









 Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink
1. Introducción
Las cuestiones relacionadas con la eponimia constituyen uno de los debates recurrentes en el ámbito de la biomedicina1. Partidarios y detractores apoyan sus opciones en argumentos de diversa naturaleza. A esta situación, se añade que, si bien el uso de epónimos es controvertido en una misma lengua, en el ámbito de la traducción los problemas que genera dicho procedimiento se multiplican.
Esta situación ha llevado a indagar sobre qué sucede realmente con la eponimia en los textos actuales y qué estrategias se utilizan para su traducción: ¿siguen siendo frecuentes los epónimos?, ¿en qué medida?, ¿cuáles?, ¿cómo se clasifican? o, por ejemplo, ¿qué estrategias se utilizan para su traducción?
Para dar respuesta a este tipo de cuestiones, en este trabajo se analiza la presencia de epónimos en un corpus paralelo2 compuesto por fichas técnicas y prospectos sobre medicamentos huérfanos. Este corpus es trilingüe e incluye el inglés, el francés y el español. El inglés se seleccionó por ser la lengua en que están originalmente redactados los textos que componen el corpus y de la que proceden una parte importante de los epónimos. El francés y el español, por su parte, se seleccionaron por considerar que era necesario profundizar en la descripción de la eponimia biomédica empleada en ellas. Se trata, además, de un corpus caracterizado tanto por la actualidad sociosanitaria del subdominio médico focalizado -por su vinculación con las enfermedades raras (ER)-, como por la reciente fecha de las muestras textuales (publicadas entre 2016 y 2021).
El objetivo es realizar un estudio que, teniendo en cuenta los diferentes enfoques y propuestas existentes, permita analizar de un modo sistemático los epónimos presentes en el corpus compilado. Esto permitirá obtener conclusiones basadas en datos reales. En primer lugar, se presentan de manera sintética las características de la eponimia y se ofrece una visión del estado de la cuestión. En segundo lugar, se describe la metodología (corpus, herramientas de análisis, etc.). En tercer lugar, se recogen los resultados del análisis y las conclusiones obtenidas.
2. Marco teórico
La eponimia es un procedimiento clásico para la creación de unidades léxicas de naturaleza denominativa. Consiste en recurrir a un nombre propio, patronímico o topónimo (Rouleau, 2011) para la formación de nuevos términos. Si bien es utilizado de manera general en la ciencia3, su uso es especialmente productivo en los ámbitos de la historia natural, la física, las matemáticas y la medicina (Chukwu, 1996). En este último ámbito, que es en el que se centra nuestro trabajo, se emplea especialmente en la denominación de enfermedades, síntomas, estructuras anatómicas, técnicas quirúrgicas, pruebas o, por ejemplo, tratamientos. A pesar de tratarse de un procedimiento ampliamente utilizado tradicionalmente, en la actualidad es fuente de controversia y polémica.
2.1. Origen del uso de epónimos
Entre las diversas causas que pueden explicar el recurso a la eponimia en textos biomédicos destaca su carácter sintético y el permitir una fácil memorización frente a sinónimos constituidos por largas denominaciones de naturaleza descriptiva (Chukwu, 1996). A continuación, en la Tabla 1, se presentan distintos ejemplos que ilustran con claridad este aspecto, y que proceden de los diccionarios médicos que se recogen en la bibliografía:
Tabla 1 Epónimos frente a sus denominaciones descriptivas
| Epónimo | Denominación descriptiva |
|---|---|
| Hodgkin lymphoma (en) | malignant lymphogranulomatosis |
| lymphome de Hodgkin (fr) | lymphogranulomatose maligne |
| linfoma de Hodgkin (es) | linfogranulomatosis maligna |
| Pott’s disease (en) | spinal tuberculosis |
| mal de Pott (fr) | ostéoarthrite vertébrale tuberculeuse/tuberculose vertébrale |
| mal de Pott (es) | tuberculosis vertebral |
| Moschcowitz’ syndrome (en) | thrombotic thrombocytopenic purpura |
| syndrome de Moschcowitz (fr) | purpura thrombotique thrombocytopénique |
| síndrome de Moschcowitz (es) | púrpura trombocitopénica trombótica |
Junto a esta ventaja semántica (Ezpeleta, 2013) que, en nuestra opinión, es el argumento de mayor interés, los partidarios del uso de la eponimia defienden este recurso esgrimiendo asimismo otros criterios. Argumentan el respeto de la tradición, el formar parte del lenguaje que se ha estudiado, el aportar una perspectiva histórica (Araujo, 2016) o el carácter unívoco de la eponimia que facilita "la comprensión de muchos términos sin necesidad de explicar su concepto" (Aleixandre-Benavent et al., 2015, p. 168)4.
Si bien "la noción de epónimo se sustenta en un criterio extralingüístico" (García Gallarín, 2019, p. 39), no todos ellos tienen la misma procedencia. Siguiendo, fundamentalmente, a AleixandreBenavent et al. (2015) y a Kucharz (2017, 2020), se pueden indicar algunos aspectos importantes, que a continuación se detallan.
La mayor parte de ellos proceden de nombres de médicos/as o científicos/as (y, con menos frecuencia, también de enfermeras/os) que describieron por primera vez enfermedades5, crearon dispositivos, pruebas o procedimientos. Por ejemplo, trompa de Fallopio (Fallopian tuve/trompe de Fallope) procede -de acuerdo con el Diccionario de términos médicos (en adelante, DTM) de la Real Academia Nacional de Medicina de España (2012)- del anatomista italiano, discípulo de Vesalio, que las describió. Otro grupo importante procede de nombres de entidades geográficas: es el caso de denominaciones toponímicas como fiebre de Malta (Malta fever/fièvre de Malte) por el lugar en el que falleció el soldado en el que se aisló la bacteria que produce la enfermedad (Álvarez-Hernández et al., 2015, s. p.).
Junto a estos dos orígenes principales, existen, asimismo, otras fuentes para la eponimia:
a. Personajes literarios: como sucede con el síndrome de Pickwick (Pickwick’s syndrome/syndrome de Pickwick) cuyo nombre proviene de la novela de Charles Dickens The posthumous papers of the Pickwick Club (1837), uno de cuyos personajes secundarios, Joe, supuestamente padecía este síndrome (DTM). En algunos casos proceden de obras muy populares como el síndrome de Alicia en el país de las maravillas (Alice in wonderland Syndrome/síndrome d’Alice au pays des merveilles).
b. Origen histórico o mitológico: es el caso del tendón de Aquiles (Achilles tendón/tendón d’Achille) o con atlas (atlas/atlas). Este último hace referencia a la vértebra cervical primera, que sostiene la cabeza y cuyo nombre procede del "titán Atlas, condenado por Zeus a sostener eternamente la bóveda celeste sobre sus hombros" (DTM).
c. Pacientes en los que se describió la enfermedad por primera vez: como factor (de) Hageman (Hageman’s factor/facteur Hageman).
d. Seudónimos: así sucede en prueba de la t de Student (Student’s t test/test de Student). Como señalan Aleixandre-Benavent et al. (2015, p. 165), "Student era el seudónimo por el que era conocido el empollón y matemático británico William Sealy Gosset (1876-1937)", que publicó la mayor parte de sus trabajos con este nombre.
e. Animales6: ese el caso de la facies leonina (leonine facies/faciès léonin) característica de los estados avanzados de la lepra y cuya denominación se deriva "del cierto aspecto leonino que confiere a los rasgos faciales la hipertrofia por infiltración nodular del tejido subcutáneo de la cara" (DTM).
2.2. Tipos de epónimos
En relación con la tipología de epónimos Van Hoof (1986, 1998, 1999, 2001) -que es uno de los autores que más ha estudiado este fenómeno en el ámbito que nos ocupa- establece dos tipos principales atendiendo a que hayan sido o no lexicalizados7 y, dentro de ellos, varios subtipos.
Se han sistematizado estas propuestas en la siguiente tabla (Tabla 2) en la que se incluyen algunos ejemplos en inglés, francés y español. Estos, seleccionados de entre los que propone Van Hoof (1986, 1998, 1999, 2001), se han comprobado en los diccionarios médicos que se citan en la bibliografía:

