









 texto em
texto em  Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
PermalinkINTRODUCCIÓN
El nuevo coronavirus (coronavirus 2 del síndrome respiratorio agudo severo-SARS) fue reportado en el mes de diciembre de 2019 en la ciudad de Wuhan-China, con la aparición de varios casos de neumonía de etiología desconocida que causó problemas respiratorios agudos severos1-7. Este se transmite por inhalación de gotitas respiratorias, contacto cercano con el individuo infectado, y contacto con superficies u objetos contaminados1,8.
El 11 de marzo de 2020 la Organización Mundial de la Salud (OMS) declaro al COVID-19 como una pandemia9. Los casos se incrementan a nivel mundial, incluido el Perú, donde el primer caso se anunció el 6 de marzo; siendo al 12 de julio, el número total de casos confirmados, de 326 32610.
Existe una gran preocupación de la capacidad de respuesta del sistema de salud peruano para afrontar efectivamente a las necesidades de las personas con COVID-19 ya que el número de casos se incrementa y a pesar de todas las medidas dadas por el gobierno, este no se detiene; más aún que el gobierno “abrió las puertas" a la población a una “nueva normalidad”.
Los modelos matemáticos son usados para entender las transiciones epidemiológicas críticas11-14, y en los últimos meses, los investigadores han venido empleando métodos matemáticos para poder pronosticar el número de casos de COVID-19 en todo el mundo. El Método Autorregresivo Integrado de Medias Móviles (ARIMA) es el que más se ha utilizado para realizar pronósticos, tal es el caso de los propuestos por Singh RK et al11, para Estados Unidos, España, Italia, Francia, Alemania, el Reino Unido, Turquía, Irán, China, Rusia, Brasil, Canadá, Bélgica, los Países Bajos y Suiza; por Ceylan Z15, para Italia, España y Francia; por Moftakhar L y Seif M1, para Irán; por Benvenuto D et al16, para Italia; por Yousaf M et al17, para Pakistán; por Hiteshi Tandon18y Rishabh Tyagi et al19, para India y por Perone G20, para Italia.
Las series temporales constituyen colecciones de datos en un período de tiempo en los cuales se observan las tendencias o patrones para pronosticar algunos valores futuros21. El modelo ARIMA cuenta con tres principales parámetros; el parámetro p: asociado a la parte autorregresiva (AR); el cual es el número de diferencias que hay que tomar a la serie para que sea estacionaria; el parámetro d: asociado a la parte integrada (I) y; el parámetro q: asociado a la parte de media móvil (MA); el cual es el valor actual de una serie, que se define como una combinación lineal de errores pasados11,12,18.
Para estimar un modelo ARIMA se utiliza la metodología de Box-Jenkins11,22-23, la cual consta de 4 etapas: la identificación: que consiste en identificar el modelo que tentativamente se puede considerar; la estimación: que consiste en estimar los parámetros del modelo considerado tentativamente; la validación: que consiste en realizar contrastes de diagnóstico para comprobar si el modelo se ajusta a los datos y; la predicción: que consiste en obtener pronósticos en términos probabilísticos de los valores futuros y en la cual se evalúa la capacidad predictiva del modelo24.
Una de las preocupaciones en el Perú y en cualquier otro país, es saber cuántas personas se infectarán con COVID-19 en el tiempo; y esta se podría responder con modelos predictivos25; por lo tanto, el presente estudio tuvo como objetivo, estimar un modelo Autorregresivo Integrado de Medias Móviles (ARIMA) para el análisis de series de casos de COVID-19, en Perú, con el fin de buscar una aproximación entre los resultados obtenidos con el modelo y los datos observados.
MÉTODOS
Diseño y área de estudio
El presente estudio se basó en un análisis de series temporales univariante, descriptivo, transversal, retrospectivo, realizado en Perú, con la cantidad de casos nuevos diarios confirmados de COVID-19, entre el 06 de marzo y 11 de junio del 2020.
Población y muestra
Los datos utilizados se refieren a la cantidad total de casos nuevos diarios confirmados de COVID-19 entre el 06 de marzo y 11 de junio del 2020.
Variables e instrumentos
Los datos provienen de la Sala Situacional COVID 19-Peru, del Instituto Nacional de Salud y Centro Nacional de Epidemiologia, Prevención y Control de Enfermedades del Ministerio de Salud10; los cuales sirven para obtener la precisión del pronóstico de la propagación del COVID-19.
Procedimientos
Los datos sirvieron para obtener los pronósticos del número de casos de los siguientes 30 días, desde del 12 de junio hasta el 11 de julio de 2020, creando una trayectoria proyectada de estos casos, para posteriormente compararlos con los casos observados en el periodo de tiempo indicado.
