











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
La enorme afluencia de publicaciones científicas en torno a la pandemia por la enfermedad del coronavirus 2019(COVID-19) ha generado gran masa de información, que en gran parte puede carecer de calidad y de fuerza de evidencia. Antes de la pandemia, se estimó que hasta el 85% de la investigación era considerada deficiente, esto debido a preguntas irrelevantes, diseños de estudio inadecuados, falta de regulación, y presentación deficiente de los resultados1. De esa forma, se ha observado un gran número de publicaciones relacionadas al COVID-19 en revistas indexadas en Web of Science y Scopus, el cual va en aumento. En efecto, las áreas con mayor frecuencia de publicaciones son medicina interna, salud ocupacional, enfermedades infecciosas y virología, asimismo gran parte de esta evidencia consiste en artículos de opinión y revisiones2.
Debido a esto, es inherente que toda la evidencia disponible sea interpretada adecuadamente, tanto por los redactores de artículos, como por los lectores. Un adecuado entendimiento asegurará un buen camino en la toma de decisiones en la práctica clínica y en salud pública. En función de ello, los profesionales de salud y tomadores de decisiones deben conocer los aspectos metodológicos y prácticos que permitan una lectura crítica e interpretación adecuada.
En este artículo revisaremos los puntos clave de la lectura e interpretación, por lo que reportaremos una secuencia de métodos que va desde el reconocimiento de la pregunta de investigación hasta la interpretación de los resultados de un estudio. Este artículo pretende brindar las herramientas necesarias para que un lector pueda interpretar adecuadamente la evidencia científica.
CONTENIDO
Jerarquía de los niveles de evidencia
La evidencia científica no tiene una perspectiva lineal u horizontal. Esta premisa se basa en aspectos de calidad y relevancia para la práctica clínica o la toma de decisiones en los distintos niveles de atención. Más allá de la jerarquización de la evidencia científica, se toma en cuenta el impacto de la validez externa de los resultados de un estudio, y el impacto en la toma de decisiones de los clínicos o salubristas para llevar a cabo acciones que resulten en beneficio, principalmente, de los pacientes.
En el contexto de la pandemia por COVID-19, se han publicado distintos tipos de investigaciones, desde editoriales3, cartas al editor4, reportes de caso5, estudios observacionales6 , ensayos clínicos7 y revisiones sistemáticas8; pero: ¿Cuál es el orden de jerarquía? ¿A qué se debe esa verticalidad?.
Debido a la compleja metodología de ensayos clínicos y revisiones sistemáticas, estas serán abordas en un artículo de revisión dedicado a su lectura e interpretación. A continuación, describiremos los distintos niveles hasta llegar a los estudios observacionales.
Si lo planteamos como una pirámide (Figura 1), observamos en la base a las opiniones de expertos, los reportes y series de casos, y los artículos de opinión (y de revisión) 2. Las opiniones de expertos son comentarios o recomendaciones que brindan los especialistas en función de su experiencia, consecuentemente, carecen de validez para la toma de decisiones con certeza de la evidencia, puesto que no ha sido validado por ningún método científico, independientemente de la razón o de la resolución inmediata de un problema de salud9. En esta pandemia, por ejemplo, se ha escuchado en los medios de comunicación a varios profesionales recomendar tratamientos, independientemente de la evidencia publicada. Esto carece de valor científico, porque no se puede atribuir eficacia únicamente basada en la experiencia clínica.
