











 Español (pdf)
Español (pdf)
 Articulo en XML
Articulo en XML Referencias del artículo
Referencias del artículo
 Enviar articulo por email
Enviar articulo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
1. Introducción
El interés de esta investigación se fundamenta en el estudio propuesto por Clifton et al. (2016) citando a Rayner et al. (1986) respecto a tres aspectos que inciden en el reconocimiento y procesamiento léxico: longitud, predictibilidad y ambigüedad léxica. Esto sugiere proponer el estudio del reconocimiento y procesamiento de unidades terminológicas 2 basados en los postulados teóricos de longitud, predictibilidad y ambigüedad léxica. Desde el punto de vista del lenguaje general, las unidades léxicas son influenciadas por estas tres variables durante la lectura. En términos de la variable de la longitud, se plantea que las palabras más largas presentan mayor cantidad de letras, lo cual conlleva a una gran cantidad de información visual y lingüística que debe ser procesada. Asimismo, este trabajo se apoya en la importancia de la perspectiva teórica de la TCT propuesta por Cabré (1999) quien, concibe las Unidades Terminológicas (en adelante UT) como unidades poliédricas que pueden ser analizadas desde una perspectiva cognitiva, lingüística y comunicativa. Del mismo modo, los términos son considerados como unidades léxicas asociadas a un valor especializado dentro de un contexto. Por lo tanto, estas unidades cumplen características específicas en un ámbito de especialidad. También, se fundamenta por la necesidad que sostiene Sharmin et al. (2008) sobre indagar la forma en que los traductores distribuyen la atención visual durante el tratamiento de elementos léxicos.
Los estudios en traducción desde el proceso cognitivo cobran relevancia en la medida que los sujetos traductores requieren tener una mayor conciencia de los procesos subyacentes que ocurren durante la realización de una tarea de traducción, en especial cuando traducen textos especializados. Es el caso, por ejemplo, de la atención visual, un proceso básico que es determinante para el procesamiento de la información y para la traducción de este tipo de textos. El objetivo de este estudio es establecer las variaciones de la distribución de la atención visual en tareas de lectura con Sintagmas Nominales Extensos Especializados (en adelante SNEE) por parte de sujetos traductores. En este sentido, es importante destacar dos aspectos. En primer lugar, la importancia de la lectura en tareas de traducción, pues un proceso de lectura adecuado implica la comprensión del texto origen y la producción de un texto meta que cumpla con las condiciones discursivas en la lengua meta. (Macizo y Bajo, 2006; Alves et al. 2011; AL Sharif, 2017; Winfield et al. 2019). Además, la investigación relacionada con el estudio de la atención visual en tareas de lectura con fines de traducción ha sido un tema de interés en el campo de la traducción y ha permitido identificar la distribución de la atención visual en aspectos léxicos en distintos tipos de textos (Jensen, 2011; Gómez et al. 2019); sin embargo, la distribución visual en las unidades terminológicas durante la lectura de un texto con fines de traducción ha sido poco estudiada en el campo de la traducción.En segundo lugar, el interés por abordar las UTs desde una perspectiva cognitiva y con estudios experimentales que articulen aspectos cognitivos y el procesamiento de UTs, en particular los SNEEs, son todavía escasos, por lo que en esta investigación se analizaron las variaciones de la distribución de la atención visual en SNEEs de 3 y 5 tokens durante una tarea de lectura con fines de traducción.
Para dar cuenta de esta evidencia, en este artículo se muestra mediante un estudio de caso de enfoque positivo con alcance descriptivo las variaciones en la distribución de la atención visual de traductores en formación durante la realización de una tarea de lectura con SNEEs. La recolección de la información se llevó a cabo mediante la técnica de seguimiento ocular y un cuestionario tipo escala Likert. Los resultados de este estudio mostraron que la distribución de la atención visual de los traductores en formación presenta variaciones según la longitud de los SNEEs. Se observó mayor tiempo y número de fijaciones en los SNEEs de 5 tokens en contraste con los SNEEs de 3 tokens. Así mismo, en este artículo se postula que la variable longitud es un factor que afecta la atención visual durante la realización de la tarea de lectura.
