








Serviços Personalizados
Journal

Artigo
 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por emailIndicadores
-
 Citado por SciELO
Citado por SciELO
Links relacionados
-
 Similares em
SciELO
Similares em
SciELO  uBio
uBio
Compartilhar

 Permalink
PermalinkRevista de Investigaciones Altoandinas
versão On-line ISSN 2313-2957
Rev. investig. Altoandin. vol.19 no.2 Puno abr./jun. 2017
http://dx.doi.org/10.18271/ria.2017.279
REPORTE DE CASO
RMySQL para el análisis de datos de postulantes e ingresantes del área biomédicas a la Universidad Nacional del Altiplano – Puno Perú
RMySQL for the analysis of data of postulants and entrants of the biomedical area to the National University of the Altiplano – Puno Perú
Adolfo Carlos Jiménez Chura
Escuela Profesional de Ingeniería de Sistemas de la Universidad Nacional del Altiplano Puno – Perú.
Correspondencia email: adolfocarlos300@hotmail.com
RESUMEN
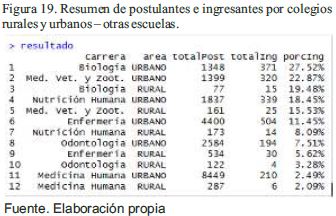
El objetivo fue aplicar RMySQL, dplyr y funciones de graficación de la base de datos de los procesos de admisión de la Comisión Central de Admisión de la Universidad Nacional del Altiplano. Se implementó el código fuente de las funciones que retornan data.frames de las observaciones de la base de datos y funciones para generar los gráficos de forma dinámica tales como ggplot y barplot; se usó summarise, select, group_by, merge, arrange, unique y otras del proyecto R. El resultado indica que el porcentaje de ingresantes, de los procesos de admisión ordinario y extraordinario, en función a la cantidad de postulantes es: el 22.91% ingresan a Medicina, Veterinaria y Zootecnia; el 10.87% a Enfermería; 26.83% a Biología; 2.44% a Medicina Humana; 17.64% a Nutrición Humana y 7.25% a Odontología, comprendidos entre el 17 de marzo del 2013 al 22 de enero del 2017; igualmente, el porcentaje de ingresantes por procedencia de colegio del área urbana y rural se obtuvo que la Escuela Profesional de Biología tiene el mayor porcentaje, 27.52% y 19.48% del área urbana y rural; Medicina, Veterinaria y Zootecnia un 22.87% y 15.53% del área urbana y rural; Nutrición Humana un 18.48% y 8.09% del área urbana y rural; Enfermería un 11.45% y 5.62% del área urbana y rural; Odontología un 7.51% y 3.24% del área urbana y rural; y Medicina Humana un 2.49% y 2.09% área urbana y rural.
PALABRAS CLAVES: estadística, funciones, librerías, procesos de admisión, tecnología.
ABSTRACT
The objective was to apply RMySQL, dplyr and graphing functions of the database to the processes of admission at the Central Admission Commission at the National University of the Altiplano. The source code of the functions that return data.frames of the observations of the database and functions was implemented to generate the graphs of dynamic form such as ggplot and barplot; summarise, select, group_by, merge, arrange, unique and others of project R were used. The result indicates that the percentage of entrants, of the ordinary and extraordinary admission processes, according to the number of applicants is: 22.91% were admitted to Medicine, Veterinary and Animal Science; 10.87% to Nursing; 26.83% a Biology; 2.44% in Human Medicine; 17.64% to Human Nutrition and 7.25% to Dentistry, included between March 17, 2013 and January 22, 2017; also, the percentage of admissions by origin of school in the urban and rural area obtained shows that the Professional School of Biology has the highest percentage, 27.52% and 19.48% of the urban and rural area; Medicine, Veterinary and Animal Husbandry 22.87% and 15.53% of the urban and rural area; Human Nutrition 18.48% and 8.09% of the urban and rural area; Nursing 11.45% and 5.62% of the urban and rural area; Dentistry 7.51% and 3.24% of the urban and rural area; and Human Medicine 2.49% and 2.09% urban and rural area.
