRR). Maldonado et al. (2017 ) developed a structure based on profit to select models and attributes using a linear SVM. They also present a detailed cost-benefit analysis, including the calculation of financial losses for non-compliant payers. Krichene (2017 ) deployed an NB classifier to predict payment defaults on short-term loans in a commercial bank in Tunisia. Bastani et al. (2019 ) proposed a two-step approach that focuses on the lending market fund allocation process for P2P lending. This study integrated credit and profit scores based on Learning Algorithms (LA). Sariannidis et al. (2020 ) compared the prediction accuracy of seven methods: LR, NB, DT, k-NN, RF, Support Vector Clustering (SVC) and Linear Support Vector Clustering (LSVC). The precision of the resulting method ranged from 70% to 83%. Kozodoi et al. (2019 ) used the EMP measure and number of attributes as two adequate functions for selecting characteristics based on coverage to tackle both profitability and interpretability. Çiǧşar and Ünal (2019) identified and used Data Mining classification algorithms to prevent default risk. They used NB, the J48 algorithm, a multivariate perceptron, six classification algorithms, and regression using WEKA 3.9 Data Mining (https://waikato.github.io/weka-wiki/).
Moreover, researchers have combined more than one technique. Trivedi (2020) presented a prediction model and CSM using the NB, RF, DT and SVM classifiers. Nalić and Martinovic (2020 ) proposed a high-performance custom CSM based on credit history with real data and deployed the Generalised Linear Classification algorithm and SVM. Li and Chen, 2020 ) conducted experiments and discussions in which a credit risk prediction model was used in a comparative assessment of four sets of algorithms: RF, AdaBoost, XGBoost and LightGBM. They combined piling with four traditional algorithms: ANN, LR, DT and SVM.
Recently, CSMs have addressed BD use, DL, and issues such as equity, profitability, sustainability, fraud prevention and economic variables. Ashofteh and Bravo, 2021 ) presented a two-step method based on an initial Kruskal-Wallis non-parametric statistical analysis to formulate a conservative CSM. This CSM is based on the Machine Learning (ML) method for the default prediction of high-risk branches or customers. Thus, the RF, ANN, SVM and LR with Ridge penalty were used for the learning and evaluation of the referred CSM. Carta et al. (2021 ) proposed an ensemble stochastic criterion that operates in a discretised feature space and is extended to some meta-features to build an efficient CSM. This approach uses a real-world data set with different data imbalance configurations to apply the following classification algorithms: RF, DT, Adaptive Boosting, Multilayer Perceptron and Gradient Boosting (GB). The stochastic criteria applied to a new feature space obtained by a twofold preprocessing technique perform the final classification of the CSM. Dastile and Celik (2021 ) provided a CSM using DL that converted tabular data sets into images to allow the application of 2D CNNs. Each pixel in an image corresponds to a feature bin in the tabular data set. The predictions of the 2D CNNs were explained using state-of-the-art CSM methods. Djeundje et al. (2021 ) evaluated the predictive performance of using psychometric variables and/or the characteristics of email use to predict consumer default probabilities. Researchers have applied a wide range of classification methods including LR, DL, PCA, XGBoost, Ridge Regression (RR) and Least Absolute Shrinkage and Selection Operator (LASSO). Instead, they are used to predict the credit risk of a new account and evaluate the predictive accuracy of CSMs. Kang et al., 2021) proposed a CSM to address the Rejection Inference (RI) issue. It considers an imbalanced data distribution for the consumer CS. Different classifiers were studied to propose the CSM; RF, DT, XGBoost, LightGBM and Modified Synthetic Minority Oversampling Technique (Borderline-SMOTE). Thus, the researchers’ conduction of imbalanced learning using a Borderline-SMOTE and a graph-based semi-supervised LA called Label Spreading is applied to solve the RI.