Análisis estadísticos
El método de series temporales utilizado para el pronóstico de los casos de COVID-19 fue el Autorregresivo Integrado de Medias Móviles de orden (p, d, q) o ARIMA (p, d, q). La construcción del modelo se realizó de forma iterativa siguiendo las 4 etapas de la metodología de Box-Jenkins11,22-241-Identificacion: en la cual se determinó la transformación estacionaria de la serie para obtener el modelo apropiado, mediante el análisis de los coeficientes de autocorrelación (ACF), y el contraste de raíces unitarias de Dickey-Fuller Aumentado (ADF); 2-Estimación: en la cual, mediante la elección de las ordenes p, d, q apropiadas, se ajustó el modelo a la serie temporal, obteniéndose el modelo ARIMA (0,2,9); 3-Validacion: en la cual se analizó si el modelo era apropiado, y se valoró con el Criterio de Información Bayesiano Normalizado (BIC Normalizado), el error porcentual medio absoluto (MAPE) y la prueba de ruido blanco o test de Box-Ljung; 4-Predicción: en la cual se generó los pronósticos del número de casos de los siguientes 30 días; para luego compararlos con los casos observados. El programa estadístico que se utilizó para el análisis de la serie temporal fue el SPSS versión 22 y para determinar el contraste de raíz unitaria de Dickey-Fuller aumentado fue el programa STATA versión 15.
RESULTADOS
En laTabla 1, se observa el recuento diario de casos con COVID 19, entre el 6 de marzo de 2020 y 11 de junio de 2020. En laFigura 1, se muestra que los coeficientes de autocorrelación (ACF) decrecen lentamente en forma lineal, por lo que corresponden a una serie temporal no estacionaria, siendo esta corroborada por el contraste de raíz unitaria de Dickey-Fuller Aumentado (p>0,01).
En laFigura 2se muestra la transformación estacionaria de segundo orden, en la cual se estabilizo la serie temporal mediante la eliminación de tendencias y así obtener el modelo apropiado con las ordenes p, d, q, el cual fue ARIMA (0,2,9). En laTabla 2se muestra los parámetros (p, d, q) obtenidos en el proceso del modelado; el Criterio de Información Bayesiano Normalizado (BIC) que indica que 13,475 fue el valor más bajo obtenido indicando el mejor modelo ARIMA; el error porcentual medio absoluto (MAPE) que indica que el pronóstico del modelo está errado en un 7,775%; y la prueba de Ljung-Box que indica que el modelo es capaz de reproducir el patrón de comportamiento sistemático de la serie temporal.
En laFigura 3yTabla 3se muestra el pronóstico del número de casos con intervalos de confianza del 95% y los casos observados; desde el 12 de junio al 11 de julio de 2020, con los datos del 06 de marzo de 2020 al 11 de junio de 2020. Los valores de los casos observados, son inferiores a los valores de los casos pronosticados, encontrándose los observados dentro de los valores mínimo y máximo de los estimados.
Tabla 1. Número de casos con COVID 19 por día, del 6 de marzo al 11 de junio de 2020. Perú
| Día | Casos | Día | Casos | Día | Casos | Día | Casos |