KEYWORDS: statistics, functions, libraries, admission processes, technology
INTRODUCCIÓN
La Universidad Nacional del Altiplano a través de la oficina de la Comisión Central de Admisión (CCA) organiza procesos de admisión para alcanzar una vacante de ingreso en sus dos modalidades: examen ordinario (general y cepreuna) y extraordinario. En cada proceso de admisión se recopila información de los postulantes tales como Escuela Profesional a la que postula, género, fecha de nacimiento, lugar de nacimiento, tipo de colegio, área al cual pertenece (rural, urbano), nombre del colegio, etc. Se tiene gran cantidad de información que puede ser analizada con un software estadístico tal como STATISTICA, EVIEWS, STATA, SAS, S-PLUS, SPSS, MATLAB, R entre otros (Mirabal Sosa, 2010). Los programas mencionados son comerciales excepto R, que es un software libre especialmente desarrollado para el análisis estadístico y la presentación gráfica de los datos.
R es un proyecto que surgió en 1990 y se deben a Ross Ihaka y Robert Gentleman del Departamento de Estadística de la Universidad de Auckland. R y un software libre y compila en las tres plataformas más importantes: Linux, Windows y MacOS (Flores Sánchez, 2013) y existe un grupo de personas que desde 1997 se ocupan del mantenimiento del sistema denominada The R Core-Development Team. (Mirabal Sosa, 2010).
Existen diversos investigadores de diferentes áreas que usan las características de R para crear paquetes avalados por CRAN (The Comprehensive R Archive Network) (R, 2017) de aplicación general o particular, paquetes como ggplot2 para graficación; dplyr y sus cinco (5) funciones básicas filter, select, arrange, mutate y summarise; para integración con gestores de base de datos se tiene RPgSQL (PostgreSQL), ROracle (Oracle), RMySQL (MySQL), RODBC (origen de datos ODBC) (Tussell F., 2005) y RSQlite (SQLite). Estos y muchos otros paquetes pueden descargarse desde la página oficial en https://www.r-project.org.
Grandes empresas están incluyendo R en su estrategia de análisis predictivo, el 70% de encuestados por "Rexer Analytics" indica que usan R para minería de datos y análisis científico (Tecnológica, 2014).
R es un lenguaje de programación simple que admite condicionales, iteraciones, creación de funciones, funciones definidas por el usuario y tiene una sintaxis muy similar a C/C++ (Mirabal Sosa, 2010) y gracias a estas instrucciones se pueden realizar cálculos fundamentalmente estádisticos (Team, 2008) además, contiene dos instrucciones muy importantes y son install.packages(nombPaquete) que permite descargar e instalar el paquete y library (nombPaquete) que permite usar las variables, funciones y objetos implementados del paquete.
Para presentar información en gráficos estadísticos y tomar ciertas decisiones, lo primero es realizar consultas específicas sobre la base de datos, luego exportarlo a un software tal como Excel, darle el formato adecuado para finalmente obtener el gráfico. RMySQL es un paquete que se integra con la base de datos MySQL y tiene la ventaja de crear consultas en una base de datos relacional con información en tablas, filas y columnas, de forma muy similar a un data.frame (tabla) con observaciones (filas) y variables (columnas) y, con paquetes adicionales se puede obtener un gráfico estadístico con sólo invocar a las funciones con los parámetros adecuados.
Se tiene antecedentes sobre la comunidad científica que viene produciendo diferentes publicaciones en investigación resaltando las ventajas que ofrece R, por ejemplo en el campo de la investigación psicológica (Anchía, 2010) donde se aplica cálculos de correlaciones policóricas con el paquete polycor; en el campo ecológico se tiene el paquete WaterML para gestionar los datos experimentales de diferentes instituciones utilizando tecnología de código abierto para establecer una comunicación con una base de datos relacional a través del paquete RObsDat (Kadlec, Bryn, Daniel P., y Richard A., 2015); también el paquete ARNN para la predicción de series de tiempo no lineales usando en redes neuronales autoregresivas (Velasquez, Laura, y Cristian, 2011).
