











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
1. Introducción
El nomatsigenga es una lengua amazónica-peruana que pertenece a la familia lingüística Arawak y tiene una mayor «cercanía» lingüística con las lenguas asháninka, ashéninka, machiguenga y kakinte de la rama kampa (Shaver, 1996; Talancha 2010; Valqui et al., 2011; Michael, 2011; Lawrence 2014) en comparación a las lenguas iñapari, piro y amuesha. De acuerdo con los datos del III Censo de Comunidades Nativas. Resultados definitivos. Tomo I (Instituto Nacional de Estadística e Informática, 2018), la población nomatsigenga asciende a 3895 habitantes y se encuentra circunscrita, principalmente, a los distritos Mazamari, Pangoa, Río Negro y Río Tambo de la provincia de Satipo, departamento de Junín.
En la mayoría de las investigaciones relevantes que describen las características de la lengua nomatsigenga (Heitzman, 1975; Wise, 1975; Shaver, 1996) no se puede encontrar un énfasis en el análisis sobre variedades lingüísticas a nivel fonético-fonológico, morfológico y léxico. Sin embargo, en aproximaciones más recientes en la lengua, se ha podido encontrar diferencias relevantes en los niveles lingüísticos mencionados, en comunidades como Mazaronquiari y San Emiliano de Cachingarani1.
La lengua nomatsigenga cuenta con 7 vocales (5 breves y 2 largas), 15 consonantes y un archifonema /N/ en su inventario fonológico. En este último punto, las investigaciones realizadas por Lawrence (2014), Apolinario (2020), Castillo (2020) y Talancha (tesis de Maestría por publicar) establecen la presencia de tal archifonema nasal. Se toma la propuesta de este último para mostrar el inventario de fonemas consonánticos y vocálicos, los cuales se presentan en la Tabla 1 y Tabla 2 respectivamente.


En el presente estudio, se pretende realizar una aproximación acústica de las nasales del nomatsigenga con especial atención en la nasal velar /ŋ/, la cual ha pasado por diferentes procesos fonético-fonológicos diacrónicos y sincrónicos para su aparición. Para esto, se inicia con el desarrollo de un breve panorama acústico de los segmentos nasales de la lengua nomatsigenga para, luego, analizar el segmento nasal velar.
La importancia de enfatizar el estudio de esta característica lingüística nomatsigenga radica en que su aparición denota una diferencia sustancial en su estructura silábica respecto a otras lenguas de la misma familia lingüística (Arawak), de allí que constituya una marca de identidad para sus hablantes. Asimismo, el análisis acústico realizado en este artículo permite conocer algunas características específicas que presentan las nasales del nomatsigenga y el rango de hertzios en algunos contextos en los que este segmento se manifiesta.
2. Marco referencial
2.1 Características articulatorias y acústicas de las nasales y definición de antiformante
Respecto a su naturaleza, las consonantes nasales, articulatoriamente, presentan similitudes con las oclusivas, debido a que en ambas hay una obstrucción en la cavidad oral que impide la salida del aire. Sin embargo, el hecho de que el aire salga sin mayor dificultad y de forma continua por la nariz hace que estas se parezcan, también, a las aproximantes (Ladefoged y Maddieson, 1996).
Por otro lado, acústicamente, las consonantes nasales se caracterizan por presentar un primer formante de baja frecuencia llamado «primer formante nasal (Fn1)» (Elías-Ulloa, 2011, p. 137) y que su paso por los conductos orales y nasales provoca un murmullo nasal «efecto creado por una cerrazón oral sostenida mientras el aire sale por la nariz» (Elías-Ulloa, 2011, p. 135), el cual se presenta con menor intensidad que un formante vocálico. Las nasales también se caracterizan por presentar una pérdida de energía acústica conocida como antiformante, la cual puede expresarse de la siguiente forma en el espectrograma según Johnson (2012):
Un antiformante puede o no aparecer como una banda blanca en el espectrograma. Si no hay formantes cerca del antiformante, este aparece como una banda blanca, pero si la frecuencia del antiformante es aproximadamente la misma que la frecuencia del formante, el resultado es el debilitamiento de la intensidad del pico formante. (p. 193)
Los antiformantes se producen cuando participan las cavidades oral y nasal en la articulación de una consonante nasal; mientras que en la cavidad nasal el aire sale libremente, en la cavidad oral la energía se queda atrapada. Por ello, las resonancias de esta cavidad se reflejan de forma que tienen su fase opuesta del mismo componente de frecuencia en la cavidad nasal. En otras palabras, cuando en la cavidad oral una onda es positiva, en la cavidad nasal es negativa y viceversa. De esta forma, cuando estas se suman, se cancelan mutuamente (Jhonson, 2012). Por otro lado, la posición central del primer antiformante es fundamental para caracterizar a las consonantes nasales, puesto que brinda información sobre el punto de articulación de esta clase de sonidos (Martínez y Fernández, 2013). La posición de los antiformantes depende del tamaño de la cavidad resonadora. Por ello, mientras más largo sea el tamaño de la cavidad resonadora, el antiformante se ubicará dentro de un rango de frecuencias bajas. En cambio, si el tamaño de la cavidad resonadora es pequeño, el antiformante se localizará dentro de frecuencias altas (Elías-Ulloa, 2011). Para ubicar la localización de los antiformantes, utilizamos dos tipos de espectros: FFT de banda estrecha, que brinda información sobre el rango de frecuencias en que se ubica el antiformante; y cepstrum, que muestra la localización de los antiformantes.