| 6/03/2020 | 1 | 31/03/2020 | 1065 | 25/04/2020 | 25331 | 20/05/2020 | 104020 |
| 7/03/2020 | 6 | 1/04/2020 | 1323 | 26/04/2020 | 27517 | 21/05/2020 | 108769 |
| 8/03/2020 | 6 | 2/04/2020 | 1414 | 27/04/2020 | 28699 | 22/05/2020 | 111698 |
| 9/03/2020 | 9 | 3/04/2020 | 1595 | 28/04/2020 | 31190 | 23/05/2020 | 115754 |
| 10/03/2020 | 11 | 4/04/2020 | 1746 | 29/04/2020 | 33931 | 24/05/2020 | 119959 |
| 11/03/2020 | 17 | 5/04/2020 | 2281 | 30/04/2020 | 36976 | 25/05/2020 | 123979 |
| 12/03/2020 | 22 | 6/04/2020 | 2561 | 1/05/2020 | 40459 | 26/05/2020 | 129751 |
| 13/03/2020 | 38 | 7/04/2020 | 2954 | 2/05/2020 | 42534 | 27/05/2020 | 135905 |
| 14/03/2020 | 43 | 8/04/2020 | 4342 | 3/05/2020 | 45928 | 28/05/2020 | 141779 |
| 15/03/2020 | 71 | 9/04/2020 | 5256 | 4/05/2020 | 47372 | 29/05/2020 | 148285 |
| 16/03/2020 | 86 | 10/04/2020 | 5897 | 5/05/2020 | 51189 | 30/05/2020 | 155671 |
| 17/03/2020 | 117 | 11/04/2020 | 6848 | 6/05/2020 | 54817 | 31/05/2020 | 164476 |
| 18/03/2020 | 145 | 12/04/2020 | 7519 | 7/05/2020 | 58526 | 1/06/2020 | 170039 |
| 19/03/2020 | 234 | 13/04/2020 | 9784 | 8/05/2020 | 61847 | 2/06/2020 | 174884 |
| 20/03/2020 | 263 | 14/04/2020 | 10303 | 9/05/2020 | 65015 | 3/06/2020 | 178914 |
| 21/03/2020 | 317 | 15/04/2020 | 11475 | 10/05/2020 | 67307 | 4/06/2020 | 183198 |
| 22/03/2020 | 360 | 16/04/2020 | 12491 | 11/05/2020 | 68822 | 5/06/2020 | 187400 |
| 23/03/2020 | 395 | 17/04/2020 | 13489 | 12/05/2020 | 72059 | 6/06/2020 | 191758 |
| 24/03/2020 | 416 | 18/04/2020 | 14420 | 13/05/2020 | 76306 | 7/06/2020 | 196515 |
| 25/03/2020 | 480 | 19/04/2020 | 15628 | 14/05/2020 | 80604 | 8/06/2020 | 199696 |
| 26/03/2020 | 580 | 20/04/2020 | 16325 | 15/05/2020 | 84495 | 9/06/2020 | 203736 |
| 27/03/2020 | 635 | 21/04/2020 | 17837 | 16/05/2020 | 88541 | 10/06/2020 | 208823 |
| 28/03/2020 | 671 | 22/04/2020 | 19250 | 17/05/2020 | 92273 | 11/06/2020 | 214788 |
| 29/03/2020 | 852 | 23/04/2020 | 20914 | 18/05/2020 | 94933 | ………………… | ……………. |
| 30/03/2020 | 950 | 24/04/2020 | 21648 | 19/05/2020 | 99483 | ………………… | ……………. |
Fuente: Sala Situacional COVID 19-Peru, del Instituto Nacional de Salud y Centro Nacional de Epidemiologia, Prevención y Control de Enfermedades del Ministerio de Salud
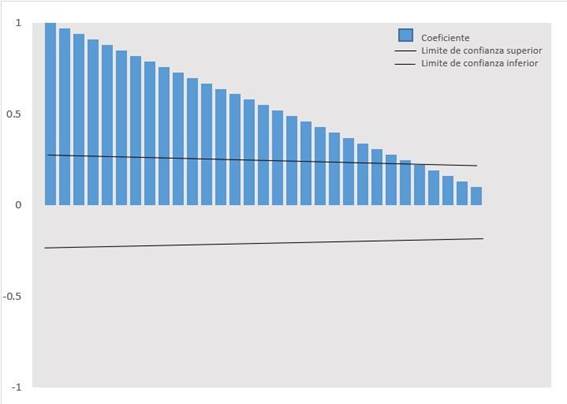
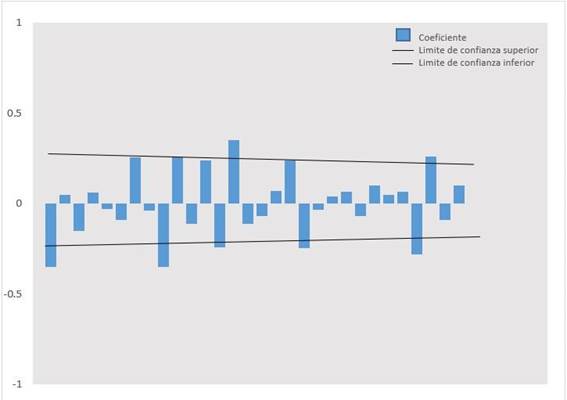
Gráfico 2. Correlograma de Autocorrelación (ACF) estimada para la serie de tiempo, con una transformación de segundo orden
Tabla 2. Parámetros óptimos para el modelo
| Parámetros | BIC | Error medio | Prueba | |
| ARIMA | Normalizado | absoluto | de Ljung-Box | |
| Perú | (0,2,9) | 13,475 | 7,775 | 0,040* |
Nota: *p <0,01 BIC Normalizado: Criterio de Información Bayesiano Normalizado ARIMA: Método Autorregresivo Integrado de Medias Móviles
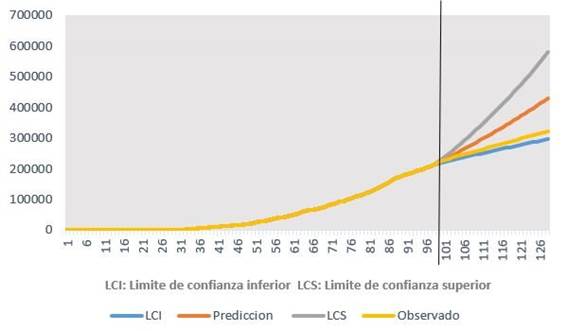
Gráfico 3. Pronóstico del número de casos de COVID 19, con intervalos de confianza del 95% y casos observados de COVID 19; desde el 12 de junio al 11 de julio de 2020