Kozodoi et al. (2022) examined ML applications in the retail credit market. The researchers revisit(ed) statistical fairness criteria and examined their adequacy for CS. They then catalogued algorithmic options to incorporate fairness goals into the development of ML-based CSMs. Ergo empirically compared different fairness processors in a profit-oriented CS context using real-world data through the EMP. The fairness pre- and post-processors, as well as an unconstrained scorecard, use four base classifiers: LR, RF, ANN and XGBoost. The corresponding code is available on GitHub (https://github.com/). Laborda and Ryoo, 2021 ) presented a methodology for selecting key variables to establish a CSM. In this study, LR, RA, SVM and k-NN were proposed to separate the data into two classes and identify the candidates that are likely to default on this CS. Li and Chen, 2020) presented a CSM that captures defaulting borrowers on an online lending platform using Multi-Layer Structured Gradient Boosted Decision Trees with Light Gradient Boosting Machines (ML-LightGBM). Roa et al. (2021 ) presented the impact of alternative data originating from an app-based marketplace (in contrast to traditional bureau data) on CSMs. Researchers have applied EMP measures and Stochastic Gradient Boosting (SGB). Furthermore, the Tree-based SHapley Additive explanation method was used for the SGB interpretation. Roy and Shaw, 2021a) proposed a low-cost CSM for financial institutions that focused on Small and Medium Enterprises (SMEs) CS. The researchers integrated the Analytic Hierarchy Process (AHP) and the Technique for Order Preferences by Similarity to an Ideal Solution (TOPSIS) for AHP-TOPSIS. Roy and Shaw, 2021b) developed a system to predict SMEs’ credit risk by introducing a multi-criteria model formulated using a hybrid method that combines TOPSIS and Best-Worst Method (BWM). Xia et al., 2021 ) devised a CSM in which the data frequency and delays from Multilevel Macroeconomic Variables (MVs) are associated with app data for CS. Moreover, Xia et al. (2021) proposed a Bayesian selection and lag optimisation method to handle highly correlated MVs and capture flexible lag effects. Roy and Shaw, 2022) filled a gap in the literature by proposing a multi-criteria Sustainability Credit Score System. This approach considers environmental and social aspects besides financial and managerial issues by combining BWM and TOPSIS.
4. Method
This research focuses on analysing the database characteristics and optimisation methods applied to CSMs. Therefore, this paper presents a literature review of technical procedures based on bibliographic exploratory research (refer to Louzada et al., 2016 ; Watson and Webster, 2020 ; Lim et al., 2022 ). The selection and classification of scientific publications included the following steps: i) database search, ii) selection of published papers and iii) classification of the selected papers. Figure 1 illustrates the steps of the research methodology.
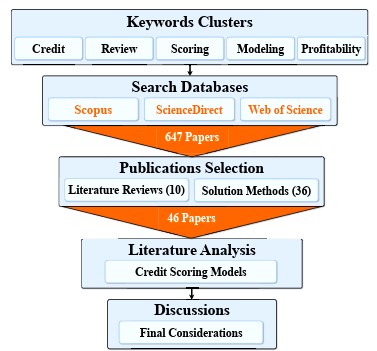
First, a search for publications was performed using the Scopus, ScienceDirect and Web of Science databases ( Paul and Criado, 2020 ; Donthu et al., 2021 ). The keywords clusters used in advanced search are as follows: ‘credit’, ‘review’, ‘scoring’, ‘modelling’ and ‘profitability’. These keywords were combined with the Boolean operator ‘AND’. Publications were published between January 1968 and May 2022. The search only considered papers published in online journals in English. After the exclusion of duplicate studies, 647 publications were included. Therefore, a preliminary analysis resulted in the segmentation of 321 publications using several approaches to CS and CSM.
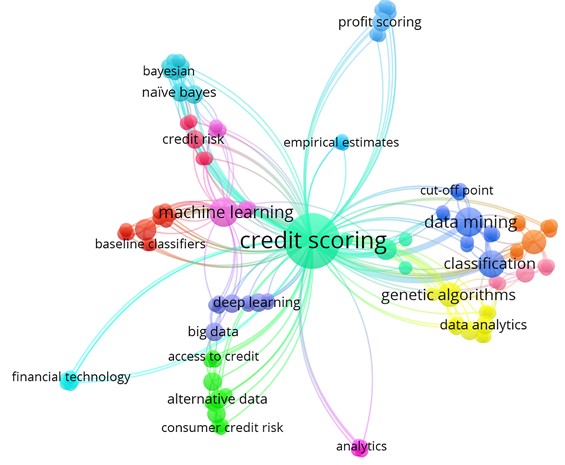
In the second step, publications were selected through a careful evaluation of the purpose of the study regarding CSMs. Notably, for this literature review, we selected papers published between January 2008 and May 2022. The paper selection period was based on the exponential growth of publications, as presented by Louzada et al. (2016). This step resulted in a final selection of 46 papers containing literature review approaches and solution methods proposed for CSMs. Papers published between January 1968 and December 2007 were used as theoretical frameworks for CS and CSMs. The remaining papers were discarded because they did not fit the established protocols for approaches inherent to CSMs. Books and abstracts addressing CSMs were excluded. The keywords used by the 46 selected papers are illustrated in the cloud map shown in Figure 2 and generated by VOSviewer version 1.6.16 (http://www.vosviewer.com/).