2.2 Las consonantes nasales del nomatsigenga
Según Maddieson (1984), «las consonantes nasales más recurrentes en las lenguas del mundo son /m/ y /n/ y el resto solo aparecen en menor medida». Esta afirmación concuerda con la presencia de fonemas nasales nomatsigenga /m/, /n/ y /ŋ/, donde los dos primeros aparecen en todas las lenguas que conforman la familia lingüística «kampa» y el último solo aparece en la lengua nomatsigenga (Heitzman, 1975; Talancha, 2010; Michael, 2011 y Lawrence, 2014). Cada uno de los fonemas nasales /m/, /n/ y /ŋ/ tienen correlatos fonéticos [m], [mw], [n], [nj] y [ŋ] que se diferencian por el punto de articulación en el que se realizan. En tal sentido, los casos de los alófonos nasales labializados y palatalizados responden a contextos y rasgos específicos que han permitido su aparición (Vennemann & Ladefoged, 1973). Por ejemplo, el proceso de asimilación denominado «labialización» se presenta en palabras de la lengua nomatsigenga respetando el siguiente contexto: /C[labial][+redondeado]/ + /ɨ/[dorsal] [+posterior] → [Cwɨ]. Para evidenciar este proceso se presentan los siguientes ejemplos: [‘mwɨaneni] ‘a menudo, todos los días’ y [‘pwɨɾo] ‘luciérnaga’ (Talancha, 2010, p. 63-64). Asimismo, este proceso fonético también fue documentado por Valqui et al. (2011), quienes presentaron ejemplos de palabras nomatsigenga que respondían al mismo condicionamiento con nasales labiales y evidenciaban el proceso de labialización. No obstante, es importante no perder de vista la investigación realizada por Rocha (2020) en la lengua shipibo, la cual problematiza si las consonantes labiales condicionan a la vocal central alta /ɨ/ para labializarse o si este proceso de asimilación sucedería de forma inversa, es decir, los rasgos terminales de la vocal central alta /ɨ/ [+alto], [+posterior] y [dorsal] son los rasgos asimilados por las consonantes /m/ y /p/, los cuales provocarían la velarización de ambas labiales: [pɣɨ] y [mɣɨ].
Otro ejemplo es la presencia fonética de la nasal alveolar palatalizada, la cual, para nuestra postura y de acuerdo con las investigaciones fonológicas realizadas por Wise (1975), Heitzman (1975) y Shaver (1996), su aparición se debería a que esta nasal estuvo condicionada por la formación de un grupo fonológico específico que tuvo su origen a nivel diacrónico: */nia/ y */nio/. Entonces, la nasal alveolar palatalizada responde al siguiente contexto para su realización: /N[dorsal]/ + /i/[dorsal] [+alto] + V [dorsal] [+posterior] → [Nj V[+posterior]]. De tal regla (basada en los rasgos del Modelo del Articulador Revisado de Halle, Vaux y Wolfe, 2000), se desprende que la consonante nasal alveolar debe estar seguida de la vocal alta cerrada /i/ y una vocal posterior /a, o/.
Por otro lado, las nasales en posición de coda (que no le prosiguen consonantes velares) tienden a neutralizarse asimilando el punto de articulación de la consonante que le sigue (comportamiento del archifonema N).
En la sección 4.1, se entrará en más detalles sobre los resultados del análisis y de cómo se presentan acústicamente las nasales de la lengua nomatsigenga con especial énfasis en la nasal velar [ŋ]. Esta información buscará sumar en la documentación de la lengua y su articulación con las definiciones conceptuales expuestas en esta sección.