Tabla 3. Casos observados y pronóstico del número de casos de COVID 19, con intervalos de confianza del 95% desde el 12 de junio al 11 de julio de 2020
| Pronostico | ||||
| Intervalo de Confianza: 95% | ||||
| Dia | Observado | ARIMA | Limite inferior | Limite superior |
| 12/06/2020 | 220749 | 220596 | 216821 | 224394 |
| 13/06/2020 | 225132 | 226675 | 220300 | 233118 |
| 14/06/2020 | 229736 | 232952 | 223819 | 242221 |
| 15/06/2020 | 232992 | 239355 | 227227 | 251717 |
| 16/06/2020 | 237156 | 245776 | 230401 | 261518 |
| 17/06/2020 | 240908 | 252499 | 233612 | 271929 |
| 18/06/2020 | 244388 | 259233 | 236578 | 282653 |
| 19/06/2020 | 247925 | 265890 | 239218 | 293600 |
| 20/06/2020 | 251338 | 272444 | 241516 | 304743 |
| 21/06/2020 | 254936 | 279083 | 243973 | 315926 |
| 22/06/2020 | 257447 | 285805 | 246533 | 327204 |
| 23/06/2020 | 260810 | 292612 | 249163 | 338615 |
| 24/06/2020 | 264689 | 299503 | 251840 | 350183 |
| 25/06/2020 | 268602 | 306478 | 254548 | 361925 |
| 26/06/2020 | 272364 | 313539 | 257274 | 373857 |
| 27/06/2020 | 275989 | 320685 | 260010 | 385988 |
| 28/06/2020 | 279419 | 327916 | 262748 | 398327 |
| 29/06/2020 | 282365 | 335232 | 265483 | 410882 |
| 30/06/2020 | 285213 | 342635 | 268210 | 423660 |
| 1/07/2020 | 288477 | 350123 | 270926 | 436665 |
| 2/07/2020 | 292004 | 357698 | 273628 | 449903 |
| 3/07/2020 | 295599 | 365359 | 276313 | 463378 |
| 4/07/2020 | 299080 | 373107 | 278978 | 477094 |
| 5/07/2020 | 302718 | 380942 | 281622 | 491054 |
| 6/07/2020 | 305703 | 388864 | 284244 | 505263 |
| 7/07/2020 | 309278 | 396873 | 286842 | 519724 |
| 8/07/2020 | 312911 | 404970 | 289414 | 534438 |
| 9/07/2020 | 316448 | 413155 | 291960 | 549411 |
| 10/07/2020 | 319646 | 421428 | 294478 | 564643 |
| 11/07/2020 | 322710 | 429790 | 296969 | 580138 |
Fuente: Los pronósticos con sus intervalos de confianza son obtenidos con el Método Autorregresivo Integrado de Medias Móviles-ARIMA (0,2,9)
DISCUSIÓN
Esta investigación se realizó para predecir el número de casos con COVID-19 desde el 12 de junio hasta el 11 de julio de 2020 en el Perú utilizando el método Autorregresivo Integrado de Medias Móviles (ARIMA), para posteriormente compararlos con los casos observados con el fin de buscar una aproximación entre ambos resultados.
Hay que tener en cuenta que los pronósticos obtenidos a partir de un modelo de serie temporal univariante, son extrapolaciones de los datos observados hasta el tiempo en que termina la serie, siendo en muchas ocasiones muy efectivas proporcionando un punto de referencia para predecir futuros valores de los casos confirmados. La mayoría de las series son estocásticas, en que el futuro solo se puede determinar parcialmente por sus valores pasados, por lo que los pronósticos exactos son imposibles24.
Diversos autores1,11,15-20, a nivel mundial, han desarrollado modelos para el pronóstico de casos de COVID-19 basados en el método ARIMA, en los cuales han utilizado determinados estadísticos para evaluar la bondad de ajuste del modelo mostrando buenos resultados en cuanto a pronósticos a corto plazo.