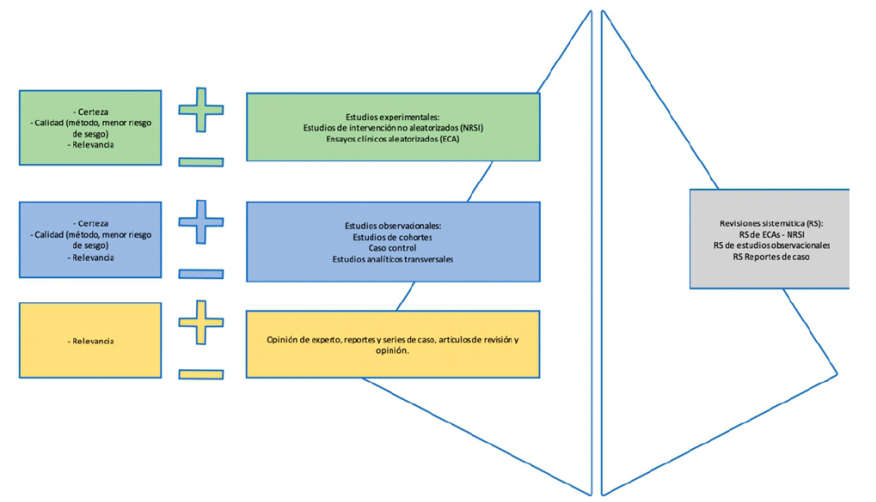
Figura 1 Pirámide de la jerarquía en la evidencia científica. Esta figura fue generada por los autores
Por otro lado, un reporte de caso es el informe detallado de un individuo que incluye aspectos como la exposición, los síntomas, los signos, la intervención y el resultado. Con más de cuatro casos se puede considerar una serie de casos10.
Los artículos de revisión están escritos en un formato de fácil lectura, y permiten la consideración del tema dentro de un amplio espectro, pero no considera la respuesta a una pregunta clínica, y por lo tanto no se rige de criterios de búsqueda específicos, ni genera una secuencia de selección y síntesis de evidencia11.
Cada nivel en la jerarquía de la evidencia, por lo tanto, debe responder a un nivel de pregunta clínica específica12. Las preguntas pueden ir enfocadas a problemas asociados al tratamiento/prevención/etiología, pronóstico, diagnóstico, prevalencia o análisis económico. De esta manera, además de una pirámide de jerarquía, podemos establecer niveles de evidencia para la toma de decisiones clínicas en función de los tipos de estudio (Tabla 1).
Tabla 1 Niveles para la medicina basada en la evidencia.
| Nivel de evidencia | Tipo de estudio |
| 1A | Revisiones sistemáticas de ECAs |
| 1B | ECAs |
| 2A | Revisiones sistemáticas de estudios de cohorte |
| 2B | Estudios de cohorte |
| 2C | Estudios ecológicos |
| 3A | Revisiones sistemáticas de estudios de caso control |
ECAs: Ensayos clínicos aleatorizados
Es necesario considerar que a pesar de la existencia de niveles en función del tipo de estudio, existen aspectos metodológicos dentro de cada tipo de estudio que deben tener en cuenta al momento de sintetizar la evidencia. Por ejemplo, hay errores metodológicos, estadísticos y de inferencia, que pueden convertir a un estudio de ensayo clínico aleatorizado (ECA) en una referencia con muy alto riesgo de sesgo, por lo cual se debe tener consideración al momento de sistematizar la información que proporciona. El Manual Cochrane de revisiones sistemáticas de intervenciones 13 recomienda el Risk of Bias tool para valorar el sesgo en ECAs según dominios, como aleatorización, desviaciones por intervenciones, pérdida de datos, medida del desenlace y selección de resultados reportados.
¿Qué son los estudios observacionales?
Un estudio observacional es aquel donde el investigador registra datos, mas no interviene asignando una intervención. Según el seguimiento, estos se pueden clasificar en transversales, donde se evaluó a la población de interés en un solo punto de tiempo, y longitudinal, donde hubo un seguimiento propiamente dicho. El objetivo puede variar desde describir la frecuencia de una patología hasta evaluar la asociación entre una exposición y un evento.
Si la variable de interés es la exposición, entonces se busca la asociación con el desenlace (que puede ser enfermedad, o cualquier otro evento). En cambio, si la variable de interés es el desenlace, entonces se busca la asociación con la exposición. Un tercer punto en los estudios observacionales (además de la exposición y el desenlace). De esta manera, podemos clasificar a los estudios observacionales en los siguientes tipos.