2. Marco teórico
Desde el lenguaje general, Rayner, citado por Clifton et al. (2016), plantea que la atención conduce los movimientos oculares y que los cambios atencionales son dirigidos por el alcance del procesamiento lexical. Rayner señala que hay una serie de variables que afectan el procesamiento lexical como la longitud de las palabras. De hecho, entre más larga sea la unidad léxica se representa mayor información lingüística y visual. Sin embargo, el autor afirma que este efecto solo se evidencia en regresiones, pero no en fijaciones sencillas.
De acuerdo con Lupón et al. (2010), uno de los propósitos de la atención es filtrar la información relevante para evitar saturar el sistema cognitivo. Este proceso de filtración implica una distribución visual que está en función del propósito de la tarea e involucra procesos de memoria y aprendizaje. La atención visual y su distribución en tareas de traducción implica que los traductores reconozcan los elementos léxicos y discursivos que requieren de un adecuado procesamiento para cumplir con la producción de un texto meta.
2.1. Sintagmas Nominales Extensos Especializados
Ahora bien, los SNEEs son las UTs que mayor dificultad generan para los traductores en formación y profesionales. Las unidades sintagmáticas son unidades complejas de estructura sintáctica que se clasifican en nominales, adjetivales y adverbiales. Según Cabré (1993), citado por Quiroz (2008, p.55), "la sintagmación se basa desde el punto de vista formal, en la formación de una nueva unidad a partir de una combinación sintáctica jerarquizada de palabras". Así, las nuevas unidades obtenidas respetan las reglas combinatorias del sistema lingüístico al que pertenecen e incluyen muy frecuentemente conectores gramaticales. (p.55)
Quiroz (2008) afirma que los sintagmas nominales pueden ser definidos o indefinidos, de más de 3 tokens (2 premodificadores y un núcleo) y constan de un sustantivo nuclear (núcleo) precedido por diversos elementos (premodificación). Estas unidades que están presentes en los textos especializados pueden generar dificultades para los traductores, en primer lugar, debido a su extensión y complejidad; en segundo lugar, a su reconocimiento en un contexto; en tercer lugar, a su comprensión en el área de especialidad y; finalmente, a la adecuada correspondencia en la lengua meta. De igual forma, Calvache y Suárez (2014) señalan que es muy común encontrar este tipo de unidades de 3 o más tokens en los textos especializados.
2.2. Traducción como actividad cognitiva
La traducción como actividad cognitiva ha sido definida por Hurtado (2007) como una actividad realizada por un sujeto (traductor) y, en ese sentido, se debe considerar el proceso mental que este desarrolla para traducir, así como las capacidades que este necesita para hacerlo adecuadamente. Diferentes estudios en el ámbito de la traducción se han realizado a través de herramientas que permiten indagar sobre el proceso traductor. Instrumentos como el Eye tracker han permitido observar los movimientos oculares de los sujetos para indagar sobre diferentes fenómenos en el ámbito de la traducción. Tal es el caso de la lectura con fines de traducción (Jakobsen y Jensen, 2008; Macizo y Bajo, 2006) y la atención visual (Sharmin et al. 2008; Jensen, 2011). Sin embargo, existen pocos estudios que aborden la terminología desde la distribución de la atención visual durante una tarea de lectura.
De hecho, como plantea Sharmin et al. (2008), existe una necesidad por indagar la distribución de la atención visual tanto en elementos sintácticos y léxicos del texto base como del texto meta. En consecuencia, los estudios en terminología experimental desde el proceso son escasos y requieren una mayor exploración de cómo los traductores profesionales y en formación procesan las UTs y los procesos cognitivos subyacentes en este procesamiento. Para efectos de esta evidencia, la distribución de la atención visual y los SNEEs fueron las variables que se tuvieron en cuenta en el estudio.