El modelado realizado en este estudio ha seguido todas las etapas de la metodología de Box-Jenkins11,22-23, con el fin de obtener el mejor modelo predictivo; y si bien algunos investigadores han aplicado estas etapas, solo han mencionado algunos parámetros estadísticos utilizados en su construcción.
Moftakhar L y Seif M1, mencionan el uso del análisis de los coeficientes de autocorrelación (ACF), autocorrelación parcial (PACF) y el test de Box-Ljung; Singh RK et al11, mencionan el uso del criterio de información de Akaike (AIC); Ceylan Z15, menciona el uso del error cuadrático medio (RMSE), error absoluto medio (MAE) y error porcentual medio absoluto (MAPE); Benvenuto D16,menciona el uso del contraste de raíces unitarias de Dickey-Fuller Aumentado (ADF) y el análisis de los coeficientes de autocorrelación (ACF) y autocorrelación parcial (PACF); Yousaf M et al17, mencionan el uso del análisis de los coeficientes de autocorrelación (ACF) y autocorrelación parcial (ACF y PACF) y el criterio de información de Akaike (AIC); Hiteshi Tandon18, menciona el uso del análisis de los coeficientes de autocorrelación (ACF) y autocorrelación parcial (PACF) además de la varianza, prueba de normalidad, el error porcentual medio absoluto (MAPE), la Desviación Absoluta de la Media (DAM) y la desviación cuadrática media (MSD); Rishabh Tyagi et al19, mencionan el uso del análisis de los coeficientes de autocorrelación (ACF) y autocorrelación parcial (PACF), el contraste de raíces unitarias de Dickey-Fuller Aumentado (ADF), y proporciona los intervalos de confianza (IC) del 95% para las estimaciones puntuales; por ultimo Perone G20, menciona el uso del criterio de información de Akaike (AIC), el análisis de los coeficientes de autocorrelación (ACF) y autocorrelación parcial (PACF), el contraste de raíces unitarias de Dickey-Fuller Aumentado (ADF), la prueba modificada para raíz unitaria de Elliott-Rothenberg-Stock (DF-GLS), el error absoluto medio (MAE), la prueba de normalidad, la homocedasticidad, la prueba del multiplicador de Lagrange de Engle, y el test de Box-Ljun, muchos de los cuales coinciden con los utilizados en esta investigación.
Si bien es cierto que dentro de los modelos matemáticos de pronóstico existe una variedad de estos; el modelo ARIMA tiene una mayor precisión de ajuste que los demás26, ya que captura las tendencias de pronóstico estacionales y no estacionales; este estudio se centra en un modelo no estacional, para describir el patrón de crecimiento a lo largo del tiempo. Por otro lado, si un modelo utiliza enfoques estadísticos para su selección y evaluación; hay que reconocer que, si el número de casos no es cierto, al ser la única fuente de información oficial disponible en el país, puede conducir a un pronóstico inexacto. Aun con esta limitación, los resultados sugieren que el método puede ayudar a estimar la dinámica del brote y proporcionar pautas para detener o controlar de la mejor manera el aumento de las infecciones en el país, pero también es evidente, que todo intento de control, depende de las políticas públicas que se dicten por parte de las autoridades y sobre todo, la toma de conciencia de cada ciudadano sobre la propagación del COVID-19 y de los efectos letales que un comportamiento o practica irresponsable puede traer como consecuencia para sí mismo, su familia y la comunidad.
Asimismo, este modelo permite analizar la posible evolución de la curva de contagios y poder comparar los resultados con los de otros países para evaluar las acciones que se están tomando.
Cabe aclarar que esta estimación está fuertemente relacionada con la tendencia de los datos de la serie original, y el resultado de los pronósticos, pueden ayudar a entender cualquier cambio repentino en el pronóstico de casos COVID-19. Dentro de la limitación del estudio se puede mencionar, que la precisión del pronostico depende de la precisión de los datos aplicados, esto quiere decir que no hay alguna otra evidencia adicional que pueda estimar el número exacto de pacientes con COVID-19, ya que solo se consideró el numero de casos oficiales reportados por el Instituto Nacional de Salud y Centro Nacional de Epidemiologia, Prevención y Control de Enfermedades del Ministerio de Salud.
CONCLUSIÓN
Los resultados obtenidos con el modelo ARIMA, comparados con los datos observados, muestran un ajuste adecuado de los valores; y aunque este modelo, de fácil aplicación e interpretación, no simula el comportamiento exacto en el tiempo puede considerarse una herramienta simple e inmediata para aproximar el numero de casos.