Estudios de cohortes
Una cohorte es un grupo humano que recibe un seguimiento por parte de los investigadores14. En estos estudios, la variable de interés es la exposición a un factor, y se busca conocer la asociación con un desenlace específico (enfermedad o evento), en función del tiempo. De esta manera, un estudio de cohorte describe a dos grupos (uno “expuesto” y otro “no expuesto” a un factor) que en un tiempo determinado puede desarrollar un desenlace, o no desarrollarlo. La temporalidad determina el tiempo de seguimiento a estos grupos de sujetos. Así, podemos hacer un seguimiento prospectivo (desde el inicio del reclutamiento hasta el término del estudio), retrospectivo (desde la captación de sujetos con el evento hasta un tiempo pasado en común en que se inició la exposición) (Figura 2). Por ejemplo, la cohorte del estudio de Framingham fue iniciada en la década de los 50s en Boston, y reclutó más de 5000 adultos para conocer los factores asociados (exposición) con enfermedad cardiovascular (desenlace) 15.
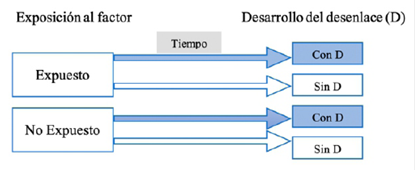
Veamos un ejemplo: en el estudio de Cavalli G. et al16 se investigó acerca del bloqueo de interleucina-1 (IL-1) con altas dosis de Anakinra en pacientes con COVID-19, síndrome de distrés respiratorio e hiperinflamación. Los autores compararon dos grupos: uno con altas dosis de anakinra (grupo expuesto) y otro con un tratamiento estándar (grupo no expuesto). Los investigadores describieron como su desenlace principal a la mortalidad al día 21 de hospitalización. Obtuvieron que al día 21, tres pacientes (10%) del grupo expuesto tuvo el desenlace, mientras que siete pacientes (44%) del grupo no expuesto tuvieron el desenlace. Este ejemplo se considera como estudio de cohortes porque cumple con los tres aspectos básicos del diseño: comparación entre grupos de exposición, desarrollo del evento de interés y temporalidad.
Tenemos que considerar, que la determinación del diseño por parte de los autores del estudio publicado, no necesariamente se corresponde al diseño original del método. Por ejemplo, en el estudio de Wichmann D. et al. 17 investigaron acerca de los hallazgos en la autopsia y tromboembolismo venoso en pacientes con COVID-19. Los autores describieron las características clínicas y patológicas de 12 pacientes. Además, en el título del trabajo, incluso en la metodología, los autores resaltan que se trata de un estudio de cohorte prospectivo. Sin embargo, no hay comparación de grupos de exposición, y por lo tanto no hay comparación entre los grupos y eventos de interés, independientemente del tiempo.
Esto indica que el lector debe tener la capacidad de discriminar los diseños de investigación, independientemente del diseño expuesto en el artículo que se está leyendo.
Estudios de caso control
Son estudios analíticos que, a diferencia de los estudios de cohorte, el principal interés es conocer cómo el desenlace se asocia con un factor específico18. De esta manera, se tiene a dos grupos (con el desenlace y sin el desenlace) y se busca conocer si estuvieron expuestos o no a un factor específico. La temporalidad en este diseño es, por lo tanto, retrospectiva (Figura 3).
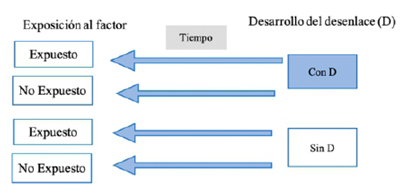
Veamos un ejemplo: En el estudio de Tang X., et al (2020) 19, compararon a los pacientes hospitalizados con síndrome de distrés respiratorio agudo causados por COVID-19 e influenza tipo AH1N1. El desenlace evaluado fue la mortalidad. Los autores encontraron que de 73 pacientes expuestos a COVID-19, 21 pacientes (35,6%) tuvieron el desenlace. Por otro lado, de 75 pacientes con influenza AH1N1, 26 pacientes (34,7%) tuvieron el desenlace.
El anterior ejemplo se trata de un estudio de caso control, porque cumple con los criterios del diseño: grupo casos (pacientes que murieron), grupo control (pacientes que no murieron), exposición (COVID-19 o AH1N1), y temporalidad (retrospectiva).