3. Metodología
En un primer momento, para la descripción acústica de los inputs que contenían segmentos nasales velares, se extrajo un corpus general de más de 450 palabras, frases y oraciones, esta información fue extraída del Diccionario Nomatsiguenga-Castellano Castellano-Nomatsiguenga (Shaver, 1996). De este total, se seleccionaron 50 entradas con la presencia de la nasal velar, las cuales tuvieron el registro de 8 colaboradores distintos, haciendo un total de 400 entradas. Este corpus pasó a organizarse de acuerdo con la cantidad silábica de cada palabra y a la posición silábica que ocupaba cada nasal velar. En un segundo momento, se cuidó la selección de los mejores audios WAV de los colaboradores nomatsigenga (recogidos con un grabador digital de audio TASCAM DR-05). En un tercer momento, los mejores registros de se seleccionaron, segmentaron, etiquetaron y se procedió a su análisis acústico con el programa PRAAT (versión 6.1.29). Esto evidenció los correlatos acústicos de los segmentos nasales en sus distintos contextos y posiciones silábicas, además de permitir la organización de los registros de hombres y mujeres de diferentes procedencias de los colaboradores (comunidades de San Antonio de Sonomoro, Jerusalén de Miniaro, Mazaronquiari y Alto Anapati). En un cuarto momento, para mostrar gráficamente la localización de los antiformantes en el análisis espectrográfico y observar las transiciones formánticas de las vocales a fines de sustentar la realización de la palatalización, con el mismo programa se procedió a graficar los espectrogramas y los dos tipos de espectros: FFT (Fast Fourier Transform) de banda estrecha y cepstrum. Estos últimos espectros también se utilizaron en las investigaciones de Martínez y Fernández (2013) y Jiménez (2018) para ubicar, de forma gráfica, los antiformantes de las nasales del castellano y el arabela, respectivamente.
Por otro lado, en esta investigación, se usó un script desarrollado por Rolando Muñoz (2018) para graficar los espectrogramas y textgrids del corpus.
Adicionalmente, para crear los espectros se usó el punto medio del total de duración del segmento nasal, debido a que así se obtiene información más estable del segmento y se soslaya de la influencia de los sonidos adyacentes. Además, para establecer diferencias teórico-metodológicas entre la definición de espectro y espectrograma se consideró las afirmaciones de Martínez (1998, pp. 30-31),
las cuales establecen que los espectros constituyen una representación frecuencial del sonido en un punto determinado de su duración. En cambio, el espectrograma refleja el sonido en su evolución frecuencial a lo largo del tiempo.
4. Análisis y resultados
4.1 Las nasales nomatsigenga [m], [n] y [nj]
En esta sección, se muestran las estructuras acústicas de tres tipos de consonantes nasales acompañados de sus promedios aproximados, en los cuales se ubica el primer antiformante de la nasal labial, alveolar y palatalizada del nomatsigenga ilustrados en la Figura 1.
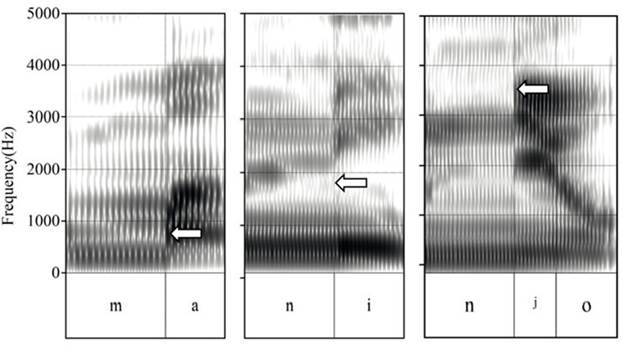
Nota. Se visualizan tres sílabas con presencia de nasales: labial, alveolar y palatalizado [m], [n] y [nʲ], respectivamente. Cada una presenta diferencias en las intensidades de sus frecuencias. Las palabras fueron producidas por hablantes hombres.