Por los puntos mencionados este estudio tiene por objetivo cargar información de postulantes e ingresantes en un data.frame realizadas con consultas SQL (Standard Query Language) (Piattini Velthuis, Martines, Muñoz, y Sánchez, 2006) simples o complejas con el paquete RMySQL como medio de interface con la base de datos MySQL, seguidamente realizar el procesamiento de los datos con las ventajas que ofrece el paquete dplyr (Wickham, A Grammar of Data Manipulation, 2016) y así evitar realizar consultas SQL de agrupación, filtrado, selección, etc. sobre la base de datos y con el uso de las funciones de graficación como ggplot, barplot obtener e interpretar información mencionada del área biomédicas de la Universidad Nacional del Altiplano.
MATERIALES Y MÉTODOS
La presente investigación tuvo lugar en la oficina de la Comisión Central de Admisión de la Universidad Nacional del Altiplano – Puno, durante los meses de enero y marzo del 2017. La población de estudio estuvo conformada por los postulantes e ingresantes del área biomédicas: Medicina Veterinaria y Zootecnia, Enfermería, Biología, Medicina Humana, Nutrición Humana y Odontología. Los procesos de admisión en estudio están comprendidos desde el 17 de marzo del 2013 al 22 de enero del 2017.
Para el entorno de trabajo se usó el software RStudio (RSudio, 2017), el paquete RMySQL (Jeroen Ooms, 2016) como interface entre la base de datos y R y del paquete dplyr las funciones implementadas (Wickham y Francois, 2017) para realizar las agrupaciones de datos, selección, filtrado de una o más variables almacenados en un objeto de tipo data.frame de postulantes e ingresantes. Para establecer la conexión a la base de datos se usó la función dbConnect de la librería RMySQL: Library(RMySQL)
con dbConnect(RMySQL::MySQL(),
dbname = "database",
user = "root",
password = "123",
port = 3306)
R al igual que otros lenguajes de programación permite crear funciones con los comandos e instrucciones requeridos. Se creó un script donde se encuentra los paquetes a cargar, funciones y variables a ser usadas para trabajar con la información. Para la carga del script en memoria y trabajar con las funciones se empleó la siguiente instrucción:
source("c: R/articulo.R")
La información de los procesos de admisión se encuentra almacenada en variables y se clasificó según el tipo de examen: general, cepreuna y extraordinario en las siguientes variables de tipo vector:

Se implementó la función "carreras" que retorna una lista con las variables id_carrera, id_grupo y nombre de la Escuela Profesional. El código de la función es el siguiente:

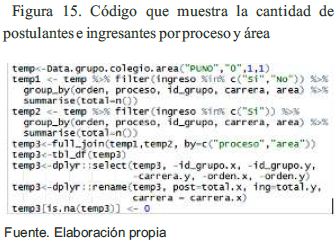
Para procesar la información de postulantes e ingresantes se implementó una función que retorna en una lista de datos de las variables proceso, departamento, provincia y si ingreso o no a la Escuela Profesional. Ésta recibe dos parámetros que indican el proceso a trabajar y el área biomédica.

La función de la Figura 3 tiene por nombre Data.post.ing.dep.prov y retorna un data.frame. El primer parámetro toma el valor de uno (1) que indica que se procesó las tablas de la base de datos cuyos nombres se encuentran en la variable tipo vector proc_general, si es dos (2) indica que procesó las tablas de la variable proc_cepreuna, tres (3) indica que se procesó las tablas de la variable proc_extraordinario, el segundo parámetro con el valor de uno (1) indica que es el área biomédica y el tercer parámetro, opcional, es el código de la Escuela Profesional.