Estudios analíticos transversales
Los estudios transversales tienen un diseño distinto a los estudios de cohorte o caso control. La diferencia está en que los estudios transversales (cross-sectional, en inglés) dirigen su interés en encontrar la asociación de un desenlace respecto a un factor expuesto, sin considerar la relación temporal entre estas variables.
¿Cuál es el proceso para leer estudios observacionales? Para leer un artículo científico, primero debemos saber cómo llegar a obtenerlo, esto es, establecer una ruta de búsqueda que permita tener siempre la información disponible. Para ello se establece la pregunta clínica y la estrategia de búsqueda para bases de datos médicas. Estas bases de datos son, por ejemplo: Pubmed, Scopus, Web of Science, Embase. Otra ruta es la suscripción a revistas científicas o utilización de repositorios o páginas web que conjugan publicaciones científicas de diferentes revistas (Tripdatabase, Epistemonikos, Researcher-app).
Una estrategia de búsqueda que nos puede ayudar al hallazgo de estudios en COVID-19, para cada base (Tabla 2).
Tabla 2 Estrategia de búsqueda para estudios sobre COVID-19
| Base de búsqueda | Estrategia |
| Pubmed | (“COVID-19” OR “2019 novel coronavirus disease” OR ”COVID19” OR ”COVID-19 pandemic” OR ”SARSCoV-2 infection” OR ”COVID-19 virus disease” OR ”2019 novel coronavirus infection” OR ”2019-nCoV infection” OR ”coronavirus disease 2019” OR ”coronavirus disease-19” OR ”2019-nCoV disease” OR ”COVID-19 virus infection”) |
| Scopus | TITLE-ABS-KEY(“COVID-19” OR “2019 novel coronavirus disease” OR “COVID19” OR “COVID-19 pandemic” OR “SARS-CoV-2 infection” OR “COVID-19 virus disease” OR “2019 novel coronavirus infection” OR “2019-nCoV infection” OR “coronavirus disease 2019” OR “coronavirus disease-19” OR “2019-nCoV disease” OR “COVID-19 virus infection”) |
| Web of Science | TS=(“COVID-19” OR “2019 novel coronavirus disease” OR ”COVID19” OR ”COVID-19 pandemic” OR ”SARS-CoV-2 infection” OR ”COVID-19 virus disease” OR ”2019 novel coronavirus infection” OR ”2019-nCoV infection” OR ”coronavirus disease 2019” OR ”coronavirus disease-19” OR ”2019-nCoV disease” OR ”COVID-19 virus infection”) |
Cuando ya sabemos el artículo que vamos a leer, primero debemos saber identificar los aspectos relevantes del estudio. Estos aspectos abarcan, entre otras (Figura 4).
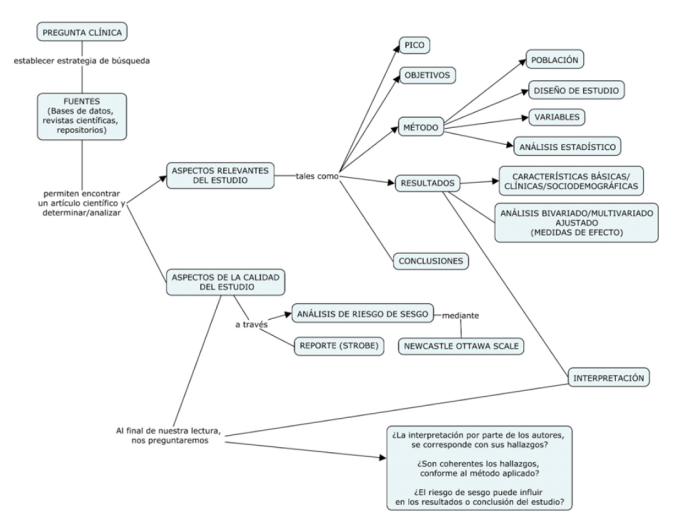
Figura 4 Proceso para la lectura de un estudio observacional Esta figura fue generada por los autores
Pregunta PICO: El título y el resumen nos dan una perspectiva para inferir la PICO (Población, Intervención, Comparador, Desenlace); o la PEO (Población, Exposición, Desenlace).