Figure 2 shows that the total number of keywords listed by all selected papers was 224, as generated by VOSviewer. Furthermore, the map shows the main keywords related to the theme group, represented by ‘Credit Scoring’. The keywords most used by the selected papers from 2008 to 2022 are Credit Scoring (31), Data Mining (6), Classification (6), Machine Learning (6), Genetic Algorithm (4) and Genetic Algorithms (4). The relations between the intensity and occurrence of keywords indicate that the selected papers are pertinent to a literature review of CSMs.
In the third step, the selected papers were classified into two groups: Solution Methods and Literature Reviews. Thus, the number of papers that proposed solution methods (including modelling, profitability and database selection) used by CSMs was 36 (78%). The literature reviews ten (22%) papers that provide a theoretical framework for CSMs. Furthermore, the literature review incorporates innovations and analyses related to recent publications proposing new solution methods for CSMs. Thus, these papers were selected based on their relevance in transferring historical information to update and improve state-of-the-art CSMs. The literature review observed two types of approaches: narrative and systematic reviews. The classifications and research methodologies used in the literature review are presented in Table 1 .
Table 1 Approaches proposing literature review

Note(s): Referenced abbreviations: NR- Narrative Review; SR- Systematic Review
Source(s): Own elaboration
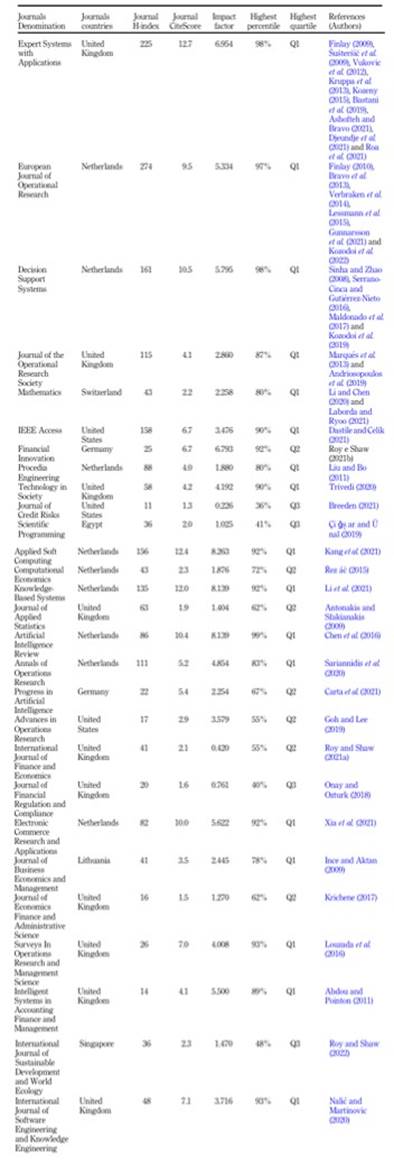
Table 1 demonstrates that the number of papers referring to narrative reviews (5) is identical to that referring to systematic reviews (5). The first exposes the state of the art with a theoretical or contextual focus, and the second answers questions using specific methods to locate, select and technically evaluate studies (refer to Paul and Criado, 2020 ; Donthu et al., 2021 ; Lim et al., 2022 ). Table 2 presents the bibliometric indicators of the Scopus and Web of Science databases referring to journals that published papers classified as Solution Methods (36) and Literature Reviews (10). The graph in Figure 3 illustrates journals with two or more publications, while the rest are classified as ‘Other Journals with Just One Publication’.