Se usó el paquete dplyr para realizar las agrupaciones por departamento, provincia y el campo ingreso de todos los procesos de admisión, según las variables ya mencionadas. La instrucción usada es: datosresult %>% group_by(depart,prov) %>% summarise(total=n())
se implementó la siguiente función para generar el gráfico de cantidad de postulantes o ingresantes por proceso.
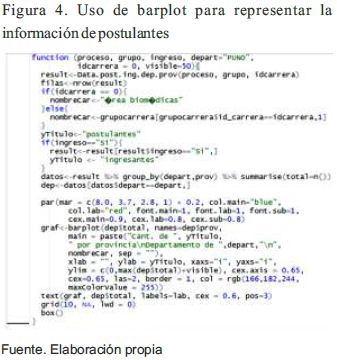
La siguiente función Data.grupo.colegio.area permite determinar la cantidad de postulantes e ingresantes de los colegios de la zona URBANA y zona RURAL de los diferentes procesos de admisión por Escuela Profesional del departamento de Puno. Dependiendo del parámetro proceso, éste tomará valores de las tablas de la base de datos almacenados en las variables proc_general, proc_cepreuna y proc_extraordinario, si se asigna el valor de cero (0) tomará todos los procesos de las tres (3) variables mencionadas. Para obtener datos de la Escuela Profesional se tien el parámetro idcarrera.

RESULTADOS Y DISCUSIÓN
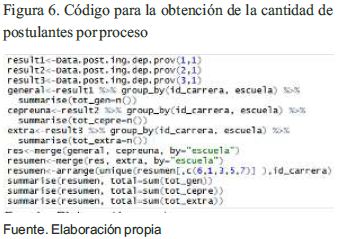
Análisis de postulantes: La implementación de la función Data.post.ing.dep.prov de la Figura 3 realiza una iteración sobre todas las tablas de la base de datos MySql, en esta línea (Velasquez, Montoya y Cataño, 2010) dan un aporte interesante acerca de la abstracción de datos en base a la programación funcional en R, por lo que en la Figura 6 se puede apreciar la utilidad de la función mencionada obteniendo un resultado de 14583, 7624 y 287 postulantes (observaciones) de los diferentes departamentos del Perú. La cantidad de postulantes de la región de Puno alcanzan una cifra de 13433, 7196 y 264 postulantes, lo que indica que el 92% de postulantes provienen de la región de Puno para el examen general, el 94% para el examen cepreuna y el 92% para el examen extraordinario, esto indica que cerca al 7.3% provienen de otros departamentos. Estos resultados se obtuvieron con el código de la Figura 6.
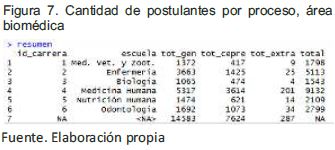
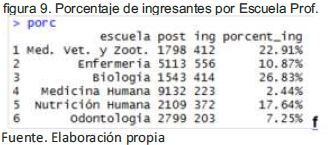
Análisis de ingresantes: La elección de la escuela profesional es importante, tal como se indica en (Duque, et al,, 2012), ya que es de vital importancia para el proyecto de vida del estudiante, esto se puede observar en la Escuela Profesional de Biología tiene la mayor cantidad de ingresantes en un 26.83%, por lo que existe una mayor preferencia por esta profesión frente a Medicina Veterinaria y Zootecnia que cuenta con un 22.91%, Nutrición Humana con 17.64%, Enfermería con 10.87%, Odontología con 7.25% y Medicina Humana con 2.44%.