Figura 1 Espectrogramas de sílabas con presencia de las nasales [m], [n] y [nʲ]
De la Figura 1, se desprende que el primer antiformante para las consonantes nasales del nomatsigenga se ubica aproximadamente alrededor de los 830 Hz en la nasal labial /m/, entre los 1500 Hz y 1800 Hz en la nasal alveolar /n/ y entre los 3300 y 3600 Hz en la nasal alveolar palatalizada. Estos rangos aproximados también guardan coherencia con lo propuesto por Elías-Ulloa (2011), quien indica 800 Hz [m] y 1100 Hz [n] para el shipibo, y por Jimenez (2018), quien señala 535 Hz [m] y 1 600 Hz [n] para la lengua arabela. Asimismo, tal y como se evidencia en los espectrogramas, a medida que el sonido consonante nasal se produce desde un punto de articulación más exterior (labial) hacia uno más interior (alveolar, palatal y velar) del aparato fonador, el antiformante adquiere frecuencias más altas. Para el caso del sonido nasal velar [ŋ], se realiza una descripción acústica de manera más específica en la siguiente sección.
4.2 Análisis espectral de la consonante nasal velar
En el apartado 2.1, se observó que los espectrogramas de las consonantes nasales del nomatsigenga evidencian una característica propia de todas las lenguas del mundo en la formación de estos segmentos: el antiformante. En el caso particular de la nasal velar nomatsigenga, la ubicación de su primer antiformante se presenta aproximadamente alrededor de los 3670 Hz. Según Martínez y Fernández (2013), la ubicación del primer antiformante del sonido nasal velar del español es de 3370 Hz, el cual estaría dentro del rango de hercios de la nasal velar del nomatsigenga. Adicionalmente, cabe señalar que, tal y como se indicó en la sección 4.1, la aparición del antiformante en las nasales adquieren frecuencias más intensas a medida que su realización se desarrolle en un punto de articulación más al interior del tracto vocálico. Por ejemplo, tal como se muestra en la Figura 2, en la producción de la nasal velar de una colaboradora mujer se observa que el espectro cepstrum que se superpone al espectro FFT de banda estrecha donde el antiformante, según Elías-Ulloa (2011, p. 138), «aparecen como valles de energía […] al contrario de los formantes, los cuales aparecen como picos de energía». En este ejemplo, el antiformante llegó a 3670 Hz.
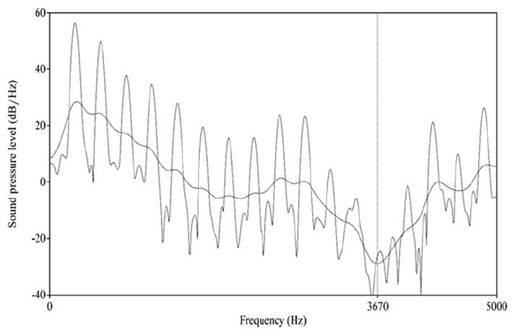
Nota. Se visualiza el antiformante de (3670 Hz.), el cual tiene forma de valle. La palabra fue producida por una hablante mujer.
Figura 2 Espectro FFT de banda estrecha y cepstrum de la consonante nasal [ŋ] en [ijiŋe] ‘nieve’
Una información adicional importante en el análisis acústico de las nasales es que el registro acústico de las mujeres tiende a tener picos más altos de intensidad en hercios en comparación a los hombres, por ello, es posible tener alguna ligera variabilidad en la ubicación del antiformante.
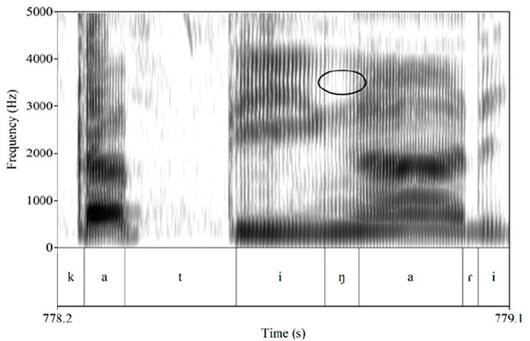
En la Figura 3, se muestra el espectrograma correspondiente a la palabra en la que fue realizada la nasal velar de la Figura 2. En esta, se remarca con un óvalo negro el primer antiformante y su frecuencia en hercios con el objetivo de hacer más explícito «el valle de energía».
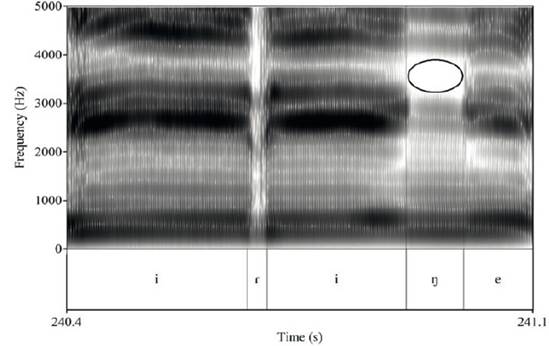
Nota. La figura del círculo señala el «espacio» o «valle de energía» que evidencia la presencia del antiformante en el espectrograma. La palabra fue producida por una hablante mujer.