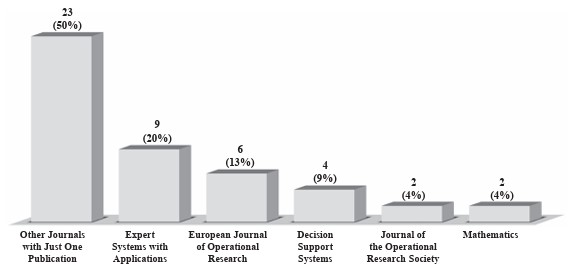
Table 2 lists the selected papers published in 28 journals. Most of these journals were published in Europe (23 journals, 41 papers). The other journals were from America (3 journals, 3 papers), Africa (1 journal, 1 paper) and Asia (1 journal, 1 paper). In terms of the number of journals, Europe (82%) was superior to America (11%), Africa (4%) and Asia (4%). Almost all the selected papers came from Europe (89%), and the rest from America (7%), Africa (2%) and Asia (2%). The countries where most journals were based were the United Kingdom (10 journals, 19 papers), the Netherlands (9 journals, 17 papers), the United States (3 journals, 3 papers) and Germany (2 journals, 2 papers). Ergo, 85% of the selected papers were concentrated in journals in the United Kingdom (41%), the Netherlands (37%) and the United States (7%). Figure 3 shows that the journals with more than one selected paper were Expert Systems with Applications (20%), European Journal of Operational Research (13%), Decision Support Systems (9%), Journal of the Operational Research Society (4%) and Mathematics (4%), amounting to 23 (50%). The remaining journals were grouped as ‘Other Journals with Just One Publication’.
5. Results
The literature review shows that during the last decade, there has been a constancy in research proposing CSMs. A significant increase was observed in 2019. Their findings show that CSMs are usually formulated using financial analysis, ML, statistical techniques, operational research and data-mining algorithms. The analysis identified 48 methods used by researchers for construction, performance tests and comparisons between CSMs. These studies and the solution methods used by CSMs are presented in Table 3 . Next, the graph in Figure 4 illustrates the methods with two or more applications while the rest are classified as ‘Other Methods’.
Table 3 Approaches proposing solution methods

Note(s): Referenced abbreviations: NB - Naive Bayes; DT - Decision Trees; RF - Random Forests; VS - Variable Selection; RR - Ridge Regression; GB - Gradient Boosting; GA - Genetic Algorithm; AB - Adaptive Boosting; CT - Classification Trees; LR - Logistic Regression; LD - Linear Discriminant; SA - Simulated Annealing; DA - Discriminant Analysis; MP - Multilayer Perceptron; k-NN - k-Nearest; Neighbors; IRR - Internal Rate of Return; BWM - Best-Worst Method; CBR - Case-Based Reasoning; MP - Multilayered Perceptron; MR - Multivariate Regression; SVM - Support Vector Machine; MCS - Monte Carlo Simulations; EMP - Expected Maximum Profit; SVC - Support Vector Clustering; ANN - Artificial Neural Networks; SGB - Stochastic Gradient Boosting; AHP - Analytic Hierarchy Process; IHT - Instance Hardness Threshold; PCA - Principal Component Analysis; XGBoost - Extreme Gradient Boosting; GLC - Generalised Linear Classification; CNNs - Convolutional Neural Networks; CatBoost - Categorical Gradient Boosting; KDD - Knowledge Discovery in Databases; ML-LightGBM - Light Gradient Boosting Machines; CART - Classification and Regression Trees; SMOTE - Synthetic Minority Oversampling Technique; LASSO - Least Absolute Shrinkage and Selection Operator; TOPSIS - Technique for Order of Preference by Similarity to Ideal Solution; Borderline-SMOTE - Modified Synthetic Minority Oversampling Technique
Source(s): Own elaboration
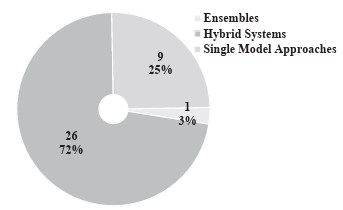
Figure 4 shows the amounts and percentages of the solution methods applied to the CSMs. The most used methods were LR (13%), NB (10%) and ANN (7%). Furthermore, according to Louzada et al. (2016) and Andriosopoulos et al. (2019), three methodological schemes can be identified for constructing CSMs: ensemble, hybrid system and single-model approaches. The distribution of the methodological schemes applied to each study is shown in Table 4 . Figure 5 displays the modelling types used in the studies according to the classification presented by Louzada et al. (2016).