3. Metodología
Para este estudio de caso exploratorio, preexperimental y de alcance descriptivo, (Hernández-Sampieri, Fernández, y Baptista, 2006; Susam-Sarajeva, Ş. (2009) se llevaron a cabo dos pasos fundamentales: por un lado, de un corpus de Genoma Humano se seleccionaron diez contextos con una extensión entre 200 y 300 palabras que tuvieran SNEEs de 3 y 5 tokens. El criterio para la extensión de los contextos se basó en lo propuesto por O’brien (2009, p.11), "the reasons for 200-300 words texts are numerous and valid. For example, participants could get tired or bored quickly, leading to a drop in motivation and an effect on the data; or for eye tracking, scrolling down on a screen is problematic and therefore texts are selected so that the source and target can fit on the screen at the same time". El criterio para definir los SNEEs de 3 y 5 tokens se basó en el número de ocurrencia en el interior del corpus. Tal y como afirma Quiroz (2008, p. 129), "los patrones de 3 tokens (dos en la premodificación) son los más frecuentes en la muestra (corpus de análisis) con un 86,16% del total (909 ocurrencias). Por el contrario, los sintagmas de 4 y 5 tokens tan sólo representan un 13,84% del total de sintagmas". Asimismo, se diseñó una tarea de lectura de diez contextos con fines de traducción.
3.1. Participantes
La muestra está conformada por 4 traductores en formación3 que son estudiantes de la maestría en traducción e interpretación de la Universidad Autónoma de Manizales, Colombia, y cuya combinación de lengua para traducción es el inglés-español. En relación con la conformación de la muestra, participaron dos hombres y dos mujeres con edades entre los 20 y los 35 años. La muestra se seleccionó por conveniencia, por lo que se siguieron los postulados de O’brien "Since translation process relies on human participants, one of the challenges is include an adequate number of participants who fit the specific profile we are hoping to investigate in order to enable researchers to make generalizable claims". (O’brien, 2009, p. 5).
3.2. Diseño de la tarea de lectura
El diseño de la tarea de lectura se basa en la propuesta de SNEEs de Quiroz (2008). Los 10 contextos fueron seleccionados del Corpus de Genoma Humano, el cual fue recopilado de The Lancet, revista médica británica, publicada semanalmente por The Lancet Publishing Group 4. De los diez contextos, cinco presentan SNEEs de 3 tokens y 5 contextos SNEEs de 5 tokens. Cada uno de los contextos presenta una extensión entre 80 y 120 palabras.
3.3. Instrumentos
Los instrumentos utilizados para la recolección de la información fueron el eye-tracker y un cuestionario tipo escala Likert.
3.3.1 Eye tracker
El "eye tracker" es un dispositivo de medición de la posición y el movimiento de los ojos. Algunos "eye tracker" modernos utilizan tecnología basada en video para medir el posicionamiento de los ojos, donde una cámara captura la reflexión de la luz infrarroja en la córnea o retina (Duchowski 2017; p. 54).
De igual forma, los datos obtenidos pueden ser analizados estadísticamente y representados gráficamente con el objetivo de dar cuenta de patrones específicos de visualización. Mediante el análisis de variables como las fijaciones, las sacadas y la dilatación de la pupila, los investigadores pueden dar cuenta de diversos fenómenos y, en el caso particular, de procesos cognitivos en tareas de traducción con fenómenos terminológicos específicos. A continuación, se presentan las variaciones de los SNEEs durante una tarea de lectura con fines de traducción (ver Figura 1).