Objetivos: Tanto el resumen como la parte final de la introducción nos permiten identificar el objetivo. Algunos estudios no dejan implícito, por lo que el lector algunas veces debe inferir el objetivo en función de los hallazgos y las conclusiones del estudio.
Método: El punto principal aquí es identificar el diseño (¿Observacional? ¿Cohorte, caso control o transversal? ¿Retrospectivo o Prospectivo?); así como las variables (de exposición, de desenlace, confusores) y el método de análisis estadístico ( análisis descriptivo, análisis bivariado-multivariado). También se debe tener en cuenta cómo identificaron/ trataron a su muestra (recolección de datos, tiempo de seguimiento, cálculo del tamaño de muestra, muestreo)
Resultados: La mayoría de los estudios observacionales, dispone en su primera tabla a las características básicas, clínicas o demográficas de los participantes. Esta tabla puede estar descrita según los desenlaces o la exposición. En el análisis bivariado-multivariado vamos a identificar las medidas de efecto (Odds ratio [OR], riesgo relativo [RR], diferencia de riesgo [RD], razón de prevalencias [RP]).
Conclusiones: En este punto tenemos dos perspectivas. La primera son las conclusiones que los autores describen en el artículo. La segunda son las conclusiones a las que llega el lector. Se debe asumir que ambas perspectivas deben ser coherentes y tener al menos premisas similares.
Aspectos esenciales en el análisis de riesgo de sesgo
Los sesgos pueden dar lugar a errores sistemáticos o alejar del verdadero efecto del desenlace ante una exposición determinada20. En términos generales, un error sistemático en el diseño, en la ejecución o el análisis de un estudio, puede acontecer en una estimación errada del efecto de la exposición sobre el riesgo de tener el desenlace, lo que indica sesgo21.
En general, podemos hablar de dos sesgos esenciales: sesgo de selección y sesgo de información. El sesgo de selección resulta del hecho de que la composición de los grupos estudio difieren de la población fuente22. Cuando la comparación entre los grupos de exposición (grupo expuesto versus grupo no expuesto) a un factor determinado, difiere en los criterios de selección o de elegibilidad, puede sobre o sub-estimarse el efecto del desenlace.
Por ejemplo: En un estudio sobre el riesgo de enfermedad por COVID-19 en niños, se evaluaron dos grupos. El primer grupo (expuesto), estaba compuesto por niños cuyos padres eran trabajadores de salud (médicos y enfermeros) que laboraron en la primera línea de atención a pacientes con COVID-19. El segundo grupo (no expuesto), estaba compuesto por niños cuyos padres no eran trabajadores de salud pero que trabajaban fuera de casa. Se obtuvo que los niños cuyos padres eran trabajadores de salud, tuvieron mayor prevalencia de enfermedad por COVID-19, comparado con los niños cuyos padres no eran trabajadores de salud, pero trabajaban fuera de casa.
Es posible que el efecto estimado sea sobreestimado, porque hay desproporcionalidad en la comparación de los grupos de exposición, y eso indica que la selección de los grupos de comparación puede estar sesgado, lo que conduce a una interpretación errónea de los resultados.
Para poder evaluar en una mayor perspectiva, si un estudio observacional tiene un determinado riesgo de sesgo, podemos utilizar la herramienta “Newcastle Ottawa Scale (NOS)”. Esta escala fue creada para evaluar la calidad de estudios no aleatorizados con el fin incorporar las evaluaciones de calidad en la interpretación de metaanálisis. La NOS evalúa la calidad a partir del contenido, diseño y facilidad de uso en la interpretación del metaanálisis. Está compuesta por ocho ítems, divididos en tres dimensiones (selección, comparabilidad y resultado) para estudios de cohorte, (selección, comparabilidad y selección) para estudios de caso-control23.