Figura 3 Espectrograma de la palabra [ijiŋe] ‘nieve’
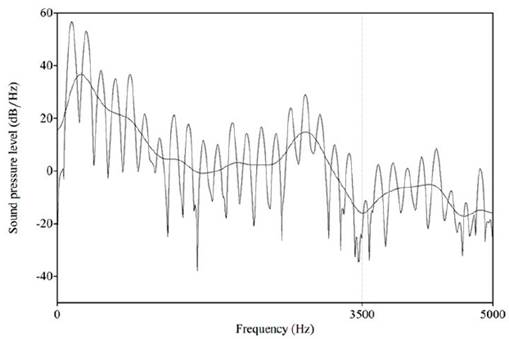
En la Figura 4, se vuelve a presentar el espectro FFT de banda estrecha y cepstrum de la nasal velar correspondiente a la producción de un hablante varón. En este se observa que el antiformante de la consonante nasal velar se ubica alrededor de los 3470 Hz -casi el mismo que en la hablante mujer-. Adicional a ello, se observa un ligero descenso de la frecuencia del antiformante respecto a la Figura 2.
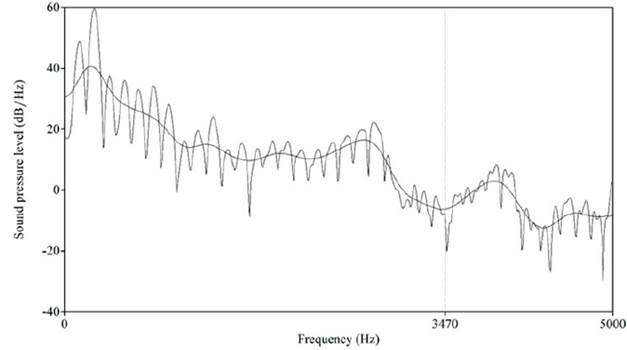
Nota. Se visualiza el antiformante de (3470 Hz.), el cual tiene forma de valle. La palabra fue producida por un hablante varón.
Figura 4 Espectro FFT de banda estrecha y cepstrum de la consonante nasal [ŋ] en [katiŋaɾi] ‘recto/línea’
En la Figura 5, se presenta el espectrograma de la palabra en la que fue producida la nasal de la Figura 4. Además, en esta se remarca con un óvalo el primer antiformante.
4.3 Casos particulares
4.3.1 Nasal velar al inicio de palabra en posición de arranque
La aparición del segmento nasal velar de la lengua nomatsigenga al inicio de palabra y en posición de arranque silábico no ha sido abordada ni considerada en la fonotáctica de la lengua en diferentes investigaciones que se han realizado. Es posible que esto haya sucedido por la falta de evidencia en los corpus presentados o por la poca profundidad en los análisis realizados. En todo caso, cabe precisar que la casuística de este segmento en nomatsigenga es bastante restringida. Las dos palabras que se han podido recoger para este estudio son [ŋotaf̞ant͡fi] ‘cocina (que no tiene propietario)’ y [ŋotomento] ‘cocina (como instrumento)’. De los dos ejemplos mencionados, este estudio solo presentará el espectrograma de la palabra ‘cocina (que no tiene propietario)’ realizada por un hablante varón con la presencia de esta nasal velar al inicio de palabra y en posición de arranque en la Figura 6.

Nota. La flecha blanca dentro del espectrograma señala el inicio del descenso de energía de la nasal velar al encontrarse en posición inicial de palabra. La palabra fue producida por un hablante varón.
Figura 6 Espectrograma de la palabra [ŋotaɣ̞dat͡fi] ‘cocina’
La Figura 6 muestra que la presencia de la nasal velar en posición de arranque no evidencia con claridad su antiformante, pues parece que en esta posición pierde intensidad o energía (como muestra la flecha), por lo cual no llegaría al rango aproximado para este segmento nasal (3640 Hz) que sí pudo evidenciarse en las figuras anteriores. En un análisis de las nasales del español, al inicio de palabra y en posición de arranque, Martínez y Fernández (2013, p. 125) evidenciaron que las vocales que acompañaron a estas nasales experimentaron un marcado descenso en sus transiciones vocálicas del F2 (formante 2), específicamente, en las nasales que se articulan en el interior del tracto vocálico (alveolar, palatal y velar). Sin embargo, en este estudio particular de la nasal velar del nomatsigenga en posición de arranque, se logra ver un inusual movimiento del F4 - mientras que el F2 se mantiene estable-. A pesar de esta primera mirada, sería conveniente seguir profundizando en la investigación de este segmento con un corpus más detallado que permita seguir evidenciando sus características acústicas. Por ello, la evidencia mostrada solo debe servir para documentar su presencia y actualizar la descripción fonotáctica de esta nasal en próximas investigaciones.