El "Eye-Tracker" utilizado en este estudio es un Eyetribe © de 60 Hz binocular como software. Para la presentación de estímulos y recolección de la información, se utilizó el TIRC® Java script, desarrollado por los grupos CITERM, Neuroaprendizaje y Automática de la Universidad Autónoma de Manizales, Colombia. Asimismo, para realizar el estudio, se utilizó un equipo Lenovo Thinkpad (Intel Core i7-5500U @ 2.4 Ghz, 8GB) y un monitor LG FullHDIPS LED Monitor (22 pulgadas, 60 Hz, 1920 x 1080 pixeles). El ancho del monitor abarca 20-30º del ángulo visual.
En términos del procesamiento del lenguaje, se ha establecido que los movimientos oculares están estrechamente relacionados con el foco de atención actual; por lo tanto, proporcionan información relevante en cuanto al reconocimiento y procesamiento de unidades léxicas en la comprensión de la lectura y la traducción. Las habilidades lingüísticas de los sujetos se evalúan cuando se siguen y registran los movimientos oculares en respuesta a estímulos verbales y visuales predeterminados. Estos son instrumentos bastante útiles para estudios relacionados con la distribución de la atención visual, ya que miden aspectos como las fijaciones, el número de fijaciones y la duración de estas en las tareas antes mencionadas.
3.3.2 Cuestionario
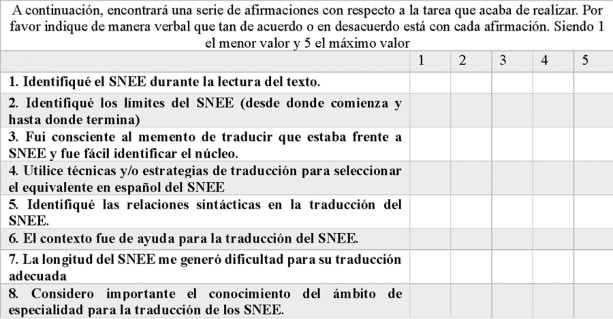
Para contrastar la información del Eye tracker, se diseñó un cuestionario tipo escala Likert de 8 ítems, con opciones de respuesta entre el 1 y el 5: el 5 era la valoración más alta y el 1, la más baja. Tal y como se observa en la Figura 2, las preguntas están relacionadas con aspectos concretos en cuanto al reconocimiento y comprensión de los SNEEs.
3.4. Procedimiento
Para la realización de la prueba, se presentaron los 10 contextos con SNEEs de 3 y 5 tokens en la pantalla del computador. El traductor en formación realiza una lectura con fines de traducción y luego, selecciona la traducción del SNEEs que considera adecuada entre dos posibles versiones. Para efectos de la traducción, el sujeto verbaliza la traducción del SNEE que considera más adecuada, luego, opción 1 u opción 2.
Una vez finalizada la prueba, se les presentó un cuestionario tipo escala Likert en la pantalla del computador con un total de 8 ítems para ser calificados con una puntuación entre 1 y 5, donde 1 correspondía a la puntuación mínima (totalmente en desacuerdo) y 5 a la puntuación máxima (totalmente de acuerdo). Los participantes contestaron en voz alta. Los movimientos oculares de los participantes durante la presentación de los estímulos de traducción fueron registrados con el "EyeTracker. 5
4. Análisis y resultados
El registro de los movimientos oculares permitió la identificación del número de fijaciones y la duración de las fijaciones con el fin de establecer las variaciones en la distribución de la atención visual de los traductores en formación (Clifton et al. (2016).
4.1 Fijaciones oculares
Con relación a la variable de la atención visual, se considera la cantidad y duración de las fijaciones oculares de los traductores durante la realización de una tarea de lectura con SNEEs de 3 y 5 Tokens.
De la información obtenida, se analizan los datos superiores a 250 ms. Según Jensen (2011), es un tiempo significativo para la comprensión.
La Figura 3 corresponde a un ejemplo de las fijaciones oculares registradas con el Eye tracker durante la tarea de lectura con SNEEs de 3 y 5 Tokens. En ambos registros, los círculos corresponden a las fijaciones oculares por parte de los traductores en formación y su tamaño representa la duración de la fijación. Las líneas que unen los círculos muestran la trayectoria de la mirada.