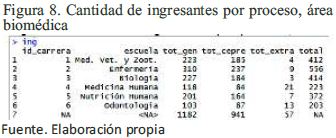
A la variable ing de la figura 8, se agregó una columna porcent de ingresantes y se relacionó con la variable post con la función inner_join del paquete dplyr. El código implementado es el siguiente:
ing$porcentpaste(round(ing$total*100/
post$total,2),"%", sep = "")
porcinner_join(ing,post,by="escuela")
porcselect(porc,1,10,5,6)
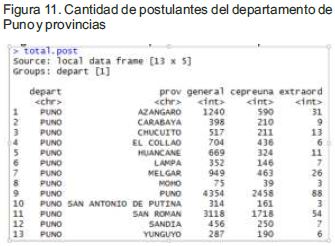
Análisis de postulantes por provincia del departamento de Puno: Este análisis muestra que los postulantes de la provincia de Moho no cuentan con una vocación, tal como indica (Vilaseca, 2009) tiene poco interés por aportar conocimiento en el área biomédica siendo ésta zona rural, o puede darse el caso de que no postularon a la Universidad. El resultado indicaque: 4354 provienen de la provincia de Puno, 3118 de la provincia de San Román, 1240 de Azángaro, 949 de Melgar, 704 de El Collao, 669 de Huancané, 517 de Chucuito, 456 de Sandia, 398 de Carabaya, 314 de San Antonio de Putina, 287 de Yunguyo y 75 de Moho. Para los procesos de admisión cepreuna y extraordinario se muestra en la Figura 11. Se puede observar que la proporción de postulantes se mantiene en las diferentes modalidades.

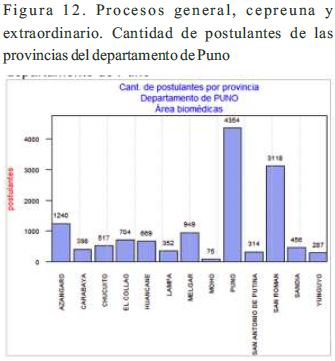
El resultado de la graficación de la información de los procesos de la variable proc_general, proc_cepreuna y proc_extraordinario se usó la función graf.post.dep.prov de la Figura 4, con las siguientes invocaciones:
graf.post.dep.prov(1,1,"No","PUNO", 0, 250)
graf.post.dep.prov(2,1,"No","PUNO", 0, 150)
graf.post.dep.prov(3,1,"No","PUNO", 0, 10)
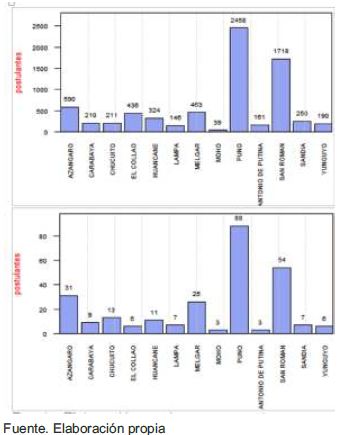
Análisis de ingresantes por provincia del departamento de Puno: El resultado muestra que para los exámenes generales se tiene que el 9.8% proceden de Puno, el 9.1% proceden de Melgar, el 8.2% proceden de San Román, etc. Para los exámenes cepreuna se tiene que el 17.7% proceden de Carabaya, el 14.5% proceden del Collao, el 14.2% proceden de Chucuito, etc. y para los exámenes extraordinario se tiene que el 33.3% proceden de El Collao, el 30.8% proceden de Chucuito, el 28.6% proceden de Sandia, etc.; tal como se muestra en la siguiente figura.
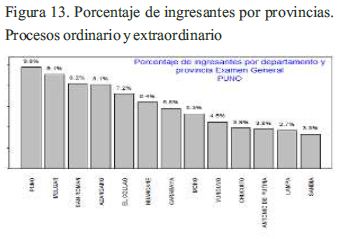
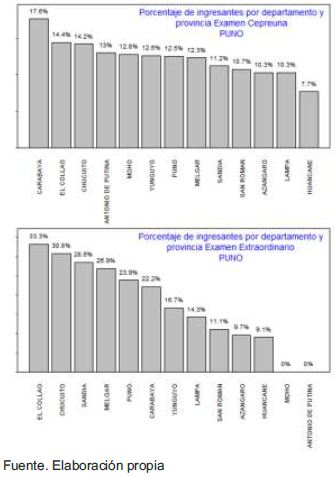
Para obtener esta información se usó el código de la Figura 10, adicionando el siguiente filtro: filter(depart=="PUNO" & ingreso=="Si").