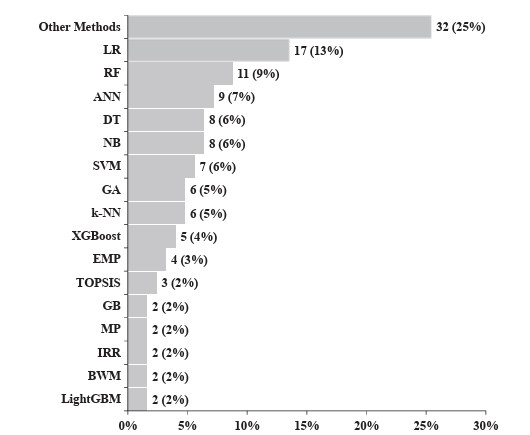

Figure 5 demonstrates that the most commonly used modelling types are Hybrid Systems (72%), followed by single-model approaches (25%) and ensembles (3%). Single-model approaches propose CSMs using only one method ( Andriosopoulos et al., 2019 ). Hybrid Systems combine diverse techniques and modelling schemes in different ways to improve CSMs’ performance ( Louzada et al., 2016; Andriosopoulos et al., 2019 ). Although many techniques have been explored for Hybrid Systems, only one is typically implemented in the final prediction ((Chen et al., 2016; . Lin et al. (2012 ) presented three approaches to construct a Hybrid System: cascade, integration and clustering combination modes. A summary of these approaches is provided in Table 5 .

Ensembles combine different models developed using one or more algorithms to obtain better classifiers ( Louzada et al., 2016 ; Andriosopoulos et al., 2019 ). A literature analysis shows that the most used ensemble models are Piling, Bagging and Impulsing. These models’ performance depends on the diversity of the methods used to reduce their bias (Louzada et al., 2016; Andriosopoulos et al., 2019 ; Breeden (2021 ). Analyses of the studies also confirmed that researchers used large and diverse databases with many variables to apply CSMs. These databases can be synthesised into three categories: i) Banks (22%), ii) Other Databases (53%) and iii) UCI Repositories and Others (25%). The frequencies of the databases used in these studies are shown in Figure 6 .
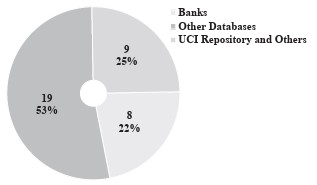
Figure 6 indicates that most researchers have used Other Databases to develop CSMs. These are the main Other Databases: i) Lending Club in the United States; ii) US and China P2P Platform; iii) Credit Bureau Germany and Australia; iv) PAKDD; v) GMSC; vi) Homecredit and vii) Financial Institutions Platforms in Benelux and the UK The literature also demonstrates that these studies used 22 databases to formulate CSMs. Thus, eight researchers used data from banks across several countries. Another six studies used databases available in the UCI Repository of the Machine Learning Database. In another three studies, the researchers dealt with UCI databases and other platforms, such as the Greek banks PAKDD and Kaggle, and financial institutions from Benelux and the UK.