4.2. Tiempo de las fijaciones oculares
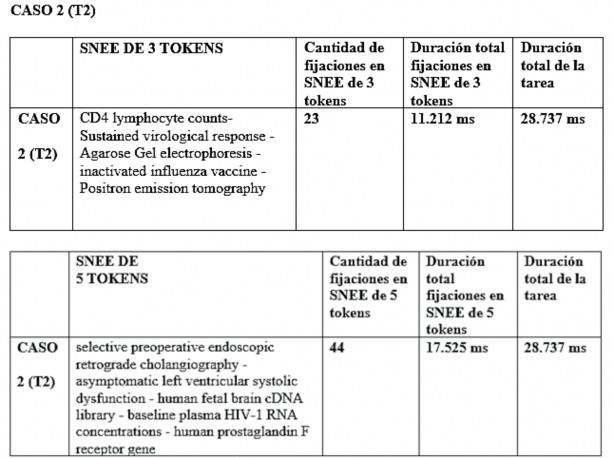
La Figura 4 es un ejemplo del número de fijaciones de cada participante durante la realización de la tarea. En términos generales, se evidencia que los traductores en formación presentaron mayor número de fijaciones y duración durante la tarea de lectura con SNEEs de 5 tokens en contraste con la lectura con SNEEs de 3 tokens.
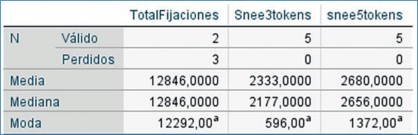
De igual forma, con los datos registrados por el Eye tracker se determina la media, mediana y moda como medidas de tendencia central y como resultado se evidencia en los cuatro participantes una mayor variación de los datos en los SNEEs de 5 tokens en comparación con los SNEEs de 3 tokens, como se ejemplifica en la Figura 5.
Este estudio muestra que los 4 traductores en formación presentan mayores variaciones en la distribución de atención visual durante la lectura de los SNEEs de 5 tokens en contraste con los SNEEs de 3 tokens; asimismo, los sujetos presentan mayor número de fijaciones y duración con los SNEEs de 5 tokens al finalizar la tarea de lectura. Lo señalado coincide con lo planteado por Quiroz (2008), pues entre mayor número de tokens tenga el sintagma, mayor esfuerzo invertido para su comprensión y mayor variación en la distribución de la atención visual.
De igual manera, los resultados de este estudio están en concordancia con lo propuesto por Rayner (1986) con respecto a la variable de la longitud y su incidencia en el reconocimiento de palabras en el lenguaje general. En el lenguaje especializado, según Calvache y Suárez (2014), es común encontrar unidades sintagmáticas extensas de hasta 8 tokens. Esta característica implica precisión y especificidad en un ámbito especializado. No obstante, requiere mayor nivel de comprensión del área por parte del lector. De acuerdo a lo señalado, se concluye que aunque Rayner (1986) planteó sus posturas desde el lenguaje general, este estudio revela que un fenómeno similar se presenta en el lenguaje especializado con los SNEEs.
En cuanto al cuestionario tipo Escala Likert, las respuestas de los participantes varían considerablemente; no obstante, los planteamientos (1,2,3) muestran las dificultades que tienen los traductores en formación en este estudio para la identificación de estas UTs en el lenguaje especializado. Del mismo modo, estos manifestaron estar de acuerdo con el planteamiento 6, pues es importante conocer el ámbito de especialidad para la adecuada identificación y/o posterior traducción de los SNEEs.