Como se puede apreciar en la Tabla 3, que figura a continuación, en los epónimos del primer grupo se ha llevado a cabo una recategorización del nombre propio. Por su parte, los epónimos del segundo grupo son sintagmas en los que siempre figura como determinante un nombre propio (Martín Camacho, 2021). Se diferencian dos subtipos dentro de ellos en función del número de elementos que los integran:

El orden de los nombres propios en este grupo de epónimos compuestos no está establecido: "puede ser por el prestigio individual de los componentes, por la antigüedad, o incluso por cierto grado de intimidación" (Aleixandre-Benavent et al., 2015, p. 165). Si se tiene en cuenta que, en el mundo actual, la investigación no es un trabajo individual, sino en equipo porque son necesarios perfiles investigadores diversos, tanto este orden de los nombres propios como la misma asignación de un epónimo pueden generar conflictos importantes que, a veces, perduran en el tiempo (Chukwu, 1996).
2.3. Problemas de la eponimia
La eponimia no se rige por reglas fijas por lo que genera, junto al que se acaba de apuntar, otros muchos problemas. Uno de ellos es la coexistencia en una misma lengua de varias denominaciones para una misma enfermedad (polisemia). Rouleau (2003, p. 147) señala, por ejemplo, que el syndrome de Claude Bernard-Horner se recoge en los diccionarios en francés también como syndrome de Horner, de Michel o de Huctchinson.
Asimismo, el uso de un mismo antropónimo para denominar diferentes enfermedades (homonimia) puede generar confusiones. Sournia (1974, p. 20) indica que, en los diccionarios en lengua francesa figuran siete syndromes de Fanconi, tres de Franceschetti, tres maladies de Marfan o dos de Recklighausen. Esta polisemia "dificulta la precisión deseable para el lenguaje científico" (Gutiérrez Rodilla, 1998, p. 116).
Por último, existen casos en que se emplean diferentes denominaciones no relacionadas históricamente para un mismo referente (sinonimia). Esto sucede con "síndrome de Adams-Stokes (<Robert Adams y William Stokes), conocido también como síndrome de Stokes-Adams, enfermedad de Morgagni (<Giovanni Battista Morgagni), síndrome de Adams-Stokes-Morgagni y síndrome de Morgagni-Adams-Stokes" (Alcaraz Ariza, 2002, p. 65).
Junto a estos problemas, los detractores del uso de epónimos, señalan, además, otros argumentos en contra de este recurso (Puerta López-Cózar y Mauri Más, 1994; Alcaraz Ariza, 2002; Ezpeleta, 2013; Aleixandre-Benavent, 2015; Araujo, 2016; Yale et al., 2020; Kucharz, 2020)8: falta de precisión y transparencia por su carácter no descriptivo ni base etimológica; falta de exactitud histórica; excesivo culto a la personalidad; o, por ejemplo, existencia de más de un epónimo para un mismo concepto.
De manera específica Alcaraz Ariza (2002) explica el rechazo de los terminólogos debido a que:
por una parte, se inscriben en un proceso de denominación diferente de la perspectiva onomasiológica adoptada por la terminología moderna, escapando, por tanto, a la lógica propia de los demás signos lingüísticos y, por otra, no poseen la sistematicidad y transparencia propia de los formantes grecolatinos, que constituyen la fuente primaria de la cual se alimenta la terminología médica. (pp. 56-57)
Si la eponimia presenta problemas dentro de una lengua, cuando se analiza en el ámbito de la traducción, estos aumentan dado que "in the matter of translation they obey no rules at all" (Van Hoof, 1998, p. 58). En principio, como señala Rouleau (2011), podría parecer que la presencia de un nombre propio debería simplificar el trabajo del traductor como sucede en casos como los que se presentan en la Tabla 4:

Sin embargo, esto no siempre es así, ya que los epónimos pueden no ser iguales en diferentes lenguas. Se caracterizan por la "ausencia de paradigmas formales coherentes" (Esteban Arrea, 2012, p. 50), por carecer de equivalencia internacional (Araujo, 2016) y por ser imprevisibles (Alcaraz Ariza, 2002). Básicamente, existen dos posibilidades (Soubrier, 1998) que se ilustran en las tablas 5 y 6 con ejemplos procedentes de los diccionarios médicos consultados.
Por un lado, aquellos casos en que existen epónimos diferentes (totalmente o en parte) para una misma enfermedad en distintas lenguas, en ocasiones por atribuirse su descripción a diversos médicos, o debido a procesos de simplificación. A continuación, en la Tabla 5 se presentan algunos ejemplos:

Por otro lado, aquellos casos en que en una o varias lenguas se emplean epónimos, mientras que en otra(s) no, como los que recogen en la Tabla 6:

Los problemas de traducción no son exclusivos de estos epónimos en los que se ha mantenido el nombre propio; también están presentes en la traducción de los epónimos lexicalizados. El pormenorizado estudio de Van Hoof (2001) para la traducción del inglés al francés ofrece datos sobre este aspecto en relación con: sustantivos (por ej., la existencia de varias formas posibles en francés, frente a una en inglés), verbos (por ej., la fácil formación de verbos en inglés añadiendo un sufijo - como -ize-, muy poco frecuente en francés) y adjetivos (por ej., cambio de categoría gramatical en francés).
Se originan, de este modo, problemas de comprensión de los que se derivan interpretaciones erróneas en las traducciones.
Para finalizar este apartado, debe indicarse que el uso de epónimos, como las lenguas, varía a lo largo del tiempo. Esto hace que existan epónimos muy utilizados en algún momento que, en la actualidad, están en desuso. Por otra parte, hay que tener en cuenta que "eponym usage also reflects changes in cultural norms" (He et al., 2022, s. p.). Por ejemplo, en la actualidad, por razones éticas, hay iniciativas para eliminar aquellos epónimos de médicos vinculados con el nazismo.
3. Metodología
El corpus empleado se compiló en 2019 con el objetivo de ampliar el número de corpus disponibles en el portal de recursos lingüísticos RERCOR. La finalidad de este portal es proporcionar herramientas multilingües que permitan conocer mejor los usos lingüísticos propios del subdominio médico de las enfermedades raras (ER), que son aquellas que afectan a menos de 5 personas de cada 10 000 en la Unión Europea. Por lo tanto, el corpus se centra en las ER y, de manera específica, en los medicamentos huérfanos. Es decir, "fármacos que no son desarrollados por la industria farmacéutica por razones económicas pero que responden a necesidades de salud públicas" (Orphanet, 2022, párr. 5). Estos medicamentos se desarrollan para el amplio grupo de ER existente (más de 7000) que, si bien son enfermedades de baja prevalencia individual, en conjunto afectan a más de 300 millones de personas en el mundo (FEDER, 2022).
Se trata de un ámbito de especial actualidad, en gran medida gracias a la implicación activa de las asociaciones de pacientes, que buscan visibilizar las ER para que constituyan una prioridad de la salud pública. En efecto, asociaciones como EURORDIS-Rare Diseases Europe, Alliance Maladies Rares o FEDER (Federación Española de Enfermedades Raras), por mencionar solo algunas del ámbito europeo, son las principales responsables de que el conocimiento sobre las ER se haya difundido tanto que hoy en día resulte difícil no haber oído hablar de ellas.
En relación con las fases de compilación y tratamiento de las muestras textuales de ORPHACOR (Sánchez Trigo y Varela Vila, en prensa), se han seguido los criterios propuestos por los especialistas más reconocidos (EAGLES, 1996; Laviosa, 2002; McEnery, 2003; Sinclair, 2004; o Tognini-Bonelli, 2010) y se ha prestado especial atención a las cuestiones relativas a calidad y representatividad (Bowker y Pearson, 2002; Berber Sardinha, 2002; o Walsh, 2013). Frente a una primera versión inicial, en estos momentos el corpus se ha ampliado y está constituido por un total de 4 391 283 palabras con la siguiente distribución en función de lenguas y géneros. En la Tabla 7 se describen sus características:
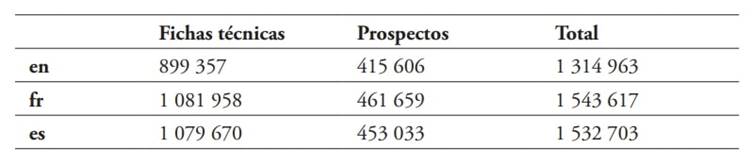
En total se incluyen 840 muestras textuales: 140 fichas técnicas y 140 prospectos de medicamentos por lengua. Estos textos forman parte del informe público europeo de evaluación (EPAR, siglas de la denominación en inglés European Public Assessment Report), una serie de documentos que la Agencia Europea de Medicamentos (EMA) publica tras conceder o denegar la autorización de comercialización de un nuevo medicamento humano o veterinario.
Las fichas técnicas son textos especializados dirigidos a médicos y profesionales sanitarios. Se trata de un género textual que "recoge información y recomendaciones para permitir a los profesionales sanitarios extender una receta del medicamento y facilitar recomendaciones a los pacientes en relación con su uso" (Agencia Europea de Medicamentos y Comisión Europea, 2019, p. 27). Por su parte, el prospecto, de carácter semiespecializado, "contiene recomendaciones clave para los pacientes sobre cómo utilizar debidamente el medicamento" (Agencia Europea de Medicamentos y Comisión Europea, 2019, p. 29).
ORPHACOR es un corpus de textos paralelos con una alineación oracional en XML realizada de modo semiautomático con el editor InterText (Vondřička, 2016). Para el etiquetado y la lematización se utilizó, por su adecuación y buenos resultados, Freeling 4.1, un etiquetador de código abierto desarrollado por el Centro de Tecnologías y Aplicaciones del Lenguaje y el Habla (TALP) de la Universitat Politècnica de Catalunya (UPC). El tratamiento del corpus y su integración en nuestro portal de recursos lingüísticos multilingües sobre enfermedades raras, RERCOR (Sánchez Trigo y Varela Vila, 2019), ha permitido que, en su explotación, se apliquen diversos parámetros disponibles en las múltiples funcionalidades del portal. Algunos de ellos se explican en el siguiente apartado.
3.1. Explotación del corpus
Con el fin de poder estudiar los diferentes epónimos presentes en el corpus ORPHACOR se llevó a cabo un vaciado terminológico semiautomático, mediante el cual se obtuvo un listado de candidatos a término que, posteriormente, se analizó de forma manual. El objeto de este análisis fue confirmar la naturaleza terminológica y eponímica de los candidatos obtenidos. Una vez que se determinó cuáles eran epónimos, se establecieron correspondencias entre ellos en las tres lenguas de trabajo y se clasificaron a fin de estudiarlos de una forma sistemática.
Para la extracción de candidatos a término se emplearon principalmente técnicas morfosintácticas. Es decir, se estableció previamente cuál era la estructura morfosintáctica más habitual de los epónimos en cada lengua y se buscó en el corpus con el fin de obtener candidatos a término que se correspondiesen con dichos patrones. Esto fue posible gracias a la lematización y al etiquetado morfosintáctico del corpus, así como a las distintas posibilidades de consulta que ofrece el portal RERCOR.
El patrón de partida utilizado tanto en francés como en español fue N. + Prep. de + N. propio, mientras que en inglés se partió de dos patrones diferentes: N. propio + N. y N. propio + genitivo + N. Estas estructuras se utilizaron para realizar las primeras búsquedas en RERCOR y, además de extraer candidatos a término, determinar otros patrones que podrían ayudar en la extracción terminológica. En la Figura 1 se muestra un ejemplo de búsqueda:
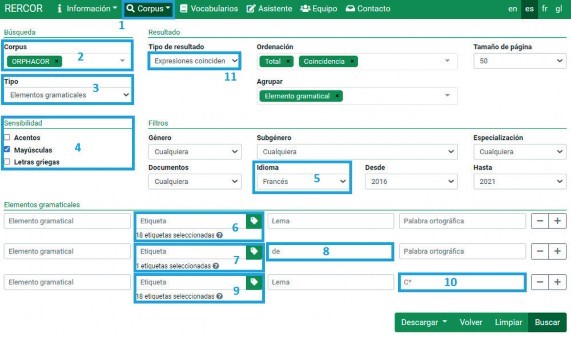
En la Figura 1 se muestra un ejemplo de búsqueda por patrón sintáctico en francés. Como se puede observar, el objetivo de esta consulta fue localizar las estructuras formadas por los tres elementos gramaticales indicados (N. + Prep. de + N. propio), pero para este último se ha indicado que debe comenzar la letra c en mayúsculas.
A continuación se presenta de forma detallada el modo en que se procedió a hacer esta consulta en RERCOR para que pueda reproducirse o que sirva de modelo para otras posibles búsquedas utilizando las funcionalidades del portal. Si bien el caso que se muestra es para el francés, podría hacerse igualmente en español, al coincidir el patrón en ambas lenguas.
En primer lugar, en la pestaña Corpus (1), se seleccionó la opción Búsqueda avanzada. Después, en la sección Búsqueda, se indicó el corpus sobre el que realizamos el análisis (ORPHACOR) en el campo Corpus (2) y la opción de búsqueda por elemento gramatical en el campo Tipo (3). Además, en la sección Sensibilidad (4) se marcó la opción Mayúsculas y, en la sección Filtros, se escogió como idioma el francés (5).
En segundo lugar, en la sección Elementos gramaticales, se introdujeron los tres elementos gramaticales que antes indicamos formaban la estructura que nos interesaba consultar (N. + Prep. De + N. que empiece por c mayúscula). Para ello, en el primer caso se escogió la etiqueta "sustantivo" en el desplegable correspondiente (6). En el segundo, la etiqueta preposición (7) y, en el campo Lema, se introdujo la preposición de (8). Para el tercer elemento se seleccionó la etiqueta "sustantivo" (9) y se introdujo C* en el campo Palabra ortográfica (10); de este modo se localiza cualquier palabra que comience por c mayúscula, pues el asterisco es un comodín que sustituye a uno o más caracteres.
Por último, en el campo Tipo de resultado (sección Resultado) se escogió la opción Expresiones coincidentes (11), que proporciona los resultados agrupados por frecuencia y con especificación del número de ocurrencias totales, el número de ocurrencias por millón y el número total de documentos en que figuran las coincidencias.
De este modo, en esta búsqueda se obtuvieron los siguientes resultados (no se muestran el número de ocurrencias por millón ni el número total de documentos) que se recogen en la Tabla 8:

Un análisis pormenorizado de estos resultados permite ver que solo una parte de ellos son epónimos. Un número considerable de las estructuras no eponímicas localizadas incluyen como tercer elemento gramatical una sigla (como greffe/allogreffe de CSH, sigla de cellules souches hématopoïétiques) o el nombre comercial de un medicamento (como administration/utilisation/dose/solution/flacon de Cayston).
Una vez descartadas estas, fue necesario estudiar cada una de las estructuras eponímicas identificadas con el fin de comprobar si existían variantes tanto ortográficas como léxicas. Por ejemplo, la formule de Cockcroft-Gault se denomina también estimation de Cockcroft-Gault. Asimismo, aparece recogida en el corpus como équation de Cockcroft Gault, sin guion para separar los apellidos. La sigla correspondiente a estos apellidos es C-G, y en el corpus figuran las formas formule de C-G y formule C-G.
En otros casos, un estudio más detallado permitió identificar variantes morfosintácticas. Por ejemplo, es posible que la estructura N. + Prep. de + N. forme parte de una estructura terminológica mayor, como sucede con la forma régression de Cox, que constituye solo una parte del término modèle de régression de Cox (también denominado, como puede verse en la tabla anterior, modèle de Cox). Esto ha llevado a determinar que N. + Prep. de + N. + Prep. de + N. propio puede emplearse también para producir epónimos tanto en francés como en español. Por lo tanto, se estudiaron las secuencias que se correspondían con esta estructura en el corpus para localizar epónimos.
Un ejemplo similar se observa en el candidato a término B de Child-Pugh que, tras una consulta más precisa en RERCOR, se identificó que forma parte del término classe B de Child-Pugh, que hace referencia a uno de los grados de la clasificación de Child-Pugh para establecer la gravedad de la enfermedad hepática.
En otras ocasiones, la forma localizada puede constituir una unidad terminológica (por ejemplo, maladie de Castleman), pero al consultarla en el corpus se observa que existe un término más específico (maladie de Castleman multicentrique) en el que se añade un adjetivo al final (N. + Prep. de + N. + Adj.)
Del mismo modo, es posible que la estructura básica en español y francés se vea alterada por la introducción de un adjetivo tras el primer nombre, como en el caso de los términos distrofia muscular de Duchenne/dystrophie musculaire de Duchenne, prueba estadística de Cochran-Mantel-Haenszel/test statistique de Cochran-Mantel-Haenszel.
Por otro lado, hemos comprobado que una parte considerable de los epónimos están compuestos por varios nombres propios (habitualmente, apellidos) unidos por guion. RERCOR localiza estos epónimos utilizando la estructura comentada al inicio (N. + Prep. de + N.), por lo que no es necesario realizar ninguna búsqueda específica para su extracción. Sin embargo, en ocasiones no se emplea el guion para unir los diferentes apellidos, por lo que es necesario realizar de forma independiente la búsqueda de la construcción N. + Prep. de + N. propio + N. propio. Esta estructura también permite extraer aquellos epónimos constituidos por un nombre y un apellido, si bien son mucho menos habituales.
En lo que respecta al inglés, las estructuras más frecuentes en la construcción de epónimos son N. propio + N. (como Kupffer cell) y N. propio + genitivo sajón + N. (como Richter’s transformation). Tal y como sucedía en francés y español, estas estructuras básicas pueden sufrir ligeras variaciones con la adición, normalmente, de sustantivos o adjetivos, como sucede con Epworth Sleepiness Scale y con Fisher’s exact test, pero también de la conjunción and para vincular nombres propios, como sucede en modified Valent and Cheson criteria.
A continuación se presentan en la Tabla 9, a modo de resumen, los patrones más frecuentes en las tres lenguas con sus correspondencias, si bien un mismo epónimo puede adoptar estructuras diferentes en las distintas lenguas:

La extracción de epónimos del corpus ORPHACOR, por lo tanto, conllevó un trabajo laborioso. Fue necesario revisar numerosas listas de candidatos a término y realizar búsquedas complementarias tanto para aclarar la naturaleza eponímica de los términos como para determinar su estructura completa.
Por otro lado, para que la extracción terminológica fuese exhaustiva, se consideró más adecuado realizarla en las tres lenguas, en lugar de llevarla a cabo solo en inglés y comprobar los equivalentes en francés y español. La consulta de los distintos segmentos en que se empleaban epónimos y de los segmentos equivalentes nos permitió localizar tanto variantes como otras denominaciones no eponímicas que se emplean como sinónimas, que también se registraron.
Este artículo, por limitaciones de espacio, se centra en los epónimos no lexicalizados, pues la extracción de epónimos lexicalizados, mucho menos frecuentes, requiere estrategias diferentes, como el establecimiento de los sufijos más habituales para su formación (p. ej., -ismo en español, -ism en inglés e -isme en francés; -niano en español, -nian en inglés y -nien en francés; -ino/a en español, e -ine en inglés y francés, etc.). No obstante, se registraron aquellos términos lexicalizados que se localizaron durante el proceso de extracción y que son sinónimos o equivalentes de un epónimo no lexicalizado.
Una vez finalizada la extracción de todos los epónimos, se establecieron las equivalencias entre los términos, tarea que resultó mucho más fácil gracias a la naturaleza paralela del corpus ORPHACOR, y se clasificaron en función de su significado. En el siguiente apartado se presenta una muestra significativa de los resultados obtenidos. Los resultados completos se publicarán próximamente en forma de glosario en RERCOR.
4. Resultados y discusión
El estudio realizado ha permitido identificar 141 conceptos que se denominaban en alguna de las tres lenguas mediante epónimos, con la siguiente distribución que se presenta en la Tabla 10:

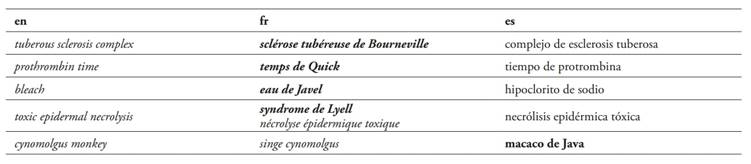
Como se puede observar, no todos los conceptos localizados se denominan mediante epónimos en las tres lenguas, sino que existen ligeras variaciones. Concretamente, en francés se utilizan epónimos para hacer referencia a tres conceptos más que en inglés y español. A continuación, en la Tabla 11, se muestran aquellos conceptos (y sus correspondientes términos) en que el corpus no recoge un epónimo equivalente:
En cuanto a los 136 conceptos restantes, para su denominación se utiliza al menos un epónimo en cada una de las lenguas. En la mayor parte de los casos, no existe una equivalencia exacta, sino que en los distintos textos se combinan los términos eponímicos con los no eponímicos y las diferentes variantes (ortográficas, sintácticas, abreviaturas…). En la siguiente Tabla 12 se muestran el número de variantes existentes en cada lengua:
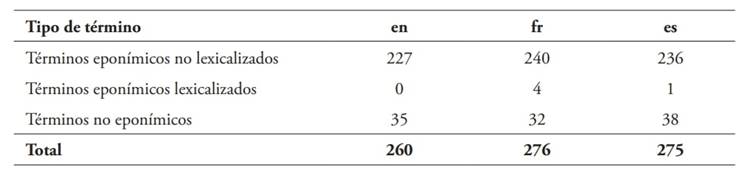
En general, el número de términos utilizados para denominar los 142 conceptos identificados es muy similar en las tres lenguas. En francés se han identificado más epónimos lexicalizados y no lexicalizados (dentro de los cuales se incluyen las siglas, pero también las diferentes variantes ortográficas), mientras que es la lengua en que se emplea un menor número de términos no eponímicos. La media de denominaciones eponímicas (lexicalizadas y no lexicalizadas) por concepto es prácticamente similar en las tres lenguas (1,6 en inglés, 1,72 en francés y 1,67 en español).
4.1. Clasificación temática
Los conceptos identificados se clasificaron en función de su significado, como puede observarse a continuación en la Tabla 13:

A continuación se describe de forma breve cada uno de los grupos establecidos:
a. Métodos e instrumentos de valoración
Se trata de escalas, criterios, estadios, cuestionarios, etc. que se utilizan para valorar una determinada situación. Estos términos suelen figurar en el apartado de Propiedades farmacodinámicas de las fichas técnicas que figuran en el corpus, especialmente cuando se describen los ensayos clínicos realizados con el fármaco para establecer su seguridad y eficacia. Por ejemplo, en la ficha técnica de Gazyvaro se describe un ensayo clínico y se indica en qué fase de la leucemia linfática crónica se encontraban los participantes al comienzo de acuerdo con los estadios de Binet.
b. Enfermedades
En la gran mayoría de los casos, estos epónimos utilizan como base el sustantivo enfermedad (maladie en francés y disease en inglés), como es el caso de la enfermedad de Castleman/maladie de Castleman/Castleman’s disease. Asimismo, en algunas ocasiones, estas enfermedades presentan subtipos que se denominan con el mismo epónimo pero añadiendo un adjetivo (como enfermedad de Castleman multicéntrica) o indicando el tipo (como enfermedad de Gaucher de tipo 1, enfermedad de Gaucher de tipo 2…). Sin embargo, aproximadamente un tercio de los epónimos referidos a enfermedades utilizan términos diferentes en su composición, como linfoma de Burkitt/lymphome de Burkitt/Burkitt lymphoma o carcinoma de células de Merkel/ carcinome à cellules de Merkel/Merkel cell carcinoma.
c. Síndromes
Todos los epónimos pertenecientes a este grupo utilizan como base el término síndrome o sus equivalentes, excepto el epónimo transformación de Richter/transformation de Richter/Richter’s transformation. Este término, que resulta muy opaco debido a la utilización de un componente tan general como trasformación, hace referencia, de acuerdo con el Dictionnaire de l’Académie nationale de médecine (Académie Nationale de Médecine, 2021) -en adelante, DANM-, a una "Transformation histologique d’une leucémie lymphoïde chronique ou d’un lymphome lymphocytique en un lymphome à grandes cellules B (ou en une maladie de Hodgkin)" (DANM, 2021a).
d. Métodos estadísticos
Incluye todos aquellos términos utilizados para denominar métodos con base estadística como fórmulas, índices, estimadores, pruebas, modelo. En este tipo de textos suelen utilizarse, al igual que los instrumentos de valoración, en el apartado Propiedades farmacodinámicas. Su mención se debe a la necesidad de explicar de forma minuciosa cómo se obtuvieron los datos que avalan, entre otros aspectos, la seguridad y eficacia del tratamiento investigado. Entre estos términos encontramos, por ejemplo, estimación de Mantel-Haenszel/estimation de Mantel-Haenszel/Mantel-Haenszel estimate o método de Brookmeyer y Crowley/méthode de Brookmeyer et Crowley/Brookmeyer and Crowley’s method. También en el apartado de Posología se usan habitualmente términos incluidos en este grupo, como fórmula de Dubois/formule de Dubois/Dubois formula, epónimo empleado para designar un método de estimación del área de superficie corporal a partir del peso y la estatura.
e. Componentes del cuerpo humano
Engloba aquellos términos referidos al cuerpo humano en sus diferentes niveles (atómico, molecular, celular y anatómico), como la tirosina quinasa de Bruton/tyrosine kinase de Bruton/ Bruton’s tyrosine kinase o la célula de Hürthle/cellule de Hürthle/Hürthle cell.
f. Pruebas analíticas y exploraciones complementarias
Incluye todos aquellos términos relativos a análisis, como la prueba de Coombs/test de Coombs/ Coombs test, que detecta "la presencia de autoanticuerpos no aglutinantes en la superficie de los eritrocitos" (DTM, 2012a), o a exploraciones complementarias que facilitan la obtención de datos para confirmar un diagnóstico. Este es el caso de la estesiometría de Cochet-Bonnet/ esthésiomètre de Cochet-Bonnet/Cochet-Bonnet aesthesiometry, que mide la sensibilidad corneal.
g. Virus y bacterias
Como el virus de Epstein-Barr/virus d’Epstein-Barr/Epstein-Barr virus o el bacilo de Calmette y Guérin/bacille de Calmette et Guérin/Bacillus Calmette-Guérin.
h. Sustancias químicas y terapéuticas
Se incluyen en este grupo un producto de uso común en la práctica clínica, como es la solución de Ringer con lactato/Ringer lactate/Lactated Ringer’s; el hipoclorito de sodio, cuyo nombre común en francés es eau de Javel, y que se utiliza para desinfectar zonas que hayan estado en contacto con organismos genéticamente modificados; y, por último, la hierba de San Juan/ herbe de Saint-Jean/St. John’s wort (Hypericum perforatum), una planta medicinal que en francés, a pesar de la existencia del epónimo, suele denominarse millepertuis (3 ocurrencias de herbe de Saint-Jean en un solo prospecto frente a 97 ocurrencias en 61 documentos [30 prospectos y 31 fichas técnicas] de millepertuis).
i. Técnicas de laboratorio
Forman parte de este grupo la prueba de Ames/test d’Ames/Ames test, mediante la cual es posible "determinar la mutagenicidad de compuestos químicos" (DTM), y el medio de Eagle modificado por Dulbecco/milieu de culture de Eagle modifié par Dulbecco/Dulbecco’s Modified Eagle’s Medium, que es un medio de cultivo, esto es, una "Preparación sólida o líquida que se utiliza para detectar, aislar, identificar o aumentar el crecimiento de células tisulares vivas o de microorganismos" (DTM, 2012a). Se trata de un tipo especial de epónimo compuesto por dos apellidos, pero no de personas que colaboraron en sus investigaciones o identificaron la misma realidad, sino que la primera es la creadora del medio original (medio basal de Eagle) y la segunda, Dulbecco, modificó este medio para poder cultivar células de mamífero.
j. Animales
En este apartado se incluye únicamente el término macaco de Java. Su nombre científico es Macaca fascicularis, pero este no se usa en el corpus. En francés e inglés, el corpus recoge las denominaciones singe cynomolgus/cynomolgus monkey, respectivamente. Este epónimo es llamativo, por un lado, porque solamente se usa en español y, por otro, porque está compuesto por el topónimo Java, pues uno de los lugares del sudeste asiático del que son originarios estos animales es la isla de Java.
4.2. Clasificación en función del tipo de nombre propio
Si bien la mayoría de los epónimos están constituidos por apellidos de médicos/as y científicos/as, como ya se ha mencionado, se han detectado casos que merecen la pena destacarlos. Estos se resumen en la siguiente Tabla 14:

A continuación, se aportan algunos datos sobre los términos recogidos en la Tabla 14.
El grupo Entidad geográfica lo constituyen los epónimos en que se emplea un topónimo para su construcción, como el cromosoma Filadelfia, ciudad en la que se encuentran los centros de investigación a los que pertenecían los dos científicos que describieron este fenómeno en 1960 (DTM ). Se trata de un caso especial de epónimo, porque el nombre propio varía en función de la lengua (se usa Philadelphia en inglés y sus exónimos correspondientes, Philadelphie y Filadelfia, en francés y español). Otro ejemplo es el virus de Coxsackie, que incluye el nombre de la localidad de Nueva York en que se aisló por primera vez este virus (Libro rojo). Las dos ocurrencias de este término en el subcorpus en inglés constan del topónimo Coxsackie escrito en minúsculas, lo que deja entrever la tendencia que tienen estas denominaciones a confundirse con nombres comunes y a lexicalizarse. Entre los términos formados por topónimos figuran asimismo los estadios de Ann Arbor, una clasificación empleada para la estadificar el linfoma de Hodgkin que se adoptó en la conferencia celebrada en la ciudad estadounidense de Ann Arbor en 1971 (Figueroa-Bohórquez et al., 2022).
Por otro lado, si bien no es frecuente, algunos epónimos están conformados por un nombre de pila que se usa solo o acompañado del apellido. Este es el caso de la ley de Hy, descubierta por Hyman Zimmerman, un gran estudioso de la hepatotoxicidad inducida por fármacos. Si bien suele utilizarse solo su nombre de pila abreviado, en el corpus se recoge también el uso del epónimo règle de Hy Zimmerman en francés. Otro ejemplo similar es el del síndrome de Gilles de la Tourette/syndrome de Gilles de la Tourette (también denominado síndrome de Tourette/syndrome de Tourette). En este caso, el uso del nombre de pila solo se registra en francés y español, pues en el subcorpus inglés solo figuran las formas Tourette’s syndrome y Tourette syndrome.
Asimismo, se han encontrado dos ejemplos del uso de iniciales para componer epónimos. El primero de ellos es un virus que se denomina por medio de las iniciales del primer paciente en que se aisló por primera vez en el año 1971. También figuran en el corpus las formas virus de John Cunningham/virus John Cunningham/John Cunningham virus, si bien la forma abreviada es más común. En efecto, las formas virus JC/JC virus figuran en el DTM, en el DANM y en el Stedman’s (Wolters Kluwer Health, 2022), pero no las formas extendidas. En el caso del término síndrome de nevus B-K, las iniciales B y K se corresponden con las primeras familias en que se inició la investigación y la descripción de este nevus.
Por último, se han localizado dos epónimos formados por nombres provenientes de la mitología griega, como son Aiolos (Αἴολος) e Ikaros (Ἴκαρος), que dan nombre a dos genes y a sus correspondientes proteínas.
4.3. Estructura morfosintáctica
Otro de los aspectos que se deben destacar en relación con los epónimos localizados en el corpus es su estructura morfosintáctica. Los resultados obtenidos hacen necesario establecer una distinción entre la estructura de los epónimos en inglés y la de los epónimos en francés y español.
En cuanto al inglés, estos pueden formarse de los tres siguientes modos. En primer lugar, debemos destacar aquellos constituidos por un genitivo sintético con ‘s. Un total de 46 de los epónimos localizados en inglés utilizan este tipo de genitivo para formarse, como Bazett’s correction o Friedreich’s ataxia. Esta estructura no se emplea si el epónimo está compuesto por dos nombres propios unidos por guion, pero sí figura en el corpus un ejemplo en que dos nombres propios están unidos por la preposición and y el último de ellos lleva la marca de genitivo: Brookmeyer and Crowley’s method. En consecuencia, el genitivo sajón sigue utilizándose a pesar de que, como señala Kucharz (2020, p.), "currently, non-possessive style is recommended, e.g. the term Cushing disease is preferred to Cushing’s disease".
Otra parte de los epónimos en inglés está formada por un nombre propio sin marca de genitivo. Se trata de la estructura más habitual, pues en el corpus se encuentran 144 epónimos diferentes sin marca de genitivo, como Kupffer cell o Lambert-Eaton myasthenic syndrome. Asimismo, existen 7 casos de epónimos que se emplean con y sin marca de genitivo en función de los textos (por ejemplo, Ewing’s sarcoma/Ewing sarcoma o Tourette’s syndrome/Tourette syndrome). Por otro lado, como se mencionaba antes, esta es la estructura habitual si el epónimo está compuesto por dos o más nombres unidos por guion, como es el caso de Clopper-Pearson method o de Zollinger-Ellison syndrome. Si bien puede parecer que se trata de la omisión de la marca de genitivo, Dirckx (2001) considera que, en estos epónimos, el genitivo se sustituye por un adjetivo de idéntica forma que el correspondiente nombre.
Por último, el genitivo analítico con of es la forma menos común de formar epónimos en inglés y, de hecho, en el corpus solo se encontró un epónimo que se correspondiese con esa estructura: islets of Langerhans.
En la siguiente Tabla 15 se muestran ejemplos de las estructuras morfosintácticas más frecuentes en inglés:

En cuanto a los epónimos en francés y español, en su mayoría están compuestos por un nombre común, la preposición de y el nombre propio, si bien la adición de otros componentes da lugar a otras estructuras comunes. A continuación, en la Tabla 16, se recogen algunos ejemplos:
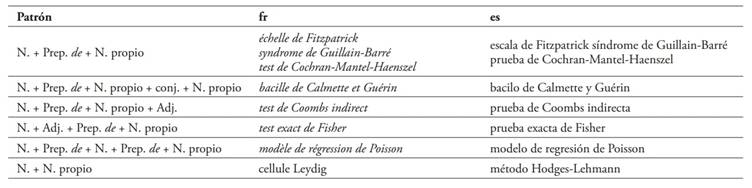
Esta última estructura es, no obstante, incorrecta, ya que debería llevar la preposición de para unir los dos nombres. No obstante, en algunos casos, como el del término cromosoma Filadelfia mencionado anteriormente, su uso sin preposición se ha impuesto en la práctica.
A pesar de que la estructura de los epónimos en francés y español es similar, no siempre un mismo término consta de la misma estructura, como es el caso de test de Boschloo unilateral/prueba unilateral de Boschloo o de score de performance de Karnofsky/puntuación funcional de Karnofsky.
Además, un mismo concepto suele denominarse con diversos términos con estructuras más o menos fijadas en cada una de las tres lenguas. Un ejemplo de ello se muestra en la siguiente Tabla 17:
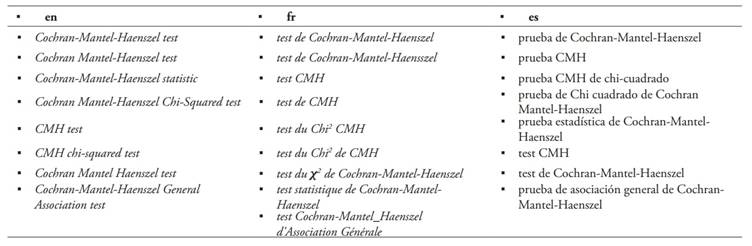
Entre las variantes se incluye una que contiene una errata (Haensszel en lugar de Haenszel) y varias con un uso incorrecto de los guiones (Cochran-Mantel_Haenszel o Cochran Mantel Haenszel en lugar de Cochran-Mantel-Haenszel). Se trata de errores habituales en la escritura de los epónimos que se mencionarán en el siguiente apartado.
Si bien este artículo se centra en los epónimos no lexicalizados, en el proceso de extracción terminológica se han identificado ciertos epónimos lexicalizados relativos a algunos de los conceptos estudiados en este trabajo que se presentan en la Tabla 18:

Como se puede observar, figura una ocurrencia de Hodgkinien en mayúsculas, lo que deja entrever que, a pesar de la lexicalización, existe una tendencia a mantener las mayúsculas del nombre propio a pesar de su lexicalización.
Por último, es importante mencionar el gran número de siglas utilizadas para abreviar los diferentes términos eponímicos tal y como se recoge en la Tabla 19.

De acuerdo con la Tabla 19, el porcentaje de siglas por término eponímico es bastante similar en las tres lenguas, si bien ligeramente superior en inglés. Por otro lado, aunque la mayoría de las siglas usadas en español y francés son creadas ad hoc para los correspondientes términos en estas lenguas (EG1 para enfermedad de Gaucher de tipo 1 y MG1 para maladie de Gaucher de type 1 o SMLE para síndrome miasténico de Lambert-Eaton/syndrome myasthénique de Lambert-Eaton), este no siempre es el caso. Por ejemplo, tanto el francés como el español usan la sigla inglesa BTK (de Bruton’s tyrosine kinase) para hacer referencia a la tirosina kinasa de Bruton/tyrosine kinase de Bruton. Existe una tendencia bastante marcada del francés a utilizar la sigla inglesa o, a alternar su uso con la sigla en francés, como sucede con las siglas SLG/LGS, usadas para hacer referencia al syndrome de LennoxGastaut (en inglés, Lennox-Gastaut syndrome).
4.4. Aspectos ortográficos
Existen distintos aspectos relativos a la ortografía de los epónimos que deben tenerse en cuenta al estudiarlos. En primer lugar, que los epónimos constituidos por más de un nombre propio deben ir coordinados por medio de guiones, como recomienda Orphanet en su Manual de procedimientos de la nomenclatura de enfermedades raras en español (2008). En el corpus ORPHACOR figuran un gran número de epónimos constituidos por varios nombres propios por guion en las tres lenguas, aunque en ocasiones se omiten erróneamente, como demuestran ejemplos como método de Kaplan Meier en español, syndrome de McCune Albright en francés o Cockcroft Gault equation en inglés.
Otro aspecto relevante, que también recoge Orphanet (2008) en su manual, es la importancia de mantener los signos diacríticos del idioma original. No obstante, en ocasiones no es fácil incluirlos, o bien porque se desconoce cómo hacerlo, o bien porque el sistema de entrada o la fuente utilizada no soporta alguno de los caracteres necesarios. En ORPHACOR se localizaron términos que incluyen diéresis, como macroglobulinemia de Waldenström (del sueco) o célula de Hürthle (del alemán); o acentos, como síndrome de Sézary (del francés). En otros casos, como en el término célula de Purkinje, el apellido original, en checo, es Purkyně, pero en la práctica se ha impuesto la forma germanizada (DTM).
Sin embargo, en muchas ocasiones la dificultad no reside en usar correctamente los signos diacríticos del original, sino simplemente en transcribir de forma correcta un apellido extranjero. En efecto, en el corpus se identificaron diferentes errores ortográficos de este tipo, como síndrome de Beradinelli-Seip (omisión de una r en Berardinelli); test de Cochran-Mantel-Haensszel (adición de una s en Haenszel); o Mc Nemar test (adición de un espacio en McNemar).
En otras ocasiones, la confusión se genera al creer erróneamente que la s del genitivo forma parte del nombre, por lo que se escribe incorrectamente, como en el caso de Cushings disease (en inglés) o procédure de Holms (en francés).
4.5. Comparación interlingüística
En general, se puede afirmar que el uso que se hace de los epónimos en el corpus ORPHACOR es bastante similar en las tres lenguas. Siguiendo la propuesta de Soubrier (1998), a continuación, se lleva a cabo una comparación interlingüística con el fin de entender mejor las ligeras diferencias que se pueden apreciar.
En primer lugar, se han localizado epónimos idénticos en los que el nombre genérico es diferente. Por ejemplo, el uso de modelo de Fridericia/formule de Fridericia/Fridericia method en un mismo texto, a pesar de que existen las tres variantes en las tres lenguas. Se han identificado asimismo casos en que se emplean epónimos idénticos, pero a los que se les añade una precisión en cualquiera de las lenguas, como enfermedad ósea de Paget/Paget’s disease of bone/maladie de Paget. En realidad, no se trata de una adición sino de la omisión del tipo de enfermedad en el epónimo en francés.
Otro grupo lo componen epónimos que son diferentes en alguna de las lenguas, ya sea total o parcialmente: test de Wilcoxon/test de Wilcoxon-Mann-Whitney en francés frente a prueba de Wilcoxon y Wilcoxon test en español e inglés; o enfermedad de Graves-Basedow como sinónimo en español de enfermedad de Basedow, frente a maladie de Basedow y Basedow’s disease en francés e inglés.
Por último, existen casos en que no existe epónimo en una de las lenguas. Como ya se ha mencionado en la Tabla 11, se recogen 5 casos como el uso de sclérose tubéreuse de Bourneville en francés frente a tuberous sclerosis complex y complejo de esclerosis tuberosa en inglés y español.
Sin embargo, no se ha encontrado ningún ejemplo de epónimos compuestos idénticos pero con cambio de orden ni de la existencia de epónimos diferentes en una misma lengua o en varias.
Por otro lado, se han localizado 33 términos no eponímicos en inglés y francés, y 37 en español, como mucopolisacaridosis tipo IVA, que es sinónimo de síndrome de Morquio A, LD généralisée acquise, que es sinónimo de syndrome de Lawrence; o congenital factor IX deficiency/haemophilia B/hemophilia B, todos ellos sinónimos de Christmas syndrome. En muchos casos, aparecen en los textos junto a los epónimos para aclarar su significado en la primera aparición. En otras ocasiones, se presenta una explicación de naturaleza no terminológica acompañada del epónimo, como en el siguiente ejemplo:
erupciones cutáneas graves en forma de manchas rojas hasta violeta (síndrome de Sweet) o erupción con descamación de la piel y llagas bucales (síndrome de StevensJohnson)
severe skin rashes such as red to purple bumps (Sweet’s syndrome) or rash with skin peeling and mouth sores (Stevens-Johnson syndrome)
éruption cutanée grave pouvant se traduire par l’apparition de petites papules rouges à violettes (syndrome de Sweet) ou éruption cutanée avec desquamation de la peau et ulcères buccaux (syndrome de Stevens-Johnson)
Es importante señalar, como se muestra en la Tabla 20, que dos de los apellidos que conforman los epónimos recogidos se utilizan para crear epónimos diferentes:

En el primer caso, pese a que se usa el mismo apellido para formar epónimos diferentes, la confusión es menos probable, ya que se trata de realidades distintas: el puntaje de Wilson es un cálculo estadístico desarrollado por Edwin B. Wilson en 1927, mientras que la enfermedad de Wilson, descrita por Samuel A. K. Wilson en 1912, es un trastorno hereditario poco frecuente que causa la acumulación de cobre en el organismo. Sin embargo, la denominación enfermedad de Wilson puede hacer referencia, asimismo, como recoge el DTM, a la eritrodermia exfoliativa, una afección inflamatoria cutánea que fue descrita por William J. E. Wilson. Si bien en las ocurrencias recogidas en el corpus no existe riesgo de confusión, ya que el contexto cercano indica que se trata de una enfermedad relacionada con el metabolismo del cobre, sí puede generar confusión en otro tipo de contexto más escueto.
En cuanto al segundo ejemplo, el apellido utilizado para la formación de ambos epónimos pertenece a la misma persona, el pediatra suizo Guido Fanconi, que describió la anemia de Fanconi en 1927 y el síndrome de Fanconi en 1936. Este último se conoce asimismo como síndrome de Toni-Debré-Fanconi, pues en realidad fue descrito en primer lugar por el pediatra italiano Giovanni de Toni en 1933 y en segundo lugar por el pediatra francés Robert Debré en 1934 (Navarro, 2022. En adelante, Libro rojo).
Por otro lado, existen otras denominaciones que figuran en el corpus ORPHACOR y que por su estructura podrían confundirse con epónimos, pero que no lo son. Es el caso de cuestionario de Quick, donde Quick no es un apellido sino la sigla de Quality of Life in Children with Vernal Keratoconjuntivitis (calidad de vida en niños con queratoconjuntivitis vernal). Para evitar esta confusión, debería haberse escrito con todas las letras en mayúsculas. Un caso similar es el de la enfermedad tipo Bulky, un calco del inglés bulky disease, que hace referencia a una neoplasia maligna o cáncer con gran masa tumoral (Libro rojo). Por último, hemos localizado también el término insuficiencia de lactasa de Lapp, donde Lapp proviene del gentilicio inglés lapón/a, y que debería denominarse en español alactasia lapona o alactasia de los lapones, de acuerdo con el Libro rojo.
5. Conclusiones
En este artículo se ha realizado un estudio de la eponimia presente en un corpus paralelo trilingüe compuesto por prospectos y fichas técnicas sobre medicamentos huérfanos. Los datos obtenidos han permitido comprobar que los epónimos constituyen un recurso muy utilizado en la actualidad en los textos biomédicos, por lo que "las afirmaciones de que el fenómeno eponímico es pasajero y está en vías de abandono progresivo […] no concuerdan con su trayectoria real" (Alcaraz Ariza, 2002, p. 71). Las razones de su uso extendido son, como se ha apuntado, de diversa naturaleza y parecen tener un mayor peso que sus desventajas. Como señala Bouché (1994), "les habitudes ont la vie dure, et l’éponyme est parfois plus commode, plus facile, plus amusant à utiliser, ou vous donne un air de grande érudition" (p. 279).
El estudio realizado se ha basado en un corpus paralelo en inglés, francés y español, lo que ha permitido comprobar, además, que el uso de los epónimos no varía significativamente entre estas lenguas. Probablemente, el hecho de que existan pocas diferencias interlingüísticas se deba, en parte, a que los textos en francés y español son traducciones de los documentos en inglés, por lo que esta última lengua ejerce cierta influencia sobre la terminología de los textos traducidos.
Por otro lado, los datos obtenidos han permitido comprobar que, como se esperaba, una parte considerable de los epónimos se refieren a enfermedades y síndromes, por lo que utilizan estos dos términos en su formación (como síndrome de Sweet/síndrome de Sweet/Sweet’s syndrome o enfermedad de Christmas/maladie de Christmas/Christmas disease). Sin embargo, es muy destacable asimismo el número de construcciones eponímicas utilizadas para dar nombre a métodos e instrumentos de valoración, métodos estadísticos o partes del cuerpo humano.
Por último, el hecho de que el corpus analizado, ORPHACOR, esté integrado dentro del portal RERCOR ha permitido emplear todas las funcionalidades de que dispone este portal, que han simplificado en gran medida el proceso de análisis y extracción terminológica. Como se ha indicado, los resultados completos de este estudio se publicarán próximamente en forma de glosario en RERCOR.
Tanto este trabajo como el glosario final suponen un paso más en la descripción de los usos lingüísticos propios del campo de la biomedicina. Se trata de un conocimiento indispensable para que los traductores y otros usuarios del lenguaje biomédico, como los médicos, tomen las decisiones más adecuadas con el fin de redactar textos de especialidad con mayor precisión.