Reporte y publicación de los estudios observacionales Para el reporte de los estudios observacionales, se requiere de la aplicación de la declaración STROBE24. La declaración STROBE es una lista de verificación de los elementos que deben abordarse en los artículos con el diseño de estudio observacional: estudios de cohortes, de caso control y analíticos transversales. Estas recomendaciones permiten orientar sobre los aspectos esenciales y estructurales de cómo informar o escribir, pero no influyen sobre el diseño o la realización de los estudios. La recomendación STROBE, se compone de una lista de comprobación de 22 puntos que se relacionan con el título y el resumen del artículo (ítem 1), la introducción (ítems 2 y 3), los métodos (ítems 4- 12), los resultados (ítems 13-17) y las secciones de discusión (ítems 18-21), y financiamiento (ítem 22). 18 ítems son comunes a los tres diseños, mientras que cuatro (ítems 6, 12, 14 y 15) son específicos para cada tipo dentro del diseño del estudio.
Métodos de análisis y medidas de efecto en los estudios observacionales
Existen diversos métodos de análisis para describir los resultados, que están en función del objetivo del estudio y de la propuesta estadística del método de investigación.
Estadística descriptiva
En este nivel de análisis se “describen” las características básicas de las variables de estudio o de los atributos, incluyendo la unidad de análisis o población de estudio. Las variables de naturaleza contínua (numérica) serán evaluadas mediante medidas de tendencia central (media o mediana) y dispersión (desviación estándar o rango intercuartil), en función de su distribución. Por otro lado, las variables de naturaleza categórica (nominal) serán evaluadas mediante frecuencias relativas y absolutas (porcentuales).
Estadística inferencial
En este tipo de análisis se realiza la comparación entre variables, con el objetivo de evaluar la relación (correlación), asociación o diferencias estadísticas. El tipo de análisis depende de la naturaleza de las variables contrastadas. Para variables cualitativas, se utiliza la prueba de Chi cuadrado; además, se requiere conocer si las muestras a comparar son dependientes o independientes. Respecto a las variables cuantitativas, también se requiere establecer si se trata de muestras dependientes o independientes, así como se necesita conocer su distribución antes de aplicar una prueba. La distribución se puede evaluar con el histograma, o mediante pruebas de normalidad, como la de Kolmogorov-Smirnov o Shapiro-Wilks (muestras pequeñas). Luego de conocer la distribución de la variable contínua, si se tratan de muestras independientes mayores a 30, se aplicará la prueba de Levene para conocer la homocedasticidad, de manera que se pueda aplicar la prueba de t de student (si las varianzas son iguales) o de Welch (si las varianzas no son iguales).
Medidas de efecto o de asociación
Las medidas de asociación en estudios observacionales son el odds ratio (OR), el riesgo relativo (RR), la razón de prevalencia (RP), y el hazard ratio (HR). Existen otras medidas, consideradas medidas de impacto, tales como la diferencia de riesgo (RD), la fracción atribuible (FA), número necesario para tratar (NNT).
Existen nuevos métodos de análisis que permiten simular que un estudio de cohorte sea un ensayo clínico. Por ejemplo, recientemente Soto-Becerra y col.25publicaron un target trial para comparar la efectividad de las terapias utilizadas para COVID-19. Para ello utilizaron un análisis de propensity score para balancear las diferencias entre los grupos.
CONCLUSIONES
En esta revisión se abordaron los diseños de investigación observacionales (transversales analíticos, casos y controles y cohortes); asimismo se estableció su valor en la jerarquía de la evidencia. Llamamos la atención tanto a los que elaboran propuestas de investigación, así como a los lectores, a considerar cautelosamente los diferentes diseños de investigación y su aplicación según la pregunta formulada, así mismo, el respeto en cada paso de este proceso. Todo ello cuenta para poder extrapolar los resultados a la población de estudio e incorporarlo en la práctica de la medicina basada en evidencias. Es importante resaltar que se requieren herramientas para poder hacer una valoración crítica de la investigación, elementos como el control de confusores, la presencia de sesgo, el tamaño de la muestra de estudio, entre otros. Por otro lado, la manera de presentar nuestros hallazgos, en ese sentido, adherirnos a las recomendaciones de la redacción científica establecida por iniciativas como STROBE. La pandemia de la COVID-19 ha puesto a prueba a todos los investigadores y lectores de investigación científica, sobre el uso de criterios de calidad tanto para generar conocimiento válido como para aplicarlo en el cuidado de la salud de pacientes enfermos.