5. Discusión
En cuanto a la distribución de la atención visual, según Sharmin et al. (2008), la complejidad del texto requiere mayor número de fijaciones, ya sea por elementos léxicos o por aspectos sintácticos. De igual forma, los autores manifiestan que hay una diferencia significativa en el número de fijaciones en textos complejos a diferencia de textos simples. Aunque en el presente estudio no se hizo énfasis en la complejidad del texto, sí se pudo evidenciar que los SNEEs, unidades con premodificación compleja de 3 tokens o más, afectan el número de fijaciones y duración total por parte de los traductores en formación. Lo señalado coincide con Quiroz (2008), quien afirma que los SNEEs más extensos implican mayor esfuerzo para su comprensión y, según los hallazgos de este estudio, mayores variaciones en la distribución de la atención visual.
Con respecto a los SNEEs, Quiroz (2008) afirma que estas unidades son un problema de traducción debido a los premodificadores y a su extensión, que dificulta su comprensión. En un proceso de traducción, se hace necesario que los traductores desarrollen cada vez más sus competencias en la combinación de las lenguas de trabajo. Los niveles de experticia permitirán a los traductores evitar inconsistencias en la re-expresión del texto meta (Terry Sáenz, 2021). De igual forma, Weffer et al. (2014) plantea que la longitud del SNEE complejiza el procesamiento de las correspondencias y genera dificultad en el momento de identificar las relaciones de dependencia sintáctica. Lo señalado se evidencia en los resultados, puesto que la distribución de la atención visual presenta variaciones en los SNEEs de 5 tokens en comparación con los SNEEs de 3 tokens. Así, los traductores en formación realizaron mayor número de fijaciones y tiempo en los SNEEs de 5 tokens.
Además, Cartagena (1998), citado por Quiroz (2008), manifiesta que la estructura sintáctica del término presenta una relación directa entre longitud, grado de especialización y estabilidad; es decir, a mayor longitud, mayor especialización e inestabilidad. Así, los SNEEs de 5 tokens presentan mayor dificultad para los traductores en formación, lo cual se evidencia en el número de fijaciones y tiempo invertido en la tarea. Los resultados coinciden con Juhazs et al. (2008), quien afirma que la variable longitud afecta el tiempo que invierte el lector durante el reconocimiento de una palabra.
El presente artículo permite destacar la importancia que tiene estudiar la distribución de la atención visual con otras UTs. Este estudio permite la comprensión y la elaboración de estrategias en la resolución de problemas con el fin de mejorar la re-expresión del texto meta.
6. Conclusiones
Los resultados sugieren que la longitud de los SNEEs juega un rol importante en tareas de lectura con fines de traducción. Lo señalado se evidencia en las variaciones de la distribución visual de los cuatro traductores en formación por el número de fijaciones y duración de las mismas.
En relación con la cantidad de fijaciones oculares en los SNEEs de 3 y 5 tokens, se observó que la distribución de la atención presenta mayores variaciones durante la realización de la tarea de lectura con SNEEs de 5 tokens, ya que los traductores en formación tuvieron mayor número y tiempo de fijaciones. Esto sugiere que los SNEEs de 5 tokens implican un mayor esfuerzo para su comprensión y, por ende, es más compleja la selección de la correspondencia adecuada. Respecto a la distribución de la atención visual entre SNEEs de 3 y 5 tokens, se evidencia que esta se ve afectada a causa de la variable longitud. Los SNEEs de 5 tokens presentaron mayor número y tiempo de fijaciones en contraste con los SNEEs de 3 tokens. A partir de lo señalado, se concluye que entre más extenso sea el SNEE, mayores dificultades genera su reconocimiento y, por lo tanto, la atención visual es mayor.
Este estudio permite establecer variaciones en la atención visual por parte de los traductores en formación durante una tarea de lectura con fines de traducción y con SNEEs de 3 y 5 tokens. Además, se concluye que el tiempo de fijaciones oculares invertido por los traductores en formación durante la tarea de lectura con SNEEs refleja la complejidad de este tipo de UTs y el esfuerzo para su comprensión. Los resultados de este estudio sugieren que los traductores en formación necesitan conocer la estructura lingüística y conceptual de este tipo de UTs para lograr una correspondencia adecuada con la lengua y la cultura meta.