Análisis de postulantes e ingresantes por procedencia de colegio urbana y rural: Según (Ramos, Duque, y Nieto, 2012), el rendimiento educativo en zonas urbanas es más altos que el de los rurales, esto puede deberse a las características de la familia o de la escuela, es se corrobora con los siguientes resultados, el mayor porcentaje de ingresantes, en función de la cantidad de postulantes la Escuela Profesional de Biología con un 27.52% y 19.48% en el área urbana y rural; Medicina, Veterinaria y Zootecnia un 22.87% y 15.53% en el área urbana y rural; Nutrición Humana un 18.48% y 8.09% en el área urbana y rural; Enfermería un 11.45% y 5.62% en el área urbana y rural; Odontología un 7.51% y 3.24% en el área urbana y rural; y Medicina Humana un 2.49% y 2.09% área urbana y rural.
Para determinar la cantidad de postulantes e ingresantes de los diferentes colegios del departamento de Puno por zona urbana – rural y por Escuela Profesional, se usó la función de la Figura 5, Data.grupo.colegio.area. Se implementó el siguiente código cuyo parámetro grupo toma el valor de cero (0) lo que indica que se procesó todos los procesos de admisión, el último parámetro toma valores entre 1 y 6, que son los códigos de las Escuelas Profesionales.
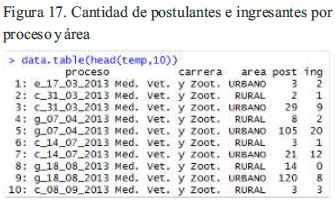
El resultado muestra las 10 primeras observaciones de la Escuela Profesional de Medicina, Veterinaria y Zootecnia. La primera columna contiene las fechas de los procesos de admisión cuyo primer carácter indica si es general (g), cepreuna (c) o extraordinario (e).

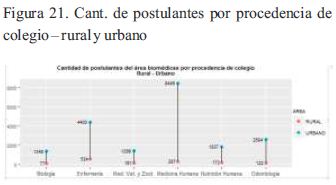
En el siguiente gráfico se usa el paquete ggplot para representar la información de los postulantes e ingresantes por colegio de procedencia del área rural y urbano.

El siguiente gráfico muestra el poco interés de los postulantes de colegios rurales de estudiar la Escuela Profesional de Medicina, Veterinaria y Zootecnia, cuando debería ser todo lo contrario, esto se debe a que las escuelas rurales no brindan los conocimientos necesarios a los escolares en su proyecto de vida y su sociedad rural (Salazar, 2017); las cifras indican que sólo se obtuvo 25 ingresantes de colegios del área rural en 32 procesos de admisión.

CONCLUSIONES
La efectividad del uso de los paquetes RMySQL, dplyr, ggplot y el propio R ofrece un gran aporte al análisis de datos llevando una clara ventaja frente a los programas de uso comercial, como SAS, SPSS y Excel; sin embargo, existe una limitante para aquellos profesionales que no tienen conocimientos sobre lenguajes de programación, esto dificultaría la preferencia por el uso de R y buscando alguna otra herramienta de análisis.
El mayor porcentaje de ingresantes en función a la cantidad de postulantes de los procesos general, cepreuna y extraordinario lo tienen las provincias de: Puno, Carabaya y El Collao, respectivamente; y un bajo índice de ingresantes las provincias de: Sandia, Huáncane y San Antonio de Putina y Moho, respectivamente.
Para el cálculo del porcentaje de ingresantes provenientes de colegios urbanos se ha considerado los diferentes tipos de colegios ya sea estatal o particular, donde la Escuela Profesional de Biología tiene un mayor índice de ingresantes, y la Escuela Profesional de Medicina tiene casi el mismo porcentaje de ingresantes del área urbana y rural.