4.3.2 Nasal alveolar palatalizada
Otro caso llamativo que se presenta es la nasal alveolar palatalizada [nʲ]. Ahora, de acuerdo con su correlato acústico, la primera gran pérdida de energía o antiformante en la nasal alveolar palatalizada se ubica alrededor de los 3400 Hz para varones y en los 3800 Hz para el caso de mujeres, muy parecido para aquellos segmentos que comprendían a la nasal velar previamente analizada. Debido a su proximidad en sus niveles de frecuencia, resulta ciertamente complejo establecer valores acústicos de intensidad que diferencien las nasales alveolares palatalizadas y nasales (aparición de su antiformante, ver Figura 7). No obstante, las transiciones formánticas dan indicios que permiten evidenciar la elevación de la energía acústica «una parábola» al producir un sonido con rasgo [+alto] que conlleva a una palatalización. Esta afirmación también se sustenta desde la perspectiva articulatoria, ya que la palatalización es la superposición de una elevación de la parte delantera de la lengua hacia una posición similar a la de la [i] en un gesto primario (Ladefoged y Maddieson, 1993).
En la Figura 7, se ha superpuesto el espectro cepstrum al espectro FFT de banda estrecha con la finalidad de observar la posición del primer antiformante en la palabra [monʲo] ‘zancudo’, la cual presenta un valor aproximado en su antiformante de 3500 Hz. Asimismo, estos espectros brindan información sobre el punto de articulación donde se realiza este segmento nasal. Mientras que, en la Figura 8, la elevación del F2 en las nasales alveolares palatalizadas confirma el fenómeno de palatalización, ya que se evidencia un ligero «vacío» al momento de la producción de la nasal alveolar (se muestra un elevación inusual en la transición formántica del F2). Además, en el espectrograma, se observa una transición prolongada ocasionada por la glide [j] que, luego, da lugar al descenso de la transición al iniciar la producción de [o].
Nota. Se visualiza el antiformante de (3500 Hz.) de la nasal velar palatalizada. La palabra fue producida por un hablante varón.
Figura 7 Espectro FFT de banda estrecha y cepstrum de la consonante nasal alveolar palatalizada [n j ] en[mon j o] ‘zancudo’

5. Conclusiones
Una característica acústica distintiva de las nasales de las lenguas del mundo es la presencia de un antiformante. De acuerdo con esa premisa, los antiformantes que se evidenciaron en los alófonos de las nasales del nomatsigenga se ubican de la siguiente manera: el primer antiformante se ubica aproximadamente alrededor de los 830 Hz para la nasal labial, de los 1500 Hz a 1800 Hz en la nasal alveolar y de 3300 a 3600 Hz en la nasal palatalizada.
En cuanto al primer antiformante de la nasal velar, este se ubica aproximadamente en 3670 Hz en mujeres y en 3470 Hz en hombres y sus rangos se encuentran muy próximos a la nasal palatalizada. Asimismo, estos rangos de frecuencias corresponden a que este segmento nasal se ubica dentro de la antepenúltima, penúltima o última posición silábica de palabra.
En el análisis de las nasales alveolares palatalizadas, se pudo evidenciar que el rango aproximado de su antiformante es de 3500 Hz. Un aspecto relevante de su configuración acústica es la elevación en la transición formántica del F2 de la nasal, debido al proceso de palatalización. Otro aspecto llamativo es que los rangos de su antiformante son similares a los rangos de una nasal velar, esto se deba posiblemente al proceso de palatalización, sin embargo, esto último merece un mayor nivel de investigación y discusión.
Por último, un aspecto para seguir reflexionando y profundizando es el análisis acústico de la nasal velar cuando esta se encuentra al inicio de palabra y en posición de arranque silábico, pues su comportamiento acústico (intensidad) no se encuentra dentro de los rangos esperados al compararlo con la nasal velar en otras posiciones silábicas dentro de la palabra. Este supuesto merece ser profundizado en otras investigaciones.