6. Discussion
A literature review demonstrates the use of different techniques and approaches for formulating CSMs. The analysed papers present CSMs formulated upon applying different techniques and methods to solve various problems present in various contexts and realities that configure the CS. We demonstrated that CS approaches are directly related to the context and characteristics of the problems, together with the choices of the most appropriate methods for CSMs. The most recent CSM studies are based on profit and loan profitability estimates instead of focusing only on payment default probability. This is because researchers concluded that the causes of profitability differ from the reasons for default. Customers with a high probability of payment non-compliance may also be profitable ( Serrano-Cinca and Gutiérrez-Nieto, 2016 ; Onay and Ozturk, 2018 ). Thus, CSMs based on distinguishing payment delinquents and constructing a loan profit and profitability score resort to approaches such as the IRR, Game Theory, Statistical Techniques and Artificial Intelligence. There is a growing trend towards complex ML algorithms ( Xia et al., 2021 ; Kozodoi et al. (2022 ). For the theoretical framework, refer to Bravo et al., 2013), Řezáč, 2015), Verbraken et al. (2014 ), Serrano-Cinca and Gutiérrez-Nieto (2016), Onay and Ozturk, 2018) and Kozodoi et al., 2019). Recent studies have demonstrated that BD prompts disruptive changes in CSMs. The incorporation of a greater volume and variety of data linked to the need for higher speed in collecting and storing these data has become a challenge for CSMs ( Ashofteh and Bravo, 2021 ; Kang et al., 2021). This requires a broader approach, not only of the recorded history of borrowers’ payments and receipts but also data from social networks, information from apps and the so-called digital footprints ( Roa et al., 2021 ). Therefore, BD enables credit quality assessment for potential borrowers with a limited financial history (Onay and Ozturk, 2018). Recent studies address the application of DL and alternative data using psychometric variables and/or email-use characteristics to predict consumer default probabilities ( Dastile and Celik, 2021 ; Djeundje et al., 2021; Roa et al., 2021). Banks, fintech companies, credit bureaus and other non-banking providers of financial services use BD to achieve a higher level of precision in their services. However, this new reality has introduced regulatory challenges in preventing discrimination and consumer rights (Onay and Ozturk, 2018). Current studies include themes such as equity in customer classification (Kozodoi et al. (2022), sustainability issues in CS ( Roy and Shaw, 2022 ) and the incorporation of macroeconomic variables that can directly affect CSMs (Xia et al., 2021).
7. Conclusions
This study presents a literature review of the most recent optimisation methods applied to CSMs. The Scopus, ScienceDirect and Web of Science databases were used (from 2008 to 2022). This investigation led to the selection of 36 papers proposing CSMs. These CSMs are used to assess the risk of payment default when granting credit, namely Credit Scoring (CS). Their findings show that CSMs are usually formulated using financial analysis, ML, statistical techniques, operational research and data-mining algorithms. The analysis identified 48 methods used by researchers for construction, performance tests and comparisons between CSMs. The most commonly used methods were LR (13%), NB (10%) and ANN (7%). Most models were formulated using three methodological schemes called Hybrid Systems (72%), followed by single-model approaches (25%) and ensembles (3%). Analyses of the studies also confirmed that researchers used large and diverse databases with many variables to apply CSMs. These databases can be synthesised into three categories: i) Other Databases (53%), ii) UCI Repositories and Others (25%) and iii) Banks (22%). The databases are as follows: i) banks from various nations (8); ii) UCI Repository of Machine Learning Database (6); iii) UCI, Greek banks PAKDD and Kaggle, financial institutions from Benelux and the United Kingdom (2), and Lending Club in the United States (2). These journals were Decision Support Systems, Expert Systems with Applications, European Journal of Operational Research and Journal of the Operational Research Society. Other studies have also used different databases to apply CSMs.
This study also demonstrated that recent studies have focused on the loan yield and profit-scoring theme of CSMs. Therefore, estimating only the PD is no longer the primary objective of all CSMs. The researchers’ shift in focus sheds light on a new perspective on maximising the financial results of loans in analyses that include CS. The main contribution of this study is to present the evolution of the state of the art and future trends in research aimed at proposing better CSMs. The results of this study can guide researchers and provide considerable practical implications for the application of CSMs. We also encourage researchers to consider legal and ethical issues and conduct studies aimed at micro- and small-sized companies for instalment sales and commercial credit through improvements or new CSMs. We conclude that advances in CS studies require new hybrid approaches that can integrate BD and DL algorithms into CSMs. These algorithms must consider practical issues to improve the level of adaptation and performance required for CSMs. Suggestions for future research are i) the Use of BD and DL in CSMs; ii) equity issues in credit ratings; iii) formulating CSMs focused on sustainability; iv) providing decision support tools for credit sales; v) improving CSMs for default risk and investment, instalment and credit sales decisions and viii) implementing legal and ethical issues in CSMs based on the General Data Protection Regulation.