REFERENCIAS BIBLIOGRÁFICAS
Anchía, R. J. (2010). Aportaciones del software libre R al proceso de investigación psicológica. MISCELANEA COMILLAS, 165-175.
Duque, D. C., Salazar, J. A., Giraldo, L. A., Castro, V. G., y Olivera, A. P. (2012). Prevalecencia de intereses y preferencias profesionales en estudiantes de grado 11 de instituciones educativas públicas de la ciudad de Ibague. Dialnet, 11.
Flores Sánchez, M. (2013). Desarrollo de una aplicación para gráficos de control de procesos industriales. Universidad de la Coruña, España. [ Links ]
Jeroen Ooms, D. J. (26 de agosto de 2016). Database Interface and 'MySQL' Driver for R. Obtenido de https://cran.r-project.org/web/packages/RMySQL/index.html [ Links ]
Kadlec, J., B. S., D. A., y R. G. (2015). Ecological Informatics. ScienceDirect, 19-28.
Mayelín Mirabal Sosa, M. R. (2010). R: una herramienta poco difundida y muy útil para la investigación clínica. Scielo - Revista Cubana de Investigaciones Biomédicas, 4. Obtenido de http://scielo.sld.cu/scielo.php?script=sci_arttext&pid=S0864-03002010000200012
Mirabal Sosa, M. (30 de abril de 2010). R: una herramienta poco difundida y muy útil para la investigación clínica. Obtenido de http://scielo.sld.cu/scielo.php?script=sci_arttext&pid=S0864-03002010000200012
Piattini Velthuis, M. G., Martines, E. M., Muñoz, C. C., y Sánchez, B. V. (2006). Tecnología t diseño de base de datos. España: RA-MA EDITORIAL. [ Links ]
Ramos, R., Duque, J., y Nieto, S. (2012). Un análisis de las diferencias rurales y urbanas en el rendimiento educativo de los estudiantes colombianos a partir de los microdatos de Pisa. International Conference on Regional Science, 26.
Rexel, K. P., Gearan, P., y Heather, A. (12 de marzo de 2015). Data Science Survey. Obtenido de http://www.rexeranalytics.com/assets/rexer_analytics_2015_data_miner_survey_summary_report.pdf
RStudio. (20 de enero de 2017). RStudio. Obtenido de https://www.rstudio.com [ Links ]
Salazar, R. A. (2 de mayo de 2017). La educación rural un reto educativo. Obtenido de http://www.docentes.unal.edu.co/lgonzalezg/docs/LaEducacionRuralunRetoEducativo.pdf
Team, R. C. (8 de febrero de 2008). R: A Language and Environment for Statistical Computing. [ Links ]
Tecnológica, G. (08 de julio de 2014). Strata+Hadoop. Obtenido de http://www.gacetatecnologica.com/teradata-amplia-la-capacidad-analitica-del-software-libre-r/ [ Links ]
Velasquez, J. D., L. V., y C. Z. (2011). ARNN: Un paquete para la predicción de series de tiempo usando redes neuronales autoregresivas. ResearchGate, 177-181.
Velasquez, J., Montoya, O., y Cataño, N. (2010). ¿Es el proyecto R para la computación estadística apropiado para la inteligencia computacional? Ingeniería y Competitividad, 81-94.
Vilaseca, B. (21 de junio de 2009). La conquista de la vocación profesional. Obtenido de http://borjavilaseca.com/la-conquista-de-la-vocacion-profesional/ [ Links ]
Wickham, H. (24 de junio de 2016). A Grammar of Data Manipulation. Obtenido de https://cran.r-project.org/web/packages/dplyr/dplyr.pdf [ Links ]
Wickham, H., y Francois, T. (13 de febrero de 2017). Package dplyr. Obtenido de https://cran.r-project.org/web/packages/dplyr/dplyr.pdf [ Links ]
Artículo recibido 31/03/2017
Artículo aceptado 18/06/2017
On line: 26/06/2017